論文メモ: Weaving Relations for Cache Performance
DB分野で、行グループ+列指向のデータレイアウトとしてよく参照される"PAX"が提案された2001年の論文、Weaving relations for cache performanceを読んだのでメモ。
簡単なまとめ
データベースにおけるデータの並べ方の分類
- N-ary Storage Model(NSM):行指向のレイアウト。同じ行は同じpageにある。
- Decomposition Storage Model(DSM):列指向のレイアウト。同じ列が同じpageにある。違う列は同じpageに無い。
- Partition Attributes Across(PAX):複数行をpageにまとめつつ、そのpage内で列指向レイアウト。これが本論文での提案内容。
(個人的な)ポイント
- PAXにするとNSMに比べCPUのキャッシュミスを減らせるためパフォーマンスが良くなる。
- いらないカラムもメモリにのることは気にしていない。ディスクI/Oは分析クエリのボトルネックではないため。比較も主にNSMとの比較。
- この論文はpageのレイアウトのみの話で、クエリエンジンやその最適化にはほとんど触れていない。(DSM+late materializationとか。時代的にまだなかったか。)
以下は論文からの引用と意訳
Abstract
In this paper, we propose a new data organization model called PAX (Partition Attributes Across), that significantly improves cache performance by grouping together all values of each attribute within each page.
- この論文でPAXというモデルを提案(DBにおけるデータの並べ方の一種)
- 各ページ内の各属性のすべての値をグループ化することでキャッシュのパフォーマンスを大幅に向上
1 Introduction
Recent research has demonstrated that modern database workloads, such as decision support systems and spatial applications, are often bound by delays related to the processor and the memory subsystem rather than I/O
[20][5][26]. When running commercial database systems on a modern processor, data requests that miss in the cache hierarchy (i.e., requests for data that are not found in any of the caches and are transferred from main memory) are a key memory bottleneck [1].
- decision support systemsのワークロード(大規模なデータを読み込む分析クエリのこと、くらいに思えばいいと思う)ではI/Oよりも、processorとmemoryバウンド(別論文参照).
- cacheミスによるリクエストが主要なメモリボトルネック(別論文参照)
the item that the query processing algorithm requests and the transfer unit between the memory and the processor are typically not the same size.
- クエリに必要なデータと、memory-processor間のデータの転送のサイズは大抵異なる。(つまり、CPUがメモリからデータを取ってくるときに隣接する不要なデータも一緒に持ってくる)
Loading the cache with useless data (a) wastes bandwidth, (b) pollutes the cache, and (c) possibly forces replacement of information that may be
needed in the future, incurring even more delays.
- 不要なデータをcacheにロードすると
- (a) (CPU-メモリ間の)帯域幅が浪費され
- (b) (CPUの)キャッシュが汚染され
- (c) 将来必要になる可能性のある情報の置換が強制される可能性がある
This paper introduces and evaluates Partition Attributes Across (PAX), a new layout for data records that combines the best of the two worlds and exhibits performance superior to both placement schemes by eliminating unnecessary accesses to main memory.
- この論文で、NSMとDSMのいいとこ取りをしたPAXを提案&評価する
- PAXはメインメモリへの不要なアクセスを防ぐことでパフォーマンスを向上する
実験した結果、
when compared to NSM, PAX (a) incurs 50-75% fewer second-level cache misses due to data accesses when executing a main-memory workload, (b) executes range selection queries and updates in 17-25% less elapsed time, and (c) executes TPC-H queries involving I/O 11-42% faster than NSM on the platform we studied.
vs NSM(行指向)
- (a) PAXはメインメモリのワークロードを実行する際のデータ アクセスによる2次キャッシュミスが 50~75%少なくなる
- (b) 範囲選択クエリと更新の実行時間が17~25%短縮
- (c) 実験環境上では、I/O を伴うTPC-Hクエリが、NSMよりも11~42%高速
When compared to DSM, PAX executes queries faster and its execution time remains stable as more attributes are involved in the query, while DSM’s execution time increases due to the high record reconstruction cost.
vs DSM(列指向)
- PAXは属性が多く含まれるので実行速度が安定する
- DSMはレコード再構築コストが高い
2 Related work
NSMとDSMに関して説明している章。
NSMだと、cacheに余計なものが入ってくるという図:
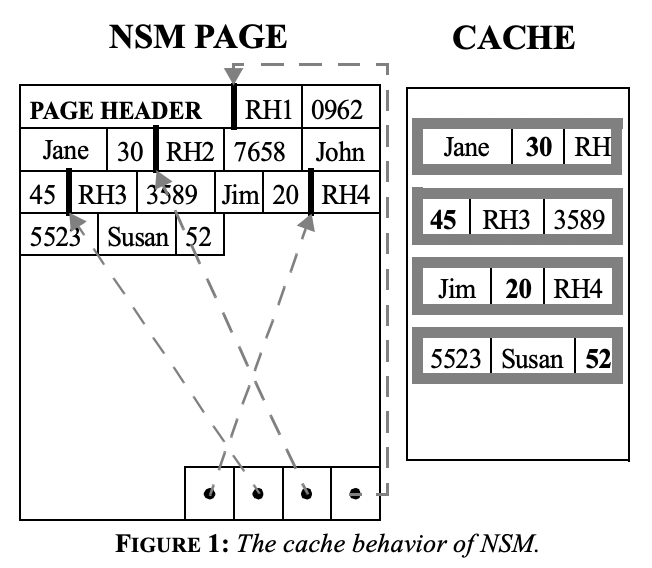
左がNSMの1pageで右側がCPUのcache。RHはrecordのheader、その他は各カラムの値で図の例ではSSN、name、ageというカラムがあり、ageだけ欲しいのに他のデータまでcacheに入ってきてしまうということを示している。
DSMの場合、
DSM performs well on DSS workloads known to utilize a small percentage of the attributes in a relation, as in Sybase-IQ which uses vertical partitioning combined with bitmap indices for warehousing applications [25]. In addition, DSM can improve cache performance of main-memory database systems, assuming that the record reconstruction cost is low [4].
Unfortunately, DSM’s performance deteriorates significantly for queries that involve multiple attributes from each participating relation. The database system must join the participating sub-relations on the surrogate to reconstruct the partitioned records. The time spent joining sub-relations increases with the number of attributes in the result relation.
- テーブル内の少ないカラムを使うワークロードで良好にパフォーマンスを発揮する。(DSSはdecision support systemの略)
- ただし、DSMは複数の属性が必要なクエリの場合に、recordの再構築コストのため大きくパフォーマンスが落ちる
3 PAX
PAXの実装例。
ここが本論文のメインの提案部分だがそこまで自分が興味のある話はなかったので図だけ。
(行でpage分割してその中に列でまとめてデータを並べているということがわかればよいと思う。)

4 System Implementation
NSM、DSM,PAXを使うシステムの実装の話。省略。
5 Analysis of the impact of data placement
いくつかの実験している章。一部だけ紹介。
NSMと比べてPAXでdata accessのパフォーマンスがどれくらい減ったかがわかる図。縦軸は行の処理にかかるclock cycleなので低いほど良い)
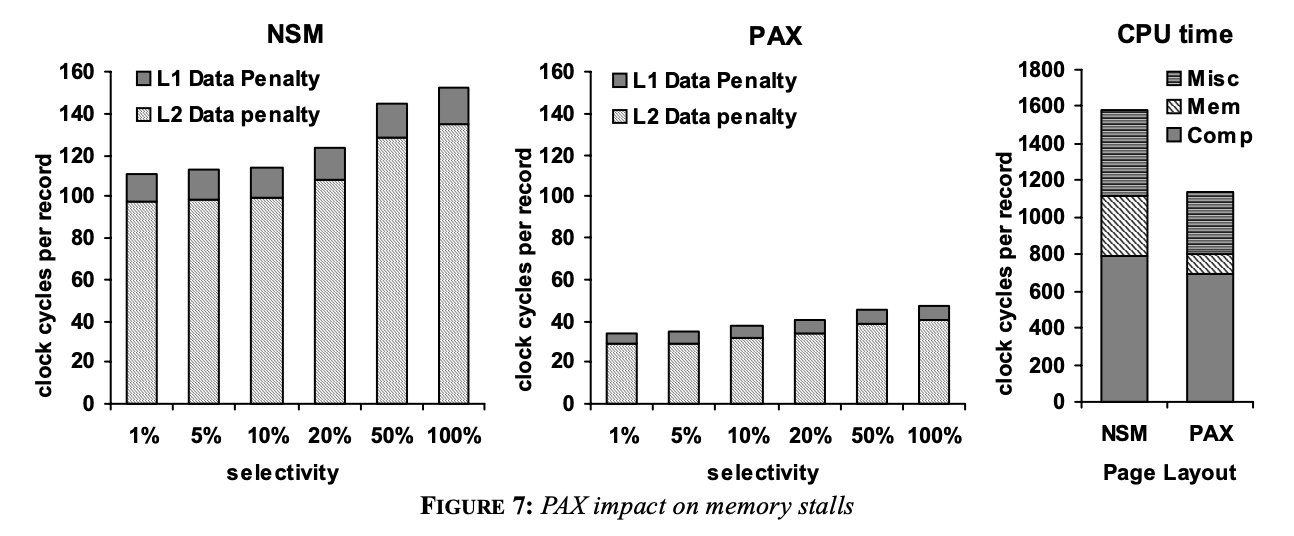
L1 cacheもL2 cahceもNSMよりPAXのほうが良くなっている。
L1はcache missしてもさほどペナルティがないが、L2は影響が大きい。L2 cache data penaltyはNSMに比べ70%減っている。
L2はデータも命令も入った統合的なcacheなので、data cache missが減って余計なデータがcacheに入らなくなると命令cache missも減る可能性がある、とも書いてある。
6 Evaluation Using DSS Workloads
データのロード時間、Rangeクエリ、TPC-Hのクエリなどで実験している。(クエリエンジンの最適化によっても変わってくる気がするので)省略。
Discussion