ECS(Fargate)用のPrometheusエクスポーター





AWSにおいて、ECSとFargateでコンテナを実行する際の監視ってどうされているでしょうか。
私の観測範囲ではオープンで自由に利用できるツールの中にちょうどいいものがなかったため自作しました。
背景
ECS+Fargateでコンテナを利用する場合、コンテナのリソース監視の方法としては以下が考えられると思います。
- CloudWatchを利用し、Container Insightを利用して詳細なメトリクスを取得する
- DatadogやMackerelと契約し、Fargate用のエージェント(サイドカー)をECS Taskで起動してメトリクスを取得、可視化してもらう
- 自分でPrometheusなどの監視サーバを構築し、FargateでECS関連のメトリクスをエクスポートしてくれるツールを利用してメトリクスを取得し、Grafanaなどで可視化する
細かい話をすれば他にもあると思いますが、概ねこんな感じだと思っています。
それぞれ、「ECSタスク単位」「コンテナ単位」でのCPU, メモリ, ネットワークのメトリクスを取得しようとすると、以下のような問題点があります。
CloudWatchを利用し、Container Insightを利用して詳細なメトリクスを取得する
Container Insightは、実は「コンテナ単位のメトリクス」は取れません。あくまで最小粒度は「ECSタスク単位」となります。
さらに、これを可視化するのも大変です。ECS Service単位のグラフはCloud Watchで簡単に可視化できるのですが、実はECSタスク単位の可視化は自分で作り込む必要があります。
具体的には、Container Insightの実体データである、CloudWatch Logsのロググループに対して適切なメトリクスフィルタを設定し、自分でタスクごとのCPU、メモリといったメトリクスをCloudWatchに送信する必要があり、さらにそのメトリクスを可視化するためのダッシュボードも作成する必要があります。
ECS Service単位のメトリクスさえあればいいよ!というようなPoCな環境であったり、それほど細かいメトリクス監視が不要な非機能要件のシステムの場合はこれで十分だと思います。
DatadogやMackerelと契約し、Fargate用のエージェント(サイドカー)をECS Taskで起動してメトリクスを取得、可視化してもらう
これが最適解だと思います。デメリットは「コストがかかる」、以上。
監視というプロダクトの直接の価値に結びつかないものについてSaaSを利用して解決するのは一つのベストプラクティスだと思います。
私の所属する環境ではこれらを使うコストを捻出する(してもらう)という交渉が難しいため使ったことがないのですが、これらの、監視のスペシャリストが提供している監視SaaSを利用するのが最もベストな選択だと思います。
自分でPrometheusなどの監視サーバを構築し、FargateでECS関連のメトリクスをエクスポートしてくれるツールを利用してメトリクスを取得し、Grafanaなどで可視化する
SaaSのランニングコストを考慮すると、自分で作ってしまうのが圧倒的に安くなってしまいます。
運用保守というTCOで考慮しても、です。(監視対象が150Task, 1000コンテナ程度の私の環境では残念ながら)
しかし、この方法は当然PrometheusやGrafanaをProduction Readyに設計、構築するスキルが必要となりますし、難易度的には高くなってしまいます。
そして一番問題だったのが、FargateでECS関連のメトリクスをエクスポートしてくれるツールを利用してメトリクスを取得しの部分です。
有志がいくつか開発したツールを公開してくれているのですが、残念ながら期待するメトリクスを取得することができず(使い方が間違っている可能性はゼロではない)、自分で開発するしかないという課題がありました。
既存のありがたいツール群
ecs_exporter
- prometheus communityに属しているもの。
- ECSタスク単位のCPU割当量、メモリ割当量が取得できない(これがないと、CPU使用率が計算できません)
ecs-container-exporter
- 個人開発のツール
- 動作的に惜しかったのだが
The metrics are sampled twice as per the configured interval (default 60s)という仕様がなぜか後から追加され、まともに動作しなくなってしまった。 - メンテナンスされていない
作成したecs-metrics-exporterについて
ecs-metrics-exporterのコンテナイメージをbuildして、Fargateで稼働するECS Taskのサイドカーとして起動し、デフォルトとしては9546ポートでアクセスすることで利用可能です。
http://ecstask-ipaddress:9546/metrics
最初にecs-metrics-exporterの実装を理解するのに必要な情報を共有した上で、最後にURLやレスポンスといった外部仕様を記載します。
Fargateでのコンテナメトリクスの取得方法
EC2をホスト(データプレーン)とする方式の場合は、EC2上のdockerdが提供するDocker Engine APIにアクセスすることでコンテナのCPU使用量などのメトリクスを取得可能です。
FargateにおいてはコンテナエンジンはAWS側のマネージドとなり隠蔽されているため、Amazon ECS タスクメタデータ を利用してメトリクスを取得する必要があります。
Amazon ECS タスクメタデータエンドポイント にはバージョン3とバージョン4がありますが、これから利用するならば最新のバージョン4だけ見ておけば問題ないでしょう。
タスクメタデータエンドポイントを利用するためのURLは、Fargateで起動したコンテナに対して環境変数ECS_CONTAINER_METADATA_URI_V4で提供されます。
このエンドポイントに対して/task, /stats などのAPIが提供されており、例えば以下で取得可能です。
curl http://${ECS_CONTAINER_METADATA_URI_V4}/stats
この /stats によって、/statsにアクセスしたコンテナが属するECS Taskのすべてのステータス情報 が取得可能です。
要は、ECS Task内のどのコンテナでアクセスしても同じ情報が取得できるということです。
レスポンスはJSONです。Fargate のタスクの Amazon ECS タスクメタデータ v4 の例 に実際のサンプルが例示されています。
それぞれの項目の定義は、DockerのDocument を参照する必要があります。
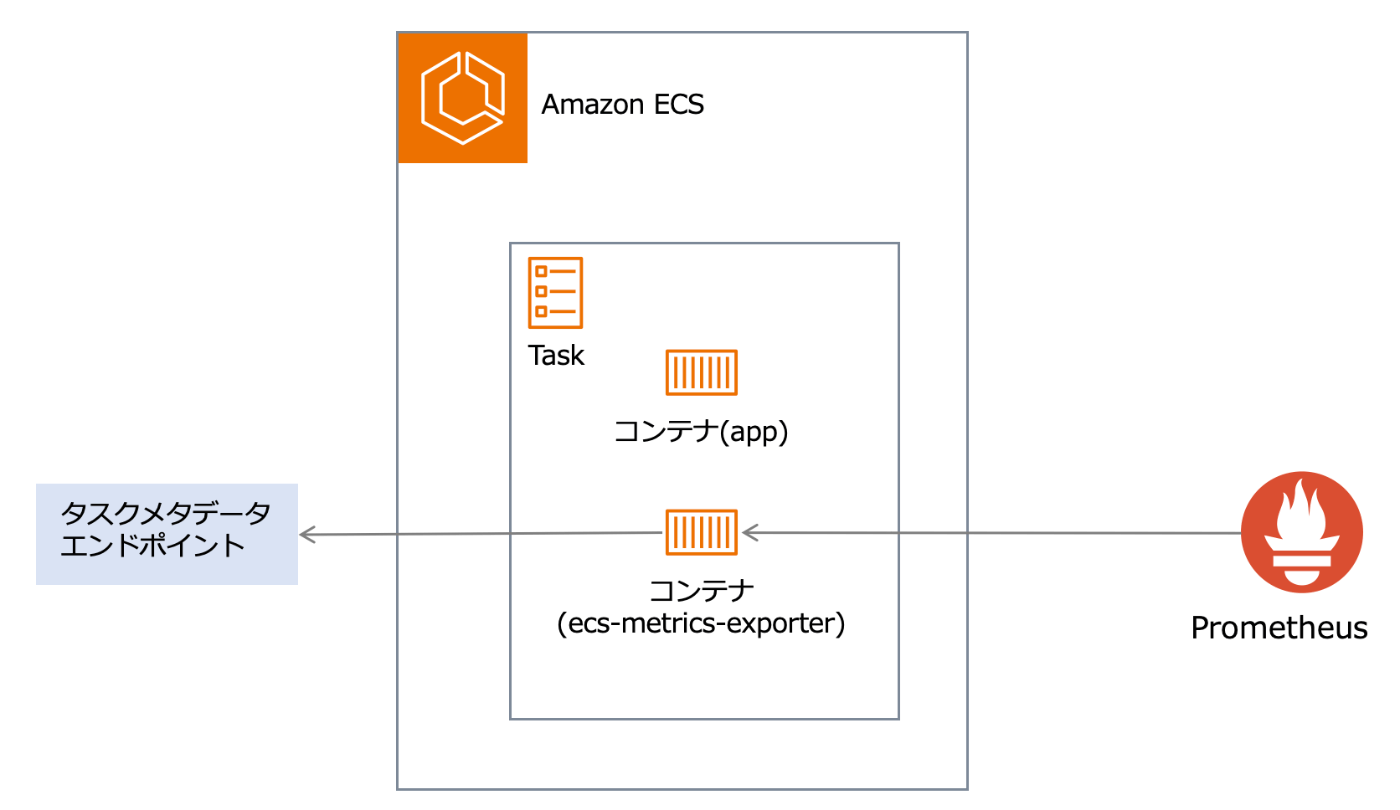
このように、Fargateにおいては以下のようにすることでTask単位,コンテナ単位のメトリクスが取得可能になります。
- 以下のようなサイドカーを用意
- prometheusに対して /metrics のエンドポイントを提供するWebサーバを起動
- タスクメタデータエンドポイントを利用してコンテナのメトリクスを取得する
- 取得したメトリクスをパースしprometheus形式のレスポンスを生成
- 上記のサイドカーをスクレイプするようprometheusを設定
実装
-
アクセスはPrometheusからの最短でも15秒に1回(私の環境では1分に1回)程度のアクセスを処理できればよいだけであるため、Webサーバとしては簡単に利用可能なものがよいです。
そのためFlaskのWebサーバ機能を利用しています。 -
Prometheus用のレスポンス形式を生成する箇所は、prometheus_client を利用しています。
-
DockerのStatsのパースと計算は試行錯誤とcAdvisorなどの実装参照と、実際に負荷をかけるなりして測定し確認しながら実装しています。
ecs-metrics-exporterの外部仕様
指定可能な環境変数
起動時に以下の環境変数を設定できます。
-
ECS_METRICS_EXPORTER_PORT:エクスポーターがリッスンするポート。デフォルトは9546です。
利用可能なURLとメトリクス一覧
URL
-
/metrics- Prometheusのメトリクスを提供します。 -
/stats-ECS_CONTAINER_METADATA_URI_V4/task/statsで取得できるJSONをそのまま返します。調査用。 -
/task-ECS_CONTAINER_METADATA_URI_V4/taskで取得できるJSONをそのまま返します。調査用。
メトリクスに付与されるラベル(Prometheusの)
-
container_name:コンテナ名。タスク単位のメトリクスの場合は_task_がセットされています。 -
container_id:コンテナID。タスク単位のメトリクスの場合は_task_がセットされています。 -
task_family:ECSタスクファミリーの名前。 -
task_revision:ECSタスク定義のリビジョン番号。
メトリクス一覧
すべてのメトリクスには接頭辞 "ee_" が付与されます。「Ecs metrics Exporter」のEE。
ee_task_cpu_limitとee_task_memory_limit_byteが取得できる点が特徴です。
-
ee_ecs_metrics_exporter_success:ECSメトリクスエクスポーターが成功したかどうかを示します。失敗の場合は0、成功の場合は1です。このメトリクスにはラベルがありません。 -
ee_task_cpu_limit:タスクCPUリミット。CPUユニットを512割り当てた場合、このメトリクスは0.5を返します。 -
ee_task_memory_limit_byte:タスクのメモリ割り当てサイズ(byte)。 -
ee_container_cpu_usage_seconds_total:コンテナのCPU使用秒数(ナノ秒ではない)。これはカウンターです。Prometheusのrate関数を使用してCPU使用率を計算できます。 -
ee_container_memory_usage_byte:バイト単位のメモリ使用量。コンテナによる現在の総メモリ使用量を表します。全てのキャッシュを含みます。 -
ee_container_network_io_rx_bytes:コンテナによって受信された全ネットワークインターフェースを通じての総バイト数。受信ネットワークトラフィックの監視に役立ちます。 -
ee_container_network_io_tx_bytes:コンテナによって送信された全ネットワークインターフェースを通じての総バイト数。送信ネットワークトラフィックの監視に役立ちます。 -
ee_container_block_io_read_bytes:コンテナによって全ブロックデバイスから読み取られた総バイト数。コンテナによって引き起こされる読み込みI/Oの圧力を理解するのに役立ちます。 -
ee_container_block_io_write_bytes:コンテナによって全ブロックデバイスに書き込まれた総バイト数。コンテナによって引き起こされる書き込みI/Oの圧力を理解するのに役立ちます。 -
ee_container_block_io_read_ops:コンテナによって全ブロックデバイスで実行された総読み取り操作数。このメトリクスは、読み取り操作の回数についての洞察を提供することで、バイト指向の読み取りメトリクスを補完します。 -
ee_container_block_io_write_ops:コンテナによって全ブロックデバイスで実行された総書き込み操作数。このメトリクスは、書き込み操作の回数についての洞察を提供することで、バイト指向の書き込みメトリクスを補完します。
取得できるメトリクスを利用したGrafanaでの可視化
本エクスポーターによって以下が取得できるようになりました。
- ECSタスク単位の割り当てCPU
- ECSタスク単位の割り当てメモリ
- ECSタスク単位のCPU使用率
- ECSタスク単位のメモリ使用率
- ECSタスク単位のネットワークin/out量
- ECSタスク単位のDisk in/out量
- コンテナ単位のCPU使用率
- コンテナ単位のメモリ使用率
- コンテナ単位のDisk in/out量
Grafanaで利用しているPromQLについては元気があってニーズがありそうなら後日紹介したいと思います。
Discussion