for Google Cloud PDBE
CloudSQL
→ メインインスタンスとフェイルオーバーレプリカを別のリージョンに置くとコストや同期遅延の課題があるため好ましくない。
並列レプリケーション フラグ
- レプリケーションを並列適用することでスループットが向上し、遅延を抑える。
- リードレプリカ側で設定する。途中から有効にする場合は一度レプリケーションをオフにしてからフラグを設定し再度有効化する。
フェイルオーバーレプリカへの一部の操作が失敗する → レプリケーションラグの可能性
PgBouncer : OSSのコネクションプーラー
コネクションプーリング
アプリケーションがデータベースとのコネクションをキャッシュすることで、DB とのコネクションハンドシェイクをスキップでき、アプリケーションのパフォーマンスを向上させることができる。データベース側にとってもコネクションを大量に維持しなくてよくなりメモリの使用を抑えることができる。
CloudSQL Auth Proxy
- インターネット公開することなく内部IPでDB接続が可能。
- 外部公開しないのでIP ホワイトリストを必要としない。
- DBのSSL有効化は必須ではない。
クエリ インサイト
クエリのパフォーマンスとリソース消費を可視化する機能。
gcloud sql operations listコマンド
- バックアップを含む CloudSQL インスタンスで実行されたすべての操作を一覧表示するツール。
- ステータス、開始時刻と終了時刻などのメタデータを確認可能なため、手動バックアップの現在の状態と進行状況を判断などに利用可能。
レプリケーションラグ
- プライマリインスタンスからレプリケートされる時間を示す。
- 復旧の際にデータ損失の可能性を判断するのに有用。
- Cloud Monitoringのメトリクスで確認可能。
- 遅れている秒数/バイト数(ポスグレのみ)/プライマリにコミットしてからWAL receiverで受け取るまでの秒数
原因
- プライマリ インスタンスが、レプリカに変更を十分な速さで送信できない。
- network_lagメトリクスで確認可能。
- レプリカが変更を十分な速さで受信できない。
- network_lagメトリクスで確認可能。
- レプリカが変更を十分な速さで適用できない。
- replica_lagメトリクスで確認可能。
mysql.slave_master_info
- MySQL のこのテーブルには、レプリケーション構成に関する情報が含まれる。
- スタンバイレプリカを昇格しフェイルオーバーする前に、レプリケーションの状態を確認することでデータ損失の可能性を判断できる。
同じリージョン内のゾーン間
→ 同期 レプリケーションを設定できゾーン障害が発生してもデータ損失が発生しない
→ 同期レプリケーションは長距離ではパフォーマンスに影響を与えうるため、異なるリージョン間では 非同期 レプリケーションを利用することが推奨。
クエリ操作のレイテンシを 1 ミリ秒未満に抑えたい → Memorystoreでキャッシュする
gcloud sql instance patchコマンドで既存インスタンスに設定変更可能。
→ フェイルオーバーレプリカの有効化、vCPU追加など
CSVファイルとしてGCSへ定期的にエクスポートする → Cloud Composerでcloudsql.instances.export APIの利用
IOが遅いなどでストレージ タイプ(HDD、SSD)を変更したいとき、直接更新はできない。
→ 新規にインスタンスを構築し、データを移行する。
リードレプリカの昇格は手動。-> RTOが小さい用件では難しい
Cloud SQL インスタンスの高可用性 (HA) を有効にすると、データベースが異なるリージョン間で動作することが保証され、リージョンの停止が発生した場合にフェイルオーバー メカニズムが提供される。
→
短い RTO (Recovery Time Objective) が求められる場合に HA 構成が有用である
HA 構成が同期レプリケーションであるのに対し、 リードレプリカは非同期レプリケーション
レプリケーションの仕組み
Cloud SQL リードレプリカは、PostgreSQL ストリーミング レプリケーションを使用します。変更は、プライマリ インスタンスの先行書き込みログ(WAL)に書き込まれます。WAL sender がレプリカの WAL receiver に WAL を送信し、そこで適用されます。
Serverless Export
- 大規模なデータベースの 1 回限りのエクスポートを作成する場合に推奨。
- エクスポートされるデータ量が少ない場合はリードレプリカからエクスポートを取得でOK。
- エクスポート オペレーションをオフロードするために、個別の一時的なインスタンスが Cloud SQL によって作成されプライマリインスタンスに負荷をかけない。
圧縮
Cloud SQL では、圧縮ファイルと非圧縮ファイルの両方のインポートとエクスポートがサポートされています
Query Insights
高負荷の SQL やその実行計画を確認できる。
インフラコストやサイズの適正などの視点ではない→レコメンダー使う
また Sqlcommenter というオープンソースライブラリを使うことでアプリケーション側で ORM を使っている場合でも SQL の特定に役立ちます。
ORM → Djangoのモデルとかあれ
メンテナンスウィンドウ
最大 90 日間のメンテナンス拒否期間を設定可能
1時間枠で設定を行う
ポスグレのオンラインバックアップ→ Oracle同様アーカイブログ、RMAN
HA構成
Cloud SQL で HA 構成を有効化することで、プライマリとスタンバイという2台のデータベースを利用した冗長構成を簡単に組むことができます。そのため、本番環境の可用性を確保するためには HA 構成がオススメです。 HA 構成を利用することで、 Cloud SQL の SLA (稼働率99.95%)が適用されるため、安心してサービスを運用できます。
99.95%のSLA
仕組み
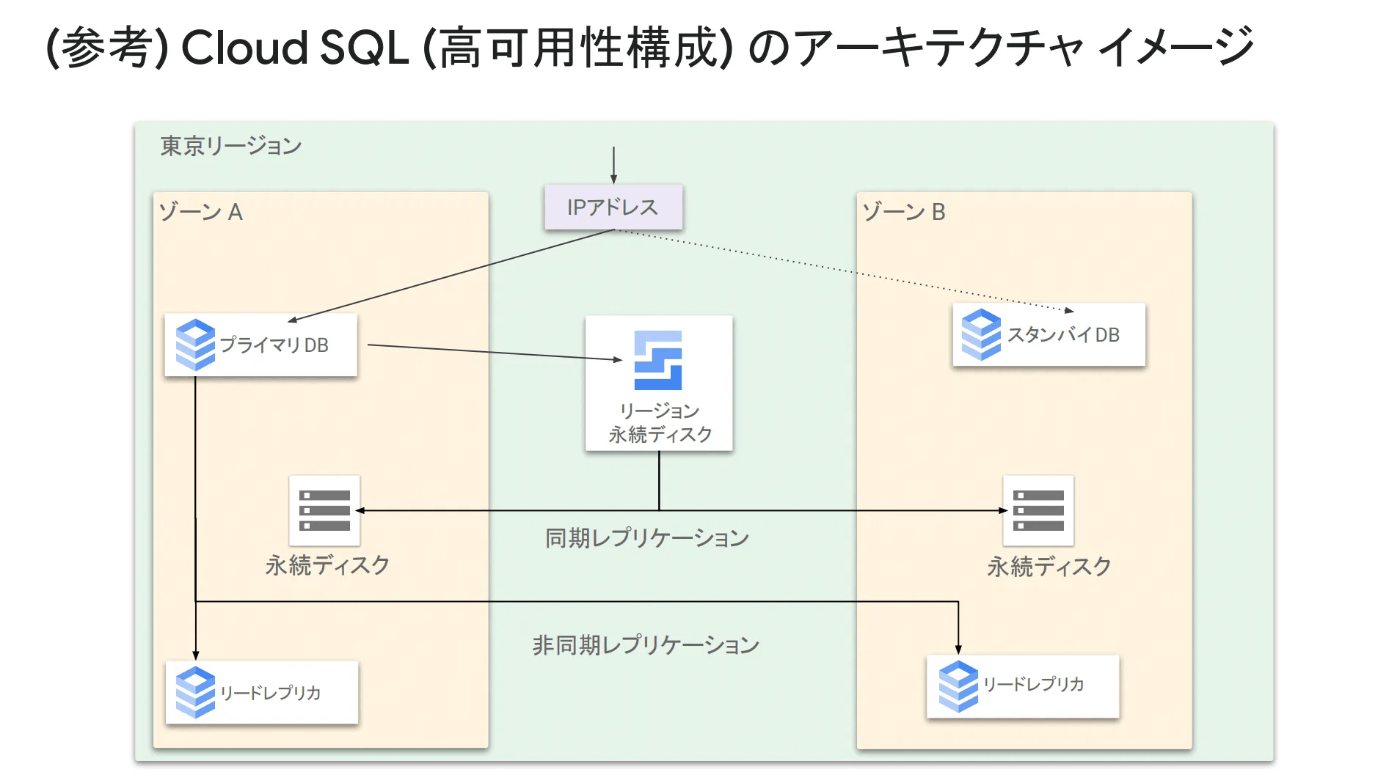
書き込みを行なう場合は IP アドレスを通じてプライマリ DB に書き込みがなされます。このとき、裏側でリージョン永続ディスクというものが利用されており、このリージョン永続ディスクに対してプライマリ DB が書き込みを行います。リージョン永続ディスクは2つのゾーンにまたがって同期のレプリケーションで書き込みを行っており、これによってデータの堅牢性を高めています。
Firestore
オフライン永続性
- モバイル上でデータをローカルにキャッシュできる。デバイスがオフラインの場合でも、アプリケーションがデータにアクセスして操作でき、接続が回復するとデータはシームレスに同期される。
- configでPersistenceEnabledをtrueに指定することでローカルにキャッシュできる。
- デフォルトでは10MBまで。persistenceCacheSizeBytesで任意の値に変更可能。
Bare Metal Solution (BMS)
非仮想化環境を必要とするアプリケーションの実行向け。eg.) Oracle、SAP HANA、SQL Server (?)
もしくは、オンプレのワークロードを全く変更せずにクラウド移行する段階でも可能な選択肢。
Bigtable
自動スナップショット → テーブルのスナップショットを定期取得。特定のGCSバケットをターゲットに保持することができる。
Veeam : 仮想・物理・クラウド問わず幅広いプラットフォームのデータ保護製品(バックアップとレプリケーション)
Memorystore
メンテナンス設定 : メンテナンスウィンドウの構成や、イベントを延期してビジネス上中断を回避したい時期をブロックすることが可能。
データ移行
Database Migration Service (DMS)
オンプレや他社クラウドからCloud SQL や AlloyDB for PostgreSQL への移行をサポート。
連続的なデータ同期を行うためアプリケーションのダウンタイムを回避可能。
OracleからCloudSQL/AlloyDBなど一部異種データベース間移行もサポート されるが事前に検証しておく必要あり。
※ 安定した帯域確保必要
ワンタイムとCDC(変更データ キャプチャ)を選択可能。前者はメンテナンスウィンドウが必要になる。
継続的レプリケーション (DBサービス組み込みのサービス)
Cloud SQL でサポートされているのは MySQL と PostgreSQL のみ。
ダウンタイムを伴わない。
※ 安定した帯域確保必要
ダンプファイル
Cloud SQL では MySQL、PostgreSQL、Microsoft SQL Server をサポート。
GCSバケットに置いたダンプファイルをインポートする。当然ダウンタイムを伴う。
Datastream
CDC(Change Data Capture)サービス。主にBigQueryに取り込むことを目的としたサービス。
GCSに移行できるのでBigQueryに取り込むなどのアーキ
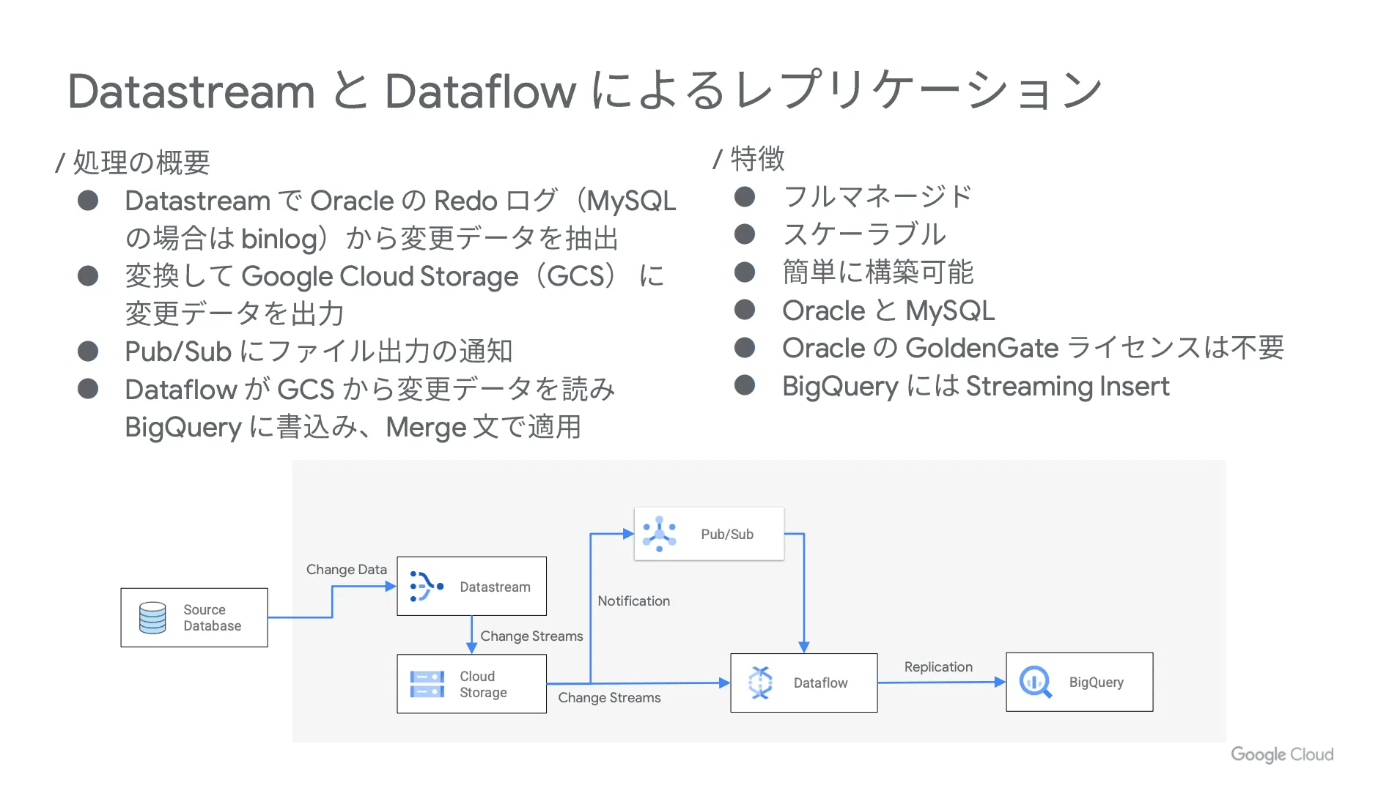
ソース
MySQL ソース
Oracle ソース
PostgreSQL ソース(AlloyDB for PostgreSQL を含む)
SQL Server ソース
宛先
-BigQuery
- GCS
- CloudSQL
- Spanner
- Dataflow
- Data Fusion
Cloud Spanner
マネージド エクスポートと復元機能 → 本番環境へのパフォーマンスへの影響を最小限に抑えられる
設定でallow_commit_timestamp = trueとすることでPITRが利用できる。
ホットスポットの回避方法
- UUID
- ビット反転 → 主キーの分散シーケンスの作成が容易になる。
リードレプリカが必要な RPO に準拠しているかの監視 ← レプリケーション監視ツールの使用。
※ 一般のモニタリング サービスでは無理
roles/spanner.databaseReader ※ roles/spanner.reader ではない
Cloud Spanner インポート ユーティリティ
データベースへのデータのロードのためのツール
特定のテーブルへのReadOnly権限を実現する場合、
spanner.database.readSessions.create 権限を有効にし特定のテーブルへの読み取り専用アクセスを許可する。
バックアップ コピーの数
- Cloud Spanner バックアップに関連するコストを最も直接的に削減する方法。
- 管理対象のバックアップ コピーの数を減らすことでストレージ要件が直接削減される
- 運用機能に比較的大きな影響を与えずにコスト効率を確保できる。
CMEK対応
クエリタグ
- トランザクションタグ
- リクエストタグ
→ タグごとのメトリクス集計(クエリの平均速度)やコスト算出に利用できる。
→ 複数のアプリケーションが混在する環境でどのアプリケーションのクエリが負荷が高いかなどのパフォーマンス解析に有用
処理ユニット( Processing Unit )
→ 1 つの処理ユニットは、読み取りと書き込みの両方のスループットとコンピューティング容量を提供
DynamoのRCU、WCUみたいなもの?
Query Insights
SQL クエリの監視を容易にし、サービス パフォーマンスに影響を与える可能性のある長時間実行クエリに関する分析情報を提供
2000回の読み取り操作/1sec に対応。
DB移行する際、移行元のDBに主キーが含まれ、移行後にレコードの一意性を維持できることを確認しておくこと。
gcloud spanner instance failoverコマンドでプライマリインスタンス名を引数に指定し、フェイルオーバーをテストできる。
JSONなど半構造化データもいける!
BigQuery
CMEK対応
PITRを利用した過去データの復旧
ポイントインタイムリカバリ (PITR)。
データ破損が広範囲にわたる変更の場合→ バックアップと復元機能 で破損前の正確な時点にデータベースを戻す。これにより、データの損失と一貫性が最小限に抑えられる。
影響を受けるデータセットが小さい場合→ 破損前のタイムスタンプで古い読み取りを実行して正しいデータ値を取得し、それを手動で現在の運用環境の状態と調整することで、よりきめ細かいアプローチが可能になる。
GCE
ext4 形式の永続ディスクの拡張 → resize2fsコマンドでファイルシステムの拡張
英語
bespoke : オーダーメイド
overhaul : 総点検する
avert : 逸らす
segregate : 隔離する
forge : 築く
jurisdiction : 管轄
procurement : 調達
pristine : 原始的な
meticulous : 入念な
sluggish : 鈍い
alleviate : 緩和する
on the verge of : 今にも-しそう