PlanetScale入門
アカウントの作成
以下のURLからアカウントを発行する。
GitHubアカウントで作成するのが最も簡単だと思います。
データベースの作成
最初はデータベースの作成から行う。
今回は以下で作成中のアプリケーションのデータベースとして利用する。
一緒に開発をしている友人もデータベースの管理をすることになるので organizationを作成してそこにデータベースを追加していく。
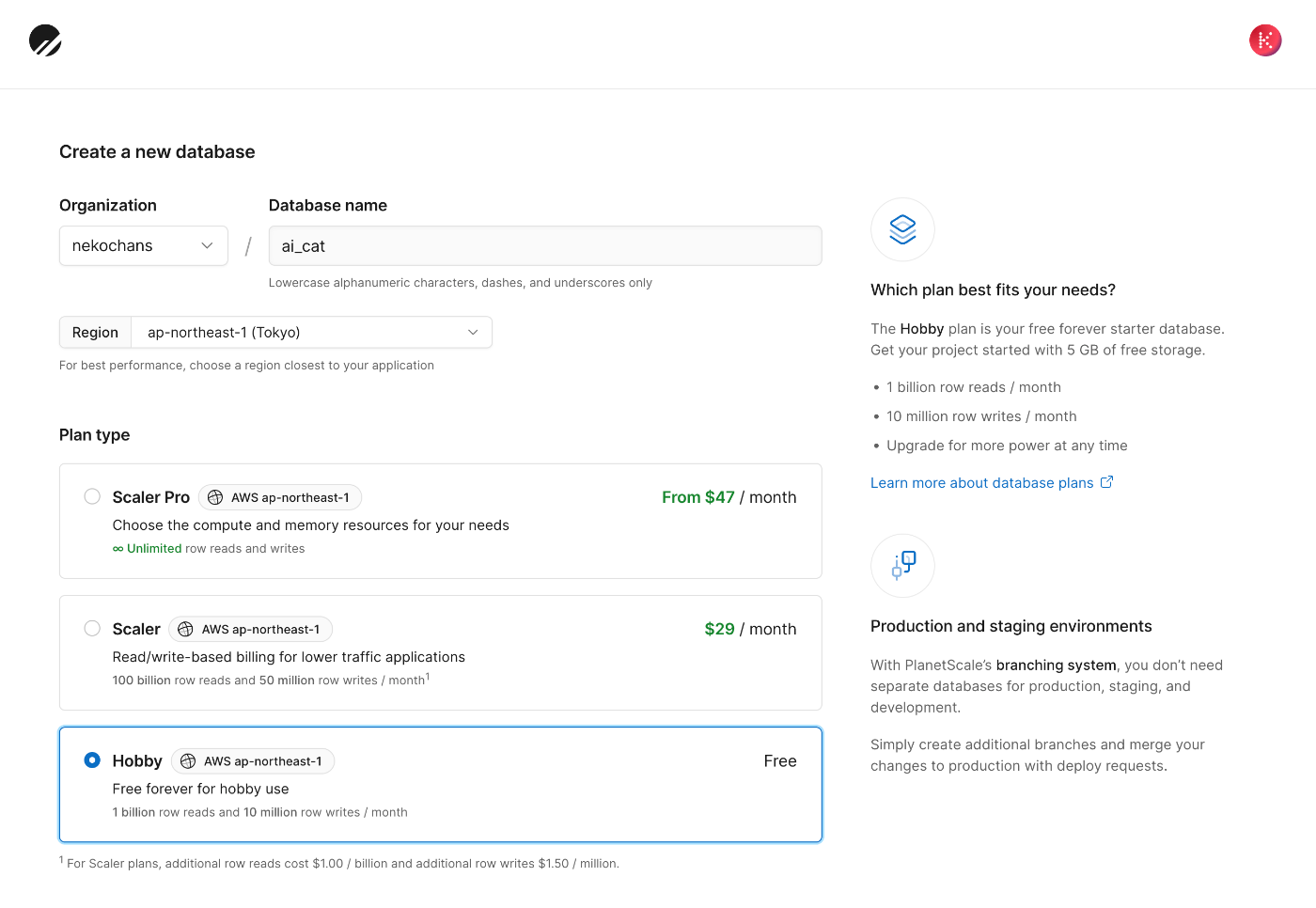
以下のように東京リージョンにDBを作成する。
- データベース名:
ai_cat - リージョン:
AWS ap-northeast-1(AWSの東京リージョン)
ちなみにorganizationにデータベースを作成した影響かHobbyプランでもクレジットカードの登録を要求された。
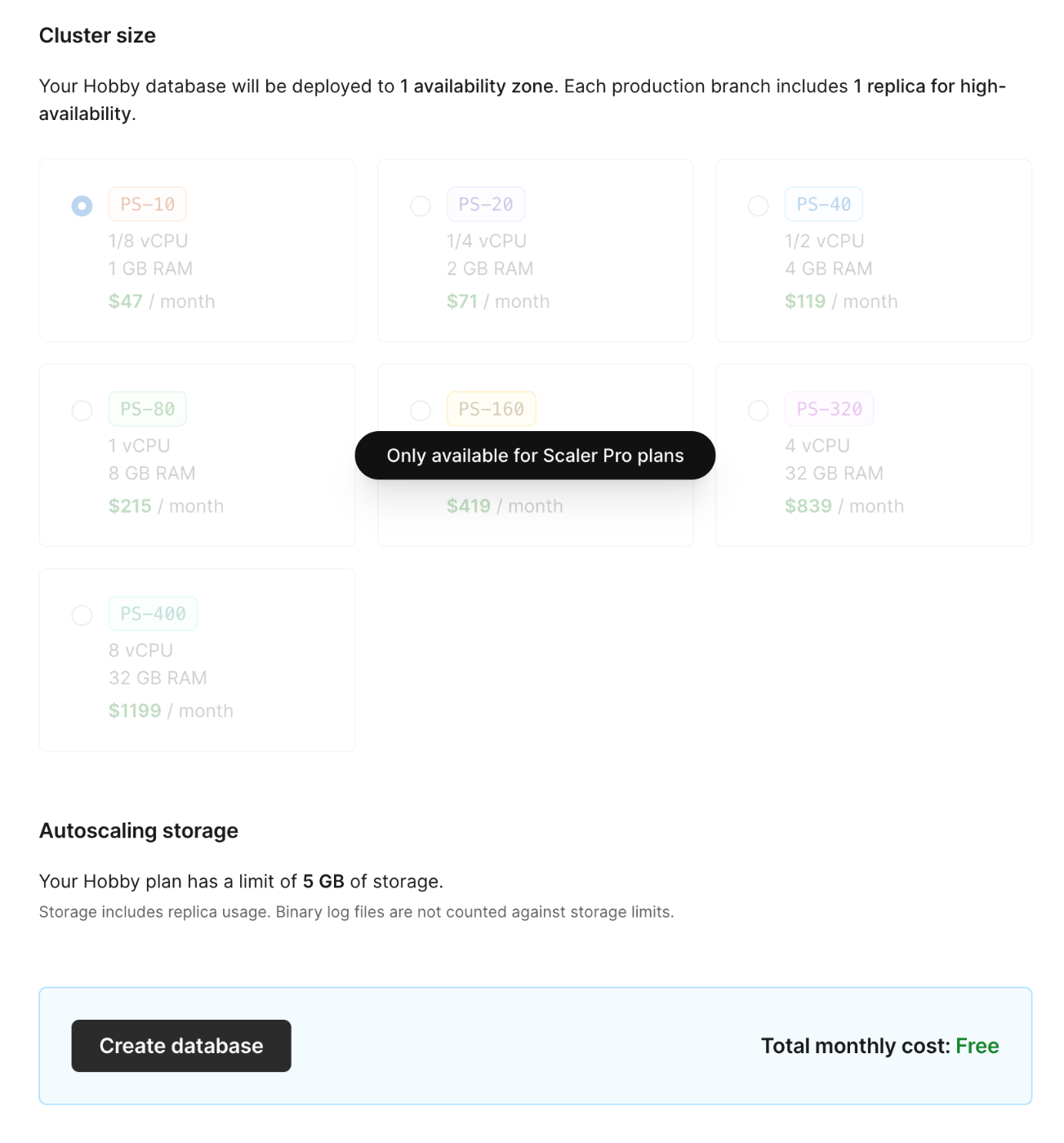
しばらくはHobbyプランで行くつもりだが、データベースを1つしか作成出来なかったりするので、将来的にはScalerプランにアップグレードする可能性あり。
branchの作成
PlanetScale の強力な機能の1つなので使ってみる。
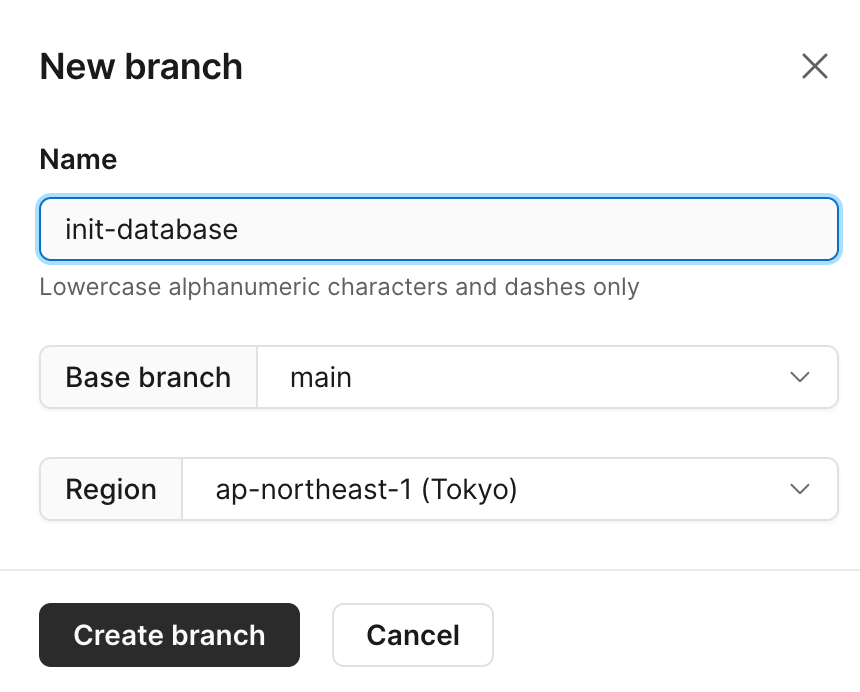
データベースのダッシュボード(Overviewタブ)から「New branch」を押下してbranchを作成する。
とりあえず最初なので init-database という名前で作成。
テーブルの作成
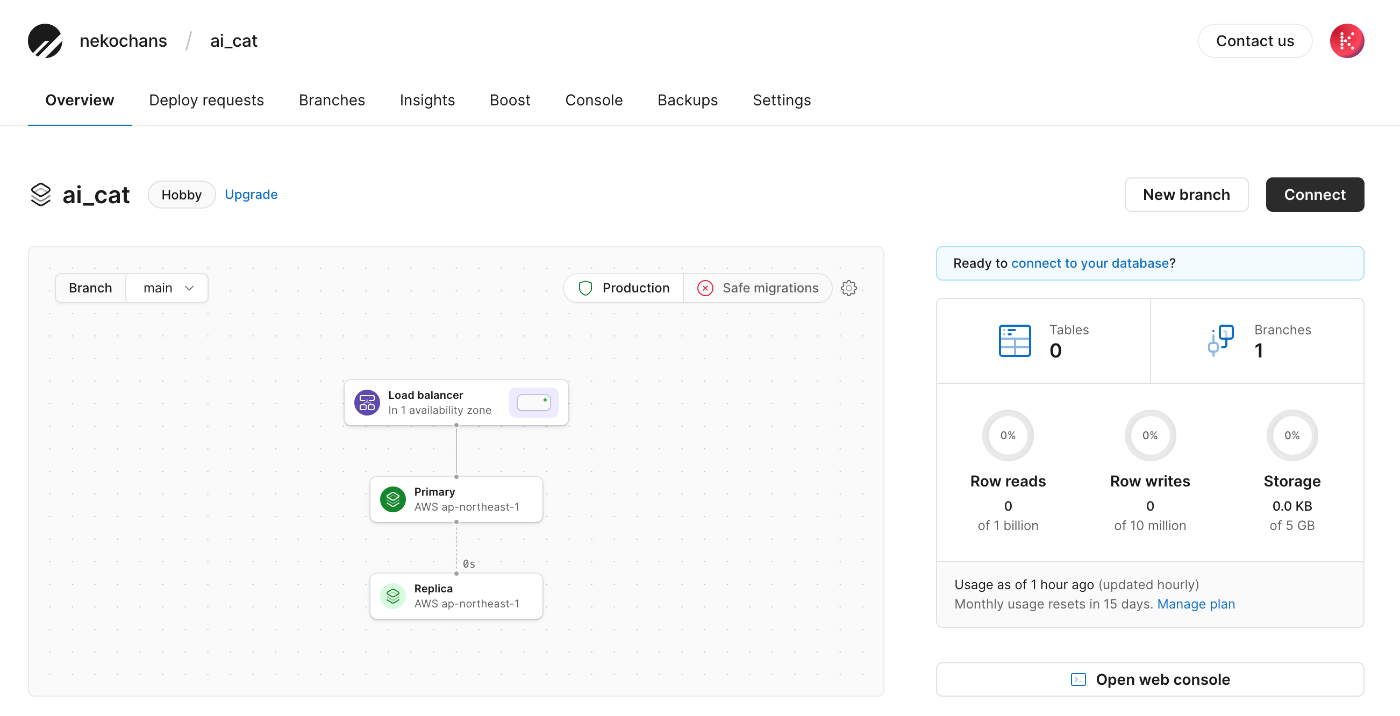
PlanetScale のコンソールから init-database branch を選択してデータベースに接続する。(Connectを押下する)
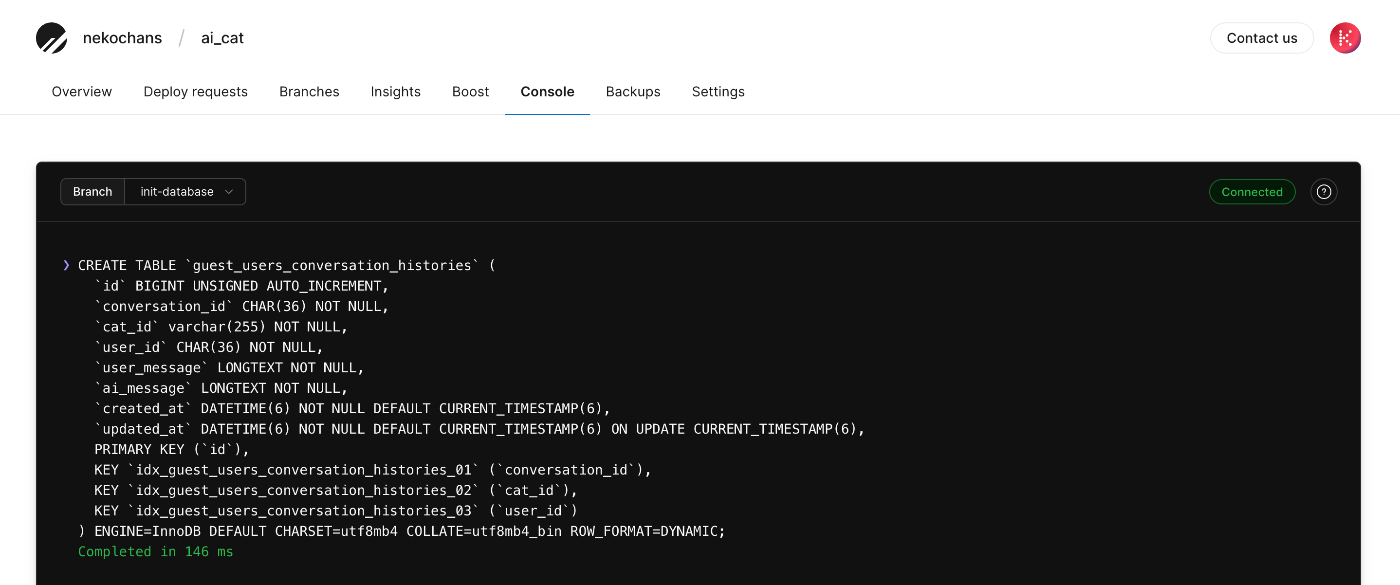
作成するテーブル構造は以下の通り。
CREATE TABLE `guest_users_conversation_histories` (
`id` BIGINT UNSIGNED AUTO_INCREMENT,
`conversation_id` CHAR(36) NOT NULL,
`cat_id` varchar(255) NOT NULL,
`user_id` CHAR(36) NOT NULL,
`user_message` LONGTEXT NOT NULL,
`ai_message` LONGTEXT NOT NULL,
`created_at` DATETIME(6) NOT NULL DEFAULT CURRENT_TIMESTAMP(6),
`updated_at` DATETIME(6) NOT NULL DEFAULT CURRENT_TIMESTAMP(6) ON UPDATE CURRENT_TIMESTAMP(6),
PRIMARY KEY (`id`),
KEY `idx_guest_users_conversation_histories_01` (`conversation_id`),
KEY `idx_guest_users_conversation_histories_02` (`cat_id`),
KEY `idx_guest_users_conversation_histories_03` (`user_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin ROW_FORMAT=DYNAMIC;
これは https://zenn.dev/keitakn/scraps/49eb2616e82eb9 で進めているアプリケーションの人間とAIねこの会話を記録する為のテーブル。
このテーブル構造の詳しい説明は 会話履歴をPlanetScaleのDBに保存 のコメントで説明している。
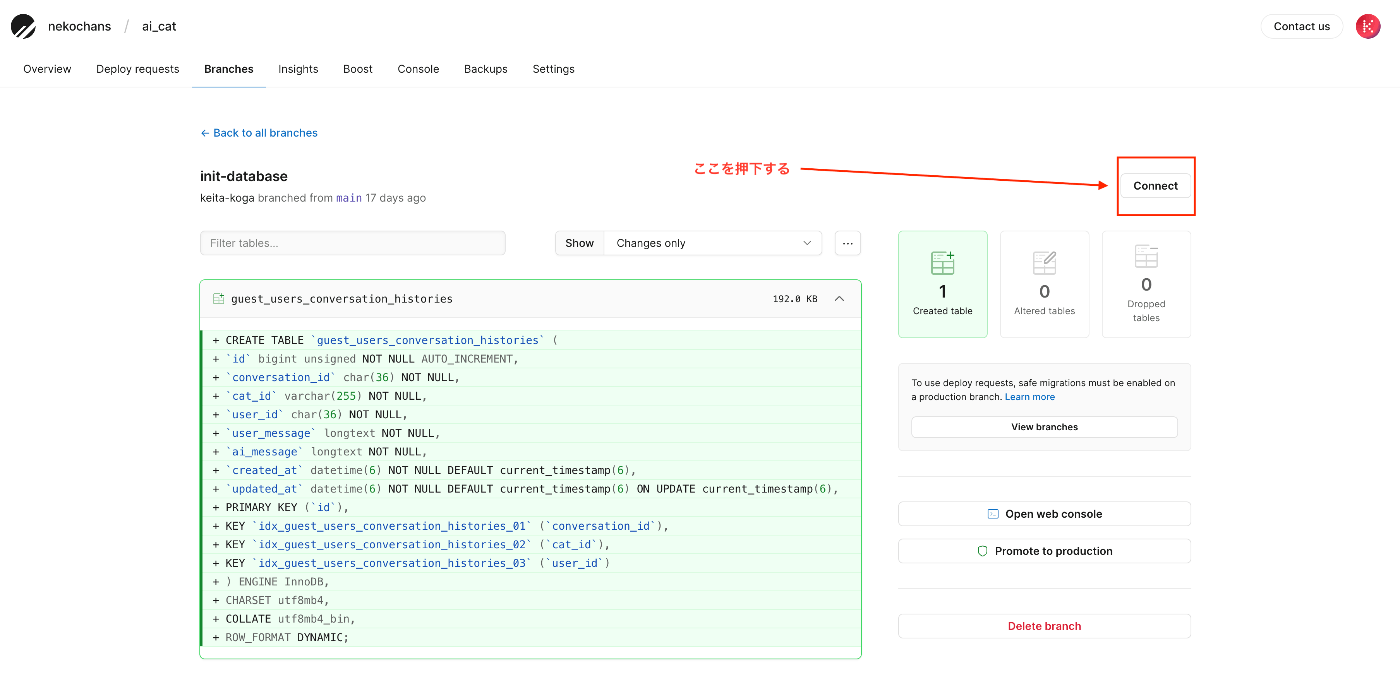
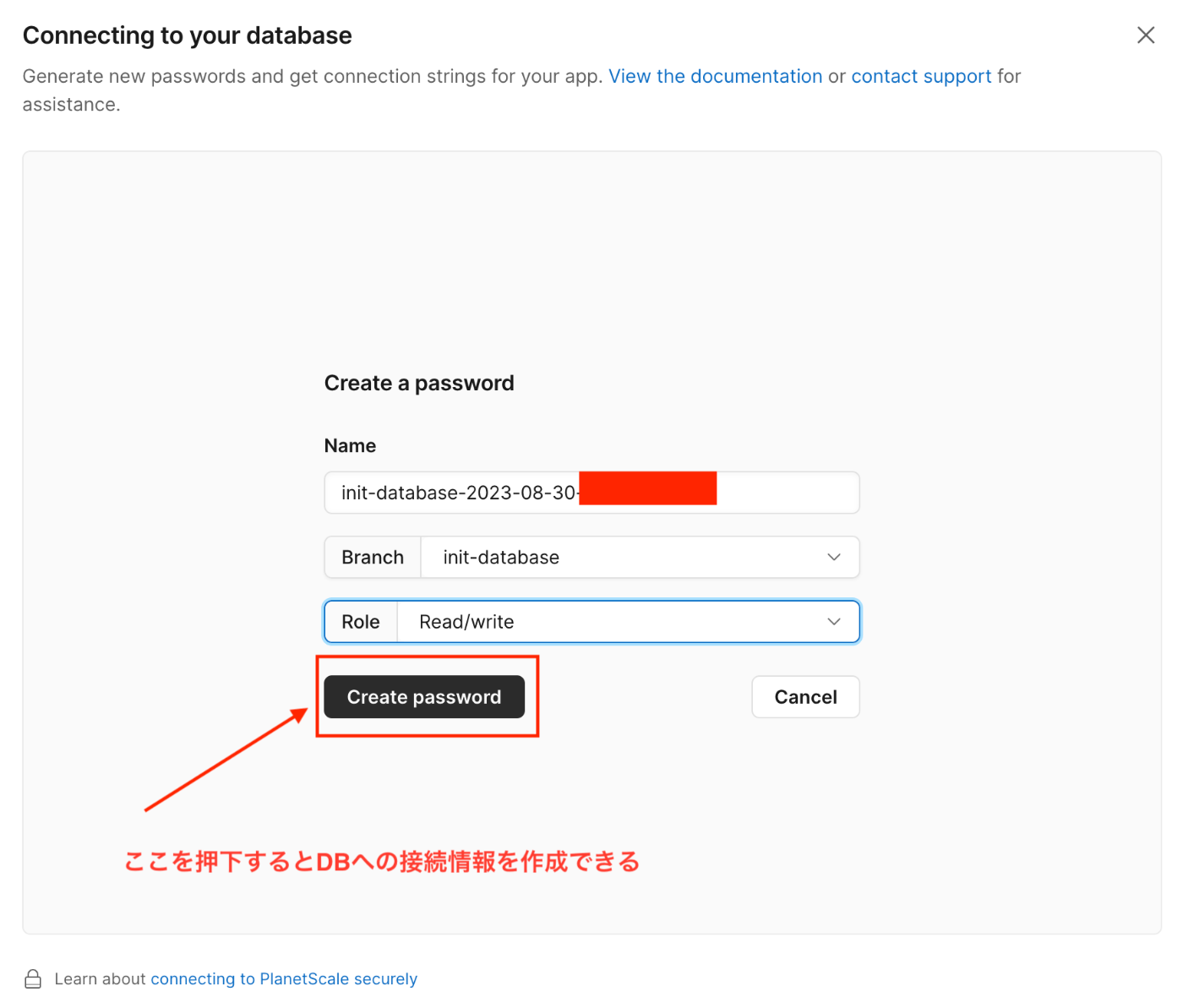
ちなみにDBへの接続情報は Branches タブから対象のBranchのページに遷移して「Connect」ボタンを遷移して作成する。
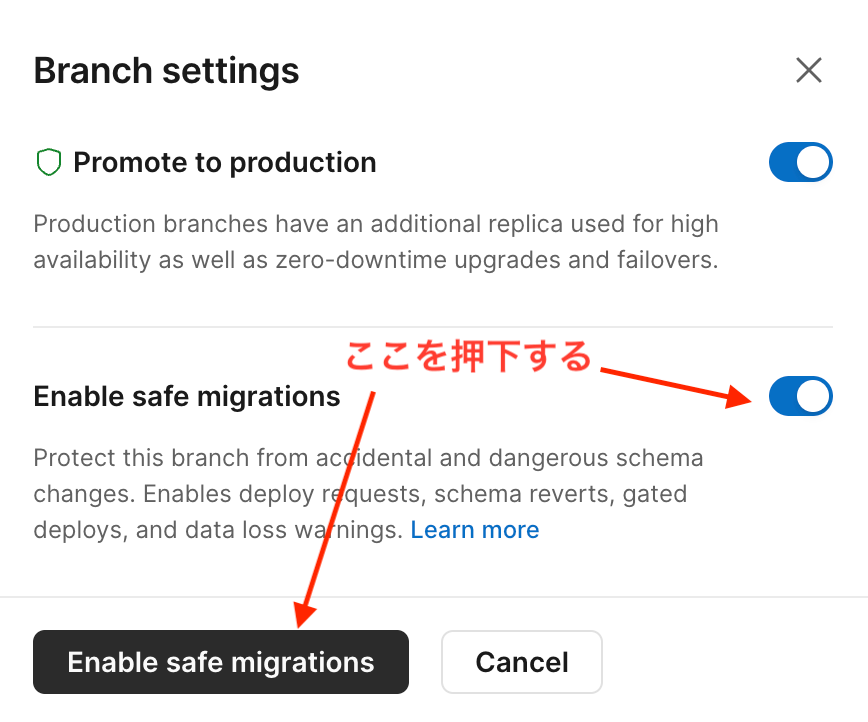
Safe Migrations機能を有効にする
個人的にはPlanetScaleを利用する一番のメリットがこの機能を利用出来るようになる事だと思う。
詳細は下記の通り。
要約すると以下の通り。
- ゼロダウンタイムでのスキーマ変更が可能になる
- 安全なスキーマの巻き戻しが可能になる
- 本番のSchema変更はデプロイリクエストが必須になるので、間違ったSchema変更が起きにくい
デプロイリクエストはGitHubのプルリクエストのような機能でプルリクエストを用いた開発フローをデータベースの世界で実現出来るようになる。
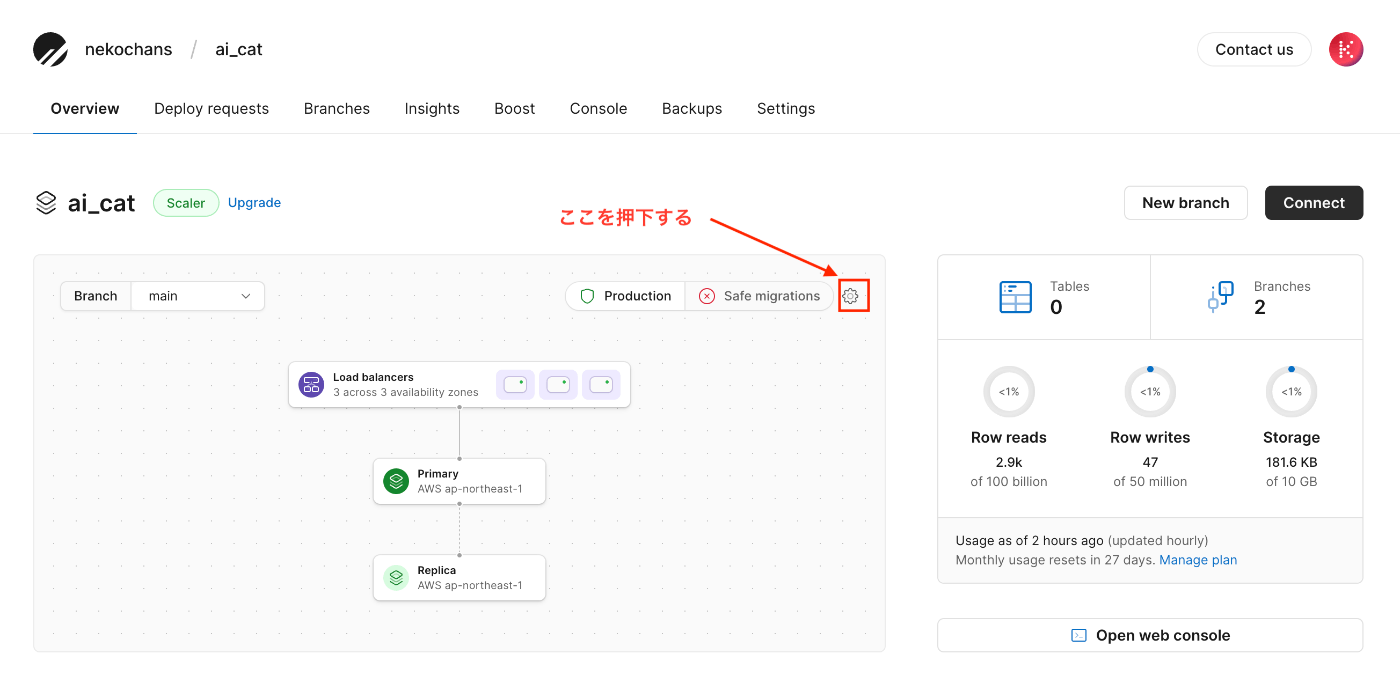
デプロイリクエストの作成
-
Branchesタブから対象のBranchに移動する
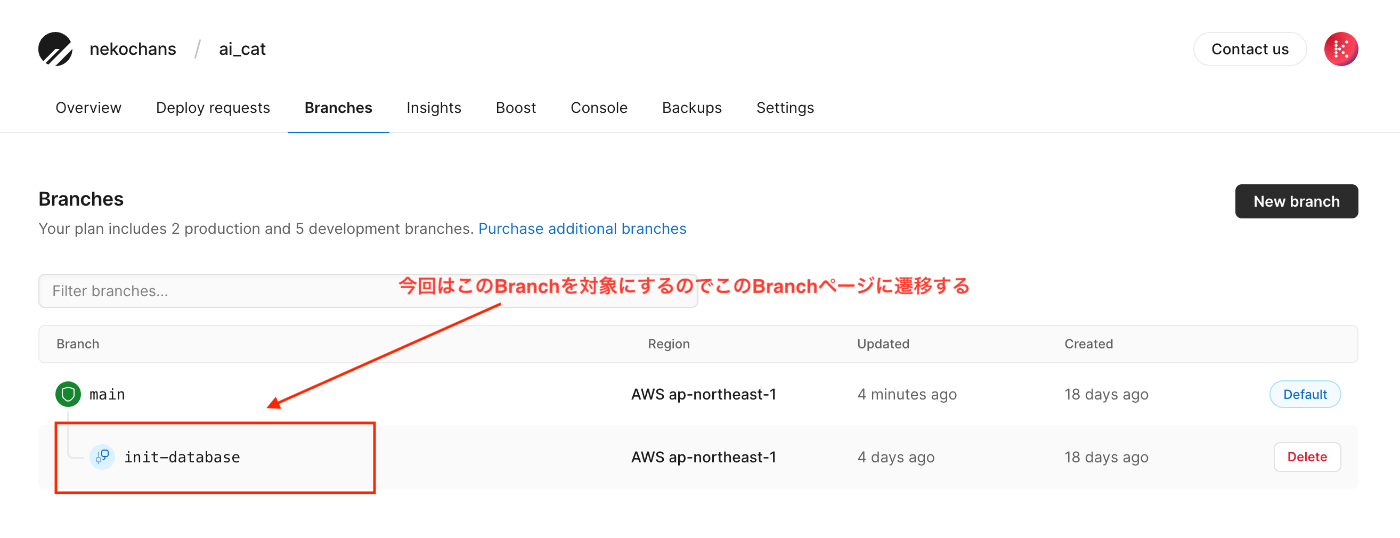
- デプロイリクエストを作成する
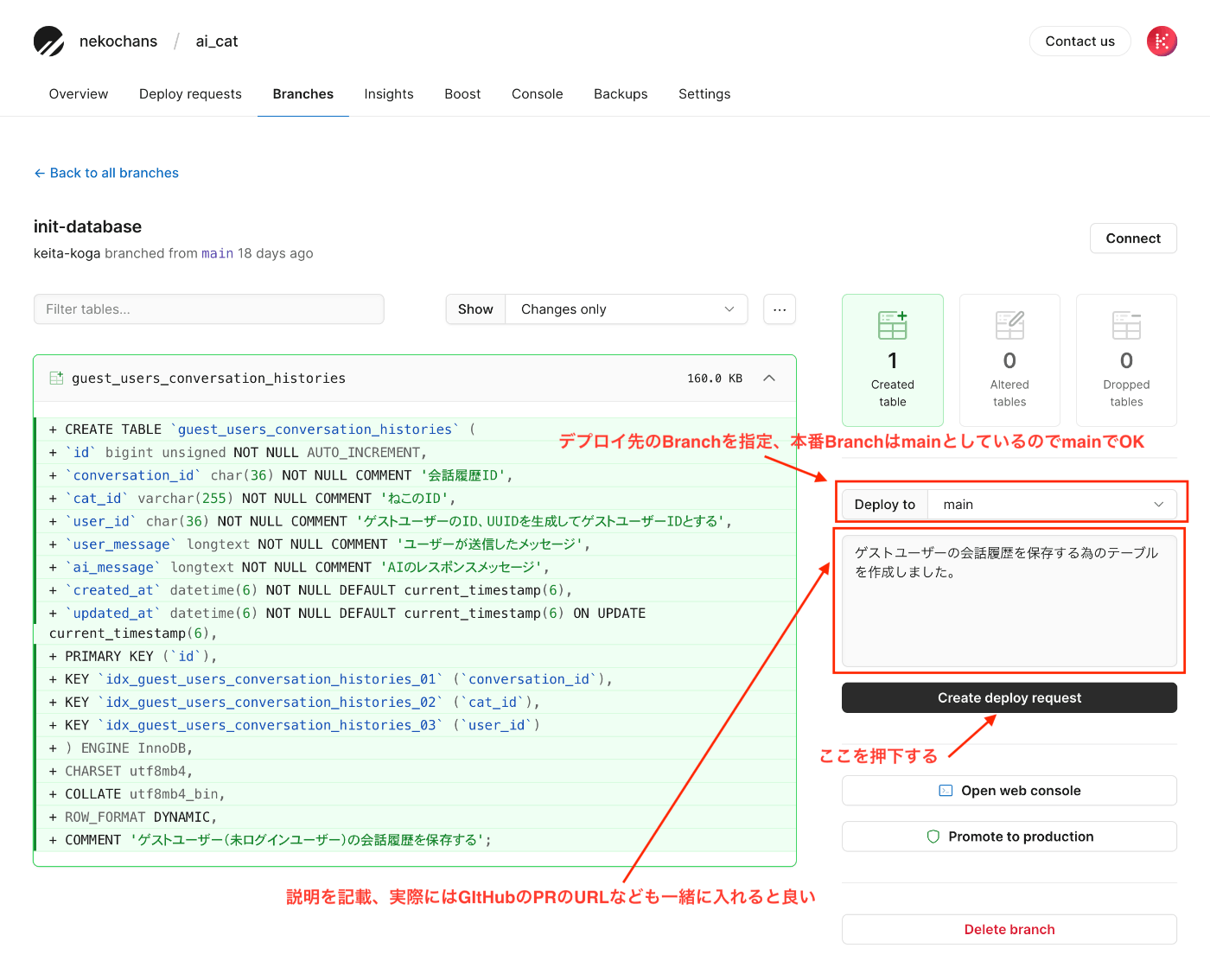
- デプロイリクエストを確認
以下のようにデプロイリクエストが確認出来ます。
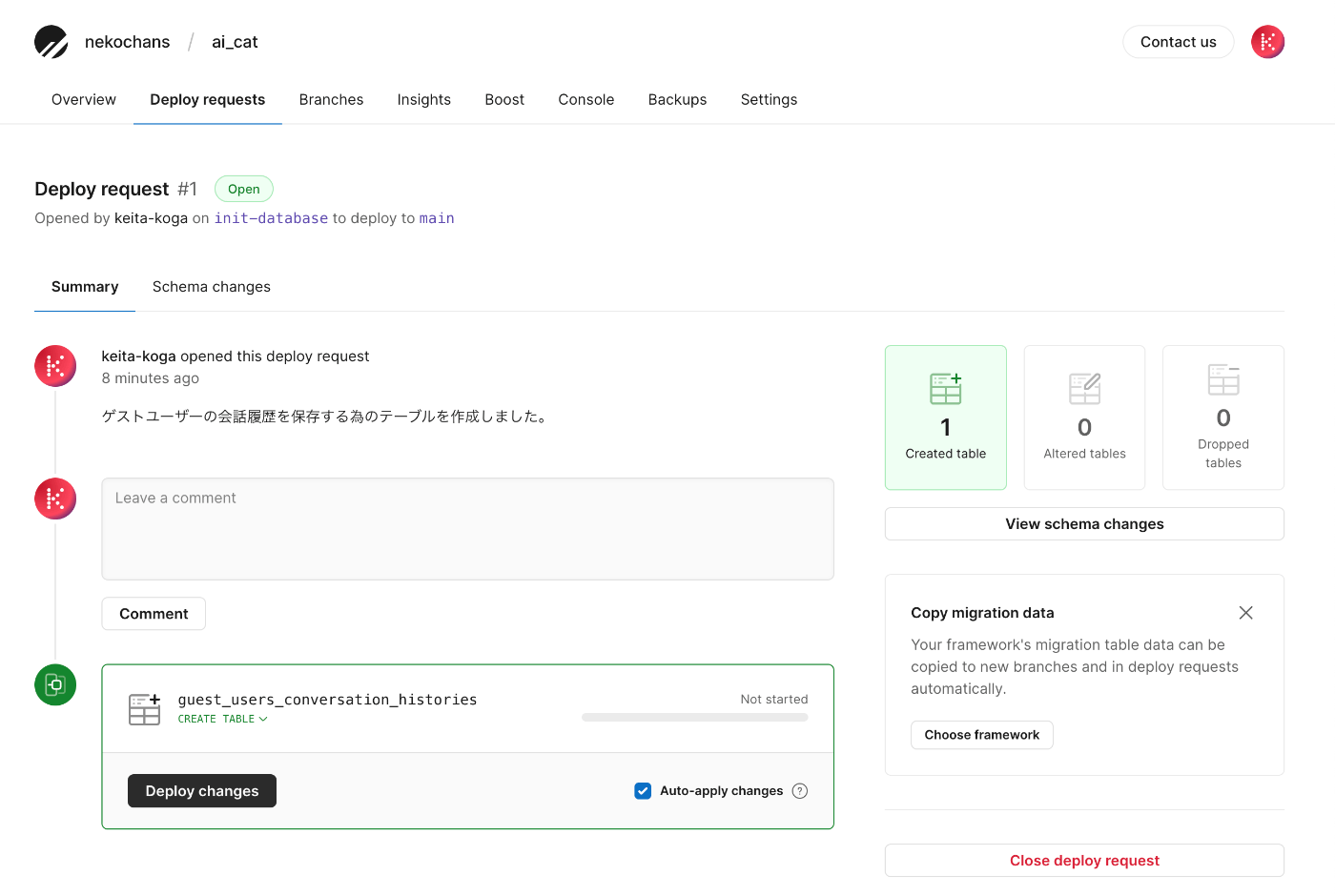
GitHubを使っている人なら何となく分かると思いますが、Schema changesタブからコメントを残したり、PRのApproveを行う事が可能。
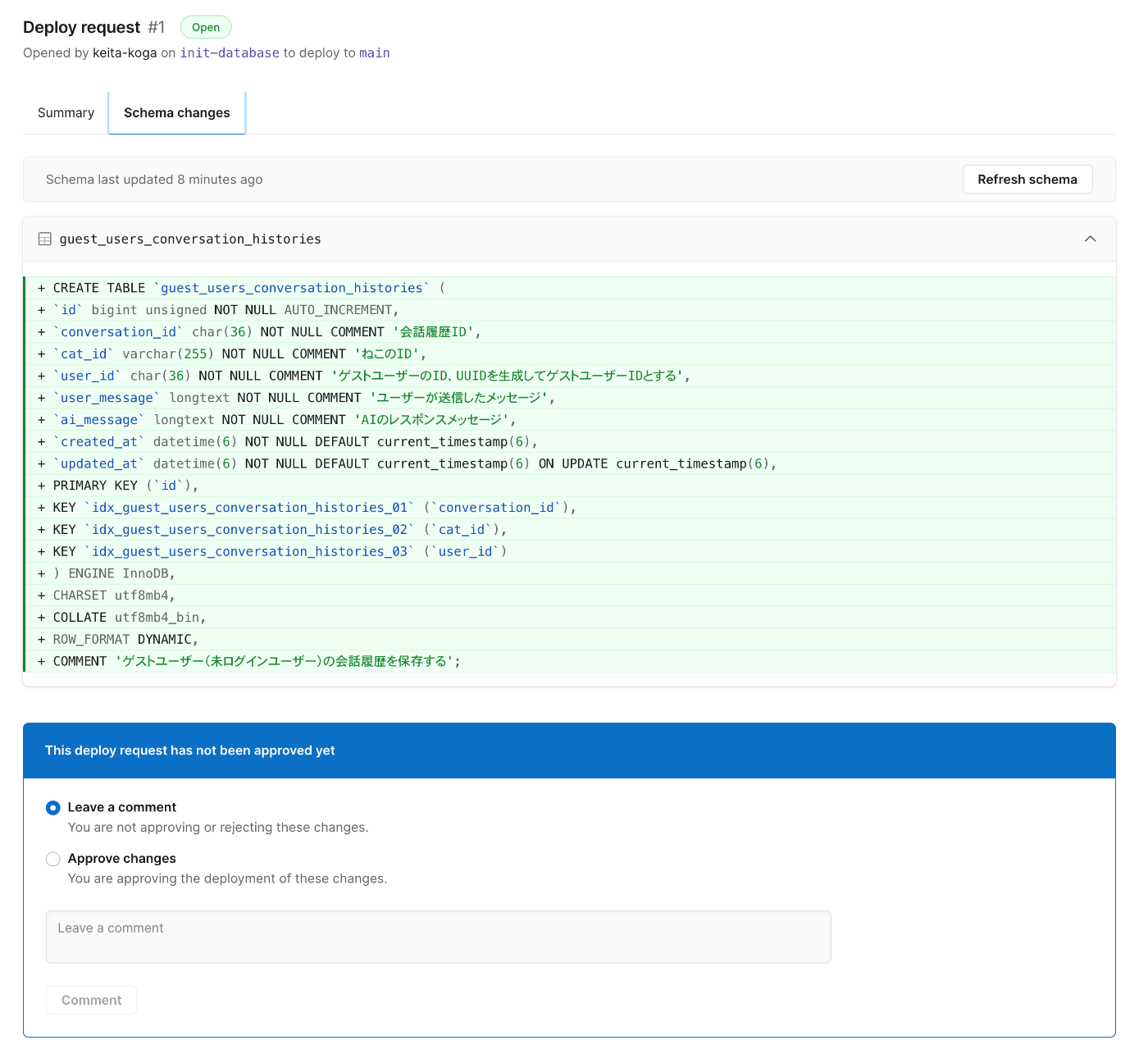
- デプロイリクエストを反映する
「Deploy changes」を押下すると対象Branchに反映されます。
- デプロイリクエストが反映されたか確認
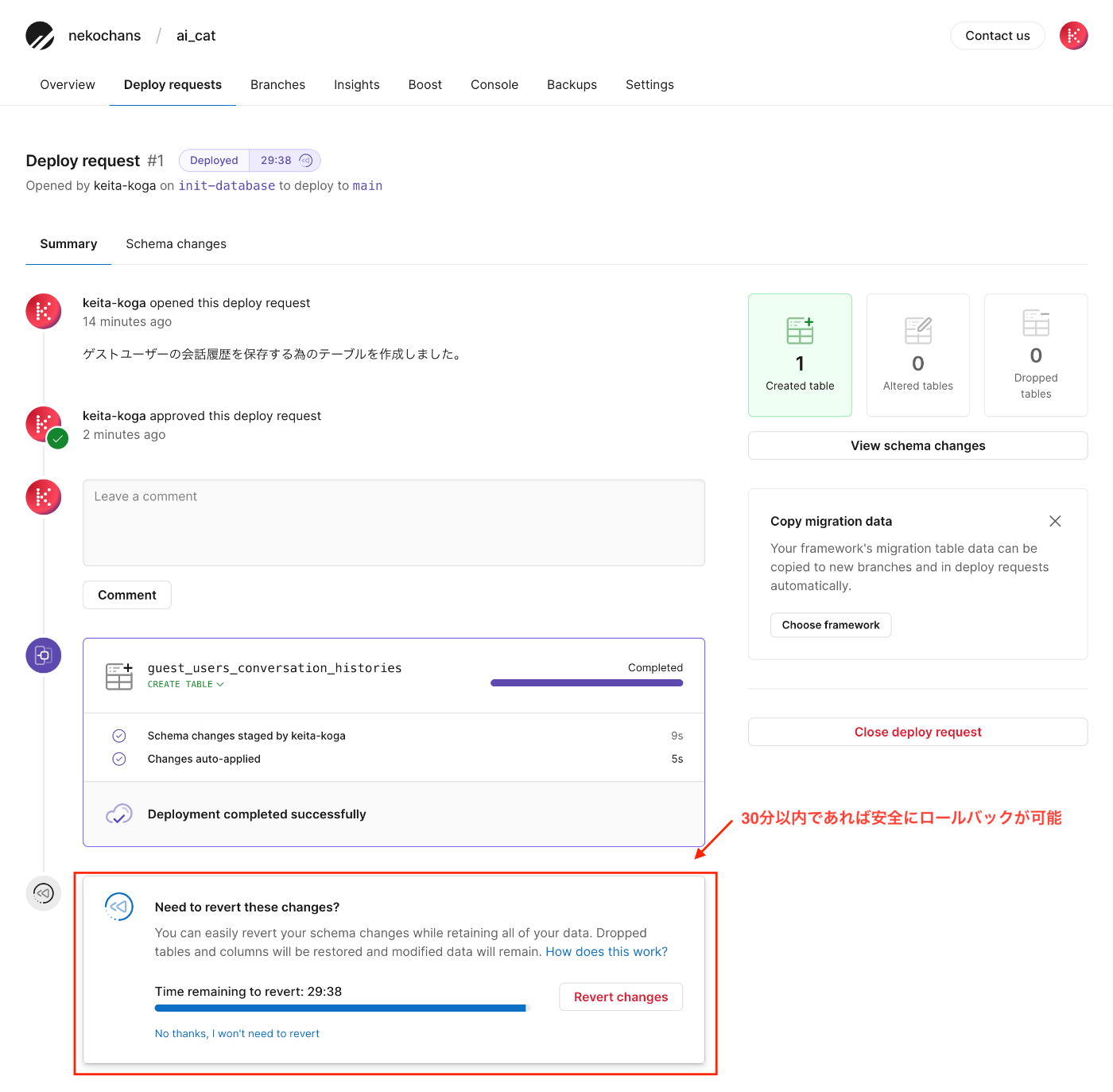
「Deploy changes」を押下してしばらくすると以下の画面が表示される。
ここに記載されている通り、30分以内であればロールバックが可能なので、この間に動作確認を実施する。
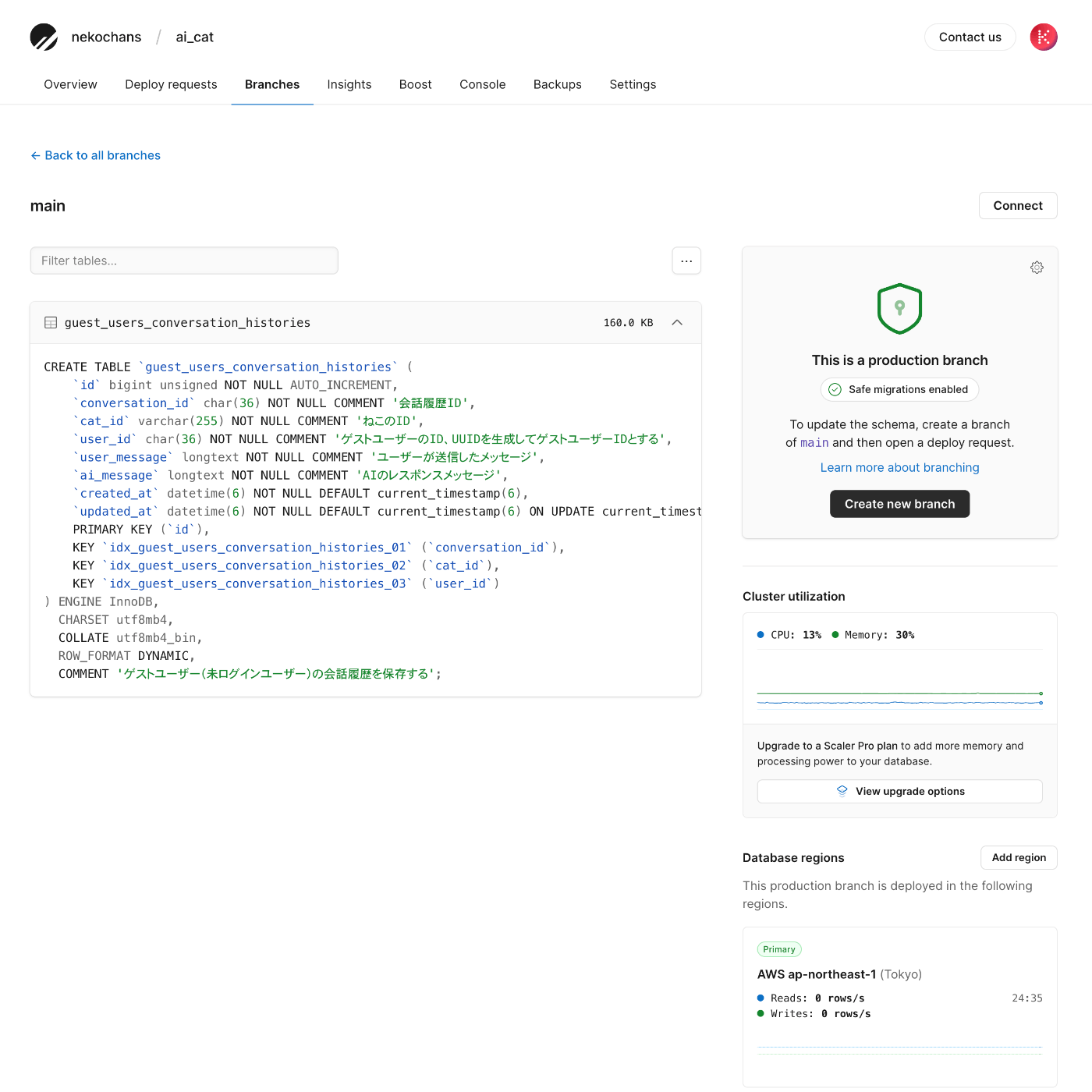
main branchを確認すると正常に反映されている事が確認出来る。
CLIツールのインストール
WebコンソールからでもDBの操作は可能だが若干使いにくいのでCLIツールを利用する事を推奨する。
インストール方法は以下のドキュメントを参照。
以下を実行してバージョン情報が返ってくればインストール成功。
pscale version
pscaleコマンドメモ
# 認証(一番最初にこれを実施する、ブラウザが立ち上がる)
pscale auth login
# organizationsの一覧を取得
pscale org list
# organizationsを切り替える
pscale org switch $ORG_NAME
# データベースの一覧を表示
pscale database list
# データベースに接続(DB名 `ai_cat`, Branch名 `init-database` に接続する場合)
# 下記のコマンド実行後は普通にSQLを使えるようになる
pscale shell ai_cat init-database
より詳しい内容に関しては下記を参照
実際の運用について
Scalerプランだと複数のDBが作成可能だがとりあえず以下の運用で行く事にする。
まず以下の2つのProductionブランチを用意する。
-
main本番用 -
stagingステージング用
スキーマの変更時はまず最初に staging ブランチにデプロイリクエストを送る。
本番反映時に staging ブランチから main ブランチにデプロイリクエストを送る事で本番反映を実施する。