🔖
Kaggle RSNA 2022 1st Place Solution

RSNA 2022 1st Solution
モデル構造
- 2ステージのモデル
- セグメンテーションと、分類問題を別個に解いている
- Stage1
- 3D semantic segmentation
- Stage2
- 2.5D w/ LSTM classification
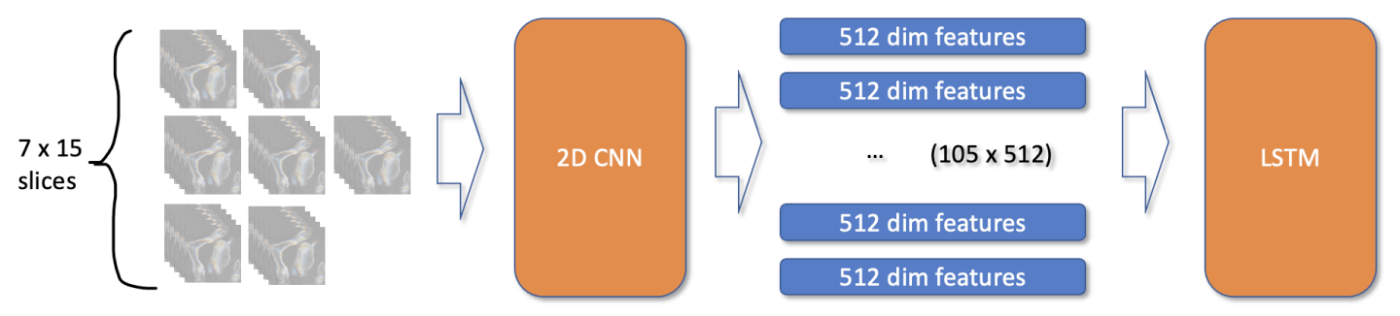
- 二種類の classification model を作成した
3D semantic segmentation
- 87 サンプルの 3D マスクで学習した
- 少数サンプルだったが十分だったのこと
- 入力
- 128x128x128 の学習データ
- モデル
- EfficientNetV2 + UNet
- 出力
- 7チャンネルの出力
- 学習したモデルが予測する3Dマスクは後段のタスクで使用する
Classification model
- 各脊椎(vertabrae)の3Dマスクを予測した
- 1枚の3D画像から7箇所の脊椎をクロップすることができる
- crop 内に複数の脊椎が映ることも合ったが大丈夫だったとのこと
- 2k の学習データに対して7箇所をそれぞれ切り出すので、合計14k サンプルが作成される
- 入力
- 128x128x30
- z軸方向に15スライス取り出して、各スライスに対して±2スライス前後のものを取り出して入力情報を作成する
type-1
- 14k 3D 学習データがあって、単純には 3D CNN を使用するのがよさそうだがそれは有効ではなかったようだ
- そのため 3D CNN ではなく 2.5D CNN を使用した
- 2.5D とは各スライスを concat したものを使用しているという意味
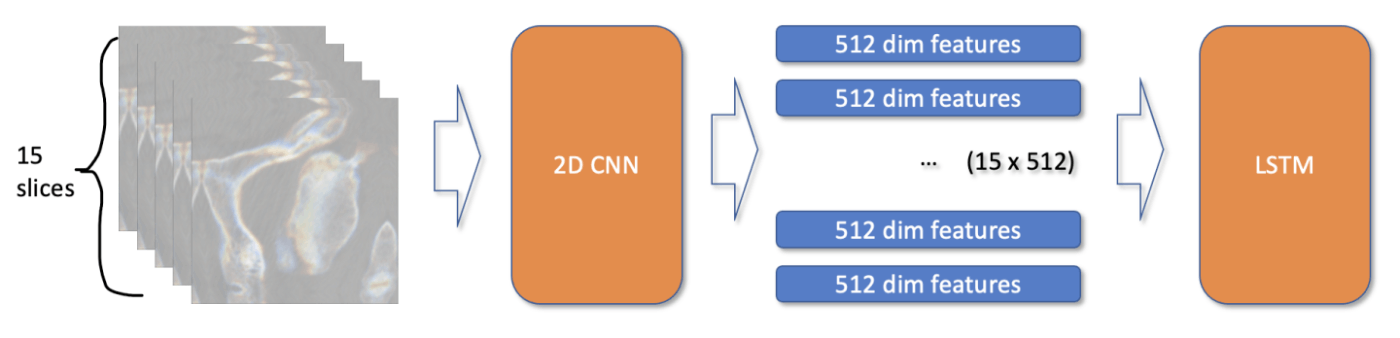
- 入力
- 15スライスを CNN に入力し、各スライスに対応した特徴量を抽出する
type-2
雑記
データ構造
-
[train/test]_images/[StudyInstanceUID]/[slice_number].dcm- StudyInstanceUID : 各 patient スキャンに個別のID(患者IDに対応していない)
- 気持ち的には
train_images/patient_id/scan_id/slice_number.dcmのようなもの
-
segmentations- 学習データの一部にアノテーションされている pixel レベルの annotation データ
- 3D Unet で自動アノテーションされている
- nifti データでファイル名が StudyInstanceUID を持っている
- train データの中で segmentation 情報を持っているものは一部なので、適宜 DataFrame のマージに気をつける
- 学習データの一部にアノテーションされている pixel レベルの annotation データ
Stage 1 (notebook)
データ
- Dataset
- 128x128x128 のデータをどのように作成しているのかは以下の通り。
- 今回は
StudyInstanceUID以下のデータから 128 枚を取得するカラクリはnp.quantileを使用している - ディレクトリ以下にファイルが10個あってそこから5個取りたいときは、0, 2, 4, 7, 9 と間引いて取ってくるようにして、5個未満の際には重複して取ってくるようにしている。こうすることで(データの重複はあれど)128次元の深さを確実に担保できるようになる
>>> np.quantile(list(range(10)), np.linspace(0, 1, 5)).round()
array([0., 2., 4., 7., 9.])
>>> np.quantile(list(range(2)), np.linspace(0, 1, 5)).round()
array([0., 0., 0., 1., 1.])
モデル
- segmentation model を作成するときは
timmのfeatures_only=Trueを使用する- https://huggingface.co/docs/timm/feature_extraction
- モデルの中間特徴量を最大5個まで取得することができるオプション。Unetを作成するときに重宝する
- 今回は encoder に
resnet18d、 decoder に Unet を使用している
- 損失関数は binary dice loss を使用している
- エポックを回すときに
train_func、valid_funcという関数を作成している- モデル、DataLoader などを引数に取っている(train のほうは optimzer, scaler も取る)
- スケジューラーに
torch.optim.lr_scheduler.CosineAnnealingWarmRestartsを使用している
Stage2 notebook
- 3D segmentation model を stage-1 で作成しているので、学習データ全体に対してもマスクを作成することができるようになる
- Stageに分けているのは、そもそも 3D マスクが全学習データに対して与えられていないことにも起因すると思われる
- 予測マスクを使ってクロップ(対象部分だけを抽出)できるようになる
モデル
- LSTM は
torch.nn.LSTMを使用している
self.lstm = nn.LSTM(hdim, 256, num_layers=2, dropout=drop_rate, bidirectional=True, batch_first=True)
- config
- image_size = 224
- n_slice_per_c = 15
- in_chans = 6
- まず
encoderに通して出力する - 出力は
viewを使って LSTM で扱える形状にする-
viewは reshape みたいなもん - 自分だったら直接 encoder の出力をそういう形にしてしまっているころだが、そうではなくてモデルの出力の後処理として入れれば良いのだなと学んだ
-
def forward(self, x): # (bs, nslice, ch, sz, sz)
bs = x.shape[0]
x = x.view(bs * n_slice_per_c, in_chans, image_size, image_size)
feat = self.encoder(x)
feat = feat.view(bs, n_slice_per_c, -1)
feat, _ = self.lstm(feat)
feat = feat.contiguous().view(bs * n_slice_per_c, -1)
feat = self.head(feat)
feat = feat.view(bs, n_slice_per_c).contiguous()
return feat
- その他
- AdamW, GradScaler
- torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, n_epochs, eta_min=eta_min)
- train_func の定義は以下の通り
def train_func(model, loader_train, optimizer, scaler=None):
model.train()
train_loss = []
bar = tqdm(loader_train)
for images, targets in bar:
optimizer.zero_grad()
images = images.cuda()
targets = targets.cuda()
do_mixup = False
if random.random() < p_mixup:
do_mixup = True
images, targets, targets_mix, lam = mixup(images, targets)
with amp.autocast(): # ここらへんで GradScaler の使用
logits = model(images)
loss = criterion(logits, targets)
if do_mixup:
loss11 = criterion(logits, targets_mix)
loss = loss * lam + loss11 * (1 - lam)
train_loss.append(loss.item())
scaler.scale(loss).backward() # scaler で backward
scaler.step(optimizer) # step
scaler.update() # update
bar.set_description(f'smth:{np.mean(train_loss[-30:]):.4f}')
return np.mean(train_loss)
- スケジューラも含めた学習ループは以下の通り
- スケジューラー自体、学習率を調整するものなので train_func とかには関係してこなくて、各エポックの頭で(後ろでもいいと思うが)
stepを呼び出すと学習率が自動で調整されるものとなる
- スケジューラー自体、学習率を調整するものなので train_func とかには関係してこなくて、各エポックの頭で(後ろでもいいと思うが)
scheduler_cosine = torch.optim.lr_scheduler.CosineAnnealingWarmRestarts(optimizer, n_epochs, eta_min=eta_min)
print(len(dataset_train), len(dataset_valid))
for epoch in range(1, n_epochs+1):
scheduler_cosine.step(epoch-1)
print(time.ctime(), 'Epoch:', epoch)
train_loss = train_func(model, loader_train, optimizer, scaler)
valid_loss = valid_func(model, loader_valid)
...
感想
- どうやって 128次元の深さを担保しているのかと思ったが、案外適当でいいのだと安心した
-
train_funcみたいなものを作ったほうが見やすいなと思った
Discussion