O'Reilly Online Learningの積読を解消
このスクラップは?
福利厚生で O'Reilly Online Learning 使えるが、積読がなかなか消化されないので、消化のために1日 15分で積読の1章を読んで3行サマリを書いていく。 1 分読んで、なんでもいいのでメモる。
Datadog Cloud Monitoring Quick Start Guide
Chapter 1: Introduction to Monitoring
- ソフトウェアシステムの監視の重要性
- 監視のユースケース
- popular な監視ツールと監視に関わる概念と用語の紹介
Chapter 2: Deploying the Datadog Agent
- Datadog Agent は Cloud, OS 上の環境の両方を監視できる
- Datadog Agent の主要なコンポーネント: Collector(15秒ごとにメトリックを収集), Forwarder(HTTPS経由でDatadogバックエンドに送信), DogStatsD(DatadogによるStatsDの実装で、デフォルトポート8125で実行されるメトリクスの収集及び集計デーモン)
- 構成オプションや一般的な使用例を説明
Chapter 3: The Datadog Dashboard
- Dashbord の重要な機能: infra list, event, metric explorer, dashboards, integrations, monitors, advandec feature
- event: datadog agent の再起動や新しいコンテナのデプロイなどのレベルのもの
- 2種のDashboard: time board(時系列にメトリクスを並べる), screen board(時間の制約がない)
Chapter 4: Account Management
- ユーザー管理、ロールを使用したカスタムアクセス
- organization: インフラの一部&その上のアプリの監視を分離できる
- ベストプラクティス
- 複数 organization で production 環境の監視をクリーンに
- カスタムユーザーロールで最小限の権限をもたせる
- SSO使う
- programmatic access には service account を使う
Chapter 5: Metrics, Events, and Tags
- Datadogが大きく依存する2つの構成要素の「メトリクス」と「タグ」の定義方法について説明
- Datadogが監視するインフラorアプリ内のアクティビティである「イベント」の説明と他のチャネルへの転送方法を説明
- タグによるメトリクスやイベントのグループ化&検索方法を説明
Chapter 6: Monitoring Infrastructure
- 基本的なタイプの1つ、インフラ監視について説明
- Datadog はホストレベル、コンテナレベルの両方を監視する機能を提供
- Lambda などインフラ関係しないサーバーレスコンピューティングリソースも監視できる
Chapter 7: Monitors and Alerts
- Datadog モニターを作成 & メンテ(マニュアル、as code)する方法を説明
- アラート通知をする方法
- メンテナンス期間やシャットダウン期間中にダウンタイム機能を効果的に使用
Section 2: Extending Datadog
- すぐに利用できる標準監視機能があり、Agent をインストールすればすぐに利用できるが、包括的に監視するにはカスタムメトリクスで拡張する必要ある
- 8-11章で拡張のためのインテグレーションを説明
Chapter 8: Integrating with Platform Components
- Platform Components についても一般的なものは標準で監視できるが、できないものはカスタムチェックオプションがある
- Platform = クラウドサービスのことだけでなく、Proxy(NGINX, Apache, ...), 各種DBMS などミドルウェアも含む
- スクリプトを
/etc/datadog-agent/check.dにインストールすることでカスタムチェックを実装できる
Chapter 9: Using the Datadog REST API
- Datadog HTTP REST API を使ってDatadog と統合する方法を説明
- API を使って、メトリクス or イベントを Datadog に publish するだけでなく、Datadog からデータを取得してレポートツールに読み込むなどもできる
- 既存のインテグレーションが使える場合は、APIを使用した独自コード実装は避けるべき
Chapter 10: Working with Monitoring Standards
- 監視における標準実装である SNMP, JMX, StatsD を用いた拡張 option を説明
- SNMP(ネットワークの監視), JMX(Javaアプリの監視), DogStatsD(任意のメトリクスの監視)
- 利用は計画的に
- SNMPでネットワークデバイスを監視するとメトリックが膨大になり、取捨選択ちゃんとする必要ある
- JMXはアプリの動作を manipulate するためにも使えるが、監視インフラ側でそういうことはしないほうが良い
- DogStatsDはサービスポートへのアクセス以外に認証を必要としないので実行環境のセキュリティを確保する必要ある
Chapter 11: Integrating with Datadog
- API や DogStatsD を使って Datadog を他のアプリと統合する方法を説明
- クライアントは公式のものとコミュニティのものがある
- 例として、一部のアプリデータをDatadogにpusblishしつつ、Zabbixと統合する方法を説明
Chapter 12: Monitoring Containers
- Docker や Kubernetes 上でログを収集する方法を説明
- Live Container 機能で Kubernetes のリソース各種を見ることができる
- コンテナから収集された情報を検索して見る方法を説明
Chapter 13: Managing Logs Using Datadog
- ログ集約とインデックス作成機能について説明
- インデックス: ログをグルーピングする機能の模様 https://docs.datadoghq.com/ja/logs/log_configuration/indexes/
- ログのフィルタリングや機密データのスクラビング(masking)方法を説明
- ログのアーカイブや検索方法について説明
Chapter 14: Miscellaneous Monitoring Topics
- 最近利用可能になったモニタリング機能の AppDynamics, Security Information and Event Management(SIEM)、Catchpoint などについて説明
- Synthetic monitoring を使うとロボットユーザーによるシミュレーションができる
- Security rule の定義方法について説明
Chapter 1. Optimization and Performance Defined
- この本はコードに適用するパフォーマンスのヒントのクックブックではなく、パフォーマンスエンジニアリングを生み出すためのさまざまな側面に焦点を当てる
- JVMパフォーマンス・チューニングは実験科学であることを説明
- 一般的なパフォーマンス指標と、パフォーマンスグラフの読み取り方について説明
Chapter 2. Overview of the JVM
- JVM が Java を実行する方法の概要を説明
- HotSpot (JIT など)やメモリ管理(GC など)を説明
- JVM の代表的な実装(Oracle, Zulu, Android, ...)やモニタリングツール(JMX, Java agents, JVMTI, The Serviceability Agentなど)について説明
Chapter 3. Hardware and Operating Systems
- Java アプリケーションを最適化するに当たって必要なハードウェアと OS の知識を説明
- CPU関連: CPU キャッシュ, Translation Lookaside Buffer(TLB), 分岐予測 & 投機的実行, Hardware メモリモデル(Java Memory Model←12章で後述)
- OS関連: スケジューラ, 時間の扱い, コンテキストスイッチ,
JVM ではシングルスレッドのアプリコードでも追加のプロセッサコアが利用できる、と書いてあったので後で調べる
Chapter 4. Performance Testing Patterns and Antipatterns
- パフォーマンステストのベストプラクティスとアンチパターンについて説明
- パフォーマンスチューニングでどこに力を注ぐべきかを決める時の3つの黄金律
- 気になるものを特定&測定する方法を見つける
- 簡単に最適化できるものではなく、重要なものを最適化する
- まずは big point をプレイする
- アンチパターンのリストと、その多くが無意識の思い込みに基づいた認知バイアスによって起こることを説明
Chapter 5. Microbenchmarking and Statistics
- JVM の動的性質によりパフォーマンス数値を扱うのは難しく、特にマイクロベンチマークは難しい
- 動的性質の理由例: JIT コンパイル、GC
- マイクロベンチマークのデファクトツールの JMH を説明
- JVM パフォーマンスの統計に関する内容を説明
Chapter 6. Understanding Garbage Collection
- Java GC を支える基本理論と、制御が難しい理由を説明
- HotSpot のランタイムシステムの基本機能ついて紹介
- HotSpot の最も単純なコレクターである並列コレクターを紹介
Chapter 7. Advanced Garbage Collection
- 適切なコレクタを決定する際のトレードオフについて概説
- 基礎となる理論としてJVMセーフポイントとTri-Color Markingを説明
- 上記これらのアイディアを実装する様々な最新のGCアルゴリズムを紹介
Chapter 8. GC Logging, Monitoring, Tuning, and Tools
- GCチューニング技術の概要を説明
- 割当率の分析: GCを調整してパフォーマンスを向上させられるかどうかを判断するのに重要
- Parallel GC, CMS, G1 に対する基本的なチューニング方法を説明
Chapter 9. Code Execution on the JVM
- JVM のバイトコードインタープリターの基本について説明
- 実行可能コード生成の代替アプローチの AOT と JIT について説明
- HotSpot JIT について説明
Chapter 10. Understanding JIT Compilation
- JIT コンパイルサブシステムの基本を説明
- 最適化の一部を説明
- 最適化の効果を JITWatch で観察する方法をあわせて説明
詳解 Terraform 第3版 ―Infrastructure as Codeを実現する
1章 なぜTerraformを使うのか
- IaC ツールの整理。選択にあたったトレードオフを挙げて、各ツールの違いを解説
- Dockerなどのサーバーテンプレートと組み合わせる場合、プロビジョニングツールである Terraform, CloudFormationなどがマッチ
6章 シークレットを管理する
シークレット管理の第1ルールは次のとおりです。
シークレットをプレーンテキストで保存しない
シークレット管理の第2ルールは次のとおりです。
シークレットをプレーンテキストで保存しない
大事
先頭にスペースを入れたコマンドをヒストリファイルにシークレット情報を残さないようにする設定あるの、知らなかった。
The Staff Engineer's Path
Intro
- 3 つの柱
- Big-picture thinking
- 全体像を考える
- 現在の時間を超えて考える
- 例: 1年に渡るプロジェクトを開始、3年以内に会社が必要とするものを予測
- Execution
- プロジェクトはより乱雑で曖昧になる
- 成功のためには、より多くの人が関与、より多くの政治資本、影響力、文化の変化が必要
- Leveling up
- 関係するエンジニアの基準とスキルをアップさせる責任が増す
- 指導による意図的な影響だけでなく、role model としての偶発的な影響もある
- Big-picture thinking
- ベースとなるのは tech knowledge and experience
- だが技術的な知識では不十分
- ヒューマンスキルが必要
- コミュニケーションとリーダーシップ
- 複雑さを乗り越える
- 大局的に見る
- 指導、しポンサー湿布
- 他の人が関心を持てるように問題を組み立てる
- リーダーであるかどうかにかかわらず、リーダとして行動
Chapter 1. What Would You Say You Do Here?
タイトルは重要
ボトムアップで、すべてのアイディアが敬意をもって扱われる、という文化は素晴らしいが
「人々が自分たちが進歩していることを理解できるようにすること、自動的には権限を与えられない可能性のある人々に権限を与えること、そして期待されるコンピテンシー レベルを外部の世界に伝えることです。」
Why Do We Need Engineers Who Can See the Big Picture?
- 単一チームのエンジニアはチームの目標を達成することに集中する可能性が高くなる
- 多くの場合、1つのチームに属するように見える決定が、チームの境界を遥かに超えた影響を及ぼす
- 現状を把握するのと同じくらい重要なのは、自分の決定が将来どのように展開されるかを予測できること
- 1年後、何を後悔するか
- 3年後、今から始めておけばよかったと思うことは何か
- どのプラットフォームを標準化するかなどは微妙で物議を醸すことも多い
- 決定のためにはコンテキストを共有し、他の人がそれを理解できるようにすることが不可欠
Why Do We Need Engineers Who Lead Projects That Cross Multiple Teams?
- 現実のプロジェクトでは一部の責任は誰にも所有されず、その他の責任は2つのチームが負うことになる
- 情報が流れなかったり、混乱して矛盾が生じる
- チームは局所最適解を下すが、ソフトウェアプロジェクトは行き詰まる
- →プロジェクトを進めるために必要なのは、全体に所有権を感じている人
- なぜ TPM(technical program manager) ではだめ?
- TPM はプロジェクトが納期通りに完了することを保証
- スタッフエンジニアはプロジェクトが高いエンジニアリング基準に従って完了することを保証
- TPM には求められず、スタッフエンジニアに求められること
- 技術設計書を書く
- テストやコードレビューのためのプロジェクト標準を設定
- レガシーシステムの内部を深く調査してどのチームがレガシーシステムと統合する必要があるかを判断
Why Do We Need Engineers Who Are a Good Influence?
- スタッフエンジニアはロールモデル
- エンジニアリングの基準はプロジェクトで尊敬されているエンジニアの行動によって決まる
- 例: 標準に何が書かれていてもシニアエンジニアがテストを作成していなければ、他のメンバーにテストを行うように説得できない
- 経験のあるエンジニアは大局的、大規模プロジェクト、良い影響を与える仕事を行うべき
- ただ、シニアエンジニアがコーディングと同時にそれらを実行することはできない
- シニアエンジニアが1日中コードを書くとコードベースは良くなるが、彼らにしかできない他のことはできない
- 技術的なリーダーシップは、職務内容の一部である必要あり
スタッフエンジニアの特性
- マネージャーではなくリーダー
- 直属の部下はいない、周囲のエンジニアの技術スキル向上に関与するが、パフォーマンスは管理しない
- 教えることはリーダーシップの一形態
- 静かに全員のレベルを引き上げる、技術的な方向性を決める、あなたが信頼しているという理由で、他の人々を納得させられる
- 技術的な役割についている
- エンジニアリングがどうあるべきかについて高い基準
- コードや設計のレビューは同僚にとって有益
- 意思決定時にトレードオフを理解し、他の人がそれを理解できるように支援
- 自律性を目指す
- マネージャーから伝えられる情報と同じくらい逆に彼らに伝える
- 自分の時間を守り、構成するのは自分次第
- 優先順位、納期、人との関係性を天秤にかけて、何をするかを判断
- 技術的な方向性をきめる
- 頻繁かつ上手にコミュニケーションをとる
役割を理解する
- 組織のどこ(レポートチェーン)に位置するかを判断する必要がある
- high
- 広い視野、高度で影響力のある情報が得られる
- low レイヤーと比べてマネージャーが使える時間ははるかに少ないので、サポートは少なくなる
- low
- 組織全体に影響を与えるのは難しい
- マネージャーから学ぶことは少ない可能性
- 上司の上司とスキップレベルの会議を行う必要があるかも
- high
Chapter 2. Three Maps
- 3種類の地図を描いていてスタッフエンジニアの仕事と組織の全体像を説明
- A Locator Map: You Are Here
- スコープを理解するにはスコープの外側にあるものを見る必要がある
- →一緒に働くチームが組織内での目的、顧客が誰であるか、自分たちの仕事が他の人々にどのような影響を与えるかを本当に理解していることを確認するのに役立ちます。
- A Topographical Map: Learning the Terrain
- 地形をナビゲート
- 組織の境界、奇妙な政治的境界、注意すべき人
- →チーム間の摩擦やギャップを強調し、コミュニケーションの道を開くのに役立ちます。
- A Treasure Map: X Marks the Spot
- 目的地と途中のチェックポイント
- 長期的な視野を持ち、自分の仕事の目的を評価
- →全員が何を達成しようとしているのか、そしてその理由を正確に理解できるようにするのに役立ちます。
マップの一部の部分は日々の学習によってクリアできるようになりますが、他の部分をクリアするには意図的に取り組む必要があります。この章の中心テーマは、物事を知ること、つまり継続的なコンテキストと何が起こっているのかを把握することの重要性です。物事を知るにはスキルと機会の両方が必要で、見えていないものが見えるようになるまで、しばらく努力する必要があるかもしれません。
これ大切。
The Locator Map: Getting Perspective
新人であることはあなたにとって最高のチャンスです完全に外部からの視点を得るためには必要ですが、スタッフ エンジニアとしては、常にこの視点を持つように努めるべきです。
部外者のように見るテクニック
- エコーチャンバーからの脱出
- 他のチーム・グループのスタッフエンジニアによる仮想的なチームを作ることでより客観的にみれるようにする
- 実際に何が重要か
- 雇用主が目標を達成できるよう支援
- 優先順序は時間とともに変わるので、現時点で何が重要かを理解
- 目標が変化したときは注意
- 顧客は何を気にしているか
- ユーザーが満足していないときは、9は問題ではない
- SLO をクリアいるかどうか以前の問題
- ユーザーが満足していないときは、9は問題ではない
- 以前に解決されているか
- 組織の内外に存在するものを時間をかけて理解
The Topographical Map: Navigating the Terrain
組織再編により、緊密に連携する必要があるグループ間のコミュニケーションが中断される可能性があります。大きな負荷がかかっているチームは、塹壕を築き、障壁を築く可能性があります。新しい上級リーダーは、一夜にして状況を一変させる地震を引き起こす可能性があります。組織内を移動するには (図 2-7を参照)、地形図が必要です。
- 地形図を持たずにミッションを開始した場合の困難
- あなたの良いアイデアは指示されない
- 難しい部分はそこに行くまで分からない
- 何事も時間がかかる
- 組織の計画サイクルの仕組みも影響
- 組織を理解する
- 組織スキルも優れたエンジニアリングの一部
- 組織の文化
- 秘密かオープンか
- 口頭か書面か
- トップダウンかボトムアップか
- 自分の組織がどのように機能する傾向があるかを知っていれば、どう動けばよいかがわかる
- 自分のアイデアを草の根の活動家仲間に伝えて最初に支援を得る
- local のディレクターを説得
- 自分の組織がどのように機能する傾向があるかを知っていれば、どう動けばよいかがわかる
- 素早い変化か、それとも意図的な変化か
- 迅速な組織
- すぐに価値を示す増分パスが必要になる
- 慎重な組織
- 計画全体を熟考したことを示す必要がある
- →口頭文化や文書化とも密接に関係
- 迅速な組織
- バックチャンネルまたはフロントドア?
- 組織では何が一般的であると考えられているかを理解
- 割り当てられているか、利用可能か
- 人員が不足し、過重労働担っている場合、既存の製品ロードマップにない新しいアイデアの足がかりを見つけるのに困難になる
- 最も成功する可能性が高いのは、一人、または少しの助けを借りて作業でき、忙しい人を集める必要がない場合
- 液体か結晶か
- 流動性がある組織
- 立場を変える余地が多い
- 昇進するには努力が必要
- 流動性が低い組織
- 階層内での自分の位置を理解し、レベルを引き上げるプロジェクトを実行する時期がいつ来るかを把握すべき
- 流動性がある組織
- 組織と情報フローに対する影響の3つのカテゴリ
- 病的
- 権力と地位が目的で人々が情報を溜め込む、協力性の低い文化
- 官僚的
- ルール指向の文化で、情報が標準的なチャンネルを介して移動し変更が困難
- 原動力
- 情報が自由に流れる、ミッション指向で信頼性が高く、協力性が高い文化
- 病的
- 地形についての注目ポイント
- キャズム
- チームの間に形成される溝
- 文化、規範、目標、期待が異なって進化し、コミュニケーションや意思決定を困難にするギャップが生じうる
- 要塞
- 決意を持っているように見えるチームまたは個人
- プロジェクトを完了することを阻止する働きをすることもある
- 大部分は善意を持っている人たち
- 気にかけているので門番をしている
- コードやアーキテクチャの品質を高く保ち、全員の安全を守ろうとする
- 紛争地帯
- チームの境界線を引く=各チームが自律的に作業できるようにする方法
- API、contract などに関してチームが自分たちのものだと考えている作業について、conflict を乗り切るのは大変なことがある
- 2つ以上のチームが緊密に連携 & 目標について同じ明確な見解が無いと混乱に陥る可能性がある
- 超えられない砂漠
- 目標を達成するために勝ち目のない戦いに遭遇することがある
- 過去上手くいかなかったことなど
- 今回は違う、ということを自分自身や他の人に納得させるのに十分な証拠が必要
- 舗装道路、近道、遠回り
- 人々が実際に行きたい場所のほとんどにつながっていない舗装道路
- キャズム
What Points of Interest Are on Your Map?
- 自分だけの地図を描いてみる
- 地図作成は本質的に政治的なもの
- 地図に含める内容は自分自身について語る
- 中心に何をおくか、どの側につく傾向があるか
- 決定はどのように行われるか
- 方向性について技術的に正しいことは始まりに過ぎない
- 適切な他の人を説得する必要がある
- どのように意思決定が行われているかを理解しないと、意思決定を予測したり影響を与えられない
- 「意思決定が行われる部屋」にいないとどう決定するかが見えない
- 参加する
- グループに参加することは、すでに参加している人にとって無料ではない
- 人が増えるごとに会議の進行が遅くなり、議論が長引き、心理的安全性が減る
- 参加したら、価値を追加するだけでなく、コストを削減する必要がある
- 準備を整えて出席
- 簡潔に話す
- 協力的で摩擦の少ない貢献者になる
- グループに参加することは、すでに参加している人にとって無料ではない
- 参加すべきではない部屋もある
- ICトラックの場合、報酬、パフォーマンス管理、その他のマネージャートラックの議論に参加すべきではない
- そういう場で技術的決定がされている場合はトピックを別の会議に分割することを提案
- 影の組織図
- 権力と影響力が流れる暗黙の構造
- 実際の組織図と同じではない可能性がある
地形図を最新の状態に保つ
地形がまだ通行困難な場合は、橋渡し役になりましょう
テクノロジー企業の成長を遅らせる問題最もよくあるのは、チーム同士の話し合いの仕方がわからない、誰も決定を下す権限がないと感じている、権力闘争など、人間的な問題です。これらは難しい問題です。
宝の地図: どこに行くのか思い出させてくれませんか?
短期的なことだけを考えていると、
- 全員が同じ方向に進むのは難しくなるだろう
- チームが大まかな計画を知らないと、間違った方向に進むか、すべての決定が長く複雑で、議論の多いものになる
- 大きなことを成し遂げられない
- チームがローカルな問題や問題点を解決するための短期的なプロジェクトに集中し続けると、複数のステップを必要とする、より大きく長期的な問題を解決できなくなる
- ゴミが溜まる
- チームがどこに向かっているのか分からない場合、選択肢は 2 つ
- 将来のあらゆる状態に対応できるほど柔軟になろうとする
- ローカルな決定を下す
- 競合する取り組みがある
- 草の根またはボトムアップの取り組みに頼る組織では、まったく異なる方向性に熱意を結集させようとしている人が複数いる可能性がある
- エンジニアの成長が止まる
Chapter 3. Creating the Big Picture
このシナリオには多くの問題が含まれていますが、その多くには簡単な技術的解決策があります。会社に新しく入社する人は皆、データストアのシャーディング、API のバージョン管理、モノリスからの機能の抽出など、変更を提案します。さまざまなワーキング グループが発足しました。それらは常に、深い関心を持ちながらも意見が一致しない 20 人の部屋から始まり、誰もそれらに集中する時間がないという泥沼に陥ります。結局のところ、より重要または成功する可能性が高いと思われる機能作業があります。エンジニアリング組織は、単一のイニシアチブの推進力を得ることができないようです。
ビジョンと戦略の文書は本当に必要ですか?
技術的なビジョンと戦略は明確さをもたらし、しかし、多くの状況ではやりすぎになることがあります。不必要な作業を自分で行わないでください。目指す状態や解決しようとしている問題を簡単に説明できる場合は、実際に必要なのは設計ドキュメントの目標セクションやプル リクエストの説明のようなものです。ドキュメントがなくても全員が足並みを揃えられる場合は、おそらくドキュメントは必要ありません。
アプローチ
人々の同意を得ることは、問題解決という実際の作業とあなたの間に立ちはだかる面倒な作業ではないことを心に留めておいてください。合意こそが作業なのです。
公式に発表する
技術的なビジョンや戦略の作成を開始する前に検討すべきチェックリストを以下に示します。
- これが必要です。
- 解決策は退屈で明白なものになることはわかっています。
- 既存の取り組みはありません (または、参加したことはありません)。
- 組織的なサポートがあります。
- 私たちは、何を創造しているかについて合意しています。
- その問題は(私によって)解決可能です。
- 上記のいずれについても、私は自分に嘘をついていません。
最後にもう 1 つ質問があります。仕事にコミットして、「声に出して」作業を開始する準備はできていますか? これは、キックオフ ドキュメント、マイルストーン、タイムライン、進捗状況の報告に関する期待事項を含め、ビジョンまたは戦略の作成をプロジェクトとして正式に設定するのに適したタイミングかもしれません。先延ばししたり、気が散ったりする傾向がある場合は、これらの構造が特に重要です。
ライティングループ
- ビジョン、戦略、その他の幅広い文書を実際に作成するためのテクニックをいくつか紹介
- これらのテクニックのほとんどを何度も実行することになる
- 情報は常に増え続けるので、このループから得られる成果が減退し始めたら注意
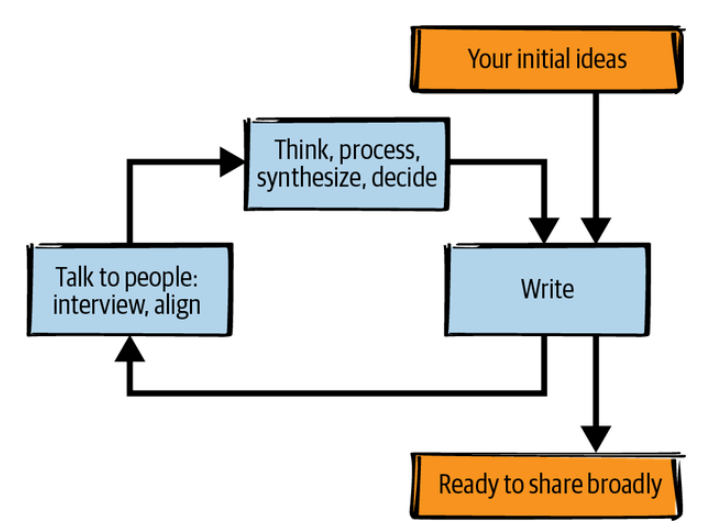
最初のアイデア
- すでに存在するドキュメントは何ですか?
- 何を変える必要があるでしょうか?
- 漸進的な改善ではなく、創造性を刺激する目標(達成不可能ではない)を設定
- 何がそのまま素晴らしいのでしょうか?
- 何が重要ですか?
- 重要ではないことに時間を費やさない
- 未来のあなたは、現在のあなたに何をしてほしかったと思いますか?