TCPの輻輳制御
この記事では、「TCPの輻輳制御とは何か」「具体的にどういったアルゴリズムでウインドウが制御されているのか」をざっくり説明します。
はじめに: HTTP/3時代にTCPの輻輳制御・・・?
今後インターネットでHTTP/3が急速に増えてくると思われます。これまでのHTTP/2とは、アンダーレイがTCPからQUIC(UDP)に変わることが大きな違いの一つです。
もしかすると、「その時代にTCPの輻輳制御を学ぶことに意味があるの?」と思う方もいらっしゃるかもしれません。まあ、そもそも、インターネットに流れているTCPはHTTPだけではありませんから、引き続き必要ですよね、というのが私の回答です。でも、仮にHTTPに限って考えるとしても、以下の理由で必要です。
- HTTP/3のアンダーレイであるQUICの輻輳制御は、TCPの輻輳制御と同じアルゴリズムが使われる
- HTTP/3は単体で動かない(HTTP/3の実現のためにはHTTP/2が必須)
つまり、HTTP/3時代になっても、TCPの輻輳制御は引き続き重要な存在 ということです。
ウィンドウサイズ
さて、重要性が分かったところで本題へ進みましょう。まずはウインドウサイズについて説明します。
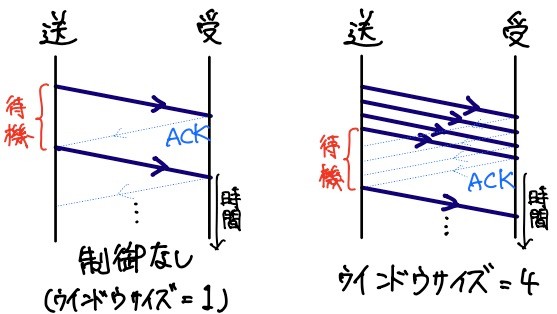
元来、TCPは高信頼性を確保するために考えられたプロトコルです。そのため、受信側は、各セグメントを受信した旨を伝えるため、セグメント単位でACK(Acknowledge)を返信する決まりです。この決まりにより、ACK応答によりデータが確実に送信できたことを確認します。ここで、セグメントとは、TCPのデータ送信を行う最小単位のことで、TCPのヘッダを1つだけ含みます。上図の紫色の太い線が1つのセグメントです。
初期のTCPは、上図右のように、1セグメントだけデータを送り、そのACKが応答されるまで次のセグメントを送らない仕組みでした。確かに信頼性が重要で、ACKが必要だとしても、このやり方はあまりに非効率です。そこで、「ACKが返って来る前に複数のセグメントを同時に送って良いよ」というルールを作ることにしました。ここで、 一度に送れるセグメントの数をウインドウサイズ といい、「ネットワークの状況を鑑み、ウインドウサイズをどう賢く制御するか」を輻輳制御といいます。ここで、輻輳とは、通信ネットワークが混雑していることを指す技術用語です。輻輳が続くと通信できなくなってしまいます。
ちなみに、輻輳制御の話をするときに、ウインドウの値を一気に大きくすることを「アグレッシブ」と表現します。また、対義語として、少しずつウインドウの値を大きくすることを「慎重」と表現することもあります。
フロー制御と輻輳制御
輻輳制御と混同しがちなものとしてフロー制御があります。いずれもTCPをより効率的に運用するための技術という点では共通ですが、何に備えているか(=何のキャパシティを超えないように制御するか)という点が異なります。
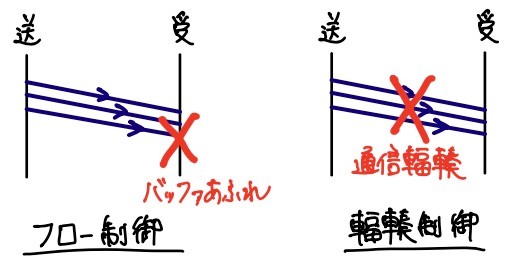
- フロー制御
- 受信側のキャパシティを超えないようにする仕組み
- 受信側が送信側に受信ウインドウサイズを伝え、送信側に従ってもらう
- 輻輳制御
- 送受間のネットワークのキャパシティを超えないようにする仕組み
- 送信側がネットワークの状態を推定し、送信側が自律的に輻輳ウインドウサイズを制御する
いずれの制御も、一度の送信量を変えるのは(もちろん)送信側です。しかしながら、フロー制御は、受信側ホストのコンピューターの性能を超えて一度にデータを送信されないように制御します。この受信側の性能のことを受信バッファといい、受信バッファの残量を都度伝える仕組み(「スライディングウインドウ」といいます)により、最新の受信バッファ残量を送信側に伝えています。
なお、フロー制御で制御するウインドウサイズを受信ウインドウサイズ、輻輳制御で制御するウインドウサイズを輻輳ウインドウサイズと呼んで区別します。
以後、この記事では輻輳制御による輻輳ウインドウサイズについてだけ解説します。
輻輳制御アルゴリズムの分類
現在、よく使われている輻輳制御アルゴリズムは1つだけではありません。加えて、現時点でも進化を続けています。この章でまず、輻輳制御アルゴリズムの分類を説明します。
- Loss-based
- パケットの廃棄をもとにネットワークの状況を推測
- Delay-based
- パケットの遅延量をもとにネットワークの状況を推測
ネットワークの状況を完全に知ることはできませんから、何らかの指標で輻輳の有無などを判断する必要があります。大きく、廃棄と遅延で状況を推測する方法の2つに分類できます。なお、組み合わせたものをHybridと呼ぶ場合があります。
現在で最も注目されているアルゴリズムは、Delay-basedに分類されるBBRだと断言して異論は出ないでしょう。しかし、Delay-basedがいかなる場合も優れているとまでは断言できません。BBRは現代のインターネットにおいてはおそらく最適に近いものだと思いますが、ネットワークの特性に応じて様々なアルゴリズムが考えられていますし、それらは年々進化しています。
(余談)遅延と輻輳って関係あるの?
余談です。長いし、本題の理解に必須ではないので、読み飛ばして頂いても構いません。
ネットワークが輻輳している状態というのは、ネットワークのキャパシティを超えてパケットの廃棄が発生している状態です。すなわち、パケットの廃棄を基準にするLoss-basedなアルゴリズムは、輻輳を輻輳の定義に即して判断するアルゴリズムということです。もちろん直感的です。でも、Delay-basedは、どうして遅延をネットワークの輻輳判定に利用するのでしょうか? 確かに遅延は短い方がよさそうですが、それでも遅延と輻輳に何の関係があるのでしょうか?
例えば、日本・アメリカ間のTCPコネクションと、日本同士のTCPコネクションを比較しましょう。明らかに前者の方がパケットの遅延が大きいはずです。でも、例えば日本国内の通信だけ混雑していて、日本とアメリカの間の方がむしろ混雑していない場合もありえませんか?この仮定の下では、遅延の大きな日本とアメリカのTCPコネクションの方が、輻輳していないといえませんか?
この疑問に回答するためには、ネットワークの輻輳直前に何が起きるか理解する必要があります。昨今のネットワーク機器は、輻輳時でも可能な限りパケット廃棄を抑えるため、送信先インターフェースの伝送容量を超えそうになった場合、バッファリングします。つまり、ルータが一時的にパケットを溜め、伝送容量に余裕ができたタイミングで送信するのです。その結果、パケットの廃棄が起こる前には、遅延が増大します[1]。遅延の増加=ネットワーク輻輳の前兆と捉えることができるのですね。
もう少し深く考えると、パケットの遅延量は概ね「伝送による遅延+ルータのバッファリングの遅延」で表されますが、輻輳制御において重要なのは「ルータのバッファリングの遅延」のみだということです。ただ、実際には、遅延の要因を確実に識別するのは困難ですから、遅延の増加を契機に制御するなどの工夫が行われています。
輻輳制御アルゴリズム
Tahoe
最も基本的で伝統的なアルゴリズムがTahoeです。現代において使う理由はありませんが、輻輳制御の概念・用語・課題を理解する上で有用ですので説明します。

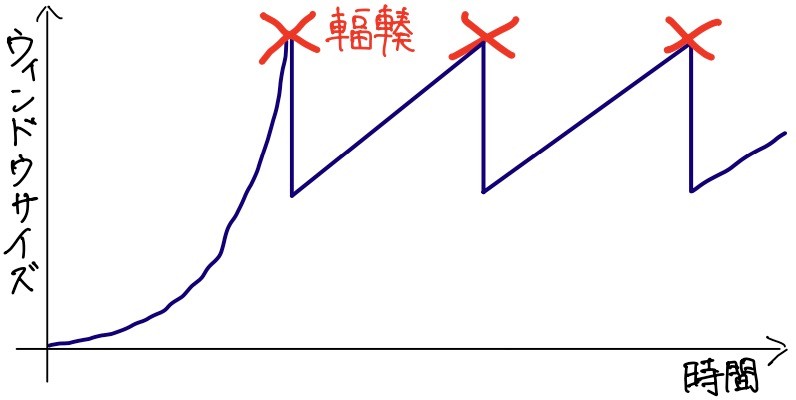
こういうグラフがよく出てきますので読み方に慣れましょう。横軸が時間で、縦軸がウインドウサイズです。紫線のグラフが、ウインドウサイズの時間変化を表しています。
最初はスロースタートで行われます。最初はウインドウサイズを1で送信、すなわち1セグメントだけでACK受信を待つ動作をします。次はウインドウサイズを2倍、その次は4倍、8倍・・・と二次関数で大きくします。すると、そのうちネットワークの限界に達し、輻輳が発生しますね。TahoeはLoss-basedのアルゴリズムですから、TCPセグメントに廃棄が発生した場合、すなわちACK応答がなかったりDuplicate ACK[2]が応答されたりした場合に輻輳として判断されます。
Tahoeは、最初の輻輳を迎えた後、ウインドウサイズを1まで戻します。 更に、それ以降は少し動作が変わり、「輻輳が発生したウィンドウサイズ÷2」の値(図中点線で示す値)までは1回目と同じ二次関数ですが、それ以降は一次関数でウインドウサイズを増やします。輻輳発生後は繰り返し輻輳を起こさないように慎重になるんですね。ちなみに、この動作フェーズを輻輳回避フェーズといいます。
Reno/New Reno
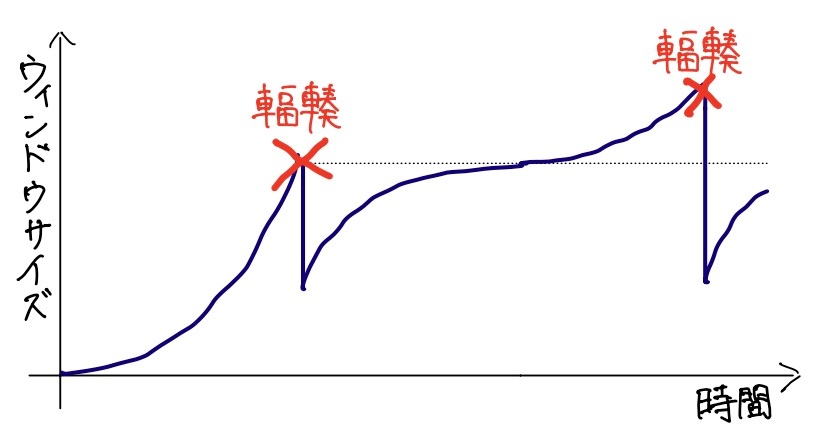
Tahoeはとても慎重なアルゴリズムで、転送効率がよくありませんでした。その課題を解決するために考えられたアルゴリズムがRenoです。
Tahoeは、輻輳が発生したときにウインドウサイズを1まで戻してしまいました。一方Renoは、輻輳が発生した後、ウインドウサイズを「輻輳が発生したウィンドウサイズ÷2」の値まで戻します。 結果としてすぐに輻輳回避フェーズが始まります(これを高速リカバリといいます)。Tahoeの転送効率が悪い最大の理由は輻輳後毎回発生するスロースタートでした。Renoは、初回以外スロースタートが発生しないアルゴリズムにすることで、転送効率が大幅に改善されました。
また、Renoの改善版であるNew Renoというアルゴリズムもあり、パケットがバースト的に廃棄されてしまう場合の挙動が改善されています。単に「Reno」と呼んだ場合でも、この「New Reno」を指していることがあります。
CUBIC
昔はReno/New Renoがとても良く動いていたのですが、インターネットの高帯域に伴い、Reno/New Renoの高速リカバリですら効率が悪くなってしまいました。そこで、より速くリカバリを行うアルゴリズムが検討され、紆余曲折[3]あった後、CUBICが登場しました。CUBICは、現在において主流なLoss-basedな輻輳制御アルゴリズムのひとつです。Linuxカーネル標準のTCP輻輳制御アルゴリズムになっています。
CUBICは、最初の輻輳を検知するところまではRenoと同じですが、その後の輻輳回避フェーズが大きく異なります。前回の輻輳を検知したウインドウサイズまでは慎重にウインドウサイズを増加させ、過ぎた後は、とてもアグレッシブにウインドウサイズを増加させます。 言い換えると、図のように、前回の輻輳を検知したウインドウサイズを極とした三次関数としてウインドウサイズを制御します。
BBR
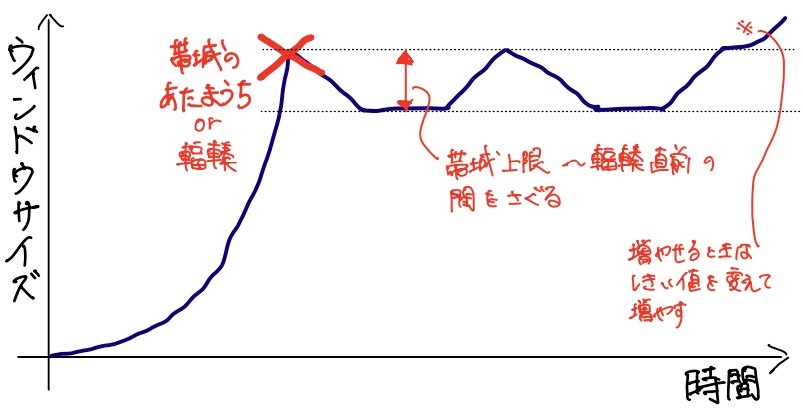
いま最も注目されているアルゴリズムがBBRです。Googleが開発した制御方法で、将来的にはQUICでも利用される見込みです。元々発表されたBBRをBBRv1、最近改良が加えられたBBRをBBRv2と呼んで区別することもあります。BBRはDelay-basedです。
BBRは、遅延量とスループット(帯域)を監視 します。いくつかのフェーズがあり、ウインドウサイズが小さい順に概ね以下の3段階があります[4]。スロースタートでウインドウサイズを増やしているフェーズであれば、1->2->3の順に遷移することになります。
- 遅延していない かつ ウインドウサイズを増やせばそれに従ってスループット(帯域)が増加する
- 遅延が増加しはじめる かつ ウインドウサイズを増やしてもスループット(帯域)が増加せず、頭打ち
- パケットの廃棄が発生する
Loss-basedなアルゴリズムは、2から3になった時点で輻輳と判断し、輻輳回避フェーズに入ります。一方、レガシーなDelay-basedなアルゴリズムは、1から2になった時点で輻輳回避フェーズに入ります。BBRはDelay-basedなアルゴリズムとは少し違い、これらの間をとった動作をします。具体的には、2の中に慎重な動作をしたりアグレッシブな動作をしたりする訳でなく、現状維持を試みます。 上図でみると、「帯域上限(1と2の閾値)〜輻輳直前(2と3の閾値)の間をさぐる」 動作です。実際にはここまでシンプルではありませんが、概要はこんな感じです。
Delay-basedなアルゴリズムは、長年検討はされていましたが、主流になることはありませんでした。しかし、BBRの最大の特徴である「現状維持を試みる」動作のおかげで、おそらく今後の主流なアルゴリズムになってくると思われます。
(余談)なぜDelay-basedはこれまで主流にならなかったの?
Delay-basedの欠点と主流にならなかった理由です。読み飛ばしてもかまいません。
端的にいうと、Delay-basedは慎重すぎるからです。
そもそも、ネットワークの仕組み上、パケットの廃棄よりも先にパケットの遅延が発生します[5]。ということは、すでにLoss-basedな輻輳制御アルゴリズムが大半を占めるインターネット環境において、より早くウインドウサイズを小さくするDelay-basedな輻輳制御アルゴリズムを導入すると、どうなるでしょう?Delay-basedなアルゴリズムが先にウインドウサイズを小さくしてしまいます。つまり、先の3段階の説明を見ても分かるように、Delay-basedは遠慮しがちなのです。
この世にLoss-basedなアルゴリズムが一切無ければ、おそらく純粋なDelay-basedなアルゴリズム(代表例としてVegasがあります)が最適だったのだと思いますが、残念ながらこの先も、そんなことは起こりえませんね。つまり、New RenoやCUBICなどのLoss-basedなアルゴリズムが浸透している以上、頑張って考えたDelay-basedの新しいアルゴリズムの方がスピードが出ない、ということです。これでは、頑張って新しいアルゴリズムを導入するモチベーションが沸きませんよね。
まとめ
- 輻輳制御は、TCPのセグメントを一度にどれだけ送るかというウインドウサイズをネットワークの都合に応じて制御すること
- 具体的なアルゴリズムは、パケット破棄を基に制御する方法と、パケット遅延を基に制御する方法がある
- 最近は前者はCUBIC・後者はBBRが主流で、最新のHTTP/3でもそれらのアルゴリズムが使われる見込み
- 初期のアルゴリズムは、初期(スロースタートフェーズ)や破棄・遅延の発生直後の挙動(輻輳回避フェーズ)が問題で、ウインドウサイズをなかなか大きくできずに転送効率が悪いという欠点があった
- CUBICやBBRはそれらの欠点を克服し、より効率的かつ現在のインターネット環境に耐えうるアルゴリズムになっている
なお、筆者は、BBRの詳しい動作を勉強中です。特にv2は、動作は分かっても意図を理解するのが難しすぎます。もう少し理解が深まれば、BBRについての記事も書いてみたいと思っています。それでは。
参考文献
- http://www.net.c.dendai.ac.jp/~yutaro/
- https://datatracker.ietf.org/meeting/104/materials/slides-104-iccrg-an-update-on-bbr-00
-
あくまでレイヤー1の話ですから、TCPに限った話ではないことに注意ください。 ↩︎
-
ACKが途中で破棄されてしまった場合に発生します。Duplicated ACKは、受信者側からみて、ACKを送ったはずのTCPセグメントが再度送られてきた場合に応答されます。 ↩︎
-
主に公平性の観点で様々な議論がありました。すでにRenoによる輻輳制御が行われている環境に対し、Renoと異なる新しい制御を導入すると、Reno/New Renoがほぼ通信できなくなったり、逆に新しいプロトコルがほぼ通信できなくなるケースがありました。そのため、"相性のよい"輻輳制御が必要でした。 ↩︎
-
BBRの「フェーズ」は、Startup / Drain / ProbeBW / ProbeRTT ですが、その話ではありません。この記事では、ウインドウサイズに対する遅延やスループット(帯域)の状態のことをだけを論じます(もっと言うと、わかりやすさのために正確性を犠牲にして、必要な説明をはしょっています)。 ↩︎
-
理由は「(余談)遅延と輻輳って関係あるの?」をご参照ください ↩︎
Discussion