Amazon Lookout for Visionことはじめ

はじめに
AWSの外観検査用のサービスであるAmazon Lookout for Visionを試してみました。汎用的な画像認識などはAmazon Rekognitionがあります。また画像にラベル付けしたり、異常部分をマーキングするアノテーションツールはAmazon SageMakerで提供されています。色々組み合わせると便利ですね!
画像の異常検知をするには、
①同じ環境で撮影すること
②画像の情報量を削減すること
③良品と不良品の違いを強調すること
の3点が重要かと思っているのですが、今回はフリーのデータセットを用いまして、①はほぼ完璧です。②と③については特に処理していないですが、AWSさんがうまいことやってくれるやろとおもてます。
※現実のデータで学習するには画像の前処理が非常に大変なので、甘く見るとつまづきます。
ちなみに無料利用枠が割と確保されているので、少々の学習であれば無料でできます。

短い文章ですが5回も「無料」というワードが出ており、試したい欲を煽ってきます。
プロジェクトの作成
細かいAWSの設定は記載しません。Lookout for Visoinの利用開始状態にしたところからはじめます。Lookout for Visionのダッシュボードに入ります。

「プロジェクトを作成」を押す

適当にプロジェクト名をtestにして、「プロジェクトを作成」を押します。
データセットのダウンロード
異常検知用のデータセットを公開しているMVTec ADのサイトからデータセットをダウンロードします。
非営利ポリシーを守りましょう!
様々な種類のデータセットがありますが、今回は「bottle」の画像を使用します。
画像は3種類あります。「良品」「小欠け」「大欠け」の3種類です。

※小欠けは左下に欠けがありますね
大欠けはわかりやすいと思うので、
今回は「良品」と「小欠け」の2種類だけ用いて、「小欠け」を正しく見抜くことができるのか?というタスクをやってもらいます。
良品画像は200枚以上、ラベル付けされた小欠け画像は21枚用意されていますが、Lookout for Visionは少ないデータで学習できるそうなので、良品20枚小欠け10枚を学習データとします。
データセットの追加

プロジェクトに入るとこんな画面です。「データセットを作成」を押します。

「1つのデータセットを作成する」にチェックをいれて、
ファイルのアップ方法はコンピュータからアップするようにしました。

急に英語出てくるやないかーい
「イメージを追加」を押します。

まずは良品20枚をドラッグ&ドロップでぶち込みます。

ラベル付け
アップができたら「ラベルを追加」を押します。

すべての画像にチェックを入れ、「正常として分類」を選択します。

Normalというラベルが付きました。

次に「アクション」のドロップダウンメニューから「トレーニングデータセットにイメージを追加します」を選択します。
小欠け画像を10枚アップロードして、同じように、「異常」とラベル付けをします。
ちなみにですが、

もし、複数の不良モードがある場合はこちらから不良のラベルを増やすことができます。
トレーニング

小欠け画像にもラベルを付けると「モデルをトレーニング」ボタンが押せるようになったので押します。

(※アップできてない画像が3枚ある!と思ったので再アップすると実はAWS側のレスポンスが悪いだけでアップできてました。。その結果イメージ数が33枚と中途半端になりました。ラベル付けしなければ学習には使われないので気にせずに進めます。)
- 今回は暗号化はAWSさんに任せるのでチェックはいれません。「うわ〜AWSに画像盗まれるわ〜」と心配になる画像を学習させたいときはチェックをいれて設定するとよいと思います。
- タグはただのラベル?っぽいので特に設定する必要ないと思い、追加していません。
「モデルをトレーニング」を実行

トレーニングが進行中みたいです。楽ですね!
モデル評価
15分くらいでトレーニングが完了しました!

「リコール=異常を見逃さない確率」なので、それが100%ということは、不良品を流出する可能性が非常に低いということがわかります。逆に精度は100%ではないので、良品を不良と判定しているものがあるということですね。
モデルをクリックするとそのあたりの評価が出ます。

ちなみに良品を異常と判定してしまったのはこちらです。

左下の部分が欠けに見えてしまったのかな。とおもいました。
画像のように、推論の信頼性も出力されるので、良品でかつ信頼性が80%以上のものは再検査なしとするというような運用もできて非常に便利です。
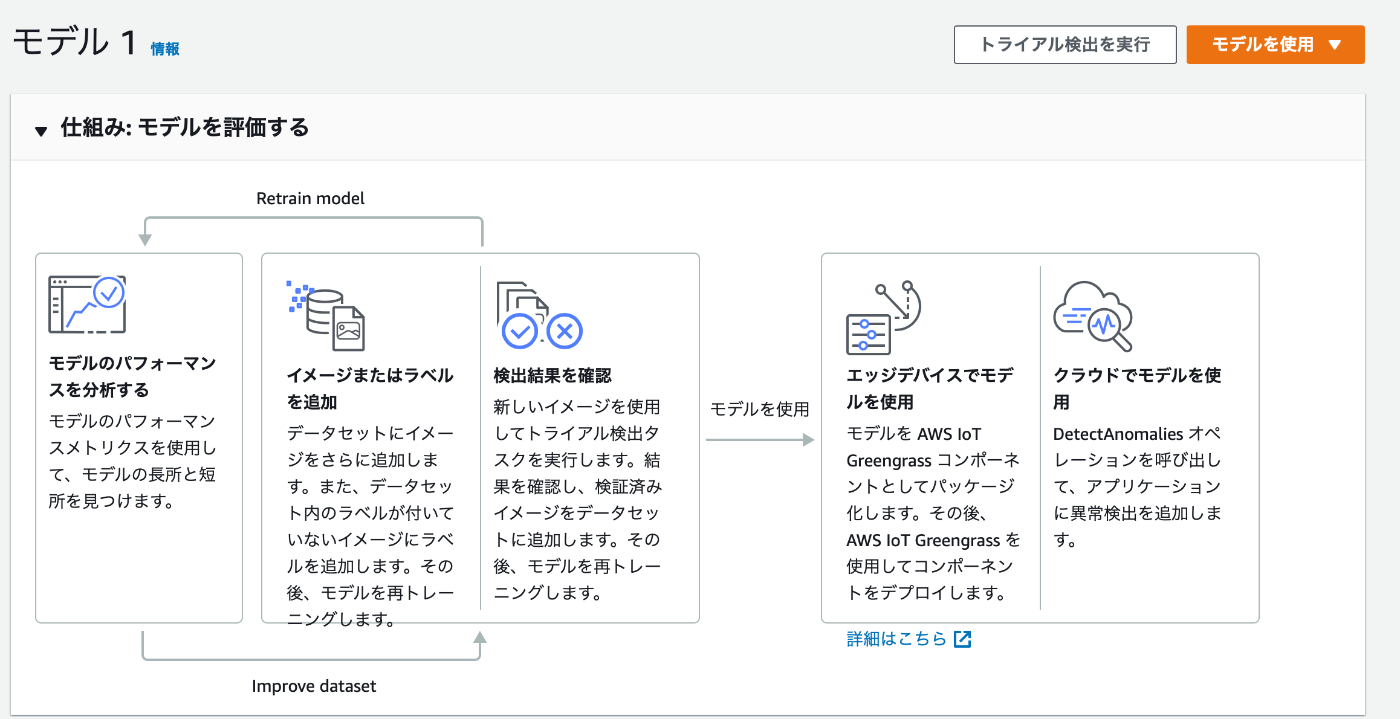
さらにエッジデバイスに学習済みモデルをデプロイできるので、ネットワークに繋がなくても推論ができます。
上の「トライアル検出を実行」をして推論を試してみます。
お試し推論

タスク名を適当につけて、コンピュータから学習に使わなかった画像をアップロードします。
今回は学習で使わなかった良品10枚小欠け10枚を追加してみます。
なんですが、、
間違えて良品に関しては学習に使った10枚をアップしてしまいました。
10分後・・・

すごいです。小欠け画像はすべて異常と検出されています!

信頼性が80%以上のものも多いです。

こちらは学習時も異常と判定された良品画像なのですが、推論時もやはり異常と判定されます。


「マシン予測を検証」から予測が正しいかインプットしてあげることで、再トレーニングすることもできます。データをインプットするほど賢くなりますね。
課題
- 推論時も割と時間がかかりましたが、工場では秒単位で判断が求められますので、エッジデバイスにモデルを入れた際に、どこまで高速で推論ができるのかは現場に落とし込む際の重要な指標になりそう。
- 推論モデルの中身を見ることができないので、特徴量だけ取り出して別のモデルをさらに適用するとかはできない
- 異常判定箇所は表示できない(AWS labが開発した良品学習手法のPatch Coreはできた)
- 撮影環境にばらつきのある画像を学習する際、前処理がどこまで必要かは検証していないので不明
まとめ
- ノーコードでらくらく自動外観検査
- 画像サイズが1枚500KBほどあってもそのままぶちこめる
- 良品20枚異常10枚と少ないデータセットで学習できる
- 推論時に信頼性も出力してくれる
- 複数の不良モードにも対応
- エッジデバイスに学習モデルを保存可能
- 検証も検証画像をアップするだけ
- 推論が正しいかインプットするだけで再学習可能
感想
やってみるか〜って思ったところから1時間半くらいでここまで出来たのでびびりました。
Discussion