Pythonの初心者レッスンーーPython文字列(str)



シーリズの目次
Pythonの初心者レッスンをここにまとめています。
Python 3における文字列(string)は、文字のシーケンスを表すデータ型で、テキストデータを扱うために使用されます。Pythonの文字列は、シングルクォート(')またはダブルクォート(")で囲んで表現します。
文字列はシングルクォートまたはダブルクォートで囲んで作成します。
str1 = 'こんにちは'
str2 = "Python"
文字列の値にアクセスする方法
- 文字列のインデックス
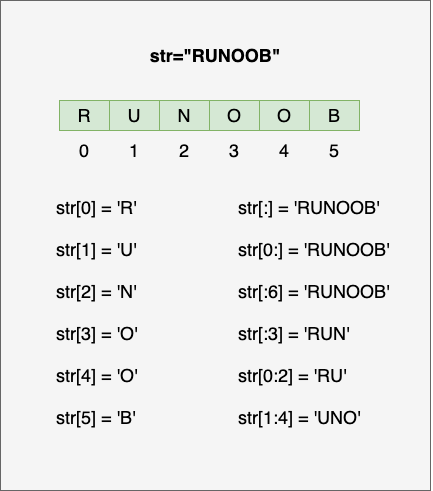
文字列は0から始まるインデックスを持つ文字のシーケンスです。各文字には、その位置に対応するインデックスがあります。インデックスを使用して、特定の位置にある文字にアクセスできます。
str = "Hello, World!"
# インデックスを使用して文字にアクセス
print(str[0]) # 出力: H
print(str[7]) # 出力: W
# 負のインデックスを使用して文字にアクセス(後ろから数える)
print(str[-1]) # 出力: !
print(str[-5]) # 出力: o
- 文字列のスライス
スライスを使用すると、文字列の部分文字列(サブストリング)を取得できます。スライスの構文は str[start:end] です。 start は開始インデックス、 end は終了インデックス(ただし、 end は含まれません)を指定します。
str = "Hello, World!"
# 部分文字列を取得
print(str[0:5]) # 出力: Hello
print(str[7:12]) # 出力: World
# 省略形
print(str[:5]) # 出力: Hello(開始インデックスを省略すると、0から始まる)
print(str[7:]) # 出力: World!(終了インデックスを省略すると、文字列の終わりまで)
print(str[:]) # 出力: Hello, World!(開始と終了を省略すると、全体)
エスケープシーケンス
Pythonのエスケープシーケンス(転送文字、エスケープ文字)は、文字列内で特定の特殊文字を表示したり、制御文字を含めるために使用されるバックスラッシュ()で始まる文字です。
エスケープシーケンスの例
以下に、Pythonで使用される一般的な例を示します。
# バックスラッシュ
print("This is a backslash: \\")
# 出力: This is a backslash: \
# シングルクォートとダブルクォート
print('He said, "Hello"')
# 出力: He said, "Hello"
print("It\'s a beautiful day")
# 出力: It's a beautiful day
# 改行とタブ
print("Hello\nWorld")
# 出力:
# Hello
# World
print("Hello\tWorld")
# 出力: Hello World
# キャリッジリターン
print("Hello\rWorld")
# 出力: World("Hello"が"World"で上書きされる)
# バックスペース
print("Hello\bWorld")
# 出力: HellWorld("o"がバックスペースで削除される)
# 8進数と16進数の文字
print("ASCII character 65: \101")
# 出力: ASCII character 65: A
print("Hex character 41: \x41")
# 出力: Hex character 41: A
# Unicode文字
print("Unicode character: \u2602")
# 出力: Unicode character: ☂
print("Unicode character: \U0001F600")
# 出力: Unicode character: 😀
エスケープシーケンスの一覧
以下にPythonの一般的なエスケープシーケンスをすべて示します。
| エスケープシーケンス | 説明 | 例 | 出力 |
|---|---|---|---|
\\ |
バックスラッシュ(\) | print("This is a backslash: \\") |
This is a backslash: \ |
\' |
シングルクォート(') | print('It\'s a test') |
It's a test |
\" |
ダブルクォート(") | print("She said, \"Hi\"") |
She said, "Hi" |
\n |
改行(ニューライン) | print("Hello\nWorld") |
Hello |
| World | |||
\t |
水平タブ | print("Hello\tWorld") |
Hello World |
\r |
キャリッジリターン | print("12345\rABCDE") |
ABCDE |
\b |
バックスペース | print("Hello\bWorld") |
HellWorld |
\f |
フォームフィード | print("Hello\fWorld") |
Hello(改ページ)World |
\a |
ベル(アラート) | print("Hello\aWorld") |
Hello(ベル音)World |
\v |
垂直タブ | print("Hello\vWorld") |
Hello(垂直タブ)World |
\ooo |
8進数値oooを持つ文字 | print("\101") |
A |
\xhh |
16進数値hhを持つ文字 | print("\x41") |
A |
\uXXXX |
16ビットのUnicode文字 | print("\u2602") |
☂ |
\UXXXXXXXX |
32ビットのUnicode文字 | print("\U0001F600") |
😀 |
運算符
Pythonには、文字列を操作するためのさまざまな運算符があります。以下に、Pythonの一般的な字符串(文字列)運算符を紹介します。
| 运算符 | 説明 | 例 | 出力 |
|---|---|---|---|
+ |
文字列の連結 | "Hello, " + "World!" |
Hello, World! |
* |
文字列の繰り返し | "Hello" * 3 |
HelloHelloHello |
[] |
インデックスによる文字の取得 | "Hello"[1] |
e |
[:] |
スライスによる部分文字列の取得 | "Hello"[1:4] |
ell |
in |
メンバーシップ(部分文字列の確認) | "e" in "Hello" |
True |
not in |
メンバーシップ(部分文字列の不在) | "a" not in "Hello" |
True |
% |
文字列のフォーマット | "Hello, %s" % "World" |
Hello, World |
== |
等価の確認 | "Hello" == "Hello" |
True |
!= |
非等価の確認 | "Hello" != "World" |
True |
> |
辞書式順序に基づく大なり比較 | "Hello" > "World" |
False |
< |
辞書式順序に基づく小なり比較 | "Hello" < "World" |
True |
>= |
辞書式順序に基づく大なりイコール比較 | "Hello" >= "Hello" |
True |
<= |
辞書式順序に基づく小なりイコール比較 | "Hello" <= "World" |
True |
詳細説明と例
str1 = "Hello, "
str2 = "World!"
result = str1 + str2
print(result) # 出力: Hello, World!
str = "Hello"
result = str * 3
print(result) # 出力: HelloHelloHello
str = "Hello"
char = str[1]
print(char) # 出力: e
str = "Hello"
substr = str[1:4]
print(substr) # 出力: ell
str = "Hello"
result = "e" in str
print(result) # 出力: True
str = "Hello"
result = "a" not in str
print(result) # 出力: True
name = "World"
result = "Hello, %s" % name
print(result) # 出力: Hello, World
result = "Hello" == "Hello"
print(result) # 出力: True
result = "Hello" != "World"
print(result) # 出力: True
result1 = "Hello" > "World"
result2 = "Hello" < "World"
result3 = "Hello" >= "Hello"
result4 = "Hello" <= "World"
print(result1) # 出力: False
print(result2) # 出力: True
print(result3) # 出力: True
print(result4) # 出力: True
文字列フォーマット
Pythonの文字列フォーマットは、文字列に変数の値を埋め込んで整形するための方法です。Pythonでは主に3つの方法で文字列をフォーマットすることができます。
%演算子によるフォーマット
これは、C言語のスタイルに似た古い方法ですが、依然として多くのコードで見られます。フォーマット指定子を使って、文字列内に変数の値を埋め込みます。
name = "Alice"
age = 30
formatted_string = "Name: %s, Age: %d" % (name, age)
print(formatted_string) # 出力: Name: Alice, Age: 30
以下に、Pythonで使用できるすべてのフォーマット指定子を説明します。
| フォーマット指定子 | 説明 | 例 | 出力 |
|---|---|---|---|
%s |
文字列または任意のオブジェクト | "Hello %s" % "World" |
Hello World |
%d |
整数(10進数) | "Number: %d" % 42 |
Number: 42 |
%i |
整数(10進数) | "Number: %i" % 42 |
Number: 42 |
%o |
整数(8進数) | "Number: %o" % 42 |
Number: 52 |
%x |
整数(16進数、小文字) | "Number: %x" % 42 |
Number: 2a |
%X |
整数(16進数、大文字) | "Number: %X" % 42 |
Number: 2A |
%e |
浮動小数点数(指数表記、小文字e) | "Number: %e" % 42.42 |
Number: 4.242000e+01 |
%E |
浮動小数点数(指数表記、大文字E) | "Number: %E" % 42.42 |
Number: 4.242000E+01 |
%f |
浮動小数点数(10進数表記) | "Number: %f" % 42.42 |
Number: 42.420000 |
%F |
浮動小数点数(10進数表記) | "Number: %F" % 42.42 |
Number: 42.420000 |
%g |
浮動小数点数(短い方を選択) | "Number: %g" % 42.42 |
Number: 42.42 |
%G |
浮動小数点数(短い方を選択) | "Number: %G" % 42.42 |
Number: 42.42 |
%c |
整数のUnicode文字 | "Char: %c" % 65 |
Char: A |
%% |
リテラルの%文字 | "Percent: %%d" % 42 |
Percent: %d |
str.format()メソッドによるフォーマット
この方法は、より強力で柔軟なフォーマットを提供します。
name = "Bob"
age = 25
formatted_string = "Name: {}, Age: {}".format(name, age)
print(formatted_string) # 出力: Name: Bob, Age: 25
フォーマットオプション
formatted_string = "Name: {0}, Age: {1}".format(name, age)
print(formatted_string) # 出力: Name: Bob, Age: 25
formatted_string = "Name: {name}, Age: {age}".format(name="Charlie", age=35)
print(formatted_string) # 出力: Name: Charlie, Age: 35
formatted_string = "Pi is approximately {0:.2f}".format(3.14159)
print(formatted_string) # 出力: Pi is approximately 3.14
f文字列(フォーマット済み文字列リテラル)
Python 3.6以降で導入された最もモダンで直感的な方法です。f文字列(フォーマット済み文字列リテラル)を使うと、変数や式を中括弧{}で囲んで直接埋め込むことができます。
name = "Diana"
age = 28
formatted_string = f"Name: {name}, Age: {age}"
print(formatted_string) # 出力: Name: Diana, Age: 28
式の埋め込み
import math
formatted_string = f"Pi is approximately {math.pi:.2f}"
print(formatted_string) # 出力: Pi is approximately 3.14
Templateクラスによるフォーマット
標準ライブラリのstringモジュールには、Templateクラスがあり、プレースホルダーを使って文字列をフォーマットできます。
from string import Template
template = Template("Name: ${name}, Age: ${age}")
formatted_string = template.substitute(name="Eve", age=22)
print(formatted_string) # 出力: Name: Eve, Age: 22
Pythonの三引号
Pythonの三引号(トリプルクォート)は、複数行の文字列を扱うための特別な方法です。三引号で囲まれた文字列は、その中に改行文字やタブ文字などを含むことができ、コード内で複数行に渡って記述することが可能です。
三引号にはシングルクォート3つ(''')とダブルクォート3つ(""")の2種類があります。どちらを使っても同じように動作しますが、文字列内にシングルクォートまたはダブルクォートが含まれる場合、もう一方を使うことでエスケープシーケンスを減らすことができます。
# シングルクォートを使用
multi_line_string = '''これは
複数行の
文字列です。'''
print(multi_line_string)
# ダブルクォートを使用
multi_line_string = """これも
複数行の
文字列です。"""
print(multi_line_string)
三引号の特徴と利点
-
複数行の文字列:
三引号で囲まれた文字列は、そのまま複数行に渡って記述できます。 -
特殊文字の使用:
特殊文字(改行、タブなど)をそのまま文字列に含めることができます。 -
ドキュメント文字列(docstring):
関数やクラスの説明を記述するために、docstringとして使用されます。
f-string
Pythonのf-string(フォーマット済み文字列リテラル)は、Python 3.6で導入された文字列フォーマットの方法で、変数や式を文字列の中に埋め込むための便利で直感的な方法です。f-stringは、文字列の前に f または F を付けることで使用できます。
-
f-stringの基本的な使い方
f-stringを使用するには、文字列の中に中括弧 {} を使って変数や式を埋め込みます。例えば、以下のように使用します。
name = "Alice"
age = 30
formatted_string = f"My name is {name} and I am {age} years old."
print(formatted_string) # 出力: My name is Alice and I am 30 years old.
-
f-stringの利点
- 可読性の向上: 変数や式をそのまま文字列の中に埋め込むことができるため、コードの可読性が向上します。
- 式の評価: f-string内で任意のPython式を評価できます。
- 簡潔さ: 他のフォーマット方法と比べて、記述が簡潔です。
-
詳細な使い方
式の埋め込み
import math
radius = 5
area = f"The area of the circle is {math.pi * radius ** 2:.2f}"
print(area) # 出力: The area of the circle is 78.54
フォーマット指定
f-stringではフォーマット指定子を使用して、数値のフォーマットを細かく制御できます。以下にいくつかの例を示します。
value = 1234.56789
# 小数点以下2桁まで表示
formatted_value = f"{value:.2f}"
print(formatted_value) # 出力: 1234.57
# 10進数をパディングして表示
formatted_value = f"{value:10.2f}"
print(formatted_value) # 出力: 1234.57
# 16進数で表示
number = 255
formatted_value = f"{number:x}"
print(formatted_value) # 出力: ff
エスケープシーケンス
f-stringの中で { と } を使用する場合は、 {{ と }} と書くことでエスケープできます。
escaped_string = f"{{ This is an escaped brace }}"
print(escaped_string) # 出力: { This is an escaped brace }
文字列の組み込み関数
以下にPythonで利用可能な主要な文字列の組み込み関数を、テーブルでまとめます。
| 関数名 | 説明 | 使用例 | 出力(例) |
|---|---|---|---|
capitalize() |
文字列の先頭を大文字に変換する。 | "hello".capitalize() |
Hello |
casefold() |
文字列を小文字に変換する。 | "HELLO".casefold() |
hello |
center(width[, fillchar]) |
文字列を中央寄せにし、指定された幅で埋める。 | "hello".center(10) |
hello |
count(sub[, start[, end]]) |
文字列内の部分文字列 sub の出現回数を数える。 |
"hello hello".count("l") |
3 |
encode([encoding[, errors]]) |
文字列を指定されたエンコーディングでエンコードする。 | "hello".encode('utf-8') |
b'hello' |
endswith(suffix[, start[, end]]) |
文字列が指定された接尾辞 suffix で終わるかどうかを判定する。 |
"hello".endswith("lo") |
True |
expandtabs([tabsize]) |
文字列内のタブ文字をスペースに置き換える。 | "hello\tworld".expandtabs(4) |
hello world |
find(sub[, start[, end]]) |
文字列内で部分文字列 sub を検索し、最初に見つかった位置を返す。見つからない場合は -1 を返す。 |
"hello world".find("world") |
6 |
format(*args, **kwargs) |
文字列をフォーマットする。 | "Hello {0}".format("World") |
Hello World |
format_map(mapping) |
文字列を辞書 mapping を使ってフォーマットする。 |
"Hello {name}".format_map({"name": "World"}) |
Hello World |
index(sub[, start[, end]]) |
find() と同様だが、部分文字列 sub が見つからない場合は ValueError を返す。 |
"hello world".index("world") |
6 |
isalnum() |
文字列がすべての文字が英数字であるかどうかを判定する。 | "hello123".isalnum() |
True |
isalpha() |
文字列がすべての文字がアルファベットであるかどうかを判定する。 | "hello".isalpha() |
True |
isascii() |
文字列がASCII文字のみを含むかどうかを判定する。 | "hello".isascii() |
True |
isdecimal() |
文字列がすべての文字が10進数であるかどうかを判定する。 | "12345".isdecimal() |
True |
isdigit() |
文字列がすべての文字が数字であるかどうかを判定する。 | "12345".isdigit() |
True |
isidentifier() |
文字列が識別子(変数名として有効な名前)かどうかを判定する。 | "hello123".isidentifier() |
True |
islower() |
文字列がすべての文字が小文字であるかどうかを判定する。 | "hello".islower() |
True |
isnumeric() |
文字列がすべての文字が数値であるかどうかを判定する。 | "12345".isnumeric() |
True |
isprintable() |
文字列がすべての文字が印刷可能であるかどうかを判定する。 | "hello\n".isprintable() |
False |
isspace() |
文字列がすべての文字が空白文字であるかどうかを判定する。 | " ".isspace() |
True |
istitle() |
文字列がタイトルケース(最初の文字が大文字で、それ以外が小文字)になっているかどうかを判定する。 | "Hello World".istitle() |
True |
isupper() |
文字列がすべての文字が大文字であるかどうかを判定する。 | "HELLO".isupper() |
True |
join(iterable) |
iterable(リストやタプルなど)内の要素を文字列で連結する。 | ' '.join(["Hello", "World"]) |
Hello World |
ljust(width[, fillchar]) |
文字列を左寄せにし、指定された幅で埋める。 | "hello".ljust(10) |
hello |
lower() |
文字列をすべて小文字に変換する。 | "HELLO".lower() |
hello |
lstrip([chars]) |
文字列の先頭から指定された文字(もしくは文字セット)を削除する。 | " hello ".lstrip() |
hello |
maketrans(x[, y[, z]]) |
文字列の変換テーブルを作成する。 | str.maketrans("abc", "123") |
translation table |
partition(sep) |
文字列を sep で分割し、タプルとして返す(最初の sep、sep そのもの、残りの部分)。 |
"hello world".partition(" ") |
('hello', ' ', 'world') |
replace(old, new[, count]) |
文字列内の old を new で置換する。 |
"hello".replace("l", "L") |
heLLo |
rfind(sub[, start[, end]]) |
find() と同様だが、後ろから検索を開始する。見つからない場合は -1 を返す。 |
"hello hello".rfind("l") |
9 |
rindex(sub[, start[, end]]) |
index() と同様だが、後ろから検索を開始する。見つからない場合は ValueError を返す。 |
"hello hello".rindex("l") |
9 |
rjust(width[, fillchar]) |
文字列を右寄せにし、指定された幅で埋める。 | "hello".rjust(10) |
hello |
rpartition(sep) |
文字列を sep で分割し、タプルとして返す(後ろからの sep、sep そのもの、先頭の部分)。 |
"hello world".rpartition(" ") |
('hello', ' ', 'world') |
rsplit([sep[, maxsplit]]) |
文字列を右から左に sep で分割し、リストとして返す。 |
"hello world".rsplit(" ", 1) |
['hello', 'world'] |
rstrip([chars]) |
文字列の末尾から指定された文字(もしくは文字セット)を削除する。 | " hello ".rstrip() |
" hello" |
split([sep[, maxsplit]]) |
文字列を sep で分割し、リストとして返す。 |
"hello world".split() |
['hello', 'world'] |
splitlines([keepends]) |
文字列を行ごとに分割し、リストとして返す。行末の改行文字も含むかど |
Discussion