T5 とは
はじめに
こちらの記事を参考にしています。
T5(Text-to-Text Transfer Transformer) はテキスト入力に対してテキスト出力を行うモデルである。 多様な下流タスクで高いパフォーマンスを発揮することができるfine-tuning性能をもつ。
このモデルの素晴らしい点は以下
- 多くの転移学習の方法論を適用した
- C4と呼ばれる高品質、大規模データセットを作成し学習を行った。
これらについて紹介していきます。
多くの転移学習の方法論
2018にはGPT, BERTなど, RoBERTaなど今でもよく耳にするモデルの開発が行われました。
T5はそれらの手法を評価して、統合できるものは統合して、その時代のベストプラクティスなモデルとして開発されました。
エンコーダーデコーダーモデル
T5はモデルアーキテクチャとしてエンコーダーデコーダーモデルを採用しています。 GPTはデコーダーのみのモデルです。 Transformerはエンコーダーとデコーダーを含んでいます。
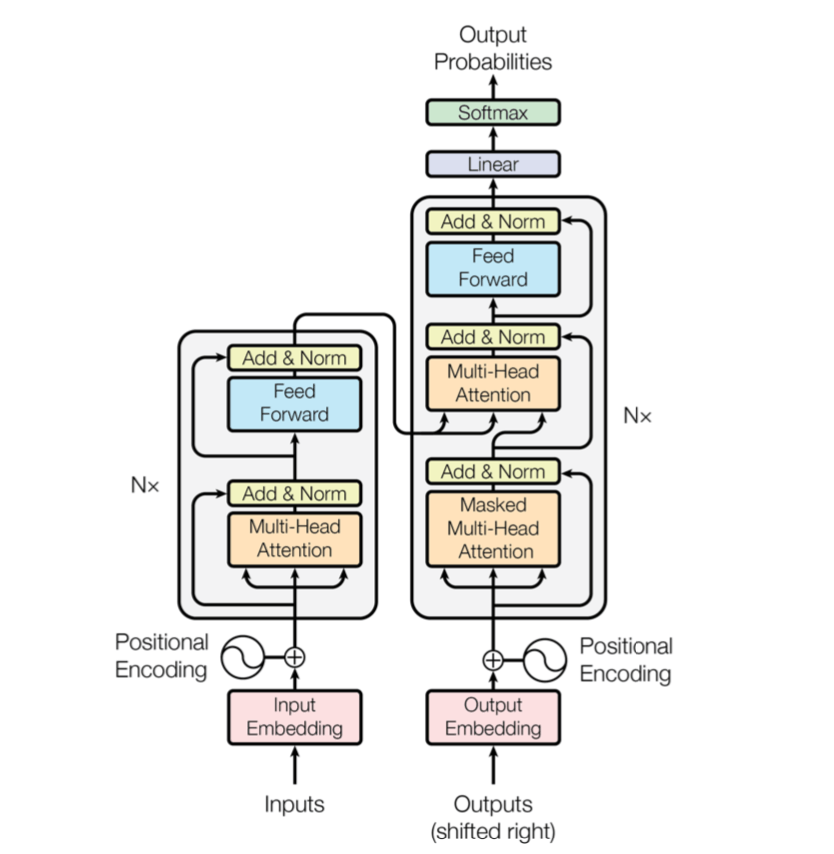
上図左がエンコーダーで右がデコーダーです。
このどちらとも使うのか、どちらだけ使うのかという話です。
事前学習
事前学習の方法に対しても、当時のベストプラクティスを確立しました。それは穴埋め形式の学習です。 Bertで使われた学習目標で、文章の中で一部をマスクした状態でモデルに入力しマスク部分の単語を当てるタスクを事前学習で行います。
ラベルなしデータセットでの学習
事前学習段階では、ラベルなしのデータセットで学習した方が良いことが示されました。 事前学習は大量なデータを必要とするため、現実問題としてラベルありデータセットを使えない問題はあります。
しかし、それを抜きにしても事前学習ではラベルなしを用いて学習を行うことで過学習を防ぐことができます。
C4
C4(Colossal Clean Crawled Corpus)はT5の学習のために導入された新しいデータセットです。
T5の事前学習用のデータセットであり、ラベルなしです。
Huggingfaceでも公開されています。
それまでに学習に使われていたのは
- wikipedia: https://huggingface.co/datasets/wikipedia
- Common Crawl
の二種類でした。
しかしこれらのデータセットはWikipediaは高品質なデータセットですが、スタイルが統一されている点と規模が小さいこと。 CommonCrawlが規模は大規模で多様だが品質が低いことが問題でした。
C4はその中間となるようなデータセットとして開発されました。
このように多様なデータセットで学習が行われました。
まとめ
T5は最近でもよく使われているモデルです。 事前学習モデルを使ってfine-tuningすれば多様なタスクに対して高いパフォーマンスを発揮できる点が優秀です。
また。C4データセットの話などは固有ドメインでモデルを学習する際に非常に重要なので、もうちょっと深く知りたいと思いました。
Discussion