Sentence Transformersでできること 拡張SBERT、埋め込み量子化、クロスエンコーダーの学習
Sentence Transformersでできることを紹介します。
今回紹介するのは以下の機能です。
- 埋め込み量子化
- クロスエンコーダーの学習
- 拡張SBERT
埋め込み量子化
埋め込み量子化とは、通常float32で表現される埋め込みベクトルを整数型やバイナリで表現することで、計算の高速化、メモリの節約、ストレージの節約を目指すものである。
埋め込みベクトルのバイナリ化を行うことで、1/32のデータ量になり、検索精度は90%以上を保持することができる。
またバイナリ化された埋め込みベクトル間の距離はハミング距離であるので、XOR演算とpopcountを使うことで高速計算が可能。実際にハミング距離を使った高速検索はGoogle検索でも使われている。
このアプリケーションの実用性はその制約次第だが、VectorDB内のベクトル量が250Mを超えたら、利用を考える価値が高い。
クロスエンコーダーの学習
クロスエンコーダーの利用と学習はSentence Transformersのメイン機能である。
バイエンコーダーとクロスエンコーダー
ベクトル検索に使われるRetriverではBi-Encoderが用いられます。
Bi-EncoderはSentenceAとSentenceBの距離を一度埋め込みベクトルに変換したのちに、ベクトル間の距離等を計算して類似度を計算します。埋め込みベクトルを一度計算しておくことで、その再計算の手間を省くことができます。 しかし類似度計算の精度に課題があります。
Cross-EncoderではSentenceAとSentenceBの類似度自体をAIモデルで行います。 そうすることで精度の高い類似度計算が可能になります。 一方で計算速度は遅くなるため、RetriverとしてではなくRerankerとして用いられることが多いです。

https://www.sbert.net/examples/training/cross-encoder/README.html
学習
Cross-Encoderの学習はこのように行います。labelはそのペアでの類似度を0~1で表します。
実際の学習データでは0or1(類似するペアか類似しないペアか)になると思います。
train_samples = [
InputExample(texts=["sentence1", "sentence2"], label=0.3),
InputExample(texts=["Another", "pair"], label=0.8),
]
クロスエンコーダーの学習は本家のREADMEが詳しいです。
拡張SBERT
拡張SBERTはBi-Encoder(つまりEmbeddings model)の学習を少量データで行う際に用いると良いです。
Bi-EncoderはRetiver,Clustringなどのタスクで高いパフォーマンスを発揮しますが、学習には大量のデータとターゲットタスクの微調整が必要になります。
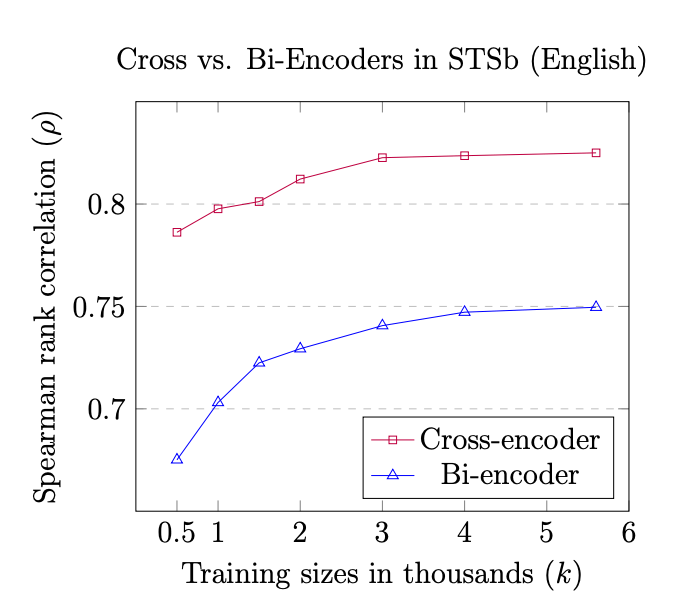
https://arxiv.org/pdf/2010.08240.pdf
上の図から学習データ量が小さいときにはBi-Encoderのパフォーマンスが低いことがわかります。
拡張SBERTはCross-Encoderを使いデータ拡張を行うことでBi-Encoderのデータセットを拡張することができます。個別ドメインで埋め込みモデルを試したいと思ったら、活用します。

https://github.com/UKPLab/sentence-transformers/tree/master/examples/training/data_augmentation
基本的なデータ拡張戦略はGold Datasetと呼ばれるラベル付きデータセットからCross-Encoderを学習させたのちに、それを用いてSilver Datasetと呼ばれるweekly Supervised Datasetを作成します。それらからBM25、シード最適化などを用いてサンプリングを戦略的に行いデータセットを作成します。
以上です。
Discussion