Go言語で高速JSONライブラリをメモリ安全にしたらさらに速くなった話
はじめに
こんにちは。Sugawara Yuutaです。"Go言語で最速のJSONデコーダーを作った話", "それでも僕はGoで最速のJSONデコーダーを作りたかった"...以来の方はまた読んでいただきありがとうございます。まだの方は、経緯を伝えやすくなると思うので、そちらの方も読んでいただけたら幸いです。
その後
Go言語チームのメンバーが取り組んでいる新しいバージョンのJSONライブラリであるgo-json-experiment/jsonというレポジトリを発見しました。(厳密に言うと、知ってはいたのですが中身等は見ていない状態でした。) そこで学んだことが少しでも役に立てばとissueを提出したところ、そのときのJSONデコーダーに足りないものが見えてきたため、今回は僕の見つけた課題と、どのように解決しようとしたか・したかを話せればと思います。
見つけた課題
パフォーマンスも重要ですが、Go言語チームは「使うことがかんたん」で、「間違って使うことが難しい」くらいの (原文: easy to use, hard to misuse) ものを作ることを重要視しています。
速さよりも”正しさ”を優先することによりこのような素晴らしい言語が作れたのだなと改めて感動しました。
もうひとつ、気になったことがあります。コードの読みやすさです。前回のバージョンを書いた当初はあまり気にしていなかったのですが、他のプログラマーと協力して作業することもこれから増えていくと思うので、読みやすいコードを書くクセをつけることもまた、重要であると思いました。
最後に、メモリ安全です。前バージョンは他の殆どのライブラリと同様にunsafeを使うことによる高速化を狙うということをしていました。ランタイムリフレクションは重い作業であるため、unsafeを直接使用しオフセット等の換算・メモリのレイアウトが同じである別の型へのキャスト等する、という手法なのです。が、メモリ安全が破られるということを考えると(もしその使い方が危険でないにしても)避けるべきことなのでは?という疑問が浮かびました。
unsafeはgo:linknameという強い武器も同時にもたらします。他のパッケージから非公開の関数のエイリアスを持ってくることができるというものです。前作では、無駄なアロケーションやコピーを避けるために頻繁に使用していました。もちろん、非公開の関数ですので互換性などは保証されません - 実際に、これを使用したことに関するバグもリリース直後から複数発生していました。
課題の解決方法
難しいことなのですが、reflectというラッパーを使うことによってほとんどの問題は解決できます。メモリ安全は基本的に守られ、コードは読みやすくなります(unsafeよりreflectのほうが高レイヤー部分であるため前者では得られないヘルパー関数なども同時についてくる、というのもひとつです。)
もちろん、さきほどいったようにリフレクションは重い作業です。これに切り替えた上で速度を改善するということは可能なのでしょうか?
課題の解決
前セクションの問への答え:可能です。
まずはしたのベンチマーク結果を見てください。

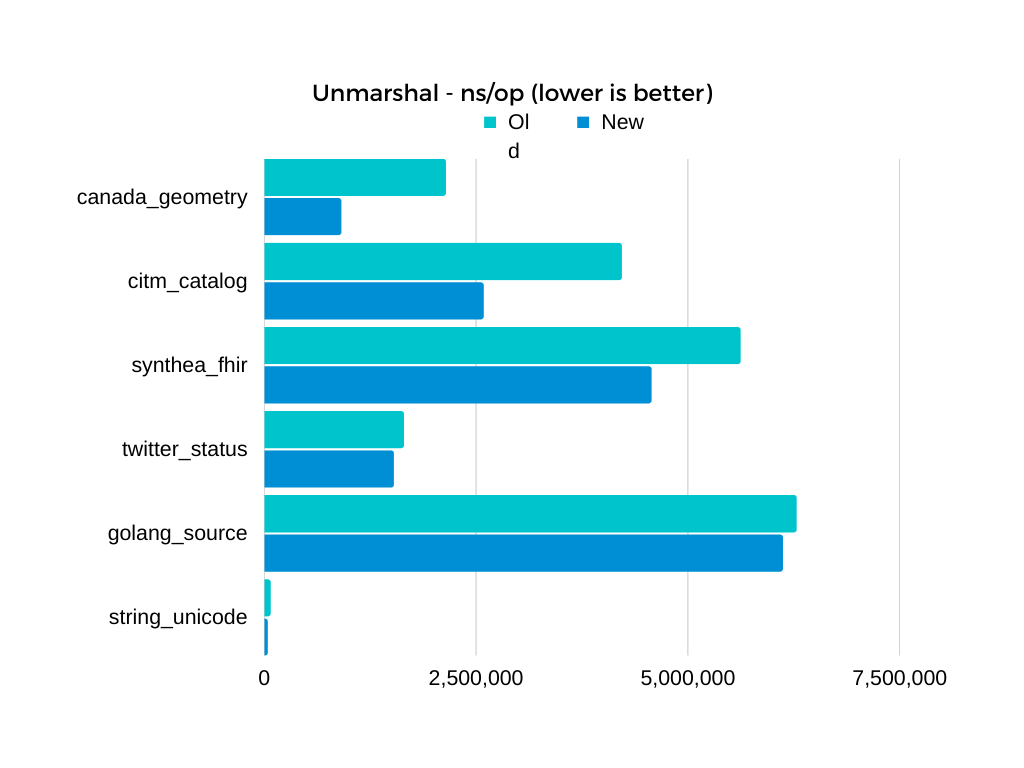
前バージョンに比べて、12このテストケースを使用した場合、(エンコード: 6こ、デコード6こ)そのうちの11こでより高速な成績を収めることに成功しました。
また、先ほど紹介したgo-json-experiment/jsonと比べると同じ状況下にあるにも関わらず、すべてのケースで上回っていて、ほとんどのケースで差は歴然です。
もちろん、パフォーマンスには使用する機械や状態、JSONの大きさ等に大きく左右されるため、もし気になるという方がいらっしゃいましたらご自分で計測されることを強くおすすめします。
なぜ可能なのか - 安全性と速度の両立の舞台裏
デコーダー高速化の例を4つ、挙げたいと思います。
- 高速に整数をデコードする
みなさんは整数のデコードには何を使っていますか?ほとんどの人がstrconvと言ったと思います。ただ、完璧な実装など存在しないのでもっと細かいユースケースに合わせて改良を試みることはできます。眼の前にある問題をシンプルにして変化を観察しやすいように、以下のようにします。
「string型の文字列の符号なし整数の表現をuint64にできるだけ高速に詰める」
もちろん、SIMD等使えば、今回作るものより先に行くことも可能なのですが、それだとGoだけで書くことが不可能になり、クロスプラットホームを保つための労力が無視できなくなります。
まずは思いつく一番シンプルな実装を考えます。以下のような感じでしょうか。
// 旧コードで一行漏れがありました。@jm様指摘ありがとうございます。
func parseUint1(str string) (uint64, error) {
var dst uint64
for len(str) >= 1 {
num := uint64(str[0] - '0')
if num > 9 {
return 0, strconv.ErrSyntax
}
add := dst*10 + num
if add < dst {
return 0, strconv.ErrRange
}
dst = add
str = str[1:]
}
return dst, nil
}
ASCIIコードでは'0' - '9'は横並びになっているため、読んでいるバイトから文字の0を引くことによって実際の整数を手に入れることができます。これは符号なし整数のため、それら以外の文字は存在することができません。よって、他の文字が出た場合にはエラーを返します(今回はダミー実装のためErrSyntaxを返します。)。
ちなみに、* 10はコンパイラがシフト命令の組み合わせに書き換えてくれるので、遅くなる心配はほとんどありません。さあ、これがstrconvと比べてどのようなパフォーマンスを出すか見てみましょう。
BenchmarkStrconvParseUint-4 1903638 3124 ns/op 0 B/op 0 allocs/op
BenchmarkParseUint1-4 2862594 2091 ns/op 0 B/op 0 allocs/op
なかなかいいですね。標準ライブラリ(上)と比べて約1.5倍の速度が出ています。理由として、標準ライブラリは10進数以外にも対応しているためブランチや関数呼び出しが重なることが考えられます。
これより速くできるのでしょうか。
できます。今存在する殆どのCPUのレジスタは64bitであるのに、上のコードでは8bitずつ処理していることに気づいたでしょうか?これをフルに使うことによって、さらなるスピードアップを狙えます。いかに例を示します。
const (
x01 = 0x0101010101010101
)
func makeUint64(u64 uint64) uint64 {
const mask = 0x000000ff000000ff
const fst = 100 + 1000000<<32
const sec = 1 + 10000<<32
u64 -= x01 * '0'
u64 = u64*10 + u64>>8
return (u64&mask*fst + u64>>16&mask*sec) >> 32
}
func canMakeUint64(u64 uint64) bool {
return u64&(u64+x01*0x06)&(x01*0xf0) == x01*0x30
}
どちらもインプットが整数では?と思った方、そのとおりです。ただこのuint64は64bit loadと呼ばれるものを行った結果得られるもので、アウトプットの数字とは全く違います。先程言ったとおり、64bitレジスタには8bitが8つ - つまり8バイト入るため、実質8文字同時に操作できます。これのしくみについてはこの方のブログでよく紹介されているため、そちらをご覧ください。実装が32bitのため、64bit用の実装はDaniel Lemireさんの記事をご覧ください(ちなみに、この方も高速なJSONライブラリを作っています)。それでは、これのパフォーマンスも見ていきましょう。
BenchmarkParseUint2-4 4444332 1349 ns/op 0 B/op 0 allocs/op
また速くなりました。残念ながら、JSONのように何桁の数字がはいっているかわからない場合は無駄に読み込んでしまう場合もあるので注意が必要です。
- 高速にオブジェクトの名前が構造体内に存在するか確認する
構造体のフィールド情報は型ごとに決まっていて、先に名前の衝突の確認や優先度を適用させるなどの計算しておくこともできます。ただ、この構造体の情報に実際に流れてくるオブジェクトの名前を照らし合わせる作業は頻繁に起こる作業であり、時間がかかる場合も多いです。ということで今回はこれの高速化を考えていきます。
まず、最初に思いつくのはmapでしょうが、mapは挿入やループにもある程度高速に動作するように作られているため、ルックアップの割合が多い作業には不向きな可能性があります。この場合、ルックアップは挿入よりもずっと重要ということが先程の説明だけでもわかっていただけたと思います。どころか、最初にすべての情報を使ってデータ構造を作成し、読み取り専用で挿入が必要なくさせることすらできます。
これには前からシードをシャッフルする形の完全ハッシュ関数を利用していたのですが、ハッシュを単純化のためにループ展開したFNV1-aを使用していたため、分布は最高ではありませんでした。ここから考えられるのは、ハッシュを改善する必要があるということです。少しトリッキーなところは大文字小文字関係なく探索を行わなければいけない場合が多く存在するということです。
また、問題をシンプルにして以下に示します。
「アルファベットを小文字にしてできるだけ高速にハッシュを取得する」
ということでまずは英単語3000語を利用して標準ライブラリではどのハッシュが速いか小文字化込でみていきます。
BenchmarkFNV1a-4 35215 166097 ns/op 28488 B/op 3000 allocs/op
BenchmarkCRC32-4 34110 177475 ns/op 28488 B/op 3000 allocs/op
BenchmarkAdler32-4 35414 167569 ns/op 28488 B/op 3000 allocs/op
BenchmarkMaphash-4 37741 161913 ns/op 28488 B/op 3000 allocs/op
bytes.ToLowerを使うと、アロケーションのせいでそれぞれのハッシュが本当の力を出せていないように見えます。毎回バイト配列を作り直す代わりに再利用したらどうでしょうか?文字はすべてASCIIなので実装は難しくないはずです。例を以下に示します。
func appendToLower(dst, src []byte) []byte {
for _, char := range src {
if char >= 'A' && char <= 'Z' {
dst = append(dst, char|('a'-'A'))
continue
}
dst = append(dst, char)
}
return dst
}
ここで唯一面白い部分はおそらくOR(|)でしょう。気になった方はASCIIテーブルを見たらわかりやすいと思います。ToLowerを上の実装に置き換えて再度測ると...
BenchmarkFNV1a-4 105688 55860 ns/op 0 B/op 0 allocs/op
BenchmarkCRC32-4 82906 70441 ns/op 0 B/op 0 allocs/op
BenchmarkAdler32-4 95647 61397 ns/op 0 B/op 0 allocs/op
BenchmarkMaphash-4 101689 59381 ns/op 0 B/op 0 allocs/op
差が大きくなりましたね。maphashやループ展開したFNV1-aが速いようですね。
ところで、僕が実際に使っているハッシュ関数の速度は以下のようです...
BenchmarkHash32Lo-4 346429 16303 ns/op 0 B/op 0 allocs/op
アセンブリを使っているmaphashより何倍も速いという結果が出ています。これは先程話した64bit loadや32bit loadを駆使しているからです。例えば、これを使って最初の8バイトを読み込んだ場合、上で紹介した|('a'-'A')と組み合わせることによって小文字にする作業とハッシュを一体化させることが出来ます(ただし、これは文字列が一部のASCIIのみで成り立っているとわかる場合だけに利用できます - 例えば、アルファベットや数字など。)'a'-'A'は32, 16進数で0x20なので64bitだと0x2020202020202020のようになります。つまり、この大きい整数をORするだけで、小文字化された・大文字化された結果のハッシュを得ることができます。実装例は以下です。
var (
lit = binary.LittleEndian
)
const (
wy1 = 0x53c5ca59
wy2 = 0x74743c1b
wy3 = wy1 | wy2<<32
)
const (
lo8 uint8 = 0x20
lo32 uint32 = 0x20202020
lo64 uint64 = 0x2020202020202020
)
func hash32Lo(buf []byte, seed uint32) uint32 {
hash := uint64(seed^wy1) * uint64(len(buf)^wy2)
if len(buf) != 0 {
for ; len(buf) > 8; buf = buf[8:] {
hash = hash ^ (lit.Uint64(buf) | lo64) ^ wy3
hash = (hash >> 32) * (hash & 0xffffffff)
}
hi, lo := hash>>32, hash&0xffffffff
if len(buf) >= 4 {
hi ^= uint64(lit.Uint32(buf) | lo32)
lo ^= uint64(lit.Uint32(buf[len(buf)-4:]) | lo32)
} else {
lo ^= uint64(buf[0] | lo8)
lo ^= uint64(buf[len(buf)>>1]|lo8) << 8
lo ^= uint64(buf[len(buf)-1]|lo8) << 16
}
hash = (lo^wy1)*(hi^wy2) ^ wy3
hash = (hash >> 32) * (hash & 0xffffffff)
}
return uint32(hash>>32) ^ uint32(hash)
}
実際のハッシュ関数は32ビットバージョンのWyhashをつかっています。このハッシュ関数はGo言語の内部実装でも利用されています。
- 高速で文字列で表現されている小数から
float64に変換する
これに関しては問題をシンプルにしてかんたんな例からというわけにはいかないのが本当のところです。というのも、float32/float64は整数型のように数字を完全に正確に表せられるというわけではないのです。それに、strconvもすでにホットパスでは高速な処理を使っています。改善できる場所はあるのでしょうか?僕が気づいたのはParseFloatを使うために小数リテラルの終わりを見つける必要があるということでした。余分にその関数に文字列を入れてもその文字列全体が有効な小数を表していないとエラーになります。そこで、バッファのイテレーションが1回ですむように、Daniel Lemireさんの高速ダブルパーサーをGoにポートして使用することにしました。最初の方に貼ったグラフでもわかるように、これは相当な高速化をもたらしました。(特にcanada_geometryが浮動小数点数を多く含むデータです)
- 高速でスペースをスキップする
フォーマットされたJSONドキュメントで一番と言ってもいい量存在するのがスペースやタブです。JSONでは、インデントは文法において関係ないため、完全に無視することができます。さて、高速でスキップする方法を考えてみましょう。おそらく一番シンプルなのは、スペースの全4種類を順番に比較することでしょう。ただ、他にも方法はあります。
const spaces uint64 = 1<<' ' | 1<<'\n' | 1<<'\r' | 1<<'\t'
if 1<<char&spaces != 0 {}
これは1バイトが8bitの数字であることを利用して、その回数分だけシフトし、先に作っておいた64bit整数にANDすることによって一致を見るという例です。
前回紹介した固定長のテーブルを使う方法とは違い、メモリ使用量が大幅に少なくなるということも利点です。
さらに先ほど紹介した64bitレジスタに詰めることによる高速化(一般的には、SWARといいます)をつかうこともできます。
最初僕の実装に抜けていたことは、インライン化でした。この関数はよく呼ばれるものであったために、関数呼び出しに時間を食っていたことに気づき、最初の文字がスペースでなかった場合、リターンする。他の場合、別の関数を呼び、上で紹介した技術を使ってスペースをスキップする。というような実装を組み込んだところ、スペースがないようなJSONファイル等でのスピードの減少を抑えることができました。また、SWARを使用した場合のどこで最初のスペースでない文字が出現するかは、<math/bits>.TrailingZeros64で知ることができます。
ちなみに、math/bitsパッケージは実際に.goファイルで定義されている関数だけでなく、パフォーマンスのためにコンパイラが直接置き換える可能性も小さくないため、この場合このパッケージに頼っておくのがよい策だとおもいます。
おわりに
ということで今回は僕が新しい課題に対して行ったことと例を4つ紹介しました。
また、これの続きやエンコーダー編もやっていきたいと思っているので気軽に新しい記事もチェックしてくれると嬉しいです。また、今回改善したレポジトリを貼ってこの記事を締めくくりたいと思います。
ありがとうございました。
Discussion
Jsoniter-Scala というライブラリの README に爆速 JSON パースの知恵がまとまっているので(JVM の特性によるものもありますがそれ以外の部分もあるので)もし興味があれば見てみると面白いかもしれません.
Goにあるjsoniterとは作者は別なのですかね?ともかく、とてもおもしろそうです!ありがとうございます。
parseUint1ですが、1行漏れていませんでしょうか?元のコードだと毎回0になると思いました。
参考: https://go.dev/play/p/ktS251xIa1w
申し訳ないです!ここに載せるときに何かを間違えたようです...
編集可能であればさせていただきます。