2022年 個人的 Google Spreadsheet の(頻出?)便利技 7選



※この記事は、CyberAgent PTA Advent Calendar 2022の20日目の記事です。
株式会社AbemaTV ビジネス開発本部 で広告システムのエンジニアをしています @shunta-furukawaです。
あっというまに一年が過ぎてしまいました。 アドベントカレンダーを書くとすっかり年末になったんだなと感じる今日この頃でございます。
さて、 普段は Go言語 でプログラムを書くことが多いのですが、それと同じぐらい Google Spreadsheet 様にはお世話になっております。 例えば、ちょっとしたデータ出しや、障害調査の結果のまとめ、開発物の仕様まとめ、テスト項目の洗い出しなど、さまざまな用途に使っております。 こういった、細かい一時的なタスクで主に活躍するスプレッドシート様ですが、そうすると自ずと省力化しようといろんなネタ工夫が身に付くわけですね... なので 今年よく使ったものから、今後使えそう!!ってものまで 自分なりに良さそうなスプレッドシートに関係するネタ工夫をごっそり紹介していこうと思います。
ちなみに今回の記事を書くに当たって、説明用に作ったスプレッドシートがこちらです。
それぞれの工夫の価値が伝わりやすいように、例として Wikipedia の 日本のテレビアニメ作品一覧 (2020年代 前半)からデータを引用してスプレッドシートで加工するシチュエーションを想定して もろもろ書いています。それを踏まえてご覧ください。
1.LAMBDA関数で関数の記述量を削減する
今年一番の収穫だったと思うのは LAMBDA関数 が使えるようになったことです。
これは、プログラミング言語でいう クロージャー関数や即時関数に近い概念で、重複するような表現がおなじ関数内にあった場合に LAMBDA関数でラップをしてあげると記述量が格段に削減できるだけでなく、引数による同一性も表現できるようになるので、関数の可読性も上がります!
例えば、以下のようなシーンで利用数ことが多かったです。
- 動的な範囲における FILTER 表現
- 動的な範囲における ARRAY_CONSTRAIN 適応
- 日付の加工
動的な範囲における FILTER 表現
FILTER関数 は フィルタをかける条件にかかる元の範囲と同じ行数の範囲を指定することが多いです。
例えば
=FILTER(A2:A26, A2:A26 > 5)
という関数を考えた場合、
FILTERの第一引数の範囲A2:A26 に変更があった(例えばA2:A32と範囲を広げるなど)場合に、第二引数の A2:A26 > 5 の範囲も変更を加えなければならず、二度手間になってしまいます。
そこで LAMBDA で以下のように書き換えてあげると
=LAMBDA(RNG, FILTER(RNG, RNG > 5)(A2:A26)
範囲に変更があった場合に引数の A2:A26 を一箇所変更してあげるだけで修正が完了するようになります。
動的な範囲における ARRAY_CONSTRAIN 適応
ARRAY_CONSTRAIN関数は、範囲を任意の行数および列数に制限したい場合に用いられる関数です。
この関数の厄介なところは、行数と列数を両方とも指定する必要があるというところです。
例えば、A1 から C10 の範囲を 縦2行、横3列 にしたいと思った場合に 以下のような記述になります。
=ARRAY_CONSTRAIN(A1:C10, 2, 3)
この第3引数の3列は、実はA〜Cの列数と同数なので、なにも制限がかかっていないのですが、列数も指定しなければいけないので、やむおえず範囲と同数の3を指定している のです。そこで、さらに A1:C10 の範囲 が列追加などで A1:E10 に変わった場合、刈り込む意図がなければ この変更のために、3から5に修正が必要になってしまいます。
これはとても冗長なので、LAMBDA関数で ラップすると簡潔になります。
=LAMBDA(RNG,ROWS,ARRAY_CONSTRAIN(RNG,ROWS,COLS(RNG))(A1:C10,2)
このように記述すると、 A1:C10 の範囲が変わった場合にも柔軟に列数が変わり、行数だけが制限されるようになります。
実は、この2つを組み合わせると、2列以上のFILTER関数がすっきりかけます。
=LAMBDA(RNG, FILTER(RNG, ARRAY_CONSTRAIN(RNG,ROWS(RNG),1) > 5)(A2:B26)
日付の加工
実は、任意のタイムスタンプ (秒まで描いてある) から日付への加工というのが少し面倒くさかったりします。
例えば 今現在の時刻 =NOW() から 今月の始まりを求めたい場合
=DATE(YEAR(NOW()), MONTH(NOW()), 1)
という書き方になります。 NOW() が冗長ですね...
こう言う場合も、LAMBDAを介してあげると変更されるべき場所が外だしされ、すっきりします。
=LAMBDA(D, DATE(YEAR(D), MONTH(D), 1))(NOW())
2.名前付き関数で複雑な関数を簡略化
LAMBDA関数 について説明をしましたが、いくらすっきりかけるとは言え、どうしても処理が複雑化すると記述量がとんでもないことになります。
例えば、こちらで wikipedia上の日本のテレビアニメ作品一覧のテーブル要素から アニメの情報を抜き出そうとする処理を書いています。
Google Spreadsheet の IMPORTHTML 関数を使うとページの任意の<table> タグを表として認識して インポートすることができますが、 期間の書き方が 10月30日 - 2021年1月29日 などとデータとしては扱いづらいフォーマットになっています。
以下、表のフォーマットを例示します。
| 開始日 - 終了日 | 作品名 | 制作会社 | 主放送局・系列[1] | 話数 |
|---|---|---|---|---|
| 1月4日 - 3月21日 | ダーウィンズゲーム | Nexus | TOKYO MX、AT-Xほか | 全11話 |
| 1月3日 - 3月27日 | 恋する小惑星 | 動画工房 | AT-X、TOKYO MXほか | 全12話 |
| 1月4日 - 3月28日 | へんたつ | irodori | TOKYO MX、BS11ほか | 全12話 |
| 1月5日 - 3月29日 | マギアレコード 魔法少女まどか☆マギカ外伝 | シャフト | TOKYO MX、AT-Xほか | 全13話 |
| 1月5日 - 2021年6月23日 | りばあす[注 1] | ライデンフィルム | TOKYO MX | 全49話 |
| 1月5日 - 3月22日 | 八十亀ちゃんかんさつにっき 2さつめ | サエッタ | TOKYO MX、TVA、AT-X | 全12話 |
上記の表を動的に読み込んだ上で、その上に
- 一番先頭の行を " - " で分割する
- 読み込み時にそれが、何年の作品かを渡し、年が書かれていたらその年を、そうでなければ渡した年を先頭につける
- その内容を元のインポートした内容と結合して表示する
- テーブルを読み込むたびにヘッダ行が出てくると重複するので除外する
などの処理を ワンライナーの関数で 描こうとすると以下のようになります。
=LAMBDA(TBL,{LAMBDA(SUBTBL,Y,ARRAY_CONSTRAIN(ARRAYFORMULA(IF(REGEXMATCH(TEXT(SUBTBL,"yyyy-MM-dd"),"2022"),LAMBDA(D, DATE(Y, MONTH(D), DAY(D)))(SUBTBL),SUBTBL)),ROWS(SUBTBL),2))(ARRAYFORMULA(SPLIT(ARRAY_CONSTRAIN(TBL,ROWS(TBL),1)," - ")),2020),TBL})(LAMBDA(RNG,REMOVE_KEY,FILTER(RNG,ARRAY_CONSTRAIN(RNG,ROWS(RNG),1)<>REMOVE_KEY))(IMPORTHTML(B1,"table",13,"ja_JP"), "開始日 - 終了日"))
LAMBDA を使いまくってもこの量なので、かなり複雑になってしまいました。
しかし、これは wikipedia の一つの表(1クール分) しか読み込めておらず、さらにこれを縦に結合していく必要があります。 この複雑な関数を重ねていくと、可読性もメンテナンス性も下がるので、ここで名前付き関数の出番です。
名前付き関数を作成する
メニューから「データ > 名前付き関数」を選択すると、「名前付き関数の編集」画面が 表示されます。
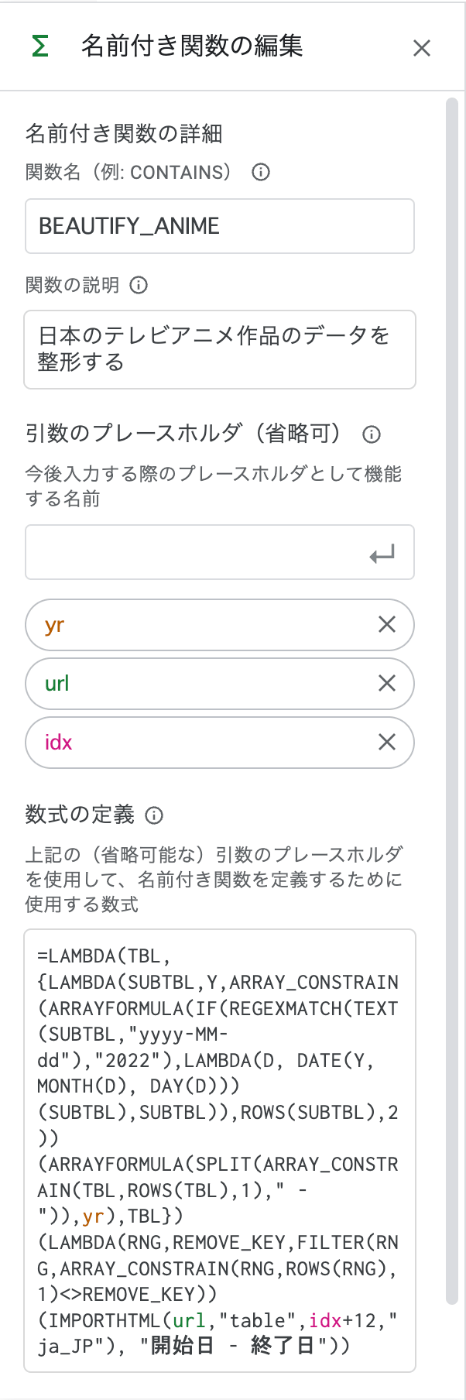
- 名前付き関数の詳細
- 関数の名前や説明を記入します
- 引数のプレースホルダ
- 指定する引数の設計をここでします
- 数式の定義
- 「引数のプレースホルダ」で指定した変数を含めて関数の定義をします。
これらを記入すると、 同じ情報量の関数が 以下の記述量に収まります。
=BEAUTIFY_ANIME(2020,B1,1)
さらに、ARRAY_ROW を用いて、結果を縦に繋げるときの可読性も上がります。
=
LAMBDA(URL, {
BEAUTIFY_ANIME(2020,URL,1);
BEAUTIFY_ANIME(2020,URL,2);
BEAUTIFY_ANIME(2020,URL,3);
BEAUTIFY_ANIME(2020,URL,4);
BEAUTIFY_ANIME(2021,URL,5);
BEAUTIFY_ANIME(2021,URL,6);
BEAUTIFY_ANIME(2021,URL,7);
BEAUTIFY_ANIME(2021,URL,8);
BEAUTIFY_ANIME(2022,URL,9);
BEAUTIFY_ANIME(2022,URL,10);
BEAUTIFY_ANIME(2022,URL,11);
BEAUTIFY_ANIME(2022,URL,12)
}
)("https://ja.wikipedia.org/wiki/%E6%97%A5%E6%9C%AC%E3%81%AE%E3%83%86%E3%83%AC%E3%83%93%E3%82%A2%E3%83%8B%E3%83%A1%E4%BD%9C%E5%93%81%E4%B8%80%E8%A6%A7_(2020%E5%B9%B4%E4%BB%A3_%E5%89%8D%E5%8D%8A)")
名前付き関数を用いることで、関数をどんどん抽象化すると メンテ性が格段に上がります。
3.可変データにARRAYFORMULAを適応する
ARRAYFORMULA関数は、関数を配列に対して一括適応するために用いる関数です。
ただ、この効果というだけで十分便利なのですが ARRAYFORMULA の使い方を少し工夫するたけで、適応する範囲を柔軟に適応できます。
- ARRAYFORMULA に渡す範囲を 最後まで指定する方法 で指定する。
- 条件に合わない行をエラーにしない工夫を加える
- ヘッダ行にヘッダを表示する条件を付け加える
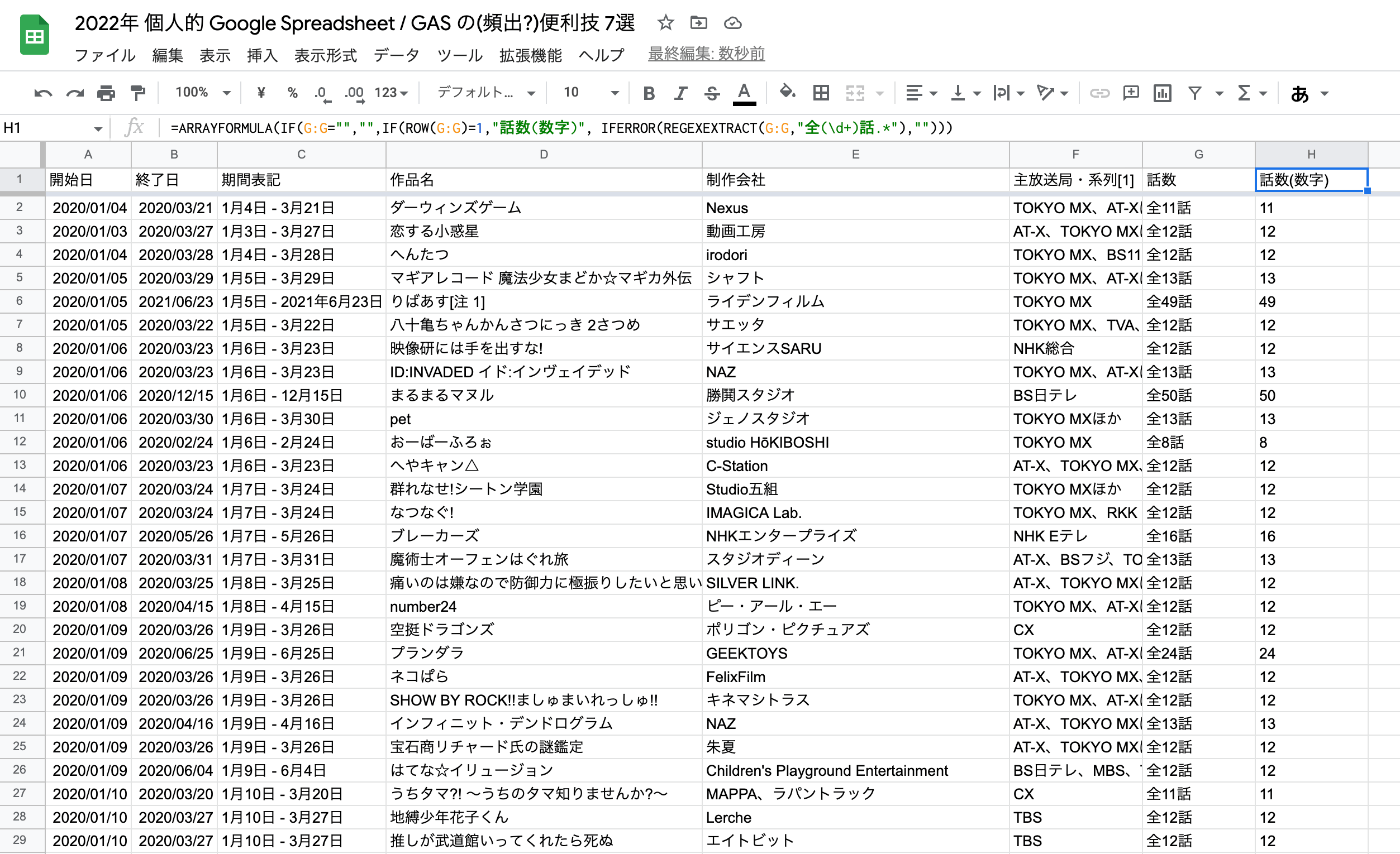
例えば、 アニメの話数 の表記に対して、数値に変換したものを横に表示するという処理を一括で かけることを考えます。
| 開始日 | 終了日 | 期間表記 | 作品名 | 制作会社 | 主放送局・系列[1] | 話数 |
|---|---|---|---|---|---|---|
| 2020/01/04 | 2020/03/21 | 1月4日 - 3月21日 | ダーウィンズゲーム | Nexus | TOKYO MX、AT-Xほか | 全11話 |
| 2020/01/03 | 2020/03/27 | 1月3日 - 3月27日 | 恋する小惑星 | 動画工房 | AT-X、TOKYO MXほか | 全12話 |
| 2020/01/04 | 2020/03/28 | 1月4日 - 3月28日 | へんたつ | irodori | TOKYO MX、BS11ほか | 全12話 |
| 2020/01/05 | 2020/03/29 | 1月5日 - 3月29日 | マギアレコード 魔法少女まどか☆マギカ外伝 | シャフト | TOKYO MX、AT-Xほか | 全13話 |
| 2020/01/05 | 2021/06/23 | 1月5日 - 2021年6月23日 | りばあす[注 1] | ライデンフィルム | TOKYO MX | 全49話 |
| 2020/01/05 | 2020/03/22 | 1月5日 - 3月22日 | 八十亀ちゃんかんさつにっき 2さつめ | サエッタ | TOKYO MX、TVA、AT-X | 全12話 |
↓
| 開始日 | 終了日 | 期間表記 | 作品名 | 制作会社 | 主放送局・系列[1] | 話数 | 話数(数字) |
|---|---|---|---|---|---|---|---|
| 2020/01/04 | 2020/03/21 | 1月4日 - 3月21日 | ダーウィンズゲーム | Nexus | TOKYO MX、AT-Xほか | 全11話 | 11 |
| 2020/01/03 | 2020/03/27 | 1月3日 - 3月27日 | 恋する小惑星 | 動画工房 | AT-X、TOKYO MXほか | 全12話 | 12 |
| 2020/01/04 | 2020/03/28 | 1月4日 - 3月28日 | へんたつ | irodori | TOKYO MX、BS11ほか | 全12話 | 12 |
| 2020/01/05 | 2020/03/29 | 1月5日 - 3月29日 | マギアレコード 魔法少女まどか☆マギカ外伝 | シャフト | TOKYO MX、AT-Xほか | 全13話 | 13 |
| 2020/01/05 | 2021/06/23 | 1月5日 - 2021年6月23日 | りばあす[注 1] | ライデンフィルム | TOKYO MX | 全49話 | 49 |
文字列から数値を変換する処理は以下のように書けます。(G2 は "全◯話" と記載のある単一セル参照)
=INT(REGEXEXTRACT(G2,"全(\d+)話.*"))
これを、単純にARRAYFORMULAに当てはめると以下のように書けます。
=ARRAYFORMULA(INT(REGEXEXTRACT(G2:G621,"全(\d+)話.*")))
この書き方の問題点はいくつかあります。
-
今アニメが何本あるのか,いつアニメが増えていくのか が明確でない場合、
G2:G621の621が決まらない。変更があった場合に、ここの621の変更が必要になる。 -
G2から指定しているので、H2など、2行目への関数埋め込みになるが、A~G列の並べ替えをされてしまうと壊れる。 - G列にデータがない場合に「#N/A」が表示されてしまう。
これらの問題を解決するために、以下のような関数の工夫を入れていました。
-
今アニメが何本あるのか,いつアニメが増えていくのか が明確でない場合、
G2:G621の621が決まらない。変更があった場合に、ここの621の変更が必要になる。- =>
G:Gと G列全体を処理対象としてしまう
- =>
-
G2から指定しているので、H2など、2行目への関数埋め込みになるが、A~G列の並べ替えをされてしまうと壊れる。- => 1行目に関数を書き、「もし1行目だったら ヘッダ行のラベルを表示」という処理をたす
- G列にデータがない場合に「#N/A」が表示されてしまう。
- => エラーだったら表示しないという処理を追加する
これらの対策を入れると以下のように書けます。
=ARRAYFORMULA(IF(G:G="","",IF(ROW(G:G)=1,"話数(数字)", IFERROR(INT(REGEXEXTRACT(G:G,"全(\d+)話.*")),"")))
)
4. 柔軟にVLOOKUPをする
VLOOKUP関数は スプレッドシートで最も多用する関数だと思っています。 ただ、この関数の仕様は面倒で、探索対象の範囲の一番左が検索キーが格納されている列だという決まり があります。
故にたとえば、以下のようなテーブルがあった場合
| 開始日 | 終了日 | 期間表記 | 作品名 | 制作会社 | 主放送局・系列[1] | 話数 |
|---|---|---|---|---|---|---|
| 2020/01/04 | 2020/03/21 | 1月4日 - 3月21日 | ダーウィンズゲーム | Nexus | TOKYO MX、AT-Xほか | 全11話 |
| 2020/01/03 | 2020/03/27 | 1月3日 - 3月27日 | 恋する小惑星 | 動画工房 | AT-X、TOKYO MXほか | 全12話 |
| 2020/01/04 | 2020/03/28 | 1月4日 - 3月28日 | へんたつ | irodori | TOKYO MX、BS11ほか | 全12話 |
| 2020/01/05 | 2020/03/29 | 1月5日 - 3月29日 | マギアレコード 魔法少女まどか☆マギカ外伝 | シャフト | TOKYO MX、AT-Xほか | 全13話 |
| 2020/01/05 | 2021/06/23 | 1月5日 - 2021年6月23日 | りばあす[注 1] | ライデンフィルム | TOKYO MX | 全49話 |
| 2020/01/05 | 2020/03/22 | 1月5日 - 3月22日 | 八十亀ちゃんかんさつにっき 2さつめ | サエッタ | TOKYO MX、TVA、AT-X | 全12話 |
作品名から制作会社などは簡単に引くことができます。 作品名が D列、制作会社がE列にある場合以下のように書くことができます。
=VLOOKUP("へんたつ",D2:E,2,FALSE)
しかし、この書き方。作品名をキーとした場合に 作品名より左側の項目を引くことができません。
列を入れ替えてあげればいいとお思いかもしれませんが、 このデータは Wikipedia から IMPORTHTML 経由で取得しているため、元のデータの列の順番通りにしか並ばず、入れ替えることは困難です。
では、どうすればいいかというと、検索対象の範囲を {}を使って組み上げると自然と左側の列でもアクセスが可能になります。 例えば開始日を引きたい場合。
=VLOOKUP("へんたつ",{D2:D,A2:A},2,FALSE)
と書くことができます。 {D2:D,A2:A} というのは、一時的に 以下のようなテーブルを作っているイメージです。
| 作品名 | 開始日 |
|---|---|
| ダーウィンズゲーム | 2020/01/04 |
| 恋する小惑星 | 2020/01/03 |
| へんたつ | 2020/01/04 |
| マギアレコード 魔法少女まどか☆マギカ外伝 | 2020/01/05 |
| りばあす[注 1] | 2020/01/05 |
| 八十亀ちゃんかんさつにっき 2さつめ | 2020/01/05 |
これでもともと左側にあった列の検索も柔軟にできるようになりました。
これを覚えてから、元データの整形にあまり力を入れずに気軽にVLOOKUPを使えるようになりました。
5.データ入力規則を動的に切り替える
データの入力規則は、何かユーザに入力を求めるときに協力な武器になります。
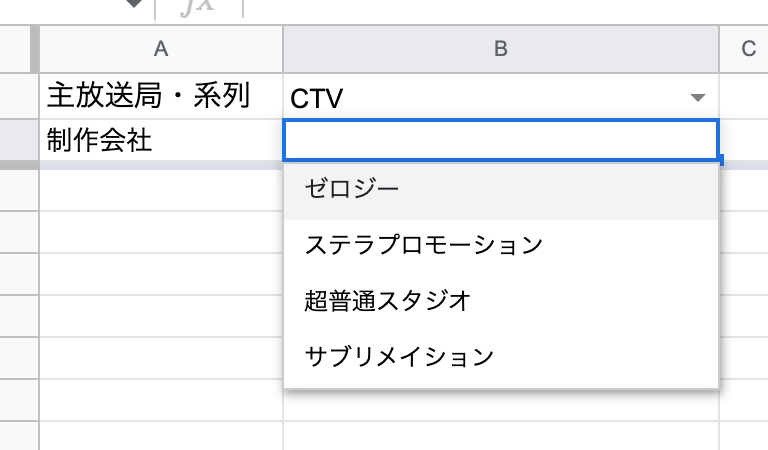
例えば 取得したアニメ一覧から 別シートで 絞り込み検索を行いたい場合、主放送局などは表に存在する候補の中から選べた方が自由入力よりも選択するコストが下がります。
例えば このような形

データの入力規則で制限をかける場合、ドロップダウンリストの候補は範囲指定を行います。
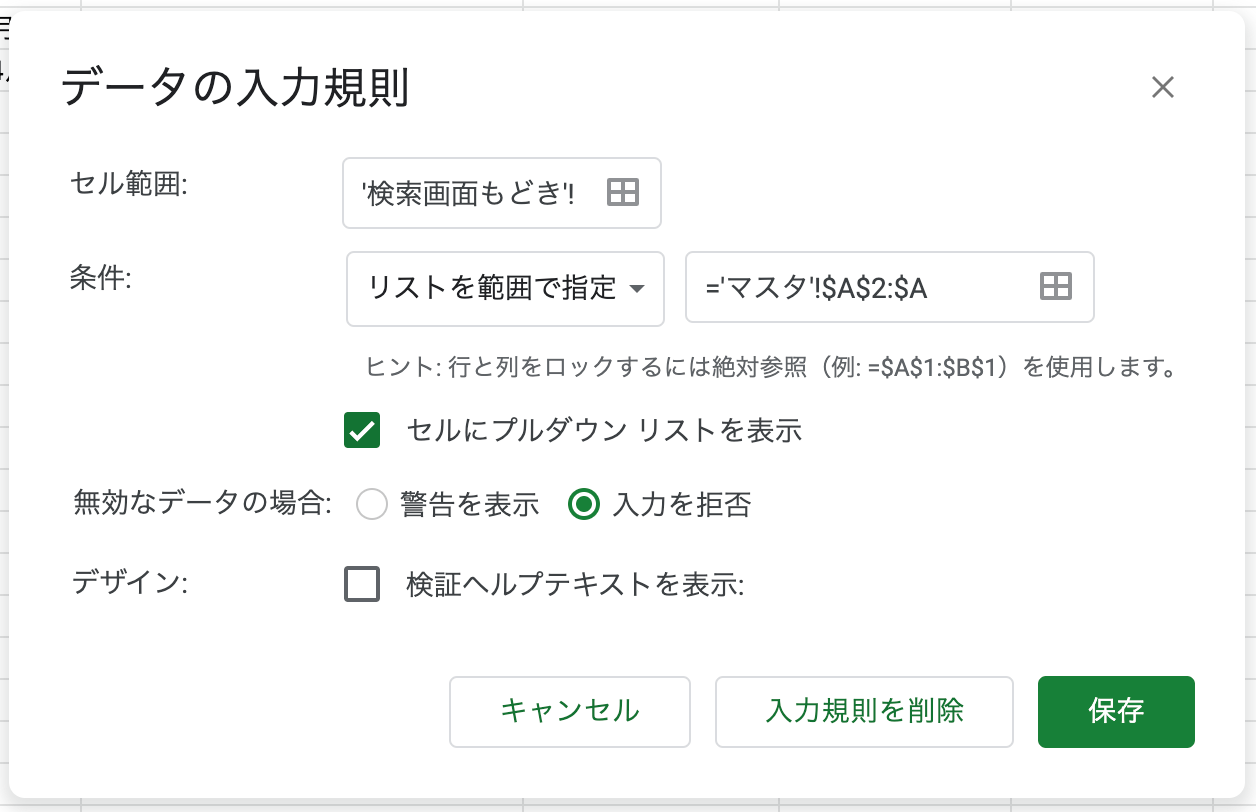
候補はこの範囲での指定方法か、直接指定しかなく、どうしても固定のリストしか指定できなさそうに見えます。
なので、例えばここから「主放送局・系列」を選んだ時に、その結果を踏まえて「制作会社」の選択肢をあらかじめ絞り込んで表示させたいとなった場合にできなさそうです。
ですが、範囲に対して 特殊な処理を挟むことによって、さも選択肢が動的に生成されているように見せかけることはできます。
以下のような マスタのシートを一つ準備しておきます。
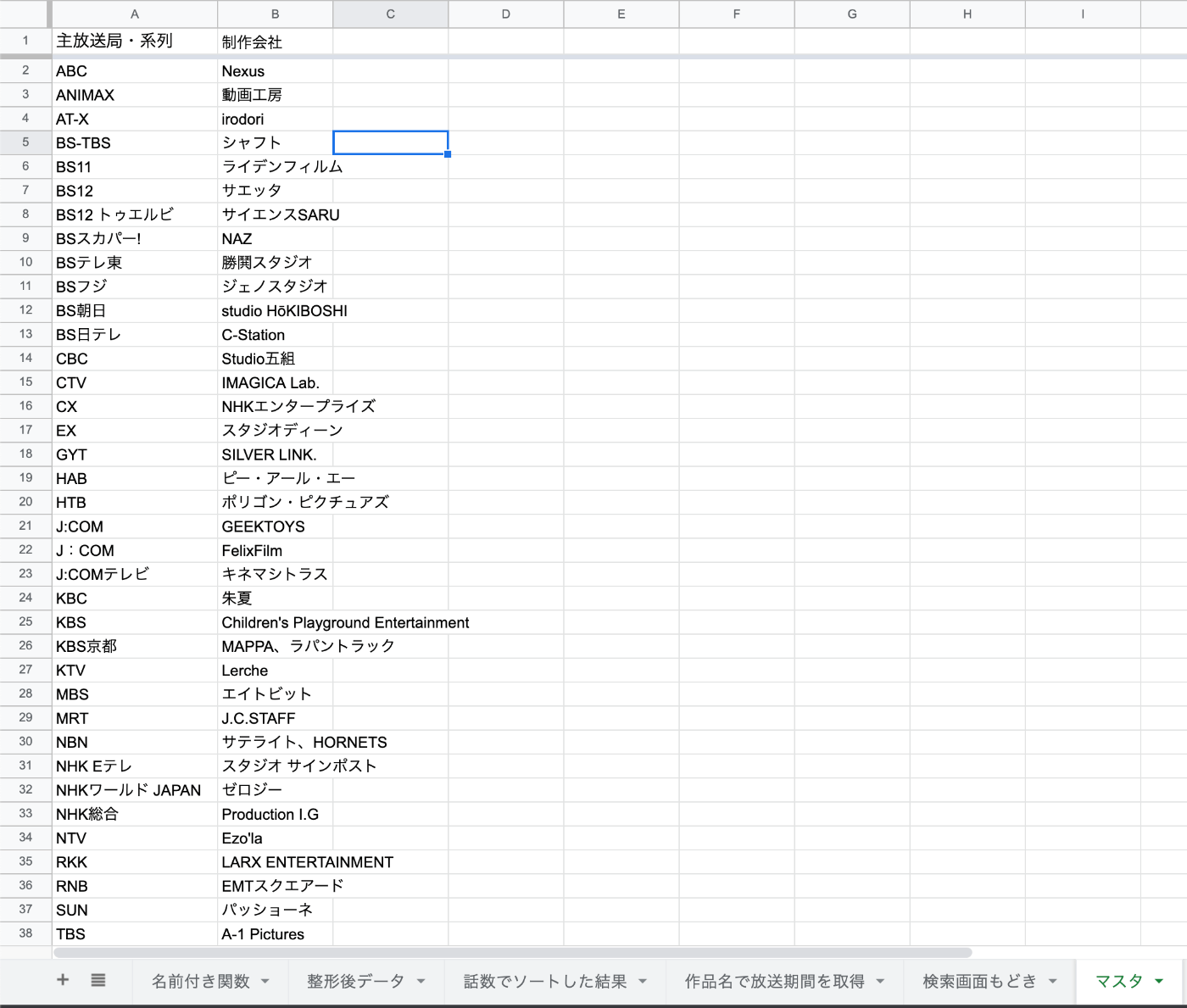
その上で、 B列を 「制作会社」のマスタにしておき、 検索シートでデータの入力規則の対象マスタをこの範囲に設定しておきます。
そして、検索画面の「主放送局・系列」 の値を見て、B列のリストの中身を書き換えます。
=UNIQUE(FILTER('整形後データ'!E2:E,REGEXMATCH('整形後データ'!F2:F,'検索画面もどき'!B1)))
こうしておくことで、 元のデータで 「主放送局・系列」が 選ばれたものの「制作会社」だけがB列に表示され、
絞り込み検索のようなものが実現できます。
| CTV | WOWOW |
 |
 |
6.条件付き書式を行全体に適応する
データから特定の特徴をもった行をわかりやすく表示したいという場面はよくあります。
そういうときに、条件付き書式にうまく数式を埋め込むと簡単にその特徴をもった行を目立たせることができる上に、自分自身で書式を逐次いじる必要がなくなります。
例えば、(あんまり例はよくないかもしれないですが) 先ほどの検索画面でタイトルに「魔」が入っているアニメを確認したい場合に、その行を 紫 にしたいとします。
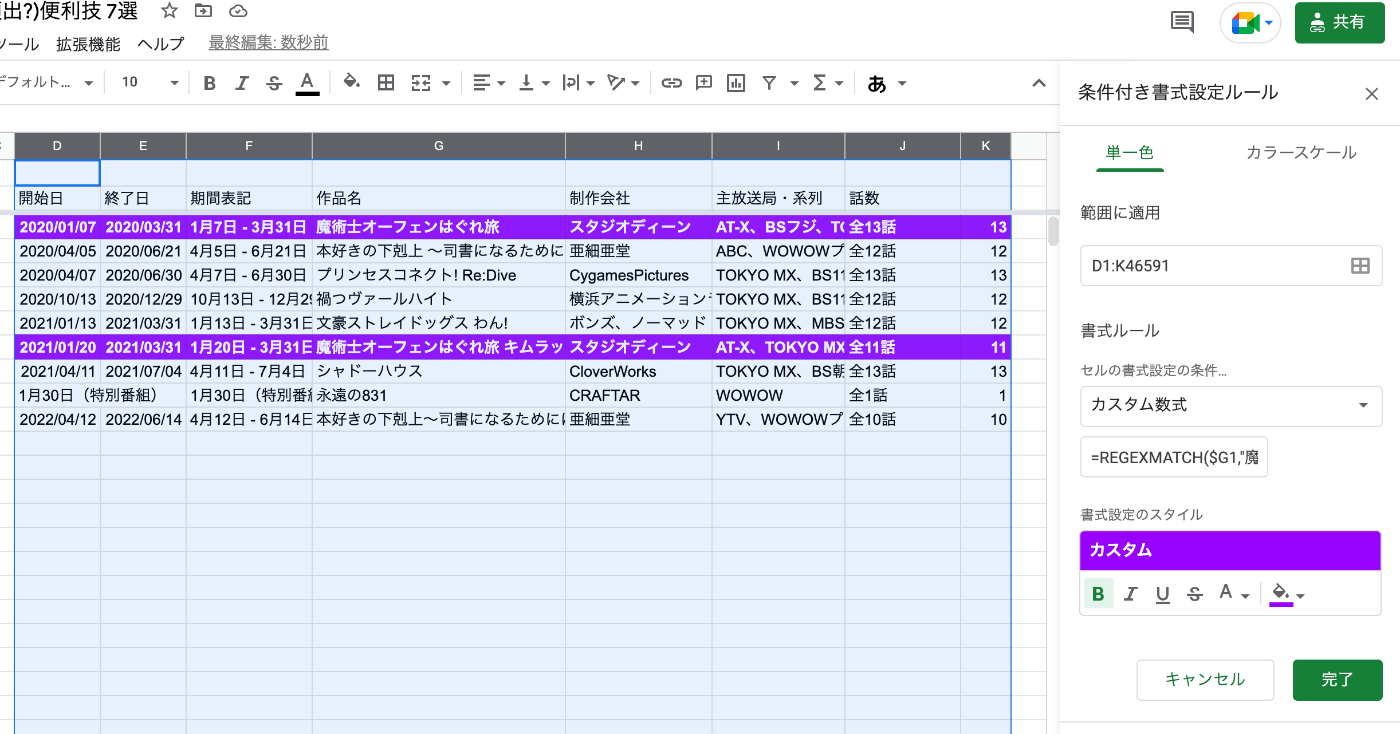
単一列のルールに則って行全体に書式を適応したい場合は、条件付き書式の設定ルールの設定で
「書式ルール」を「カスタム数式」にします。
その上で、範囲の左上(画像の例でいうと、D1) を基準にして条件を書いていきます。
カスタム数式内での参照は $ をつけないと相対参照、つけると絶対参照になります。
そのため、D1〜K1 までの範囲において $G1 と記述すると、G列が必ず評価対象になります。
それを踏まえて、カスタム数式に以下のように記述すると、 タイトルに「魔」が含まれたアニメだけが書式の変更対象になります。
=REGEXMATCH($G1,"魔")
7.SPARKLINEで表のままデータを可視化
データを視覚的に判断するためにはグラフが役立ちますが、 グラフは表に覆い被さる形で表示されるのでなかなか表との一体感が出なかったりします。 また、関数などが入り込む余地が狭いのでわかりやすい見た目になるのに工夫が必要だったりする(感覚を持っています。)
そこで、SPARKLINEを使うと セルの表示の中にグラフを入れ込むことができます。
=SPARKLINE(K5,{"charttype","bar";"max",25;"color1",IF(REGEXMATCH(G5,"魔"),"purple","gray")})
話数を数値かしたものをグラフにしました。また、関数を入れ込むことで、タイトルに「魔」が入っているもののグラフの色を変えることもできます。
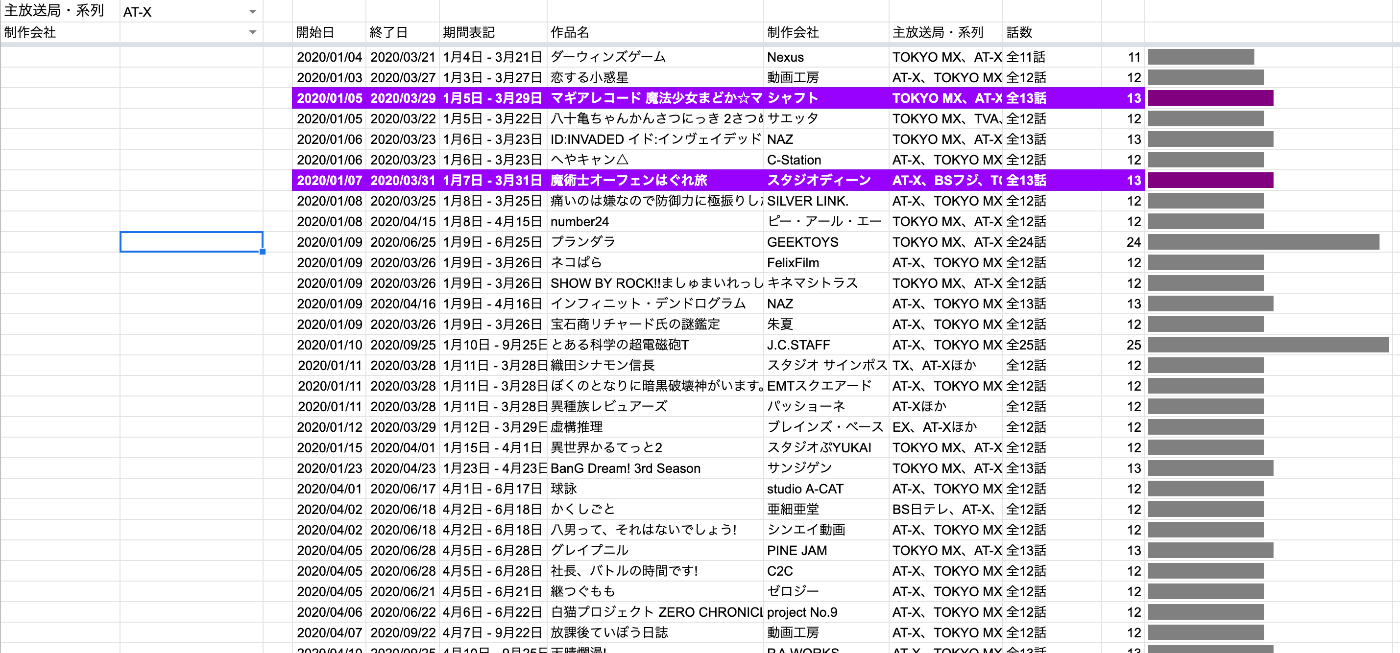
検索条件を変えても、紫色が追随してきます。

まとめ
堅牢な業務システムを作るには、きちんとプログラムを書いてシステムを組んだ方がいいと思いますが
反面一時的な業務もたくさんあるのも事実です。スプレッドシートを使うとそういった業務を快適に捌ける...かもしれないので 今年もスプレッドシートにきちんと感謝して来年もたっぷりスプレッドシートのネタをかけるように精進します。
良いお年をー!!
Discussion