さぼです、沖縄でWebと設計について考えてます。2023/09/23 に沖縄で行われたTechBaseOkinawa2023 にて上記のタイトルで登壇しました。
今回の内容は
- GraphQLを設計の観点から考えてみる
- GraphQLの目的や用途を整理する
- GraphQLを使う時、または使わない時のヒントを持ち帰ってもらう
- 最近、GraphQLじゃなくてRESTで良くないと思うケースがなんとなくわかってきたのでそれを共有する
という感じで話しました。話した内容を文字に起こし少し改修してZennでも共有することとします。
まえおき
- 最近はクライアントAppとサーバーAppを分けて実装する事が増えてきた
- クライアントの環境はますます複雑になっている
- クライアントとサーバーはWebAPIで通信を行う
- クライアントが複雑になるのと同時にWebAPIの要求が更に増して来ている
- APIの要求・応答を効率化する必然性が立ち現れてくる
GraphQLの目的と設計思想
GraphQLのターゲット
主にサービス要求の高い複雑なWebクライアントとAPI
- ブラウザ, ネイティブアプリ
- 特にエンゲージメントが重要な場合
- 同期的・オンライン
- 低レイテンシ
- 不特定多数の利用者
- 利用者毎に構造は同じだが異なるデータが要求される(ログインユーザー毎)
- オリジンに問い合わせるしかない
ターゲットではない
- 非同期・オフライン
- バッチ処理
- サーバー間連携
- レイテンシがあまり考慮されない
GraphQLの設計思想と目的
ここで紹介する内容がGraphQLのコアコンセプト、キーバリューだと考えています。このあたりでサービスの要件にクリティカルに効く場合に特にGraphQLは有効な手段となります。
- ネットワーク
- データの構造と操作
- アーキテクチャ
- クラサバの状態同期
- 開発プロセス
ネットワーク
- ネットワークトラフィックの最適化
- リクエスト内のデータの集積度を上げるアプローチ
- 往復回数が減る(量)
- データの有効率が上がる(質)
こんな問題を解決する
- サービス提供に必要なリクエストの往復回数を減らす
- リクエスト回数を減らす事により通信のオーバーヘッドを減らす
- Keep-Aliveが使えない規模のケース(?)
- 不要なデータ送信によるトラフィック量の増加を抑える
- レイテンシが長くかかるクライアントのUXの向上
こんな問題は解決しない
- 膨大な量の書き込み(ストリーミングデータ処理系が得意)
- 特定少数クライアントとの膨大な量の双方向通信(gRPCとかが得意)
- 不安定な通信環境(MQTTとかが得意)
データの構造と操作
- GraphQLではスキーマとクエリを使って定義・利用する
- スキーマではサービス上の全てのデータと操作が閲覧・利用できる
- 最大で定義し、最小で利用する
スキーマ
- あるオブジェクトが持ちうるフィールドを最大限盛り込むことができる
- 計算量が可変であるため、実行時の計算量を考慮せずにスキーマ定義しやすい
- 将来的な利用ケースなどを考えずに済みます
- スキーマは拡張しやすいため、未来のユースケースの事を考慮せずに定義しやすい
- 現在見えているスコープで定義することが出来る
- 心理的安全に設計出来る
- 現在見えているスコープで定義することが出来る
クエリ
- クライアントがクエリを用いて要求出来るため1回のリクエストで必要なデータが取得出来る
- 必要以上のデータを要求せずにすむ(オーバーフェッチ問題)
- リクエストのN+1が発生しない(アンダーフェッチ問題)
- サーバーでは要求されたフィールドだけ計算する
アーキテクチャ
- ネットワークトポロジーの最適化
- クライアントと対話するAPIサーバーが1台に集約される
- APIアグリゲーションされた Single Source of Truth
- 複数のプラットフォームのクライアントが複数ある場合に1台のGraphQLで対応出来る
- それぞれのBFFではなく、全てのクライアントのためのBFF
- マイクロサービス、サービス指向アーキテクチャ
- サーバーサイドでは様々な業務を行う
- ドメイン毎の要求やデータ特性が異なる
- そのため様々なソフトウェア、データベースを使い分ける必要性がある
- サーバーサイドにとっても集約層となる
GraphQLのネットワーク・トポロジー

出典: https://www.apollographql.com/blog/graphql/basics/what-is-graphql-introduction/
GraphQLで得られる恩恵
ここで紹介するGraphQLで得られる恩恵はコアコンセプトに比べるとやや重要度が低いと個人的には考えています。ここで紹介するものは必ずしもGraphQLだけが方法ではなく別解がある場合が多いため、この点でGraphQLを導入したいと考えている場合は、メリットとトレードオフとを熟慮し検討することを進めます。
(サービス毎に特性が異なるのであるサービスにとってはクリティカルである場合もあるはずなので全てのケースで必ずしも重要度が低いという訳ではない、あくまで参考にと思っていただけると幸いです)
クライアントAppへの恩恵
- 強い型システム
- 操作やデータに型がある
- TypeScriptの型生成がしやすい
- クライアントにとって使いやすいデータ構造である場合に加工が不要になる
- 通信するサーバーが1台になることで通信の煩雑さがなくなる
- ComponentとFragmentの相性が良い(Fragment Colocation)
- クライアントでの状態同期の実装が不要になる
- GraphQLクライアントが状態管理まで行う
- Subscribe(Websocket)
- そのサービスで利用できる操作・データが一覧できる
サーバーAppへの恩恵
- Schema Driven Development
- ドキュメントとしてのコード
- フィールドの変更でのbreaking changeが検知出来る
- ユースケース毎の実装が減る
- 拡張する場合に実装工数がリニア
- RESTに比べてデータソースの呼び出し箇所が減る
- マイクロサービス化しやすい
運用面での恩恵
- ネットワークコスト、計算リソースを最適化出来るチャンスがある
- クライアント・操作・フィールド単位でどのように利用されているかトラッキングできる
- フィールドの変更でのbreaking changeが検知できる
クライアントでのデータモデリング
データモデリングと結合
密結合
- DRY原則と相性が良い
- 高速に構築できる可能性がある
- 少人数で開発する時に向いている
- 大規模になると足かせになりがち
疎結合
- SOLID原則と相性が良い
- 他方の仕様に依存しない実装・モデリングができる
- 特定のコンテキストだけで作業ができて認知コストが下がる
- 大人数で開発する時に作業分担がし易い
- 規模が小さいとメリットを得られづらい
- コードの量や設定が増えがち
- 他方を変更できない場合に新たな層としてモデリングする(腐敗防止層)
インピーダンスミスマッチ
異なるレイヤでデータモデルの差異が大きいと変換にコストがかかる
データモデリングを行う層
- データベース
- ドメイン
- API
- クライアント
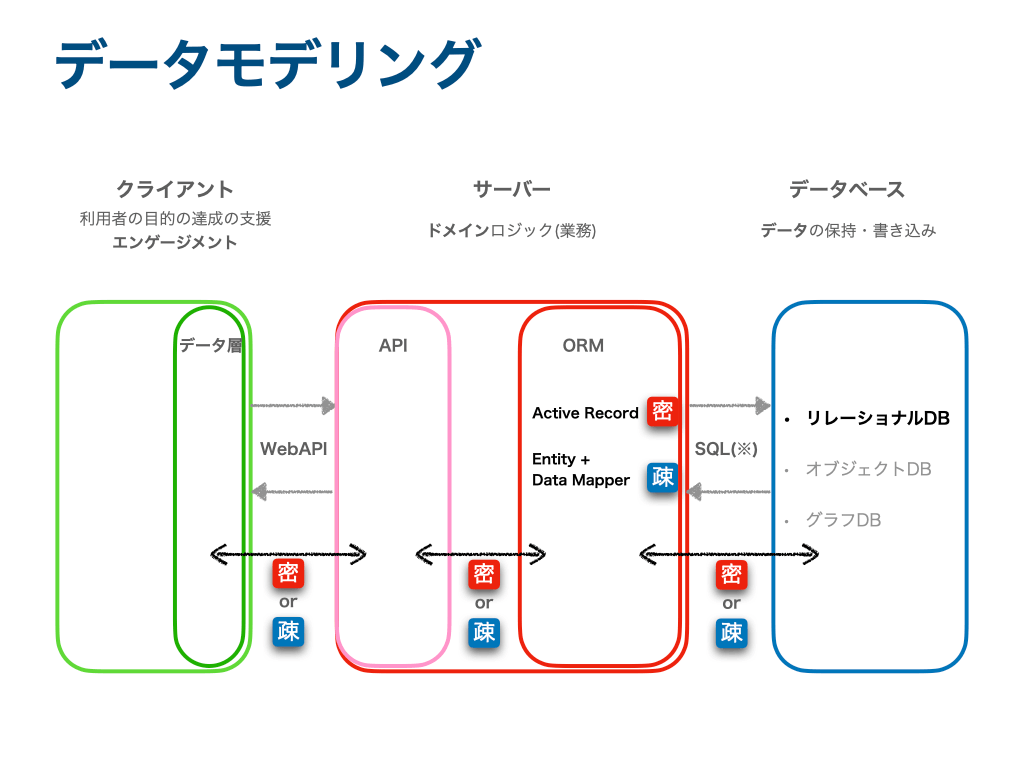
データベースとドメイン間
例えばActiveRecordとEntity。 実装の速さから密結合なActiveRcordが使われる事が増えて来たが、大規模で複雑なアプリケーションでは疎結合なEntityが活躍するケースがある。
ActiveRecord
DBのテーブルとオブジェクトが同じ構造を持つ(密結合)
Entity + Data Mapper
Data Mapper: DBのテーブル取得・操作を担当するロジック
Entity: DBのデータ構造を考慮しないドメインに特化したオブジェクト
Entity DataMapperで疎結合
ドメインとAPI間
- 特に問題がない限り基本的にはドメインのモデルをAPIとするケースがほとんど(密結合)
- インピーダンスマッチが大きい場合はクライアントに合わせてモデリングする(疎結合)
APIとクライアント間
- APIが提供するデータ構造でそのままサービス提供できる場合は問題ない(密結合)
- インピーダンスマッチが大きい場合は用途に合わせてクライアント上で加工(モデリング)する(疎結合)
- Redux等の肥大化につながる可能性
データモデリングとAPIデザイン
REST
- ユースケースとデータモデリングと計算コストがセット(固定)
- フィールドや階層構造が増えると計算量・通信量が増える
- 設計時点で計算量と通信量を考慮する必要がある
- ちゃんとやろうと思うと特定のユースケース毎にAPIを作る必要が出てくる
- 変更はバージョニングすることで対応する
- 未来において変更がしずらい
- 作成時に現在から見える最長のスコープで設計する必要がある
GraphQL
- スキーマのモデリングからユースケースを分離できる
- ユースケースはクエリが担当
- 最大でモデリングし、最小で利用できる
- 実行時に計算量が可変に決まるので計算量をそこまで考慮しなくてよい
- 未来において変更しやすい
- モデルの変更が必要になった時に追加・削除出来る
GraphQLの特性とRESTとの比較
アーキテクチャ特性

パフォーマンス
ネットワークレイテンシ
- リクエストを集積する事でレイテンシが最小化する
- ※しかし日本国内向けサービスだとレイテンシが問題として表面化しにく
- クエリで必要なデータだけ取得するためトラフィック量・通信時間が最小化する
ネットワークキャッシュ
- HTTPのレスポンスキャッシュを使えない ※一応GETでもリクエスト出来てキャッシュも出来る
- RESTではできる部分的なキャッシュができない
サーバーロジック
- リクエストが集積するため、データのアクセス回数が最小化する可能性がある
- 木構造のfieldの解決を同じ高さで並行処理出来る
- 全てのフィールドの解決が終わるまでレスポンスが返せないため、遅いフィールドに依存する
GraphQLとRESTの比較

GraphQLはどんな時につかうか
- 戦略的利用
- コアコンセプトがクリティカルなケースで利用する
- 戦術的利用
- コアコンセプトではない部分の恩恵を受けるために利用する
GraphQLを検討する時の質問項目
- サービス
- サービスの規模は?
- サービス提供においてエンゲージメントが占める比重が大きいか
- サービスの進化速度が速いか、今後も変化し続けるか
- データモデル・スキーマ
- クラサバで異なるデータモデリングしたいか
- 扱うデータ・操作の関連が複雑か
- ネットワーク
- レイテンシやトラフィック量やオーバーヘッドの要求が高いか
- クライアントの性質
- APIコールと状態管理が煩雑か
- クラサバ間でのデータ更新・同期が頻繁に起きるか(特に書き込みが多い)
- アーキテクチャ
- トポロジーが複雑か(マルチクライアント, 複数のデータソース)
- レガシーなシステム・データベースを利用するAPIを作る必要がある
- 開発組織
- 組織が拡大していくか
- 未来においてもGraphQLをメンテできるか
RESTを使うケース
- サービス規模が小さい
- ネットワークトラフィックが問題になっていない
- 将来的に拡大していく予定が今のところない
- データモデル
- ドメインとクライアントでデータモデルが同型で密結合で良い
- モデルの変化が少ない
- API
- サービスのメインとなるAPIの利用がほとんど
- 計算量とセキュリティ
- 計算量が見積もれる必要がある
- 公開API等
- HTTP層で認証・認可を行いたい場合
- 計算量が見積もれる必要がある
- 開発チーム
- 開発者が少ない
- 現在未来において学習コストを支払えない可能性がある
- GraphQLを熟知している人が少ない
- GraphQL用の運用体制をコストに感じる場合
さいごに
GraphQLはいいぞ!(だけどGraphQLじゃなくてもいいケースもあるよね)ということで今回は登壇しました。筆者は合同会社春秋という開発会社を運営しています。GraphQLの相談や設計・実装などがあればお声がけください。

Discussion