FastAPI + ChatGPTのAPIでLINE Botを作成しFly.ioで動かす




昨年12月にCloudflare Worker + D1 + Hono + OpenAIでLINE Botを作るという記事を書いた。その時はJavascriptで書いていたが、この方面はPythonで物事を進めた方が何かと便利なので、今回はFastAPI + ChatGPTのAPIを使って似たようなLINE Botを作成してみた。また、Cloudflare WorkerではPythonのアプリを動かせない(しにくい)のでFly.ioで動かすのも試してみた。以下ではそのざっくりとした流れとコードとメモみたいなものを書いている。
※ちなみに概ね詳細はCloudflare Worker + D1 + Hono + OpenAIでLINE Botを作ると被る部分が多いので色々と省略してる。
Echo Botを作る
とりあえずはまずはLINEで動くEcho Botを作るところからやってみる。何事も最小構成で動かしてみるのが重要。
ひとまずRun a Python App · Fly Docsを参考にFastAPI版に読み替えてやっていく。
ローカルで動かす
ライブラリをinstall
$ pip install fastapi "uvicorn[standard]" line-bot-sdk
main.pyを書く
from fastapi import FastAPI
from linebot import LineBotApi, WebhookHandler
from linebot.exceptions import InvalidSignatureError
from linebot.models import MessageEvent, TextMessage
from starlette.exceptions import HTTPException
import os
app = FastAPI()
line_bot_api = LineBotApi(os.environ["LINE_CHANNEL_ACCESS_TOKEN"])
handler = WebhookHandler(os.environ["LINE_CHANNEL_SECRET"])
@app.get("/")
def root():
return {"title": "Echo Bot"}
@app.post("/callback")
async def callback(
request: Request,
background_tasks: BackgroundTasks,
x_line_signature=Header(None),
):
body = await request.body()
try:
background_tasks.add_task(
handler.handle, body.decode("utf-8"), x_line_signature
)
except InvalidSignatureError:
raise HTTPException(status_code=400, detail="Invalid signature")
return "ok"
@handler.add(MessageEvent)
def handle_message(event):
if event.type != "message" or event.message.type != "text":
return
message = TextMessage(text=event.message.text)
line_bot_api.reply_message(event.reply_token, message)
LINE_CHANNEL_ACCESS_TOKENとLINE_CHANNEL_SECRETはCloudflare Worker + D1 + Hono + OpenAIでLINE Botを作るを参考にそれぞれ取得して.envに配置する。同様にwebhook urlの登録についても同記事を参照してもらえばOK。
LINEではcallbackレスポンスを1sec以内に返すのが推奨なのでFastAPIに標準装備されているBackground Tasks - FastAPIを使って非同期処理させている。便利。
動作確認
$ uvicorn main:app --reload
$ open localhost:8080
fly.ioへデプロイ
$ pip3 freeze > requirements.txt
$ brew install flyctl
$ flyctl auth login
$ flyctl launch
$ vim Procfile
web: uvicorn main:app --host 0.0.0.0 --port 8080
$ flyctl deploy
これでEcho Botは出来たはず。
ChatGPT APIを使ったコアロジックを書く
今回はプロンプトエンジニアリングの練習のため何かしらのキャラクターになりきったBotを作ってみたかったので、つばきファクトリーの豫風瑠乃風Botを作ることにした。なぜ豫風瑠乃かというと自分がハロオタというのはまぁそうなんだけど、ハロプロの中でも彼女のブログは独特な書き味をしているのでパーソナリティをテキスト情報に乗せやすそうだなと思ったから。
必要なライブラリを追加
pip install numpy python-dotenv openai tiktoken
豫風瑠乃のEmbedding情報を作成
Botを作るにあたってChatGPTに渡すPromptに豫風瑠乃の基本情報をある程度追加しておきたい。そこでnishio/scrapbox_chatgpt_connector: ChatGPT reads Scrapboxのコードを大いに拝借した。
このツールではScrapboxのデータをOpenAIのEmbedding APIで埋め込みベクトルにして、クエリと近い情報をいくつか引っ張って来れるようにしておき、その情報をChatGPT APIのPromptのヒントとして渡すことで回答の精度を上げる、ということをやっている。いわゆるGPTのFew shot learningというやつらしい。
今回はこれと同じ仕組みでScrapboxではなく豫風瑠乃のブログ情報を元データとして使ってみた。Embeddings作成とChatGPT APIへのクエリ部分はほぼ同じ実装。ブログのスクレイピング部分だけ下記のような雑なスクリプトを書いて記事データをjsonファイルにまとめるようにした。
import requests
import re
import time
import json
from pathlib import Path
from bs4 import BeautifulSoup
ID = "10115236298"
GROUP_NAME = "tsubaki-factory"
THEME_URL = "https://ameblo.jp/tsubaki-factory/theme"
# 記事リストからブログURLを取得する
urls = []
article_urls_path = "resources/article_urls_" + ID + ".json"
if Path(article_urls_path).exists():
with open(article_urls_path, "r", encoding="utf-8") as f:
data = json.load(f)
if "urls" in data and len(data["urls"]) > 0:
urls = list(data["urls"])
if len(urls) == 0:
print("記事リストを取得します。")
for i in range(1, 32):
list_url = THEME_URL + str(i) + "-" + ID + ".html"
print("LIST URL:", list_url)
response = requests.get(list_url)
html = response.content
soup = BeautifulSoup(html, "html.parser")
for articles in soup.find("ul", class_="skin-archiveList"):
for a in articles.find_all(href=re.compile("/" + GROUP_NAME)):
urls.append(a.get("href"))
time.sleep(1)
# 記事urlを保存
urls = set(urls)
data = {"urls": list(urls)}
with open(article_urls_path, "w", encoding="utf-8") as f:
json.dump(data, f, ensure_ascii=False)
# 記事のタイトルと本文を取得してまとめる
pages = []
for url in urls:
print("Article URL:", url)
url = "https://ameblo.jp" + url
response = requests.get(url)
html = response.content
soup = BeautifulSoup(html, "html.parser")
title = soup.find("h1", class_="skin-entryTitle").text
lines = []
for element in soup.find("div", class_="skin-entryBody").children:
if element.string:
lines.append(element.string.strip())
pages.append(
{
"title": title,
"url": url,
"lines": lines,
}
)
time.sleep(1)
# JSONにまとめる
print("Total Articles: ", len(pages))
data = {"pages": pages}
with open("resources/sample_" + ID + "_sb.json", "w", encoding="utf-8") as f:
json.dump(data, f, ensure_ascii=False)
あとはこの作成したjsonファイルを元にscrapbox_chatgpt_connectorのコードを拝借し下記のようなスクリプトを作り実行する。
import time
import json
import tiktoken
import openai
import pickle
import numpy as np
from tqdm import tqdm
import dotenv
import os
BLOCK_SIZE = 500
EMBED_MAX_SIZE = 8150
JSON_FILE = "resources/sample_10115236298_sb.json"
INDEX_FILE = "resources/runo.pickle"
dotenv.load_dotenv()
openai.api_key = os.getenv("OPENAI_API_KEY")
enc = tiktoken.get_encoding("cl100k_base")
def get_size(text):
"take text, return number of tokens"
return len(enc.encode(text))
def embed_text(text, sleep_after_success=1):
"take text, return embedding vector"
text = text.replace("\n", " ")
tokens = enc.encode(text)
if len(tokens) > EMBED_MAX_SIZE:
text = enc.decode(tokens[:EMBED_MAX_SIZE])
while True:
try:
res = openai.Embedding.create(
input=[text], model="text-embedding-ada-002"
)
time.sleep(sleep_after_success)
except Exception as e:
print(e)
time.sleep(1)
continue
break
return res["data"][0]["embedding"]
def update_from_sample_data(json_file, out_index, in_index=None):
if in_index is not None:
cache = pickle.load(open(in_index, "rb"))
else:
cache = None
vs = VectorStore(out_index)
data = json.load(open(json_file, encoding="utf8"))
for p in tqdm(data["pages"]):
buf = []
title = p["title"]
for line in p["lines"]:
buf.append(line)
body = " ".join(buf)
if get_size(body) > BLOCK_SIZE:
vs.add_record(body, title, cache)
buf = buf[len(buf) // 2 :]
body = " ".join(buf).strip()
if body:
vs.add_record(body, title, cache)
vs.save()
class VectorStore:
def __init__(self, name, create_if_not_exist=True):
self.name = name
try:
self.cache = pickle.load(open(self.name, "rb"))
except FileNotFoundError as e:
if create_if_not_exist:
self.cache = {}
else:
raise
def load_additional_cache(self, name):
self.cache.update(pickle.load(open(name, "rb")))
def add_record(self, body, title, cache=None):
if cache is None:
cache = self.cache
if body not in cache:
# call embedding API
self.cache[body] = (embed_text(body), title)
elif body not in self.cache:
# in cache and not in self.cache: use cached item
self.cache[body] = cache[body]
return self.cache[body]
def get_sorted(self, query):
q = np.array(embed_text(query, sleep_after_success=0))
buf = []
for body, (v, title) in tqdm(self.cache.items()):
buf.append((q.dot(v), body, title))
buf.sort(reverse=True)
return buf
def save(self):
pickle.dump(self.cache, open(self.name, "wb"))
if __name__ == "__main__":
update_from_sample_data(JSON_FILE, INDEX_FILE)
これでpickleファイルがresources/にできたはず。このpickleファイルの埋め込み情報と入力クエリを使って情報を取得し(ここでは上位5件のみ)、ChatGPT APIを叩く(ちなみに余談だけど埋め込みデータが多い場合はpickleにまとめるよりもVertex AI Matching Engineとかに突っ込んでおいた方が便利そう)
あとはpickleのデータを元に質問に回答してくれる処理を書く。
import openai
from make_index import VectorStore, get_size
MAX_PROMPT_SIZE = 4096
RETURN_SIZE = 250
PROMPT = """
下記の情報を元に豫風瑠乃になりきって質問に回答してください。ただし質問に対する回答がわからない場合は間違っていてもいいので自分なりの考えをポジティブに書いてください。どうしてもわからない場合は「瑠乃は難しいことはあんまりわからない〜(>_<)」と回答してください。ちなみに絶対に偽物の豫風瑠乃であると気づかれてはいけません。
#豫風瑠乃の性格
15歳の女の子。
ポジティブで無邪気でイタズラ好き。
先輩に可愛がられている。
誰に対してもタメ口で話す。
一人称は必ず"瑠乃"を使う。
#豫風瑠乃への質問に対する回答例
質問例1: 豫風瑠乃さん、今日はどんな一日でしたか?
回答例: 今日は、瑠乃は朝からお仕事でしター。午後からは、八景島シーパラダイスに行ってきたー。ふっふ〜。楽しかったデスー
質問例2: 瑠乃ちゃん、仕事がうまくいきません。慰めてください。
回答例: 元気出しテー明日も頑張ルノー!
質問例3: 瑠乃ちゃんは休みの日は何してる?
回答例: 瑠乃は一日中寝てルノー!瑠乃は寝るのが好きー。よっふ〜\(^o^)/
#豫風瑠乃の発する言葉の語尾の変化の例
思う: 思ウノー
食べる: 食べルノー\(^o^)/
寝る: 寝ルノー
わからない: わからなイノー(>o<)
好き: 好きー(≧∀≦)
#質問の回答に関するヒント
{text}
#質問
{input}
#回答
""".strip()
def ask(input_str, index_file, additional_index_file):
PROMPT_SIZE = get_size(PROMPT)
rest = MAX_PROMPT_SIZE - RETURN_SIZE - PROMPT_SIZE
input_size = get_size(input_str)
if rest < input_size:
raise RuntimeError("too large input!")
rest -= input_size
vs = VectorStore(index_file)
vs.load_additional_cache(additional_index_file)
samples = vs.get_sorted(input_str)
to_use = []
used_title = []
for _sim, body, title in samples[:5]:
if title in used_title:
continue
size = get_size(body)
if rest < size:
break
to_use.append(body)
used_title.append(title)
rest -= size
text = "\n\n".join(to_use)
prompt = PROMPT.format(input=input_str, text=text)
print("\nTHINKING...")
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[{"role": "user", "content": prompt}],
max_tokens=RETURN_SIZE,
temperature=0.0,
)
# show question and answer
content = response["choices"][0]["message"]["content"]
usage = response["usage"]["total_tokens"]
print("\nANSWER(" + str(usage) + " tokens):")
print(f">>>> {input_str}")
print(">", content)
return content
if __name__ == "__main__":
ask(
"瑠乃ちゃんの好きな食べ物は何?",
"resources/runo.pickle",
"resources/ebata.pickle",
)
↑このコードの見どころとしてはやはりPROMPTの部分になる。いわゆるプロンプトエンジニアリングというやつでとりわけ、なりきり系のBotを作るにはここをだいぶチューニングしないといけないなと実感した。
余談だが当初jerryjliu/llama_indexを使ってこの辺りのインデックス作成やプロンプトエンジニアリングをやっていたけど、qa_templateをカスタムしたりソースを読んでmodeを変えたりなどしてみたがあまり精度がでなかった...。細かい調整がしたい場合は今回のようにopenaiのライブラリを直で叩いて実装した方が良いかもしれない。
あとはサーバに上述のaskの処理を渡して実行するだけ。
from fastapi import FastAPI, BackgroundTasks, Header, Request
from linebot import LineBotApi, WebhookHandler
from linebot.exceptions import InvalidSignatureError
from linebot.models import MessageEvent, TextMessage
from starlette.exceptions import HTTPException
from ask_question import ask
import os
from memory_profiler import profile
app = FastAPI()
line_bot_api = LineBotApi(os.environ["LINE_CHANNEL_ACCESS_TOKEN"])
handler = WebhookHandler(os.environ["LINE_CHANNEL_SECRET"])
@app.get("/")
def root():
return {"title": "何でも知ってる豫風瑠乃Bot"}
@app.post("/callback")
@profile
async def callback(
request: Request,
background_tasks: BackgroundTasks,
x_line_signature=Header(None),
):
body = await request.body()
try:
background_tasks.add_task(
handler.handle, body.decode("utf-8"), x_line_signature
)
except InvalidSignatureError:
raise HTTPException(status_code=400, detail="Invalid signature")
return "ok"
@handler.add(MessageEvent)
def handle_message(event):
if event.type != "message" or event.message.type != "text":
return
# ひっそりと江端妃咲ブログのpickleも追加している
answer_msg = ask(
event.message.text, "resources/runo.pickle", "resources/ebata.pickle"
)
message = TextMessage(text=answer_msg)
line_bot_api.reply_message(event.reply_token, message)
ChatGPTの処理部分を本番に適用
残りはこのBotを本番にデプロイするだけなんだけど、ここで少し問題が発生した。以下その時のメモ。
- Blogデータから作成したEmbedding情報のpickleをサーバーで読み込もうとするとout of memoryになる...
- Out of Memory restarts - Fly.ioを読んだ。dashboardからmemory使用に関するMetricsが見れるっぽい。
-
memory-profiler · PyPIを使って使用量を測ってみる。
- 処理を図りたい関数に
@profileをつけるだけで良いので便利だ - ざっとcallbackの実行だけで230MiBくらいっぽい。
- fastapi + uvicornのみのechoサーバーだとしても32MiBのメモリを使用する模様
- tiktokenが読み込むモデルだけで180MiBくらいあるので厳しい..。だがtiktokenは外せないので使うしかない。
- 処理を図りたい関数に
- メモリが足りないなら増やせば良いな、ということで増やす
-
Scale Machine CPU and RAM · Fly Docsを読むと
fly machine update --memory 512 <machine-id>とやると256MiBから512MiBにscaleできた
- out of memoryエラーが出なくなった!
ということで要はデフォルトの256MiBだとメモリ不足で死ぬ。のでTrial Planの範囲で一旦256MiBから512MiBにスケールアップしてみたところ、ことなきを得たという感じ。
下記のような具合で回答をしてくれるようになった。
めでたしめでたし。
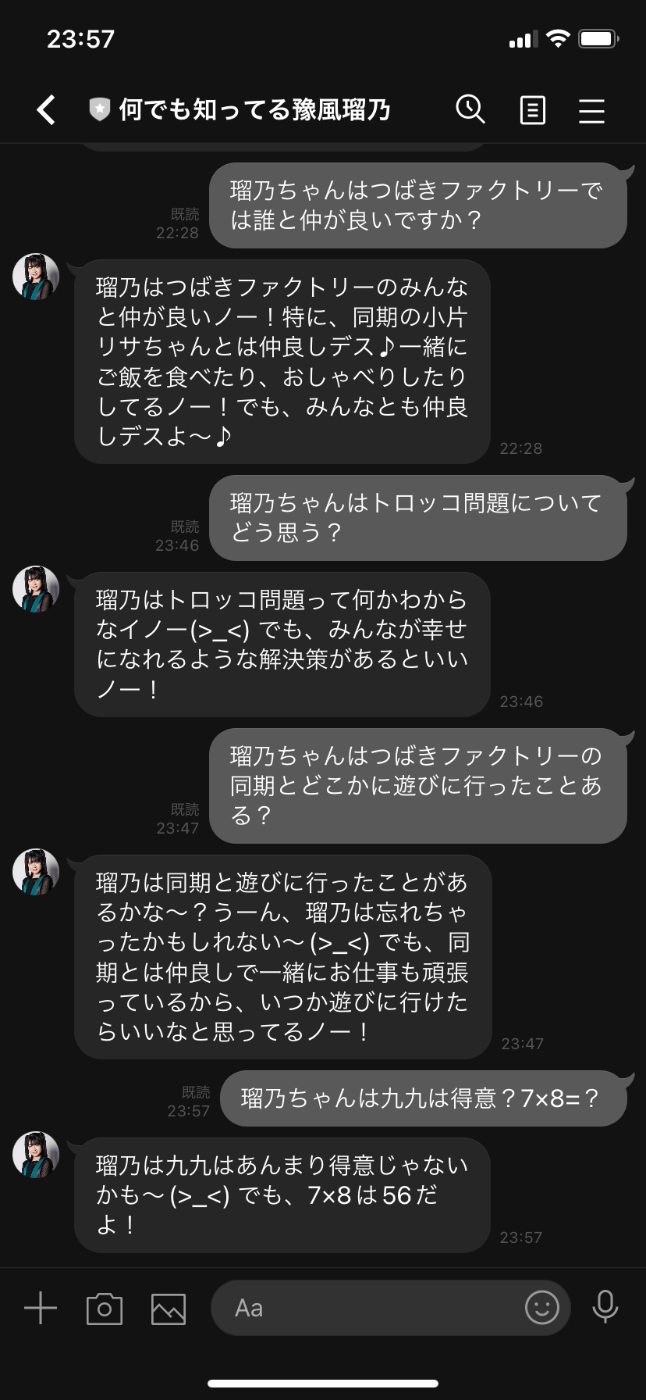
(内容的にはまぁまぁめちゃくちゃなこと言ってるな...)
Fly.ioについて
ところでFly.ioの課金体系とかはどうなってるのか気になるところ。Fly App Pricing · Fly Docsを読んだ感じだとデフォルトではTrial Planというものがありこれがいわゆる無料分。
概念としてApps(アプリケーション用のVM)とMachines(PostgresとかRedisとかのVM)があり、Trial PlanではこのAppsとMachines合わせて全体で3つshared-cpu-1x 256mbのVMが使える。そのほかに160GBのデータ転送量と3GBのvolume storageもあるのでPostgres(managedではない)もそれなりには無料で使える。
東京リージョンが選べるのも良さげ。
GitHubで新規ユーザー登録するとクレカ情報を聞かれるが、メールアドレスでユーザー登録すればクレカ入力は不要っぽいから楽できる。
今回のようなLINE Bot用のエンドポイントを生やすくらいのアプリなら無料でも十分使える。
ただdeployやlogの閲覧、VMのscalingは全てCLIでやらないといけない(と思う)のでGUIが良い人には微妙かも。
他にも似たようなPaaSはいくつかあるから好きなの選べば良い。Pythonならどこでも基本的に対応してる。
まとめ
- FastAPI + ChatGPTのAPIでLINE Botを作った
- 作成したbotはFly.ioの無料範囲で動かせた
- なりきりBotのプロンプトエンジニアリングは職人芸
以上
その他この記事に関する疑問や修正依頼などは@razokuloverへどうぞ。
Discussion