【ベクトル検索・セマンティック検索】Azure Cognitize Searchでハイブリッドな文書検索の精度が高いという報告



OpenAIが出てからベクトル検索の注目度が高まっているように思います。
お客様からもベクトル検索をすることでどのようなメリットがあるかを聞かれることが増えました。
今回の記事では、ベクトル検索はどのような技術で、どのようなメリットがあるのかを解説し、マイクロソフトのコミュニティで話題になっていた内容をご紹介します。
そもそもベクトル化とは何か
文章を数値ベクトルに変換する様々な方法です。
代表的なベクトル化の手法には疎ベクトル(sparse)と密ベクトル(dense)の手法があります。
疎ベクトルとは、ベクトル要素の多くがゼロとなり、ベクトル次元が相対的に高いものです。
例えば「準備」の語彙が i番目の要素に、「用意」の語彙がj番目の要素に、別々で取り扱われるため、類義語のような意図を加味する能力はあまりありません。
密ベクトルとは、ベクトル要素の多くが非ゼロとなり、ベクトル次元が相対的に低いものです。
例えば「準備」と「用意」の語彙を含む概念がi番目の要素で取り扱われるため、類義語のような意図を加味する能力に長けます。
以下のような手法が代表的です。
-
CountVectorizer(sparse)
文章を単語毎の出現回数の表現に変換する手法 -
Term Frequency - Inverse Document Frequency(TF-IDF)(sparse)
文書中の単語の重要度を評価する手法 -
Word2Vec(dense)
文章を解析し、各単語を200次元などの数値ベクトル表現に変換する手法 -
Bidirectional Encoder Representations from Transformers(BERT)(dense)
文脈や文章構造を考慮した手法 -
text-embedding-ada-002(dense)
OpenAIが提供しているEmbeddingモデル
ベクトル検索とは
ベクトル検索とはテキストや画像などのデータを、機械学習モデルなどを利用してベクトルで表現し、ベクトル間の距離を計算することで、類似するベクトルを検索する手法です。
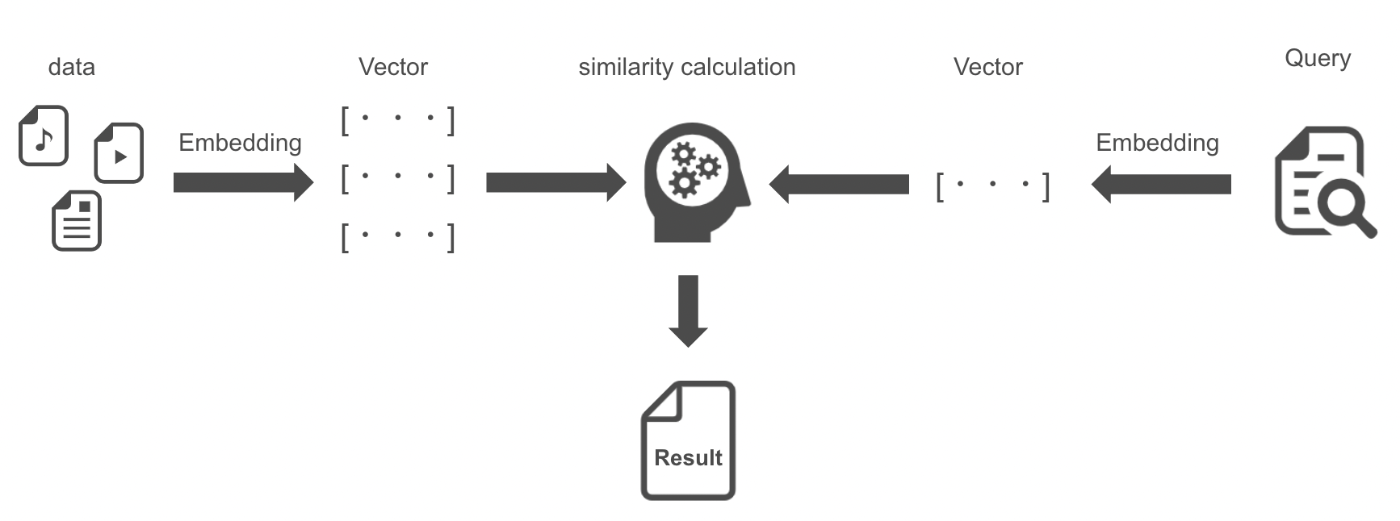
キーワード検索と比較したときのベクトル検索のメリット
弊社は製薬会社のお客様も多いので以下のようなご説明をします。
AML(急性骨髄性白血病)という疾患があります。
遺伝子変異(gene mutation)によって起こるAML(急性骨髄性白血病)に関する論文を全て調べたいとします。
キーワード検索では、
「AML is caused by gene mutation」
と入れてもAMLという疾患名に引っ張られて、遺伝子変異(gene mutation)に関係しない論文も検索上位に出てきてしまいます。
一方、ベクトル検索では、文章の意味を捉えて、遺伝子変異(gene mutation)によって起こるAML(急性骨髄性白血病)に関する論文を検索結果に出すことができます。
(その代わり検索速度はキーワード検索より落ちます)
参考:第68回 Machine Learning 15minutes! Broadcast:疎ベクトル検索と密ベクトル検索
(https://speakerdeck.com/keyakkie/shu-bekutorujian-suo-tomi-bekutorujian-suo-di-68hui-machine-learning-15minutes-broadcast?slide=6)
9/18に公開されたマイクロソフトのコミュニティで紹介されたAzure Cognitize Searchの検索精度について
ハイブリッド+セマンティックランキングは、純粋なベクトル検索よりもパフォーマンスが良かったようです。
キーワード検索より文脈を捉えることができるベクトル検索ですが、それでも上位に上がってきた文書も必ずしもユーザーの意図通りの文書であると100%言えるわけではありません。
そのため、ベクトル検索で出てきた結果に対して、優先順位をリランキングしてあげる手法が昔からありました。
Azure Cognitize Searchでは、そのリランクしてあげる手法の検索精度の結果が良かったことが報告されていました。
主に以下のことが報告されていました。
-
セマンティック検索にしても、文字列検索にしても、クエリのベクトルと文書ベクトルが類似性を持つかどうかの判断を、得られたクエリベクトルと文書ベクトルの距離の近さで比較しているだけで、(モデルがベクトルを生成することはしているが)モデルが類似性を推論しているわけではない
-
既存の検索では、埋め込みモデルによって得られたベクトルの距離を比較して検索候補を出しているだけ
検索候補をよりクエリの意図に沿った順番に並べ替えたいなら、クエリの意図に沿っているかどうか推論させる必要がある -
例えばSTS(Semantic Textual Similarity)タスクのモデルでクエリと検索候補の文の類似性を推論させて、類似スコアで並べ替えても良いし、クエリや検索候補の文のジャンル推定モデルでジャンルを予測し、両者の一致があるものをより上位になるように並べ替えてもいいし、色々できる
-
ともかくハイブリッド検索などのベクトル距離比較で得られた検索候補に、クエリと検索候補があっているかどうか参考になる別の予測モデルがあって、その情報をもとに検索候補を再度並び替えることで精度を改善している
もし、Azure Cognitize Searchを使ったベクトル検索を実装して、社内文書の検索や論文の検索システムなど開発をされたい時はぜひ以下のフォームよりご連絡ください。
株式会社piponでは定期的に技術勉強会を開催しています。
ChatGPT・AI・データサイエンスについてご興味がある方は是非、ご参加ください。
株式会社piponではChatGPT・AI・データサイエンスについて業界ごとの事例を紹介しています。ご興味ある方はこちらのオウンドメディアをご覧ください。

株式会社piponのテックブログです。 ChatGPTやAzureをメインに情報発信していきます! お問い合わせはフォームへお願いします。 会社HP pipon.co.jp/ フォーム share.hsforms.com/19XNce4U5TZuPebGH_BB9Igegfgt
Discussion