主要ブラウザでIntl.Segmenterが出揃ったので動作を見ていく

先日2024年4月16日ころ、FireFox125がリリースされました。これにより、主要ブラウザでIntl.Segmenterの実装が出揃ったことになります。
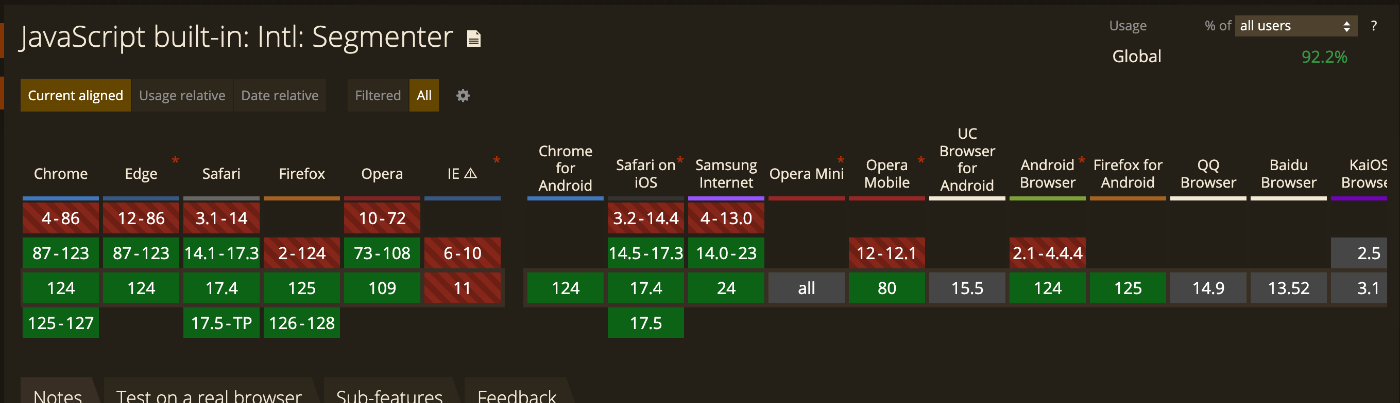
chromeで初めて実装されたのはバージョン87、時期にして2020年冬の頃になります。足掛け5年、満を持しての解禁です…!
ですがSegmenterの詳細な挙動は、ブラウザごとに結構異なります。なので今回は、ブラウザごとの差異を加味しつつ、実用レベルで出来るようになったこと、まだ出来ないことを確認していきます。
Intl.Segmenterとは
知ってるひとは読み飛ばしてもらって。
以下、MDNから引用。
Intl.Segmenter オブジェクトは、ロケールに応じたテキストのセグメンテーションを可能にし、文字列から意味のある項目(書記素、単語、文)を取得することができます。
Intlは国際化系の名前空間で、Segmenterはその空間内に定義されています。ecmaの仕様書はこちら。
Intl.Segmenter(locales, options) コンストラクタでオブジェクトを生成し、 Segmenter.segment(target)メソッドで分割処理を行えます。試しに、単語分割モードで文章の分ち書きをしてみます。
const segmenter = new Intl.Segmenter("ja-JP", { granularity: "word" })
[...segmenter.segment("吾輩は猫である")]
// 0: {segment: '吾輩', index: 0, input: '吾輩は猫である', isWordLike: true}
// 1: {segment: 'は', index: 2, input: '吾輩は猫である', isWordLike: true}
// 2: {segment: '猫', index: 3, input: '吾輩は猫である', isWordLike: true}
// ...
コンストラクタの引数 option に { granularity: "word" } を指定すると、単語分割モードでSegmenterを生成できます。wordのほかには、grapheme(文字単位で分割)、sentence(文単位で分割)のモードが存在します。それぞれの動作を見ていきましょう。
文字単位で分割
{ granularity: "grapheme" }を指定すると、文字単位で分割するモードになります。なお、optionにgranularityを指定しなかった場合も、デフォルトでこのモードになります。
これが解禁されて何が嬉しいかというと、特殊絵文字を含む文字列を簡単にカウントできるようになるのです。有名な例ですが、従来のはまりポイントを見てみましょう。
const target = "𠮷野家で𩸽を買って🙇♂️"
target.length // 16
target.substring(1, 14) // \uDFB7野家で𩸽を買って🙇'
[...target].length // 13
[..."🙇♂️"] // ['🙇', '', '♂', '️']
𠮷や𩸽はマルチバイト文字なので、lengthでカウントしようとすると2文字換算になってしまいます。🙇♂️はお辞儀と男性を組み合わせた複合絵文字であり、lengthだと4文字に相当します。その他、substring等のメソッドも正しく動作してくれません。
なお、スプレッド演算子を使って文字列を解体すると、サロゲートペアのほうは対応可能です。でも、やっぱり複合絵文字のほうは上手く扱えないので、別途正規表現で頑張ったりしがちでした。
この問題が、Segmenterの力で解決しました。やったね。
const segmenter = new Intl.Segmenter("ja-JP")
const target = "𠮷野家で𩸽を買って🙇♂️"
[...segmenter.segment(target)].length // 10
[...segmenter.segment(target)].map(e=>e.segment) // ['𠮷', '野', '家', 'で', '𩸽', 'を', '買', 'っ', 'て', '🙇♂️']
文字分割に関しては、動作確認をした主要ブラウザ6種で特に差異がありませんでした。これらのブラウザをサポート対象とする場合、Segmenterは問題なく使えそうです。
単語で分割
続いて単語単位の分割。{ granularity: "word" }を指定すると、単語単位で分割するモードになります。
形態素解析器と違い、品詞等の付加情報は提示してくれません(もちろんMeCabらとの互換もありません)。自然言語処理の文脈で使うのはちょっと苦しそうですが、Webサービスで使うぶんにはどうでしょうか。
まずはMacのChrome環境で。
const segmenter = new Intl.Segmenter('ja-JP', { granularity: 'word' })
const target = "スマートフォンおよびタブレット用に Firefox をダウンロードしてください"
[...segmenter.segment(target)].map(e=>e.segment).join("_")
// スマート_フォン_および_タブレット_用_に_ _Firefox_ _を_ダウンロード_し_て_くだ_さい
スマートフォンをスマートとフォンに分解するかどうかは難しいところですが、概ね良さそうです。
では続いてMacのFireFox。
// スマートフォン_および_タブレット_用_に_ _Firefox_ _を_ダウンロード_し_てく_だ_さい
ちょっと厳しい。"してください"を"し_てく_だ_さい"に分割してしまっています。
こんな調子で、単語単位の分割は、ブラウザ次第で結構異なる結果になります。
他にも色々確認してみましょう。
- Mac Chrome
わかち書き_と_は_、_文章_において_語_の_区切り_に_空白_を_挟_んで_記述_する_こと_で_ある_。
吾輩_は_猫_で_ある_。_名前_は_たぬき
すもも_も_も_も_も_も_もの_うち
祇園_精舍_の_鐘_の_声_、_諸行無常_の_響き_あり_。_娑_羅_双_樹_の_花_の_色_、_盛_者_必_衰_の_理_を_あら_は_す_。
あの_イーハトーヴォ_の_すき_と_おっ_た_風_、_夏_でも_底_に_冷_た_さ_を_もつ_青い_そら_、_うつくしい_森_で_飾_ら_れ_た_モリーオ_市_、_郊外_の_ぎらぎら_ひかる_草_の_波
- Mac Safari
わかち書き_と_は_、_文章_において_語_の_区切り_に_空白_を_挟_んで_記述_する_こと_で_ある_。
吾輩_は_猫_で_ある_。_名前_は_たぬき
すもも_も_も_も_も_も_もの_うち
祇園_精舍_の_鐘_の_声_、_諸行無常_の_響き_あり_。_娑_羅_双_樹_の_花_の_色_、_盛_者_必_衰_の_理_を_あら_は_す_。
スマート_フォン_および_タブレット_用_に_ _Firefox_ _を_ダウンロード_し_て_くだ_さい
あの_イーハトーヴォ_の_すき_と_おっ_た_風_、_夏_でも_底_に_冷_た_さ_を_もつ_青い_そら_、_うつくしい_森_で_飾_ら_れ_た_モリーオ_市_、_郊外_の_ぎらぎら_ひかる_草_の_波
- Mac FireFox
わかち書き_と_は_、_文章_において_語_の_区切り_に_空白_を_挟_んで_記述_する_こと_で_ある_。
吾輩_は_猫_で_ある_。_名前_はた_ぬき
すもも_もも_もも_もも_のう_ち
祇園_精舍_の_鐘_の_声_、_諸行無常_の_響き_あり_。_娑_羅_双_樹_の_花_の_色_、_盛者_必_衰_の_理_を_あら_は_す_。
あの_イーハトーヴォ_のす_き_と_おっ_た_風_、_夏_でも_底_に_冷_た_さ_を_もつ_青い_そら_、_うつくしい_森_で_飾_ら_れた_モリーオ_市_、_郊外_の_ぎらぎら_ひかる_草_の_波
- android chrome
わかち_書_きとは_、_文章_において_語_の_区切_りに_空白_を_挟_んで_記述_することである_。
吾輩_は_猫_である_。_名前_はたぬき
すもももももももものうち
祇園精舍_の_鐘_の_声_、_諸行無常_の_響_きあり_。_娑羅双樹_の_花_の_色_、_盛者必衰_の_理_をあらはす_。
スマートフォン_および_タブレット_用_に_ _Firefox_ _を_ダウンロード_してください
あの_イーハトーヴォ_のすきとおった_風_、_夏_でも_底_に_冷_たさをもつ_青_いそら_、_うつくしい_森_で_飾_られた_モリーオ_市_、_郊外_のぎらぎらひかる_草_の_波
- android FireFox
わかち書き_と_は_、_文章_において_語_の_区切り_に_空白_を_挟_んで_記述_する_こと_で_ある_。
吾輩_は_猫_で_ある_。_名前_はた_ぬき
すもも_もも_もも_もも_のう_ち
祇園_精舍_の_鐘_の_声_、_諸行無常_の_響き_あり_。_娑_羅_双_樹_の_花_の_色_、_盛者_必_衰_の_理_を_あら_は_す_。
スマートフォン_および_タブレット_用_に_ _Firefox_ _を_ダウンロード_し_てく_だ_さい
あの_イーハトーヴォ_のす_き_と_おっ_た_風_、_夏_でも_底_に_冷_た_さ_を_もつ_青い_そら_、_うつくしい_森_で_飾_ら_れた_モリーオ_市_、_郊外_の_ぎらぎら_ひかる_草_の_波
- ios safari
わかち書き_と_は_、_文章_において_語_の_区切り_に_空白_を_挟_んで_記述_する_こと_で_ある_。
吾輩_は_猫_で_ある_。_名前_は_たぬき
すもも_も_も_も_も_も_もの_うち
祇園_精舍_の_鐘_の_声_、_諸行無常_の_響き_あり_。_娑_羅_双_樹_の_花_の_色_、_盛_者_必_衰_の_理_を_あら_は_す_。
スマート_フォン_および_タブレット_用_に_ _Firefox_ _を_ダウンロード_し_て_くだ_さい
あの_イーハトーヴォ_の_すき_と_おっ_た_風_、_夏_でも_底_に_冷_た_さ_を_もつ_青い_そら_、_うつくしい_森_で_飾_ら_れ_た_モリーオ_市_、_郊外_の_ぎらぎら_ひかる_草_の_波
結構個性が出る結果となりました。まだ実用レベルとはいかなさそうです。今後に期待しましょう。
参考として、クライアントサイドで動かせる軽量形態素解析ライブラリ TinySegmenter の動作とも比較してみます。
わかち_書き_と_は_、_文章_に_おいて_語_の_区切り_に_空白_を_挟ん_で_記述_する_こと_で_ある_。
吾輩_は_猫_で_ある_。_名前_は_たぬき
すも_も_も_も_も_も_も_もの_うち
祇園_精舍_の_鐘_の_声_、_諸行_無常_の_響き_あり_。_娑羅_双樹_の_花_の_色_、_盛者_必衰_の_理_を_あら_はす_。
スマートフォン_および_タブレット_用_に__Firefox__を_ダウンロード_し_て_く_ださい
あの_イーハトーヴォ_の_すき_と_おっ_た_風_、_夏_で_も_底_に_冷た_さ_を_もつ青い_そら_、_うつくしい_森_で_飾られ_た_モリーオ_市_、_郊外_の_ぎらぎら_ひかる_草_の_波'
Segmenterより安定していそうです。クライアントサイドで分ち書きをしたい場合、もうしばらくはライブラリを採用するべきかもしれません。
ついでにnode18環境での動作も見てみましょう。
わかち書き_と_は_、_文章_において_語_の_区切り_に_空白_を_挟_んで_記述_する_こと_で_ある_。
吾輩_は_猫_で_ある_。_名前_は_たぬき
すもも_も_も_も_も_も_もの_うち
祇園_精舍_の_鐘_の_声_、_諸行無常_の_響き_あり_。_娑_羅_双_樹_の_花_の_色_、_盛_者_必_衰_の_理_を_あら_は_す_。
スマート_フォン_および_タブレット_用_に_ _Firefox_ _を_ダウンロード_し_て_くだ_さい
あの_イーハトーヴォ_の_すき_と_おっ_た_風_、_夏_でも_底_に_冷_た_さ_を_もつ_青い_そら_、_うつくしい_森_で_飾_ら_れ_た_モリーオ_市_、_郊外_の_ぎらぎら_ひかる_草_の_波
文で分割
{ granularity: "sentence" }を指定すると、文単位で分割するモードになります。
const segmenter = new Intl.Segmenter('ja-JP', { granularity: 'sentence' })
const target = "そして波のまにまに漂っています。云うまでもなく彼は気絶しているのです。"
[...segmenter.segment(target)].map(e=>e.segment) // ['そして波のまにまに漂っています。', '云うまでもなく彼は気絶しているのです。']
こちらの動作はブラウザで特に差異はなさそうです。句読点では分割できて、絵文字や空白では分割できないようです。
以下サンプル。分割に成功した箇所は改行を差し込んでいます。
そして波のまにまに漂っています。
云うまでもなく彼は気絶しているのです。
そして波のまにまに漂っています!
云うまでもなく彼は気絶しているのです。
そして波のまにまに漂っています.
云うまでもなく彼は気絶しているのです。
そして波のまにまに漂っています.
云うまでもなく彼は気絶しているのです。
そして波のまにまに漂っています 云うまでもなく彼は気絶しているのです。
そして波のまにまに漂っています❓云うまでもなく彼は気絶しているのです。
そして波のまにまに漂っています❕云うまでもなく彼は気絶しているのです。
そして波のまにまに漂っています(笑)云うまでもなく彼は気絶しているのです。
記号を見て分割する分には正しく動作しそうですが、空白や絵文字を区切りとする文の場合は拾ってくれなさそうです。使い方を選ぶ必要はありそうですね。
まとめ
というわけで3モード見てきましたが、文字単位の分割はすでに実用レベルになっているといって良さそう。一方で、単語や文章での分割はまだ悩ましいところです。
Discussion