本記事では、RAG評価ツールの「RAGAS」の論文ついてざっくり理解します。軽めの記事です。
株式会社ナレッジセンスでは、生成AIやRAGシステムを活用したサービスを開発しており、その中でもRAG精度の評価は非常に重要です。

この記事は何
この記事は、「RAGAS」についての論文[1]を、日本語で簡単にまとめたものです。RAGASはツールとして有名ではあるものの、RAGASの論文を読んだことがある方は多くなさそうです。
RAGASとは、おそらく今、一番有名なRAG評価ツールです。同様のツールとして、他にはLangSmithやARESが有名かと思いますが、他の開発者と話をしていても、評価ツールとして一番に名前が上がりやすいのは、やはりRAGASです。
また、今回も「そもそもRAGとは?」については、知っている前提で進みます。確認する場合は以下の記事もご参考下さい。
本題
ざっくりサマリー
RAGシステムを評価する手法です。カーディフ大学の研究者らによって2023年9月に提案されました。「RAGAS」という評価手法を使うメリットは、人力による評価に頼らず、RAGの性能を自動で評価できる点です。
問題意識
RAGは便利ですが完璧ではないです。なので、回答精度向上のための工夫を日々施すことになります。しかし、ふとした瞬間に「今回の工夫によって、本当にRAGの精度が高まったのか...?」となることがよくあります。
RAGASの論文にもある通り、RAGの性能評価には「正しくドキュメントを検索できているか」「検索した情報に基づいた回答ができているか」「そもそもの質問への回答になっているか」など、多面的な評価が必要です。しかし、23年9月当時、これらを総合的に評価する方法はありませんでした。
手法
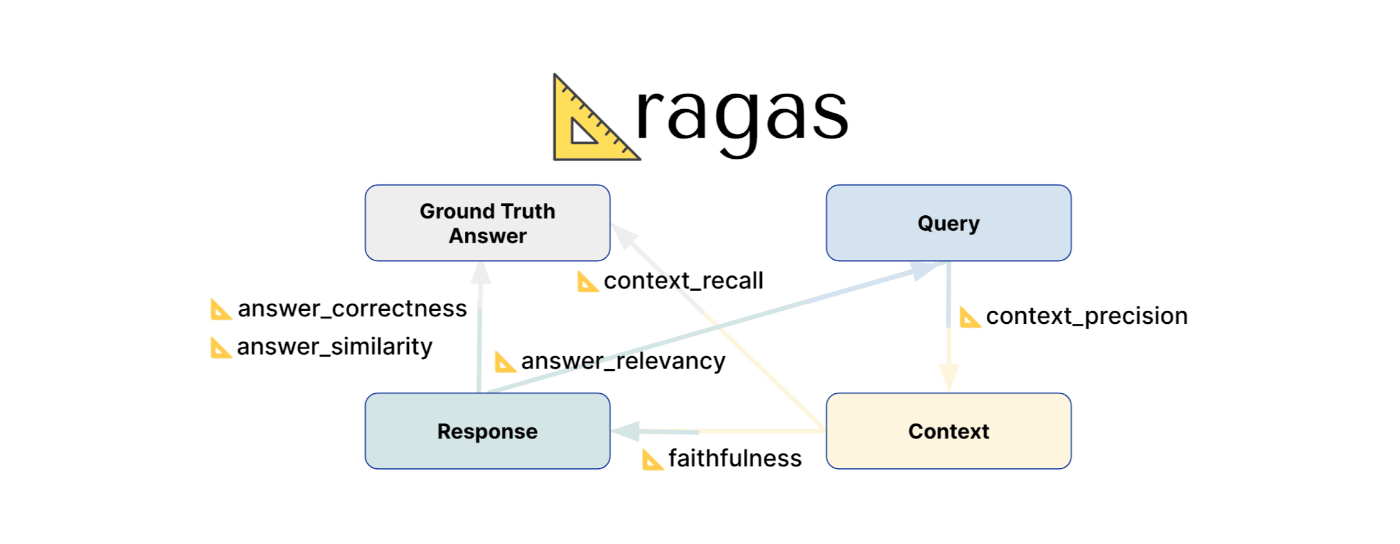
画像出典("RAG Evaluation Using Ragas" by Zilliz)
もともとのRAGASの論文では、次の3つの指標での自動評価が提案されています。(現在は進化して6~8個の評価指標があります[2])
- Faithfulness(忠実性):検索したドキュメントに基づいて回答を生成できているか
- Answer Relevance(回答の関連性):生成した文章が元の質問への回答になっているか
- Context Relevance(文脈の関連性):質問に関連するドキュメントを検索できているか
この手法のキモは、RAGの評価を複数のパートに分類したことと、それぞれのパートでLLMを活用して「自動で」評価できるようにした点です。また、細かい補足ですが、この手法ではLLMだけでなく、Embeddingも用いられています。
成果
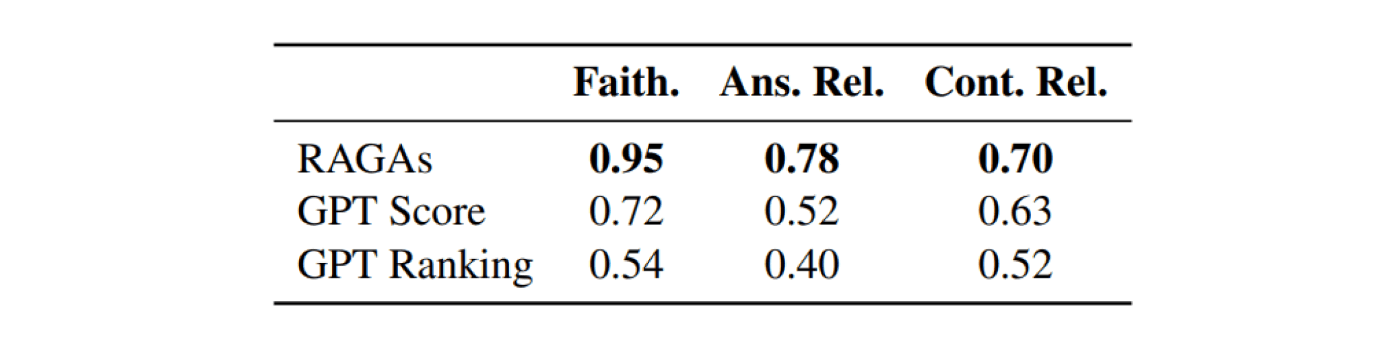
「WikiEval」というデータセットで検証しています。WikiEvalとは、Wikipediaから自動生成された質問と回答を、人間が評価したデータセットです。これを基準として、今回のRAGASによる自動評価が、人間による評価(WikiEval)とどれくら一致しているかを評価します。その結果、RAGASによる自動評価は人間の評価と高い一致率を示し、特にFaithfulnessとAnswer Relevanceで高精度であることが分かりました。ChatGPTに単にスコアリングさせるような評価方法(GPT Scoreなど)と比べても、いい精度です。ただし、「文脈の関連性」の評価は比較的難しく、検索したドキュメントが長い場合に精度が下がりやすいです。この点は、評価に使うLLMが長文に強いモデルであれば解決しますが、GPT-4に評価をやらせるとお金がかかる...というトレードオフもあります。
まとめ
私自身、普段から大企業にRAGシステムを提供していますが、LLMやRAGシステムの性質上、回答精度が完璧になることはなかなか無いです。だからこそ、「如何に素早くRAGを改善できるか」が、かなり重要な領域だと感じています。この「RAGAS」が出る前は、弊社でも、RAG評価にすごく困っていました。どれくらい困っていたかというと、当時その「怒り」から、自社で「RAG評価のためのSaaS」を作ってローンチまでしています笑(現在はサポート終了)。
みなさまが業務でRAGシステムを構築する際も、回答精度を上げる工夫として参考にしていただければ幸いです。今後も、RAGの回答精度を上げるような工夫や研究について、記事にしていこうと思います。我々が開発しているサービスはこちら。
-
"RAGAS: Automated Evaluation of Retrieval Augmented Generation", Shahul Es et al. ↩︎
-
論文当時は3つの観点でしたが、その後、ツールとしてのRAGASは進化を遂げています。現在では6~8つの観点から評価してくれます。参考 ↩︎
株式会社ナレッジセンスは、「大企業の知的活動を最速にする」をミッションに掲げ、社内データ検索ができるAIチャットボットを開発・提供しているスタートアップです。このブログでは、LLMや検索技術、RAGの実装戦略について知見を共有します。生成AIやRAG技術を使って最高品質の実装をしたいエンジニア向けのコンテンツです
Discussion