研究室内ゼミ音声認識システム




はじめに
現在、私は音声言語処理研究室でASR分野の研究に勤しんでいる某大学の大学院生です。インターンではpythonでMLや暗号系の開発を行ったりしています。
夏休みのお盆明けにインターンも落ち着いて、開発をしたいと思い始めていた6月くらいに、研究室メンバーと「せっかく音声認識に強い研究室なんだから、自動でミーティングを書き起こすシステムほしいよね」という話をした結果、研究室内でハッカソンをすることになりました。
メンバーは自分を含めたM1が2人(1日だけ参加が1人)、B4が3人の合計5人で8/17~8/19の3日間で開発行いました。
そこで開発した音声認識システムの概要を記していきます。
目的
今、所属している研究室では、ミーティング(輪行やゼミなど)をハイブリッド形式で行っており、GoogleMeetを使ってオンラインでも入れるようになっています。その際、議事録を取らないといけないと思うのですが、数人で研究室内のWikiに手入力を行っており、人的コストがかかっています。
そこで、研究室内でハッカソンを行い、ASRで自動で書き起こしをするシステムを構築しました。
ハッカソンのゴールは以下の要件を満たすシステムの構築です。
- Google meetのミーティングを録音
- ASRによって自動書き起こし
- 研究室内Wiki(Outline)APIから書き起こし結果を送信
構築方法
具体的には、以下のようなシステムを構築しました。
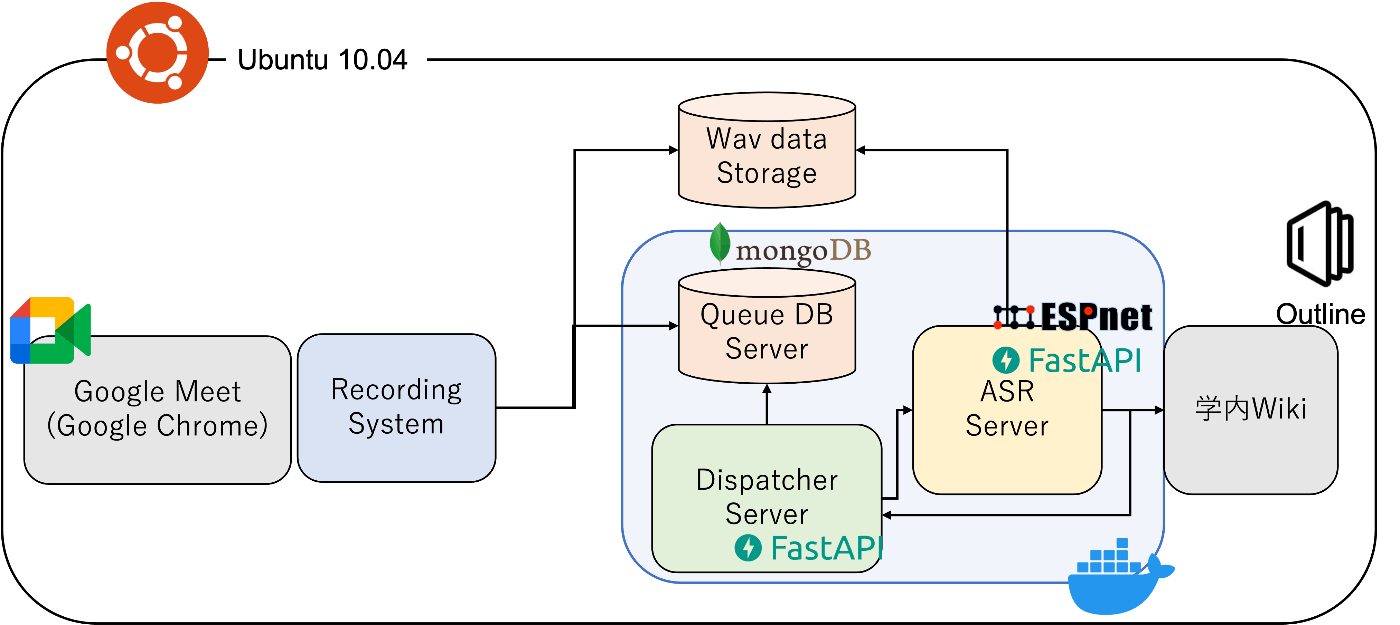
大まかには以下の5つのシステムに分かれています。
- 音声録音システム
- Dispatcher Server
- Queue DB
- ASR server
- Wiki (outline)
1.音声録音部
今回は音声を録音する機構としてPalse Audio Recorderを用いて、Ubuntuから流れている音声をそのまま録音して音声ストレージに格納するようにしました。
当初はgolangなどを用いて、ボットを作り、Google meetに参加させて録音しようと思っていましたが、
- botでmeetに入る知見がない
- golangの知見がない
- 3日しか時間がない
などの理由から、今回は非常にシンプルな方法にしました。もし知見がある方がいれば、コメントで教えていただけると、めっちゃ嬉しいです。
2. Queue DB server
録音された音声はqueue DB serverによって、FIFOで管理されます。今回はMongoDBを使いました。
採用した理由としては、
- NoSQLなので初学者にとって理解が楽
- 保持する情報が小さい、かつ対して重要なわけでもない
- できるだけ軽いものがいい
という条件があったからです。実際、RDBを用いるよりも、B4の飲み込みが早かった気がします。
MongoDBをそのまま使っただけではFIFOにならないので、statusカラムを設けて、ASRsystemから終了トリガが来たら"Done"とするようにしました。
データベースの概要は以下のとおりです。

3. Dispatcher Server
Dispatcherサーバは、以下の2つの機能を持ちます
- DBにpendingのデータが追加されたことをトリガーとして、ASRsystemにタスクを投げる。
- QueueDBから音声パスと情報を取得してASRsystemに情報を渡す。
- ASRシステムが処理が終了されれば、書き起こし結果ファイルのパスをDBに格納
今回は軽くて、学習コストの低いFastAPIを用いました。こちらをDocker containerとして運用し、常に立ち上げておきます。
4. ASR system
いよいよメインディッシュのASRsystemです。
利用した技術スタックについて、一つづつ説明していきます。
Docker
Docker Container をcompose を使って運用することにしました。この理由として、後々kubernetesでコンテナをPodsとして管理し、自動オーケストレーションにより復習処理に対応できるようにしたかったからです。
FROM pytorch/pytorch:1.11.0-cuda11.3-cudnn8-runtime
RUN apt-get -y update \
&& apt-get -y upgrade \
&& apt-get -y install \
git \
wget \
make \
cmake \
sox \
libsndfile1-dev \
ffmpeg \
flac \
coreutils
RUN apt-get -y install locales && \
localedef -f UTF-8 -i ja_JP ja_JP.UTF-8
# install ESPnet
RUN cd /opt \
&& git clone --depth 1 https://github.com/espnet/espnet \
&& cd espnet/tools \
&& rm -f activate_python.sh && touch activate_python.sh \
&& make TH_VERSION=1.11.0 CUDA_VERSION=11.3
COPY docker/asr_system/requirements.txt ./
RUN pip install -U pip setuptools \
pip install -r requirements.txt
WORKDIR /app/
FastAPI
Dispatcher サーバと同様にFastAPIで簡単にサーバを立てました。Dispathcerからの音声パスと音声の情報が送られてきます。情報が送られてくれば、background_taskとして、音声認識タスクを処理します。
本当はgRPCを使って、ストリーミングに対応できるようにしたかったのですが、学習コストが高い、コード量が増えるため、終わらないなどの理由より却下となりました。
from fastapi import FastAPI, BackgroundTasks
from pydantic import BaseModel
from asr_system.controller import Controller
app = FastAPI()
class Audio(BaseModel):
attribute: str
audio_path: str
job = Controller()
@app.get("/api/inference")
async def asr_inference(audio: Audio, background_task: BackgroundTasks):
if job.is_running is False:
background_task.add_task(job.speech2text, audio.attribute, audio.audio_path)
return {
"attribute": audio.attribute,
"audio_path": audio.audio_path,
}
return {"message": "job is running"}
ESPnet
ESPnetとは、End-to-End(E2E)型のモデルの研究を加速させるべく開発された、E2E音声処理のためのオープンソースツールキットです。ESPnet2で始めるEnd-to-End音声処理
私達の研究室では、主にコレを用いて実験しており、そのためのリソースや学習済みモデルが山程あります。なので、今回は学習期間は含めていません。
音声認識モデルとして、Transformer/CTC ASR modelを用い、学習コーパスはCSJを用いて学習させているモデルを用いています。今回はこのモデルには触れずに、後々記事にまとめようと思います。
今後は、このモデルをLaboroTVを用いて学習させたモデルに差し替えようとしています。
ESPnetは以下のようなソースで簡単に推論することができます。
import soundfile
from espnet2.bin.asr_inference import Speech2Text
s2t = Speech2Text(
asr_train_config=asr_train_config,
asr_model_file=asr_model_file,
lm_train_config=lm_train_config,
lm_file=lm_file,
audio, rate = soundfile.read(ad)
result = self.s2t(audio)
)
Sox
Transformerは非常に計算資源を必要とし、音声が長くなればなるほど膨大なメモリが必要となるモデルです。たしか、1分以上になると厳しく、GForce RTX3090でメモリエラーが出てた気がします。また、長すぎる音声は、推論に時間を要します。
そこで、 Soxのsilence機能を用いて、一定期間無音が続くと分割するようにしました。
コマンドは以下のとおりです。これをpythonのサブプロセスで叩いています。
sox input.wav output.wav silence 1 0.2 0.2% reverse silence 1 0.2 0.2% reverse
コーディング設計
今回はview,Model,Controller,Repositoryの考え方に沿ってコーディングするように設計しました。
こうすることにより、読みやすく、かつテストコードが書きやすくなります。
基本的には、以下の4つに別れています。
- Step 1 前処理(音声分割)
- Step 2 音声認識
- Step 3 後処理(Text format)
- Step 4 結果送信
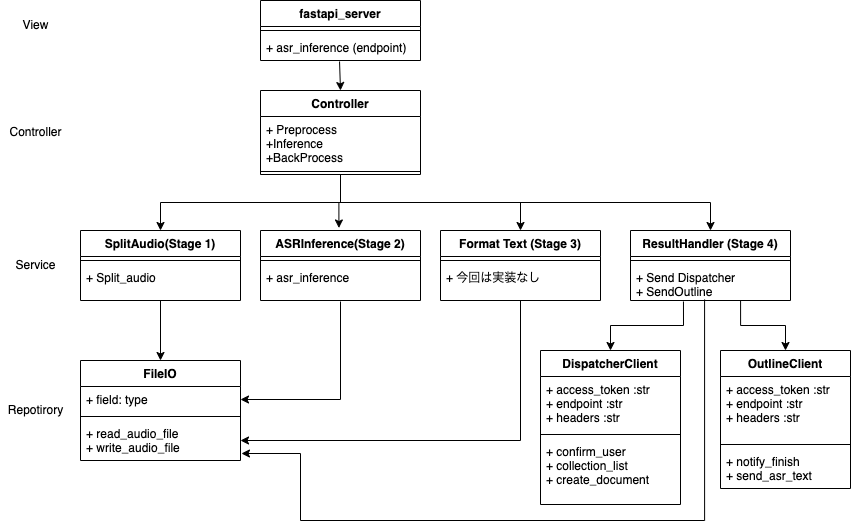
5. outline
Outlineは研究室内で利用しているオンプレのWikiサービスです。研究室内に余っているデスクトップをUbuntuサーバとして運用しています。こちらのサービスですが、Web APIが利用でき、curlなどで、リクエストを送ることで,ドキュメントの作成ができます。
こちらに利用可能なAPIが書かれています。
今回は、以下の3つを使っています。
- auth.info
- collections.list
- documents.create
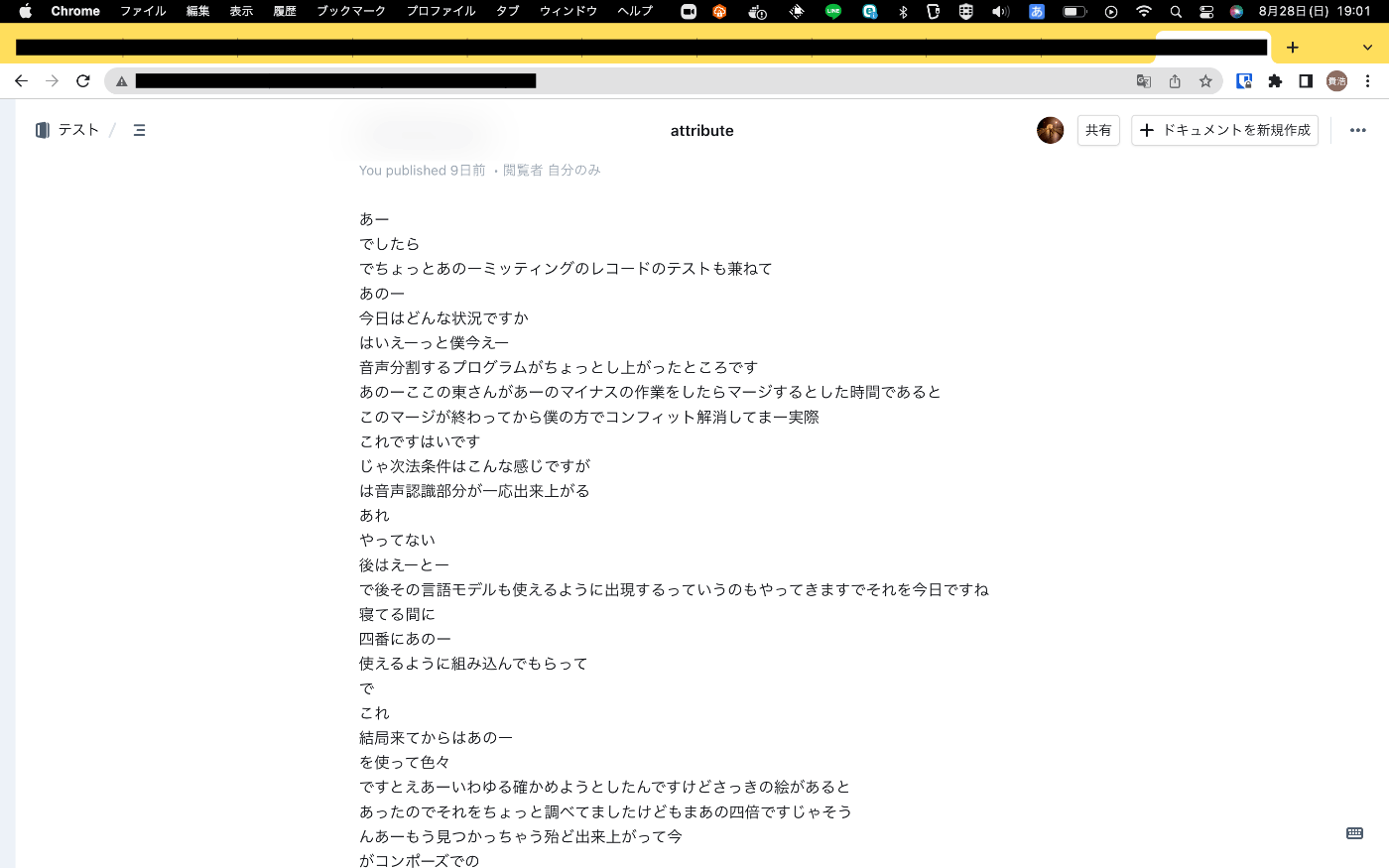
音声認識結果
you publishedになっているのは、自分のaccess tokenを用いてAPIを叩いたからです。
学習に用いたスクリプトは学術公演の話し言葉コーパスなので、カタカナや固有名詞などに対応できていない印象です。より堅牢なモデルを用いて推論すべきでしょう。
振り返り
- 今は、音声認識システムから直接Outlineに結果を送っていますが、一度Dispatcherサーバに送リ、そこからOutlineに送るべきでした。理由としては、ASRシステム単体で他のシステムに使い回せないからです。また時間があれば早く修正したいポイントです。
- M1の二人は開発に従事していたため、素早く作業に取りかかれたのですが、B4はまだ開発の経験がなかったため、Gitの使い方から始めなければならず、事前の勉強会が必要であったと痛感しました。もし次回する際は、1週間前から開発するための事前準備会を設定しようと思います。
- やはり通信をgRPCにして、相互通信とストリーミングに対応させたかったです。そのうえでkubernetesでauto scalingをできるようにしたいですね。
まとめ
今回,限られたメンバーと限られた期間でASRを用いた書き起こしシステムを構築しました。まだまだ作り込みが甘い印象ですが、とりあえず動くので、研究室内で運用、保守していこうと思います。
また、研究室内でハッカソンをすることで、技術力の向上だけでなく、縦のつながりも深くなりました。M1とB4は部屋が違うため、あまり喋る機会がなかったので、話し合う機会が増えて、楽しかったです。
今度はもっと技術力をつけてから挑んでみたいですね。
以上研究室ハッカソンの開発記録でした。
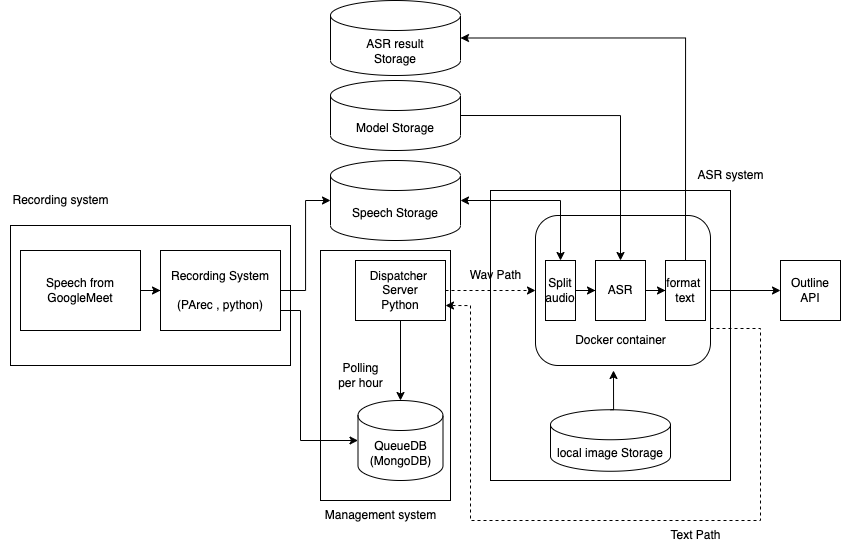
付録
実際に設計に用いた図は以下のとおりです。
Discussion