Google Cloud でのビッグデータ処理の選択肢
はじめに
こんにちは、クラウドエース データソリューション部所属の伊藤です。
普段は、データ基盤や機械学習基盤を中心とした案件に携わったり、エンジニアリングマネージャーをしたり、Google Cloud 認定トレーナーとしてトレーニングを提供したりしてます。
データ処理システムのよくある課題として、データ処理が遅い、今後データ量が増える、などといったものがあります。
そのような課題を解決するために、Google Cloud では、ビッグデータ処理を行うための様々なプロダクトが提供されています。
ただ、候補のプロダクトも多く、似た名前のプロダクトもあるため選択する際に迷うこともあるかと思います。
そこで、本記事では Google Cloud において、ビッグデータ処理に使用される各プロダクトを選択肢に入れるときのポイントや、それぞれのプロダクトの特徴をまとめてご紹介できればと思います。
選択肢フローチャート
ビッグデータ処理の選択肢を決める際のフローチャートを以下に示します。
こちらは、あくまで一例であり、状況によって選択肢が変わることがあります。
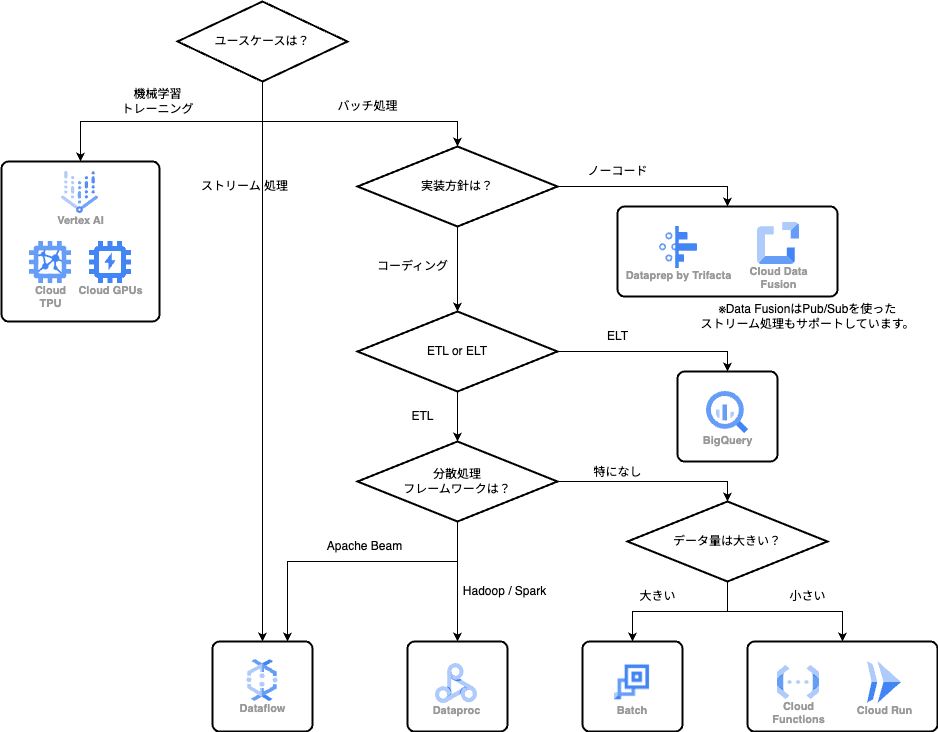
フローチャート中の ETL、ELT は Extract (データの抽出), Transform (データの変換), Load (データのロード、保存) の略です。
ETL と ELT はそれぞれ変換を先に行うかデータ保存後に行うかの違いがあります。
ビッグデータに関してと言いつつも Cloud Run や Cloud Functions などの小規模バッチ処理向けのサーバーレスサービスも含めています。
こちらに出てくるプロダクトについて、それぞれの特徴を以下にまとめていきます。
BigQuery
特徴
BigQuery は言わずと知れたペタバイト級のデータを高速かつスケーラブルに処理できる Google Cloud を代表とするデータウェアハウスサービスです。SQL でクエリを実行でき、スケーラビリティとパフォーマンスに優れています。
選択する際のポイント
- BigQuery ですべてを完結させたい場合
- 今回紹介する中で唯一データ保存から分析までを BigQuery で行うことができます
- SQL でデータ加工したい場合
- ELT 処理でも構わない場合
Dataflow
特徴
Dataflow は、Apache Beam で実装された処理を実行できるフルマネージドのストリーミングおよびバッチデータ処理サービスです。
リアルタイムのデータ処理や、機械学習の推論を分散処理で行いたい場合に適しています。
Apache Beam で独自に実装しなくとも、Google Cloud は Dataflow の多くの処理テンプレートを提供しており、簡単にデータ処理を行うことができることも特徴です。
さまざまな実行エンジンで実行できる、柔軟で移植性があり、バッチとストリームが統合されたプログラミングモデルであることが Apache Beam の特徴であり、これをフルマネージドで実行することができるデータ処理基盤が Dataflow です。
選択する際のポイント
- ストリーミング処理をしたい場合
- ストリーミングデータとバッチデータの両方を処理したい場合
- 機械学習の推論を分散処理する場合
- 分散処理が必要なデータ量で、自動スケーリングを求める場合
- Apache Beam を使用したプログラミングモデルを活用したい場合
Dataproc
特徴
Dataproc は、Apache Hadoop や Apache Spark などの Hadoop/Spark ベースの OSS ツールを使用して、ビッグデータ処理を行うためのフルマネージドサービスです。
クラスタの迅速な立ち上げとシャットダウンが可能で、オンプレミスで利用するよりもコスト効率が高くなります。
大規模バッチ処理や、機械学習モデルのトレーニング、推論などに適しています。
Streaming は利用できますが、オートスケールに対応していないのに注意が必要です。
Hadoop/Spark に慣れているエンジニアがいる場合、Dataproc は選択肢の一つとして検討できます。
選択する際のポイント
- 既存の Hadoop/Spark エコシステムを利用したい場合
- Hadoop/Spark のクラスタ管理を自動化し、コストを最適化したい場合
- Hadoop/Spark に慣れているエンジニアがいる場合
Vertex AI
特徴
Vertex AI は、機械学習モデルの構築、トレーニング、デプロイメントを一元管理できるフルマネージドプラットフォームです。
特に今回のビッグデータ処理の文脈では、機械学習モデルのトレーニングに関連するサービスを紹介します。
Vertex AI training のカスタムトレーニングでは、分散トレーニングをサポートしており、他にも TPU や GPU を利用したモデルトレーニングもサポートされています。TensorFlow や PyTorch などの機械学習フレームワークを利用している場合、Vertex AI は選択肢の一つとして検討できます。
選択する際のポイント
- 機械学習モデルの構築と運用を統合的に管理したい場合
- モデルのトレーニングを行いたい場合
- TensorFlow や PyTorch などの機械学習フレームワークを利用する場合
Data Fusion
特徴
Data Fusion は、クラウドネイティブのデータ統合サービスで、UI が提供されており、ノーコードでデータパイプラインを構築することによって ETL(Extract, Transform, Load)の構築プロセスを簡素化できます。
処理自体は従量課金制ですが、Data Fusion インスタンスには固定の料金がかかるので、長期間稼働する場合はコストを考慮する必要があります。
データソースのコネクタが豊富で、Google Cloud 以外のデータソースも利用できることが特徴です。
公式のクイックスタートより引用
選択する際のポイント
- ノーコードでデータ統合パイプラインを構築したい場合
- 複数のデータソースからデータを統合する必要がある場合
- ETL 構築プロセスを簡素化したい場合
Dataprep by Trifacta
特徴
Dataprep は、データのクリーニング、整形、変換をインタラクティブに行うためのツールです。
Google Cloud Storage、BigQuery のデータソースからデータを取得し、UI ベースの操作でデータ変換の定義を行うことができます。
Data Fusion よりもデータのクリーニング・準備に特化しており、データを可視化しながら探索的に処理を定義することができます。
作成したデータ変換のレシピは定期的に実行することもできます。実際のデータ処理は裏側で Dataflow や BigQuery が利用されます。
こちらの Marketplace もしくは Google Cloud コンソールから開始することができます。
始める場合は STARTER、PROFESSIONAL、ENTERPRISE のいずれかのエディションを選択する必要があります。固定の料金がかかってきますので、利用する際はコストを考慮する必要があります。
公式ページより引用
選択する際のポイント
- データのクリーニングや整形作業を効率化したい場合
- ノーコードでデータ準備を行いたい場合
Batch
特徴
Batch は大規模なバッチ処理ジョブを実行するためのフルマネージドサービスです。ハイパフォーマンス コンピューティング(HPC)、機械学習(ML)、データ処理ワークロードなど多様なワークロードに対応可能です。
裏側では Compute Engine (GCE) が動いているので、クオータ内で利用できるマシンインスタンススペックなら Batch サービスとして利用できます。これには GPU の利用も含まれます。
GCE をそのまま使った場合、インスタンスの立ち上げやシャットダウンといった管理作業が必要ですが、Batch はそれらを自動化してくれます。
紹介する中で最も柔軟性に富んだプロダクトと言えるでしょう。
選択する際のポイント
- 大規模なバッチ処理ジョブを効率的に実行したい場合
- 柔軟なジョブスケジューリングが必要な場合
- 多様なワークロードに対応したい場合
Cloud Run / Cloud Functions
特徴
Cloud Run は、フルマネージドのサーバーレスコンテナ実行環境です。任意のコンテナイメージを利用でき、デプロイされたコンテナは自動でスケールしてくれます。
Cloud Functions は、フルマネージドのサーバーレスコンピューティング環境で、イベント駆動型のコードを簡単に実行することができます。インフラストラクチャの管理を気にせず、必要なコードだけを書いてデプロイすることができます。Cloud Run と違いコンテナのビルドすら不要です。
両プロダクトとも今回のデータ処理の文脈では、小規模のデータ量に対してのバッチ処理に活躍します(Cloud Run のメモリ制限、Cloud Functions のメモリ制限がデータ量の参考になります)。例えば Cloud Storage にファイルが配置されたときに起動するイベントドリブンの処理などで多く活用されます。スケーラビリティが高いので、処理対象のファイルが増えても自動でスケールし処理してくれます。
選択する際のポイント
- 小規模のバッチ処理ワークロードの場合
- 処理自体の自動スケーリングが必要な場合
- イベントドリブンの処理が必要な場合
まとめ
今回は Google Cloud でのビッグデータ処理の選択肢についてまとめてみました。
ビッグデータ処理を行う際には、データの規模や処理の目的、エンジニアのスキルセット、コストなどを考慮して選択することが重要です。
また、紹介したプロダクトの中でも紹介しきれなかった機能も多数提供されているため、これらを考えるとさらに選択肢が広がります。
例えばデータサイエンスの文脈だと Vertex AI Workbench もありますし、BigQuery では今後 continuous queries という機能のリリースも予定されています。
今後の Google Cloud のアップデートにも注目していきたいですね。
Discussion