近似最近傍探索ライブラリVoyagerで類似単語検索を試す
本記事について
2023年10月にSpotifyが新たな近似最近傍探索ライブラリとして「Voyager」を発表した[1]。本記事ではVoyagerについて調べたことや、単語の類似検索をユースケースとした実装サンプル、Annoyとの性能比較の結果を備忘としてメモしておく。
近似最近傍探索とは
Voyagerの話に入る前に、近似最近傍探索について説明する。
最近傍探索 (Nearest Neighbor Search)とは、あるベクトルのクエリが与えられたときに、そのクエリと「最も似ているベクトル」をベクトルの集合から見つける技術である。
ナイーブな方法としては、クエリのベクトルと、集合の一つ一つのベクトルとの距離をコサイン類似度などで計算し、最も距離が近いものを抽出する線形探索が考えられる。しかし、このアプローチでは
そこで厳密な最近傍ではなく近似的な近傍を求める代わりに、探索に係るパフォーマンスの問題を解消する技術が近似最近傍探索 (Approximate Nearest Neighbor Search)である。
近傍探索のユースケースとしては、ベクトル化された画像データを用いた「類似画像の検索」やベクトル化された文章データを用いた「類似文章の検索」などが挙げられる。
Voyagerとは
VoyagerはSpotify社が2023年10月に発表した近似最近傍探索のライブラリであり、OSSとしてGitHubにコードが公開されている[2]。Voyagerは従来Spotifyが開発してきた近似最近傍探索ライブラリ「Annoy[3]」の後継として実際に本番環境で運用されている。
特徴
Voyagerの特徴をSpotify Engineeringのブログ記事から、主に性能面の観点での特徴をいくつか抜粋して記載する。
- Annoyと比較して、同じrecallで10倍以上の速度
- Annoyと比較して、同じ速度で最大50%の精度向上
- Annoyと比較して、最大4倍のメモリ使用量の削減
上記の通り、精度 / 探索速度 / メモリ効率といった観点において、従来のAnnoyを上回る性能を持っている。
アルゴリズム
Voyagerは「Hierarchical Navigable Small World (HNSW)[4]」という近似最近傍探索アルゴリズムを使用している。近似最近傍探索のアルゴリズムにはツリーベースのもの、ハッシュを利用したもの、グラフベースのものなどいくつかのカテゴリがあるが、このHNSWはグラフベースのカテゴリに属する手法である。
HNSWでは探索対象となる各アイテムを、それぞれ異なるエッジのスケールを持つ階層的なグラフ構造で表現する。あるクエリに対して近傍の探索を行うときは、エッジ数の少ないトップの階層のノードから探索を開始し、近傍に辿りついたらエッジの数がより多い次の下の階層に移動してまた探索を行う。この操作を一番下の階層まで繰り返す。
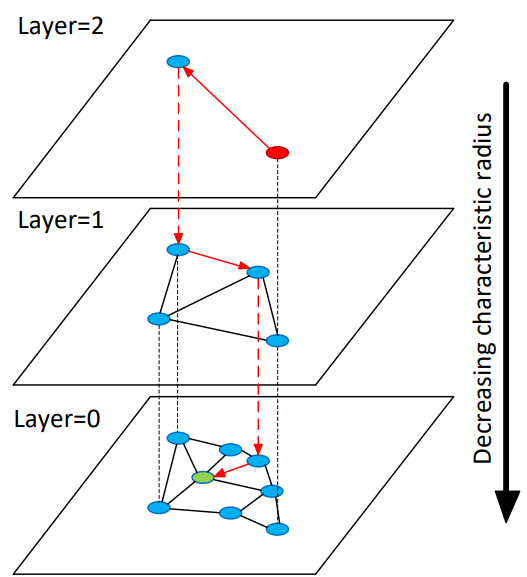
論文より抜粋したHNSWの概念図。トップの階層(Layer=2)から探索を開始し(赤の点)、探索対象のクエリ(緑の点)の最近傍に達するまで近傍探索→下の階層への移動を繰り返す
直感的には目的地まで辿り着くのに各駅停車だけを使って行くのではなく、飛行機を使ってある程度近くまで行って、特急に乗り換えてさらに近づき、最後は各駅停車で目的地まで行くことで、移動にかかる時間を抑える、というイメージとして理解できる。
このような階層的なグラフ構造を用いることにより、HNSWがベースとしている手法のNavigable Small World (NSW)[5]が抱えていた、探索の計算量がネットワークのサイズに対してpoly-logarithmic (
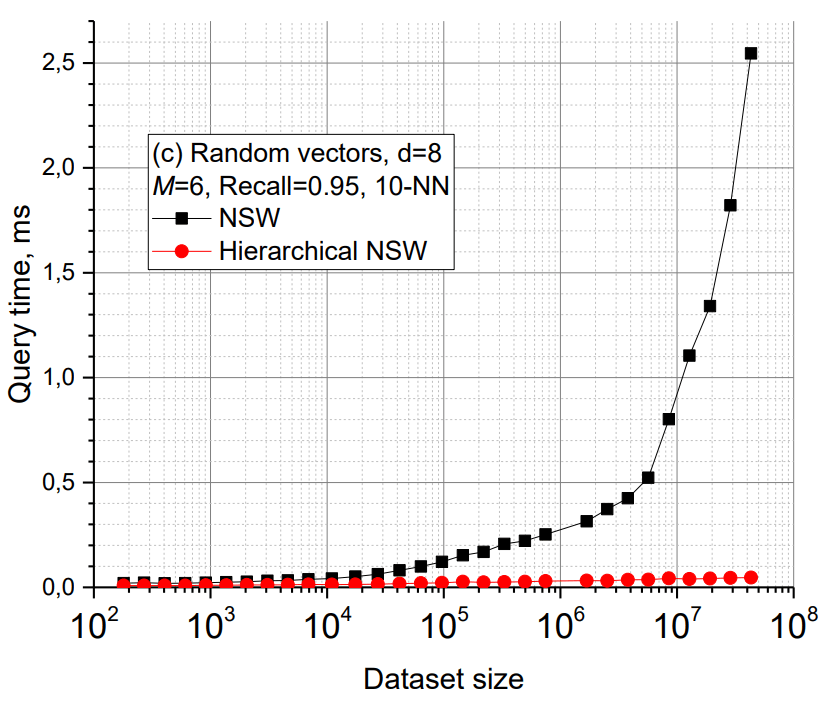
論文より抜粋したHNSWとNSWの探索時間の比較。NSWに対してHNSWでは、データセットのサイズ(横軸)の増加に対して探索にかかる時間(縦軸)が低く留まっていることが分かる。
なおこのHNSWは、本記事で紹介するVoyager以外にも以下に挙げる複数の近似最近傍ライブラリで実装されている。
実際に動かしてみる
ここからは実際にVoyagerを使って近傍探索を実装し、その結果を確認してみる。本記事ではGlobal Vectors for Word Representation (GloVe)[9]を用いて獲得された、事前学習済みの単語ベクトルを使用して、単語の類似検索をVoyagerで実現する。
データセットの準備
まずはGloVeの事前学習済みの単語ベクトルのデータセットを準備する。
import os
import urllib.request
from zipfile import ZipFile
GLOVE_FILE_NAME = 'glove.6B'
def download_glove_dataset(output_dir='glove', file_name='glove.6B'):
# GloVeのデータセットのURL
url = f'http://nlp.stanford.edu/data/{file_name}.zip'
# 出力ディレクトリの作成
os.makedirs(output_dir, exist_ok=True)
# ダウンロードしたZIPファイルの保存パス
zip_file_path = os.path.join(output_dir, f'{file_name}.zip')
# ファイルが既に存在する場合はダウンロードをスキップ
if not os.path.exists(zip_file_path):
print(f'Downloading {file_name} dataset...')
urllib.request.urlretrieve(url, zip_file_path)
print('Download complete.')
# ZIPファイルを解凍
with ZipFile(zip_file_path, 'r') as zip_ref:
zip_ref.extractall(output_dir)
print(f'{file_name} dataset is available in the "{output_dir}" directory.')
# GloVeデータセットのダウンロード
download_glove_dataset(output_dir='glove', file_name=GLOVE_FILE_NAME)
インターネット接続がある環境から上記のPythonコードを実行することで、400,000の単語に対するベクトル表現のデータがローカルのディレクトリにダウンロードされる。
次にダウンロードしたファイルはテキスト形式であるため、後続の処理でデータを扱いやすいようにPandasのデータフレームに変換しておく。
import numpy as np
import pandas as pd
NUM_DIMENSION = 50
def load_glove_vectors(file_path):
# ファイルを読み込み、各行をリストに格納
with open(file_path, 'r', encoding='utf-8') as file:
lines = file.readlines()
# 各行を単語とベクトルに分割し、データを格納するリストを初期化
words = []
vectors = []
for line in lines:
parts = line.split()
word = parts[0]
vector = np.array([float(value) for value in parts[1:]], dtype=np.float32)
words.append(word)
vectors.append(vector)
# データフレームに変換
df = pd.DataFrame({'Word': words, 'Vector': vectors})
return df
# GloVeデータセットの次元数とファイル名
file_name = f'{GLOVE_FILE_NAME}.{NUM_DIMENSION}d.txt'
# ファイルのパス
file_path = os.path.join('glove', file_name)
# GloVeベクトルのデータフレームを読み込む
glove_df = load_glove_vectors(file_path)
ダウンロードしたファイルには、ベクトルの次元数が異なる4つのファイル(50, 100, 200, 300)が含まれる。ここでは次元数が50のものを使用している。
glove_df.sample(5)
出力結果

インデックスの作成
ここからVoyagerによる近似最近傍探索を行う。前準備としてVoyagerをpipでインストールする。
!pip install voyager
次に単語ベクトルからインデックスを作成する。
from voyager import Index, Space
# Voyagerのインデックス作成
index = Index(Space.Cosine, num_dimensions=NUM_DIMENSION)
vectors = glove_df['Vector'].to_numpy() # shape = (num_vectors,)
vectors = np.stack(vectors, axis=0) # shape = (num_vectors, num_dimension)
_ = index.add_items(vectors)
最初の行ではvoyager.Indexクラスからインデックスのインスタンスを初期化している。初期化にあたり2つのパラメータを指定している。
-
space: voyager.Space-> ベクトル間の距離の計算方法。ユークリッド距離、内積、コサイン距離から選択が可能。ここではコサイン距離を選択。 -
num_dimensions: int-> ベクトルの次元数。ここでは今回使用している単語ベクトルの次元数に従って50を指定。
次に単語ベクトルを格納したデータフレームから、単語数×ベクトル次元数のnumpyの2次元配列(vectors)を準備したうえで、add_itemsメソッドでインデックスに各単語のベクトルを追加する。なお公式のAPIドキュメントによると、ベクトルを1つずつ追加するadd_itemメソッドよりも、こちらのadd_itemsを用いるほうが高速に処理できるとのことである[10]。
近似最近傍探索の実行
インデックスの準備ができたので、実際にクエリに対して類似するベクトルの探索を試してみる。下のコードでは、"king", "dog", "justice"という3つの単語に対し、それぞれの単語の近傍の探索をVoyagerを用いて実行している。
# 近傍探索:Voyagerによる近似最近傍探索
word_list = [
"king",
"dog",
"justice",
]
for word in word_list:
print(f"===== query word : {word} =====")
row = glove_df[glove_df["Word"] == word]
if len(row) == 0:
print(f"there is no vocabulary for query word : {word}")
continue
query_vector = row["Vector"].to_list()[0]
neighbors_indices, distances = index.query(query_vector, k=4)
neighbors = glove_df.iloc[neighbors_indices[1:]] # クエリとしているベクトルは除く
neighbors = neighbors["Word"].to_list()
print(f"neighbor words : {neighbors}")
実際に探索を行っているのは、index.queryの部分である。ここでクエリとなるベクトル(query_vector)と、何番目までの近傍を探索するか?のパラメータ(k)を指定している。
このコードを実行すると、以下のような出力が得られる。
出力結果

クエリとしている単語に対して、関連する単語を見つけられていることが分かる(例:kingに対してprince, dogに対してcat, justiceに対してlawなど)。
ナイーブな方法(線形探索)による最近傍探索との実行結果と比較してみる。
# 近傍探索:線形探索による最近傍探索
from sklearn.metrics.pairwise import cosine_similarity
word_list = [
"king",
"dog",
"justice",
]
def get_top_n_similar_vectors(query_vector, vector_set, n):
# クエリとベクトルセットのCosine類似度を計算
similarities = cosine_similarity([query_vector], vector_set)[0]
# 類似度が高い上位N個のベクトルのインデックスを抽出
top_n_indices = np.argsort(similarities)[-n:][::-1]
return top_n_indices
for word in word_list:
print(f"===== query word : {word} =====")
row = glove_df[glove_df["Word"] == word]
if len(row) == 0:
print(f"there is no vocabulary for query word : {word}")
continue
query_vector = row["Vector"].to_list()[0]
top_n_indices = get_top_n_similar_vectors(query_vector, vectors, 4)
neighbors = glove_df.iloc[top_n_indices[1:]] # クエリとしているベクトルは除く
neighbors = neighbors["Word"].to_list()
print(f"neighbor words : {neighbors}")
出力結果

Voyagerの結果と一致する結果が得られた。少なくともこれらのサンプルの単語に対しては、Voyagerによる近似最近傍探索はナイーブな最近傍探索と同じ近傍ベクトルを抽出できていることが分かる。
Annoyとの性能の比較
最後にVoyagerとAnnoyとで、性能の比較を行ってみる。Voyager, Annoyそれぞれについて、同一のデータセットに対して複数のパラメータでインデックスの作成→近傍の探索を行い、探索にかかる時間や精度(recall)の比較を行う。比較にあたり、近傍探索のベンチマーク用のリポジトリであるann-benchmarks[11]を使用した。
以下はデータセット:GloVe(ベクトルの次元数=100)に対する、精度と探索速度のトレードオフをVoyagerとAnnoyとで比較したものである。横軸にrecall、縦軸に1秒あたりに探索できたクエリ数をプロットしており、図の右上に点があるほど性能が良いと言える。図を見ると分かる通り、Annoyに比べてVoyagerは同程度のrecallに対してより多くのクエリ探索を、同程度のクエリ探索数に対してより良いrecallを実現できていることが分かる。

Glove(ベクトルの次元数=100)に対するrecallと探索速度のトレードオフをVoyagerとAnnoyで比較したもの。横軸がRecall, 縦軸が1秒あたりの探索数。
インデックスのサイズの比較も行ってみる。VoyagerとAnnoyで同程度のRecallを実現しているランを取り出し、インデックスのサイズを比較したのが以下の表である。Annoyに比べてVoyagerは、よりサイズが小さいインデックスで同程度のRecallが実現できていることが分かる。
| Algorithm | Hyper Parameter | Recall | Size of index (MB) |
|---|---|---|---|
| Voyager | M: 36, ef_construction: 500 | 0.99294 | 956 |
| Annoy | n_trees: 100, search_k: 200000 | 0.99234 | 2672 |
以上から、Spotify Engineeringのブログ記事にあったとおり、VoyagerはAnnoyと比較して精度 / 探索速度 / メモリ効率の観点においてより良い性能を実現できることが確認できた。
まとめ
Spotifyが発表した近似最近傍探索ライブラリVoyagerはHNSWというグラフベースのアルゴリズムを使用して高速でスケーラブルな近傍探索を実現しており、従来Spotifyが開発してきたAnnoyと比較して、精度 / 探索速度 / メモリ効率といった観点においてAnnoyを上回る性能を持っている。
-
Introducing Voyager: Spotify’s New Nearest-Neighbor Search Library ↩︎
-
Malkov, Y.A., Yashunin, D.A.: Efficient and robust approximate nearest neighbor search using Hierarchical Navigable Small World graphs. ArXiv e-prints (Mar 2016) ↩︎
-
Y. Malkov, A. Ponomarenko, A. Logvinov, and V. Krylov, "Approximate nearest neighbor algorithm based on navigable small world graphs," Information Systems, vol. 45, pp. 61-68, 2014. ↩︎
-
Jeffrey Pennington, Richard Socher, and Christopher D. Manning. 2014. GloVe: Global Vectors for Word Representation. ↩︎
Discussion