【Better than ReLU】What is GLU ?【Method】
Original paper: Language Modeling with Gated Convolutional Networks
1. What is GLU(Gated Linear Units)?
GLU is a method for adjust the quantity of information pass through to forward. As trditional method to prove it, we recall activation layers like sigmoid or ReLU, but in here, we consider a different method called GLU.
What is the actual behavior of activation layes? That is multiply number between 0 to 1.
GLU provide it by linear layer with sigmoid function.
Let's see the formula.
・
This is the GLU formula. The
・Inprementation
class GLU(nn.Module):
def __init__(self, in_size):
super().__init__()
self.linear1 = nn.Linear(in_size, in_size)
self.linear2 = nn.Linear(in_size, in_size)
def forward(self, X):
return self.linear1(X) * self.linear2(X).sigmoid()
The linear2 works same as a activation layer.
・Making it faster
class FastGLU(nn.Module):
def __init__(self, in_size):
super().__init__()
self.in_size = in_size
self.linear = nn.Linear(in_size, in_size*2)
def forward(self, X):
out = self.linear(X)
return out[:, :self.in_size] * out[:, self.in_size:].sigmoid()
Those two imprementation are the same operation, but first one has two matrix multiplications(linear1 and linear2), and for this last one only one matrix multiplication. So it's faster.
This is a GLU, it use linear layer with sigmoid instead of activation layer.
By the way, don't you think the ideas of GLU similar to LSTM? That's ture, GLU inspired from LSTM's gated unit.
2. Comparisons
In the original paper, GLU compared to other activation methods. The result is this:
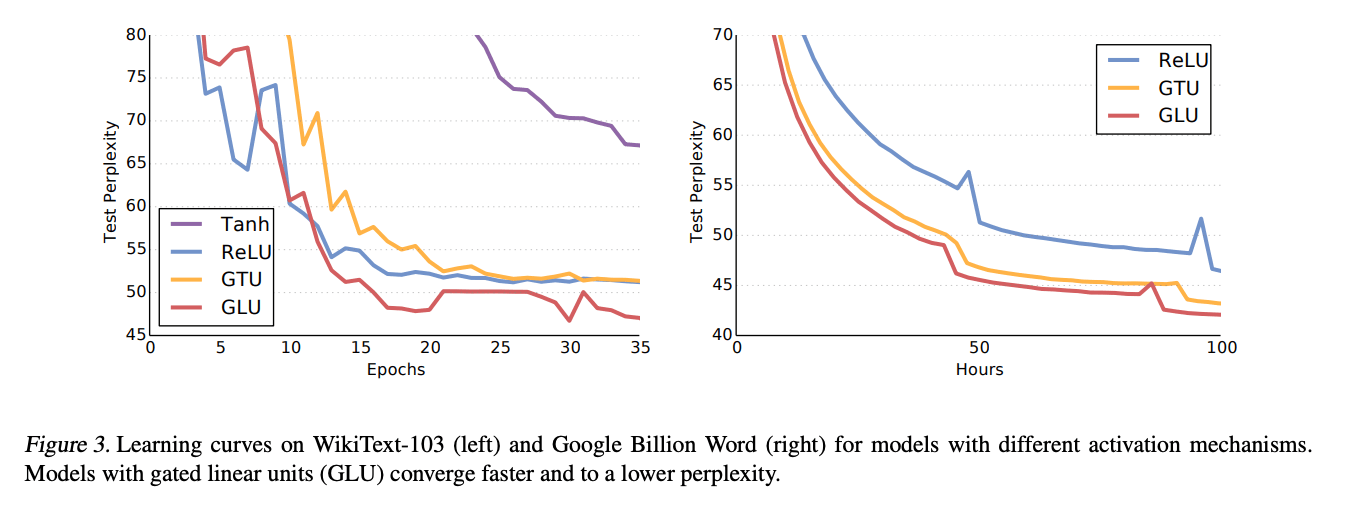
Quote: Language Modeling with Gated Convolutional Networks
^1
GLU achieved better, stable and faster result than others in natural language tasks, and, it is adopted new great model such as "Conformer".
These things show that GLU works well.
3. Conclutions
The most inportant thing is that GLU is far more stable than ReLU and learns faster than sigmoid.
Thank you for reading.
References
[1] Yann N. Dauphin, Angela Fan, Michael Auli, David Grangier, "Language Modeling with Gated Convolutional Networks", 2016
[2] Alvaro Durán Tovar, "GLU: Gated Linear Unit implementation"
Discussion