


本記事の背景
現在、筆者の企業で機械学習(Machine Learning)パイプラインの技術選定を行なっており、機械学習パイプラインにおいてどの部分にどの技術を利用するか検討しています。そのための情報収集を行なっている際に、Snowflake 社の Data Cloud Academy Data Scientist School という主に Data Scientist や ML エンジニア向けの動画を集めた Web サイトが公開されており、機械学習パイプラインの参照アーキテチャについて言及されていることを発見しました。
筆者の企業では、クラウドサービスとして AWS および Snowflake を利用しており、両者をどう組み合わせるか考えていたため、同コンテンツで言及されている内容で学習し、さらに筆者なりの考えをまとめて整理しました。本記事では、AWS と Snowflake を組み合わせて機械学習パイプラインを構築する際の筆者なりの推薦事項について紹介します。
機械学習パイプラインとは
読者の中には機械学習パイプライン自体が何かご存じない方もいらっしゃると思いますので、先に ML パイプラインが何かを紹介します。以下は、ML モデル構築自動化サービスで有名な DataRobot 社のブログからの引用です。色々検索して出てきた中でわかりやすいので紹介します。
What is an ML pipeline?
One definition of an ML pipeline is a means of automating the machine learning workflow by enabling data to be transformed and correlated into a model that can then be analyzed to achieve outputs. This type of ML pipeline makes the process of inputting data into the ML model fully automated.
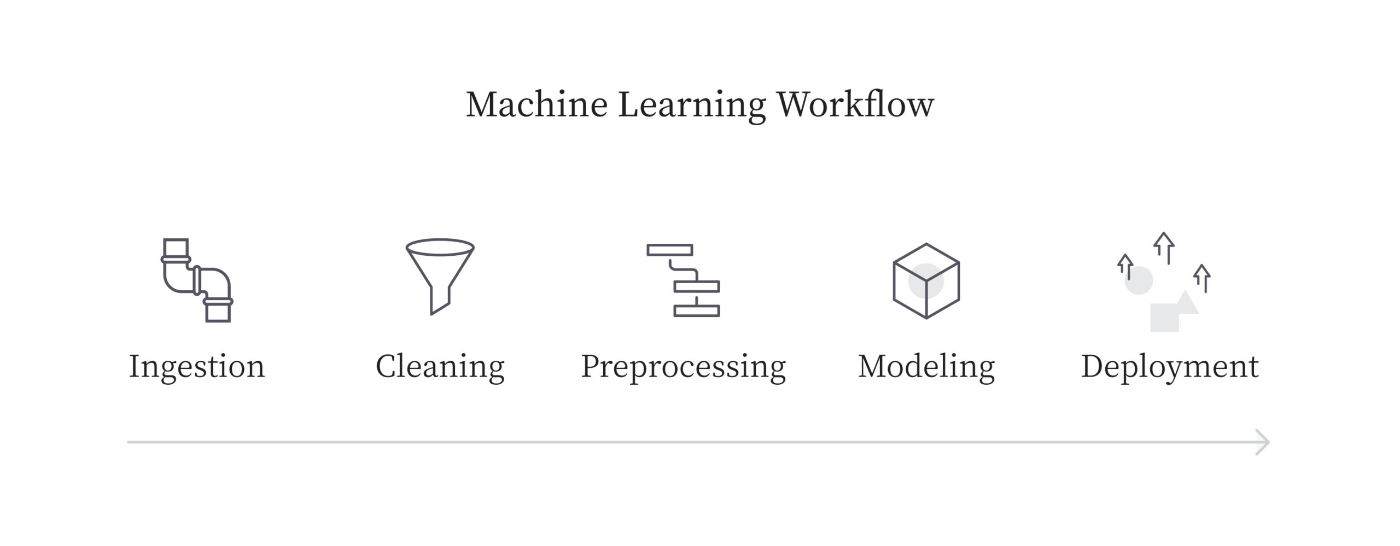
要は、自社の機械学習モデルを使ったユースケースにおいて継続的にモデルを更新し、デプロイする必要性があった場合、一通りの工程を安定的に手動で行い続けるのは困難なため、一連の工程をソフトウェアで自動化しようというものです。
機械学習パイプラインは大きく分けて以下の4つのフェーズにわけて考えることができます。実際にプロジェクトで機械学習パイプラインを構築する場合は、各工程においてユースケースや要件に応じて利用する技術やサービスを選定する必要があります。
- データの準備 (Prepare)
- 外部のデータソースからデータウェアハウスへデータの投入(Ingestion)
- データの整理(Cleaning)
- 前処理(Preprocessing)
- モデルの構築 (Build)
- モデルのデプロイ (Deploy)
- モデルの監視 (Monitor)
機械学習パイプラインの詳細については以下にも解説があるので、ご興味あればご覧ください。
機械学習パイプラインの工程ごとに利用するべき Snowflake の機能または外部サービス
機械学習パイプラインの概要やフェーズについて説明したところで、次は、どのような機能やサービスを利用するべきかについて議論します。Data Cloud Academy Data Scientist School の Web サイト上に "Snowflake for Data Science Overview" というタイトルの動画で以下の図が紹介されています。
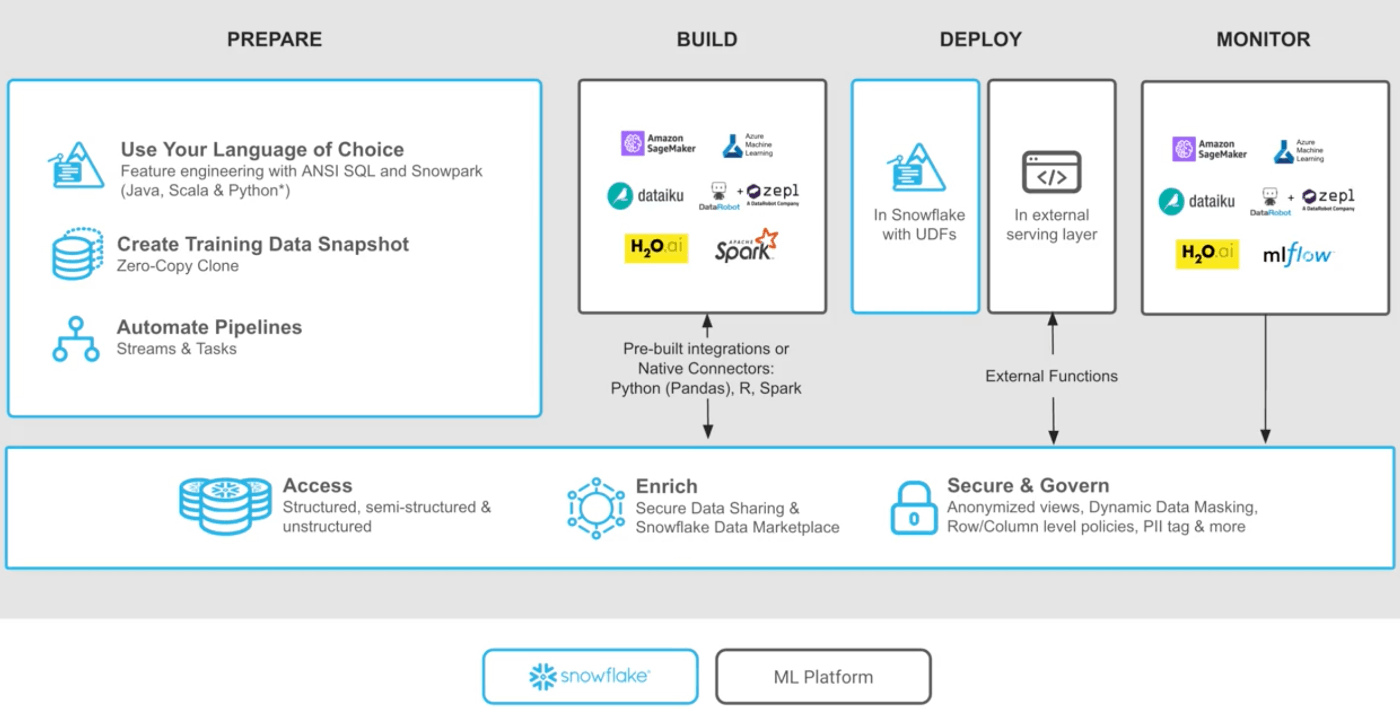
上記の図では、機械学習パイプラインの以下の4つのフェーズについて、それぞれ利用するべき Snowflake 上の機能、もしくは外部サービスが紹介されています。なお、薄い青の枠が Snowflake の機能、灰色の枠が外部サービスを表現しています。
(1) PREPARE(データの準備)
これはデータの投入(Ingestion)、データの整理(Cleaning)、前処理(Preprocessing) などを含んだフェーズでしょう。Snowflake の機能としては以下が推奨されています。
- ANSI SQL や Snowpark(Java, Scala, Python)・・・(注)Snowpark Pythonは 2022年3月時点でまだプライベートプレビュー中です。
- ゼロコピークローンを利用したトレーニング用のスナップショットデータ
- ストリーム・タスクを使った自動化パイプライン
筆者としては、一般的なデータ処理は可能な限り、Snowflakeの機能を使って実現することに大いに賛成です。Snowflake は非常にスケーラブルであり、パフォーマンス上の心配もあまりありません。外部にデータを出力する場合はセキュリティやプライバシーの問題が発生する可能性があるため、Snowflake 内に閉じて処理できることが望ましいと思います。
一方で、2022 年 3 月時点では、Snowpark Python はプライベートプレビュー中であり、SQL では実装が困難な複雑な処理を Java/Scala ではなく Python で実装したい場合、AWS であれば以下のサービスを利用すると良いと思います。
- AWS Glue・・・サーバレスの ETL サービスであり、プリインストールされたSpark、scikit-learn、SciPy、NumPyといった Python ライブラリを使ってデータ処理を実現できます。
- SageMaker・・・サーバレスの機械学習用のサービスです。Spark、scikit-learn、SciPy、NumPyといった Python ライブラリをインストール済みのコンテナイメージを利用して一般的なデータ処理を実現できます。
(2) BUILD(モデルの構築)
Snowflake は機械学習に特化したサービスや機能は提供していないため、機械学習用途の外部サービスの利用が推奨されています。
モデルの構築を自動化したい場合、AutoML の一種である DataRobot と Snowflake を連携できます。
また、AWS SageMaker では単純なコンピューティングだけでなく、モデルのレポジトリ、Feature Store、メトリクスの監視、など機械学習に必要なサービス・機能が一式用意されています。
(3) DEPLOY(モデルのデプロイ)
モデルのデプロイについては、Snowflake 自身は機械学習をデプロイする機能は提供していないため、以下の2種類の方法が推奨されています。
(3-1) 外部サービスの利用
AWS SageMakerでは、モデルレジストリでのモデルの管理、バッチとリアルタイムの両方についてモデルを使った予測を行う機能が提供されています。
リアルタイム予測用の API を SageMaker 上にデプロイした場合、Snowflake の外部関数を利用すれば、SQL 上で外部 API を通じてモデルを利用することができます。
(3-2) Java UDFを使った予測
Snowflake は Java UDF をサポートしているため、外部の機械学習サービスで構築したモデルをステージに上げれば、Java UDF でモデルを参照し、予測を行うことができます。以下の図は "Unleashing the Power of Java UDFs" という動画で紹介されています。
外部関数を使った外部 API の呼び出しと比較すると、モデルと UDF が Snowflake 上にあるため、よりセキュアに予測を行うことができます。
なお、モデルのフォーマットは言語によって異なるため、トレーニングを Python で行う場合、予測は Python UDF でやった方が良いでしょう。
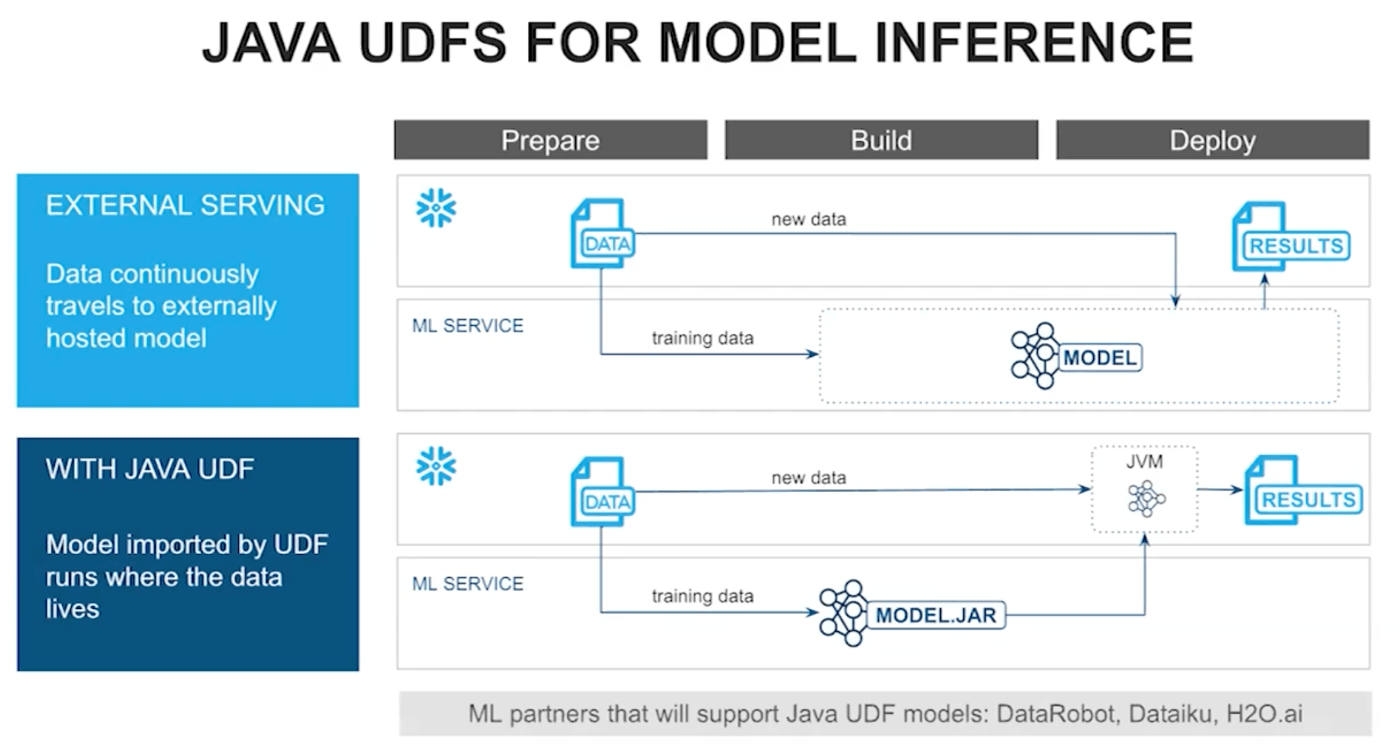
(4) MONITOR(モデルの監視)
Snowflake 自身にモデルのモニタリング機能がないため、監視は外部サービスを利用するのが良いでしょう。
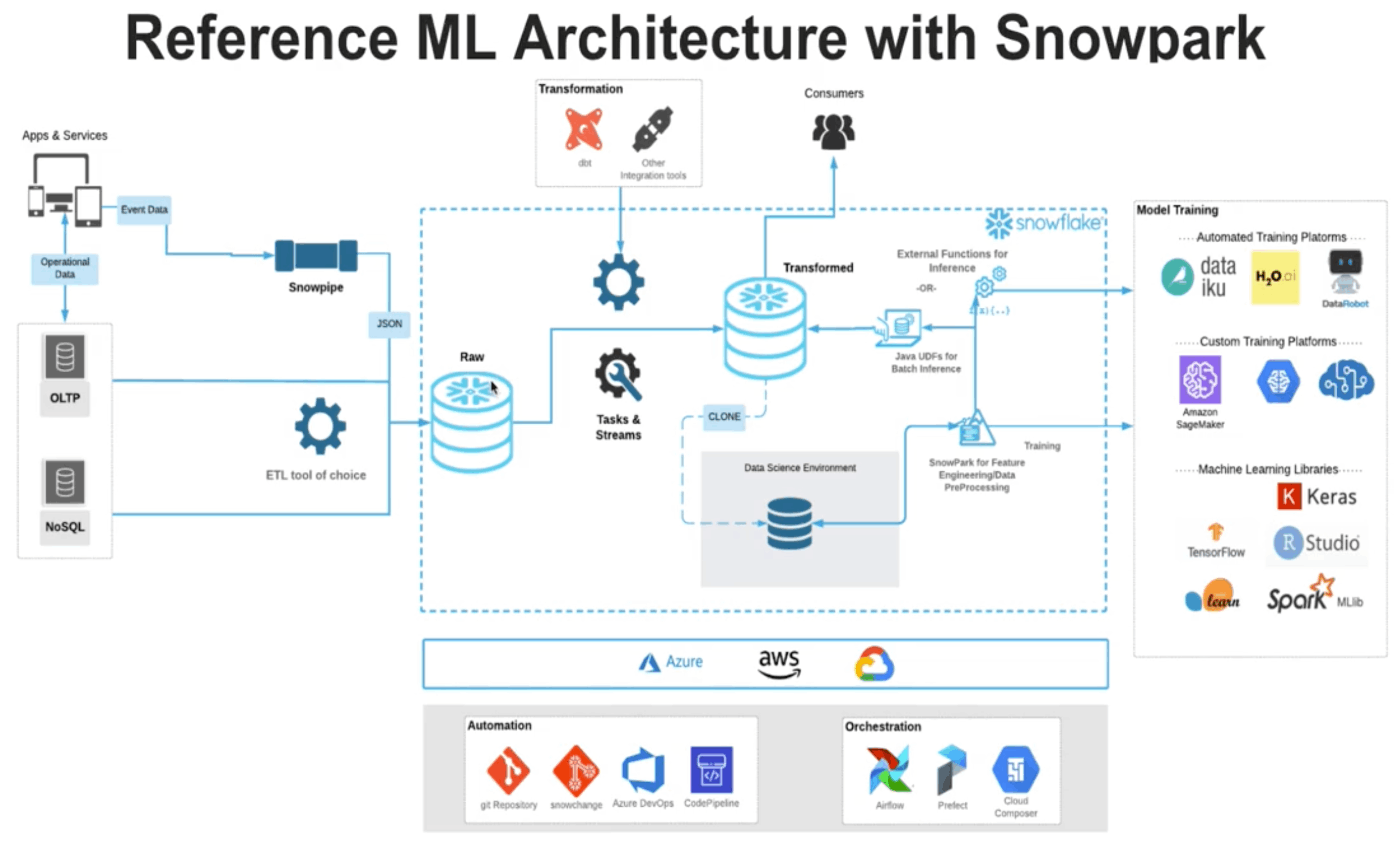
機械学習パイプラインの参照アーキテクチャ
以上の議論を踏まえた機械学習パイプラインの参照アーキテクチャは以下の図の通りです。
こちらはあくまで参照アーキテクチャであり、プロジェクトの事情や要件に応じて、適切な Snowflake の機能や外部サービスを組み合わせていくと良いでしょう。
まとめ
本記事では、Data Cloud Academy Data Scientist School で紹介されていた主に機械学習パイプラインのアーキテクチャについて、動画で紹介されている推奨事項や筆者なりの見解を紹介しました。もし読者で機械学習パイプラインを検討されている方がいらっしゃれば、本記事が何かの参考になれば幸いです。
先日、会社のアカウントでプライベートプレビュー中の Snowpark Python が利用できるようになりました。次回は、例を使って Snowpark をどのように機械学習モデルの構築に利用できるか紹介したいと思います。

Discussion