はじめに
今年、新卒としてシステム基盤チームに入り、SRE業務を行っている吉田です。現在は新規プロダクトのインフラ構築・運用作業をメインに取り組んでいます。
今回は、Aurora PostgreSQLとS3を利用したデータマスキング処理(以下、マスキング処理)の実例から、Aurora MySQLとAurora PostgreSQLの仕様の違いや利用時の注意点についてご紹介していきます。
目的・課題
マスキング処理の目的
マスキング処理は、本番データに含まれる機密情報を識別できない別の文字列へ置き換える仕組みを指します。
私たちシステム基盤チームは、開発者が障害調査やお客様からのお問い合わせ調査を安全に実施できるよう、マスキング処理済みデータベースを提供しています。
マスキング処理の課題
これまでAurora MySQL向けのマスキング処理基盤を提供してきましたが、新規プロダクトの立ち上がりに伴い、Aurora PostgreSQLでも同様の環境を提供する必要がありました。
同じAuroraとはいえ、データベースエンジンが異なるため、実装方式や動作仕様の違いを踏まえた対応が求められました。
構成
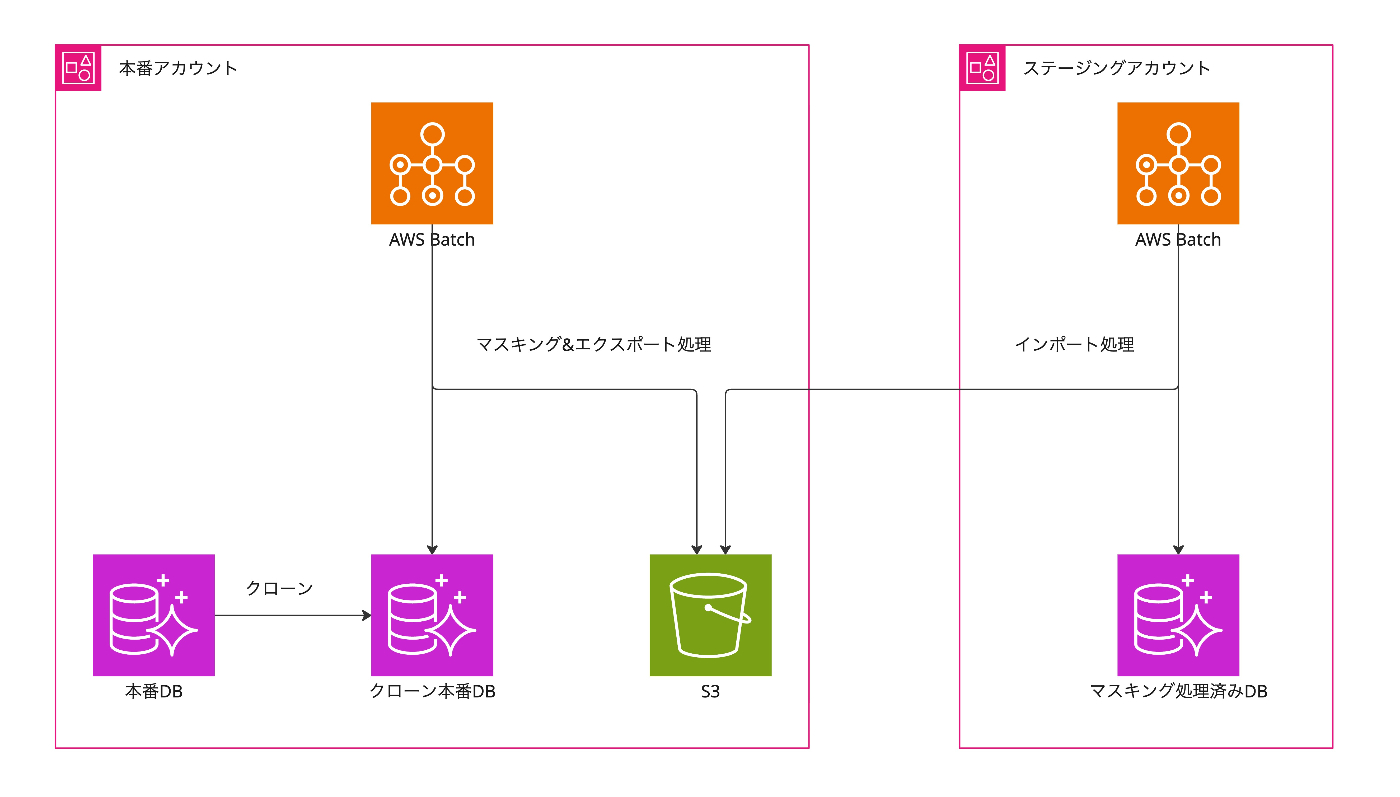
簡単な構成は上記の図の通りです。
マスキング処理は、Step Functionsにより以下のワークフローで自動実行されます。
- 本番DBをクローンした、クローン本番DBを用意する。(マスキング処理により、本番DBに対して負荷がかかることを避けるため。)
- クローン本番DBから取得したデータをマスキング処理[1]したデータをS3へ格納する。(マスキング&エクスポート部分)
SELECT *
FROM aws_s3.query_export_to_s3(
'select column1, column2, ''****'', column4 from example_table',
aws_commons.create_s3_uri('<バケット名>', '<パス>', '<リージョン>'),
'format csv, header true'
);
3. マスキング処理されたデータをS3からマスキング処理済みDBへ格納する。(インポート部分)
SELECT aws_s3.table_import_from_s3(
'example_table',
'', -- 列を指定しない場合、全ての列をテーブルへコピー
'(format csv, header true)',
aws_commons.create_s3_uri('<バケット名>', '<パス>', '<リージョン>')
)
構築時に注意した点
カスタマーマネージドキーのKMSを用意
Aurora PostgreSQLとS3間のデータ送信時にaws_s3拡張機能を利用しました。これにより、Aurora PostgreSQLからS3へ直接データを送信・保存することが可能になります。
ただし注意点として、上記のクロスアカウントの構成では、インポート時にマスキング処理済みDB側からKMSキーの復号権限を付与する必要があるため、Aurora PostgreSQLにおいてデフォルトで設定されるSSE-KMS(AWSマネージドキー)をそのまま扱うことができません。そのため、新規にカスタマーマネージドキーのKMSを作成するようにしました。新規作成したKMSキーは以下のように、SQLクエリ内に指定する必要があります。
SELECT *
FROM aws_s3.query_export_to_s3(
'select column1, column2, ''****'', column4 from example_table',
aws_commons.create_s3_uri('<バケット名>', '<パス>', '<リージョン>'),
'format csv, header true',
'<KMSリソースarn>' -- 指定が必要
);
PostgreSQLの権限設定
PostgreSQLはMySQLと比べて、スキーマやテーブルなどの各オブジェクトに適用する権限が異なっている上、拡張機能を導入することでオブジェクトの権限管理がさらに複雑になります。
マスキング処理時に権限エラーが発生しないように、必要な権限を再整理し、権限を管理しやすいようにロールを設計し直しました。
インポート時の外部キー制約エラー回避
インポートを実行する際、一時的に外部キー制約によるエラーを回避する必要があります。オープンソース版PostgreSQLでは、session_replication_roleの変更により実現可能です。
しかし、session_replication_roleを含むPostgreSQLの一部の設定値の管理は、DBクラスターのパラメータグループで制御される仕組みとなっており、SQLクエリによる変更ではなく、パラメータグループを変える必要がありました。
ちなみに、外部キー制約によるエラーを回避するためのパラメータグループの変更と、インポート処理後にパラメータグループを元に戻す変更については、前述したStep Functions内で自動的に処理するようにしています。
空テーブルインポート時の制御
インポートを実行する際にはaws_s3.table_import_from_s3関数を利用していますが、この関数は対象ファイルのレコード数が0件である場合にエラーになります。
Importing 0 bytes file will cause an error.
その際にエラーが発生してしまうことを回避するため、バッチ側で制御を行う必要がありました。具体的には、エクスポート時の段階から、レコード数が0件であるテーブルに対してはS3へファイルを作成する処理をスキップするように制御しています。
まとめ
今回はAurora PostgreSQLとS3を利用したマスキング処理実装の実例を書きつつ、Aurora MySQLにはなかったAurora PostgreSQLでの仕様の違い、注意した点についても触れさせていただきました。
今回はPostgreSQLの権限設定やAurora PostgreSQLの仕様に関して手詰まってしまう場面が多々ありましたが、落ち着いて整理しながら細部のキャッチアップを進め始めてからは、納得しながらスムーズに進められたという感覚がありました。何でもかんでも無闇に触ってみることは控え、一旦冷静に立ち止まり、細部にわたるまでキャッチアップを進めてみるということも大事にしたいと感じました。
この記事が皆様のお役に立てれば幸いです。
-
例として、機密情報部分を****と置き換えるマスキング処理を表現しています。 ↩︎

Discussion