Closed10
Meilisearch を利用して Sphinx で日本語全文検索を実現する
前提
- 日本語全文検索に対応する
- OSS を利用する
- ドキュメントツールは Sphinx を利用する
- Sphinx の検索バーを置き換える
- サーバレスの検索は諦める
- サーバ運用を検討する
- 企業利用前提なので費用がかかっても良い
- 検索は難しいので検索部分は頑張らない
- 完璧は求めない
- reStructuredText を解析するのではなく HTML を解析して処理する
Meilisearch を採用
いろいろ調べたりしていたが Meilisearch が良さそうと判断した。
-
Meilisearch
- 日本語検索に対応している
- Rust で書かれており性能がでそう
- Rust であれば問題が起きた際、会社でなんとかできる
-
meilisearch/docs-scraper: Scrape documentation into Meilisearch
- config.json を用意して実行するだけなので、簡単に利用できる
- HTML 解析して Meilisearch に突っ込んでくれるツール
- Python であれば問題が起きた際、会社でなんとかできる
-
meilisearch/docs-searchbar.js: Front-end search bar for documentation with Meilisearch
- 簡単に導入できるため Sphinx 拡張として追加が簡単そう
構築、検証からプロダクション利用までの距離が短いと感じた。
運用
自社運用時のメモ
- Sphinx で生成した HTML は Cloudflare Pages へデプロイしている
- Meilisearch クラウドサービスはプライベートベータ中だが日本リージョンがないため不採用
- インクリメントサーチがしたいので距離は大事
- インデックス作成は 1 ドキュメント 3-4 万程度
- 2 コアあれば充分対応できそう
- CPU バウンドなので Linode の 専用 CPU インスタンス 2C/4G の $ 30 月を採用
- オンラインドキュメント向けなのでインデックスは消えてもいいし張り直せばいい
- 手動でスクレイピングできるようにする
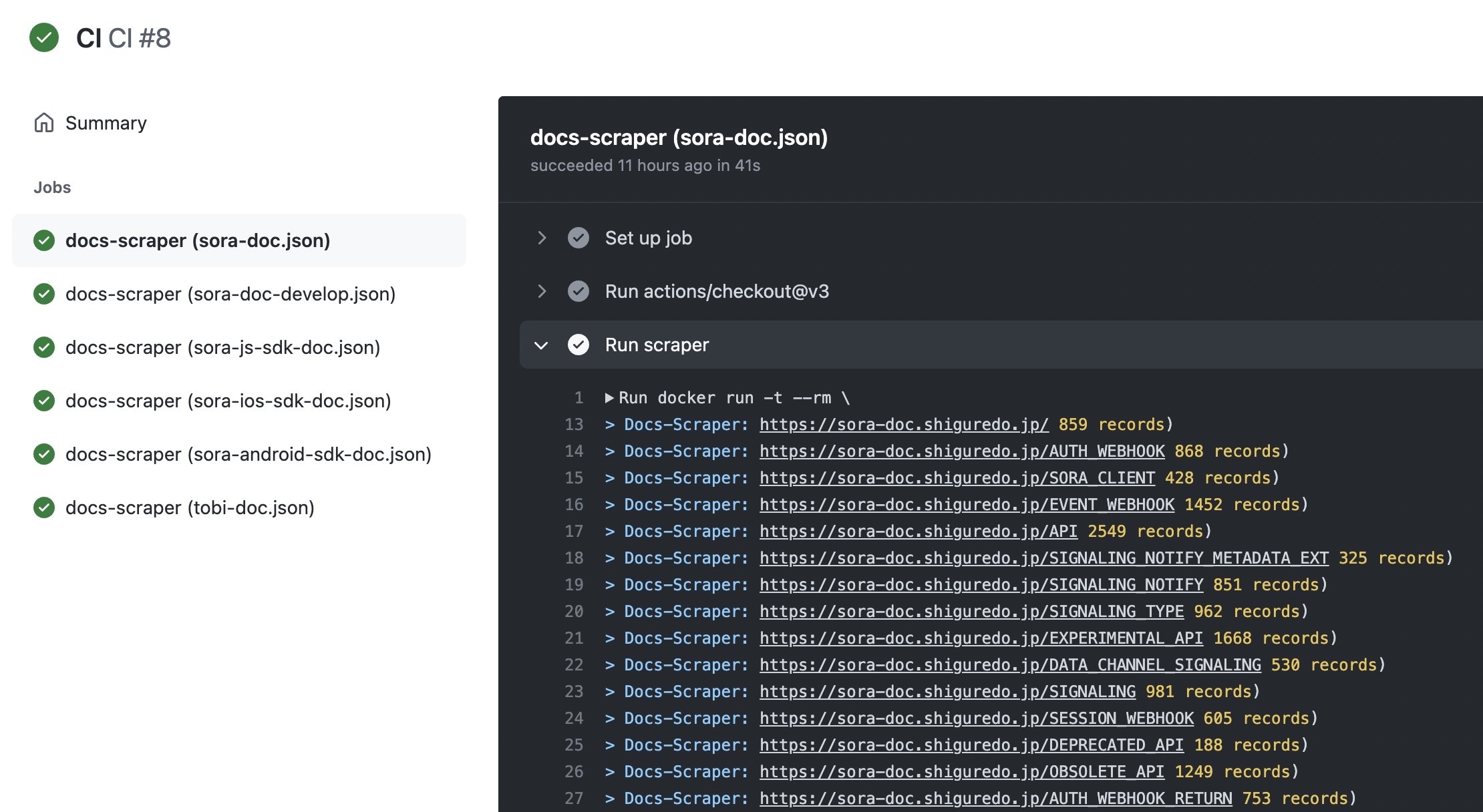
- docs-scraper は GitHub Actions で動作させる
- self-hosted を利用して Meilisearch との距離を近くする
- バッチで誰もドキュメントを使わない深夜に走らせる
- 監視は OpenMetrics (Prometheus) にはまだ非対応なのでこちらでいろいろ頑張る必要あり
- MasterKey から API Key を生成して利用、search 向けにすべてのドキュメント共通で利用する
- デフォルトでフロントエンド用と管理用の API Key が用意されてるのでそれを使うと良い
- Nginx を前段におく
- HTTP/2 を有効にしておく
- ついでに Cloudflare DNS Proxy も有効にしておく
- Cloudflare DNS Proxy -> Nginx (HTTP/2) -> Meilisearch という構成
- 監視は Tailscale 経由で VictoriaMetrics + Node exporter + Blackbox exporter
結果
docs-searchbar.js の最小限 HTML で動かしている。

- Sphinx で生成した HTML を解析し、日本語対応の全文検索を実現できた
- Sphinx 拡張への組み込み以外はコード書いてない
- docs-scraper の config.json を設定しただけ
Sphinx テーマへの組み込み
自社で開発している Sphinx テーマに上記の検索バーを追加してみた。
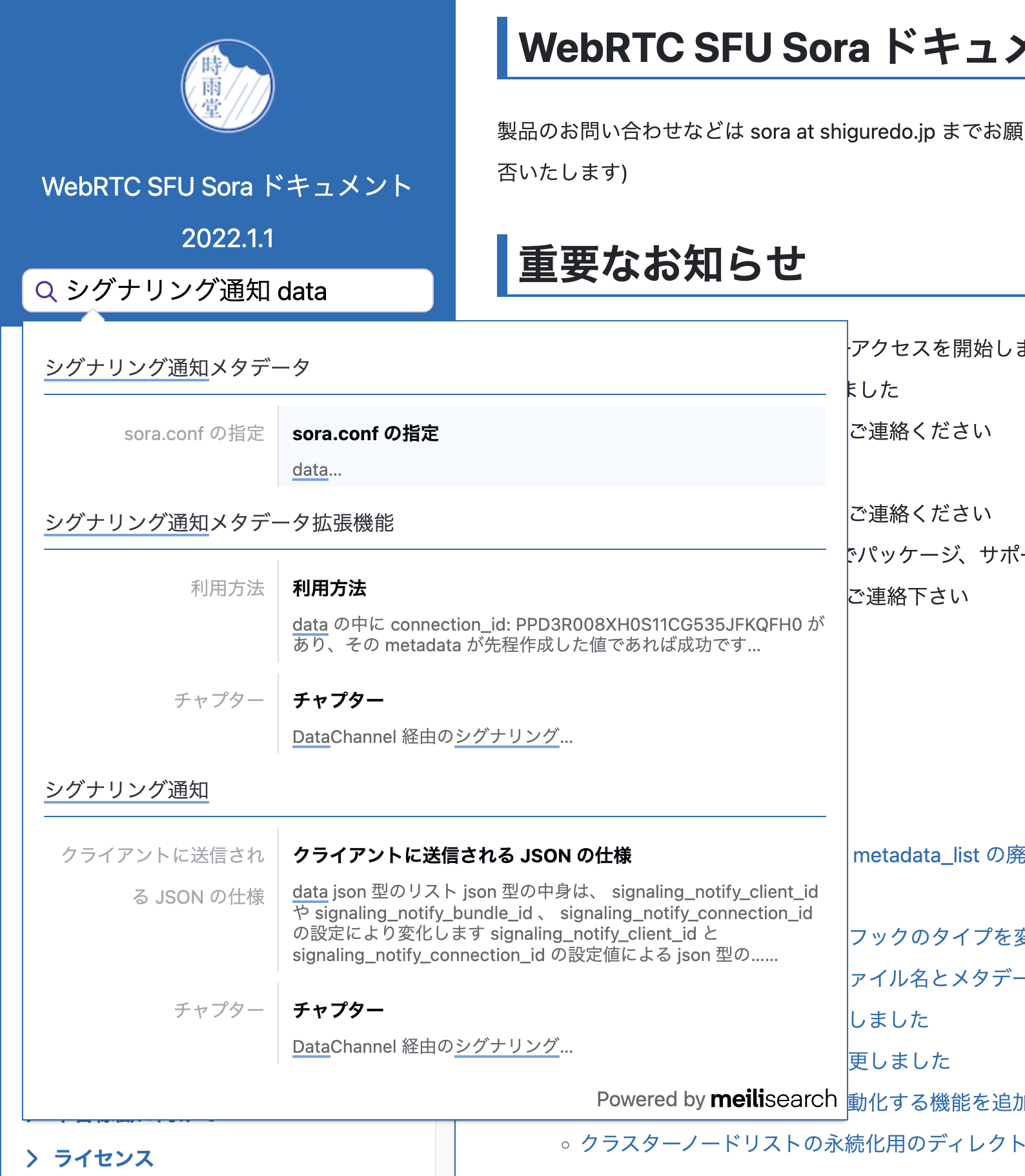
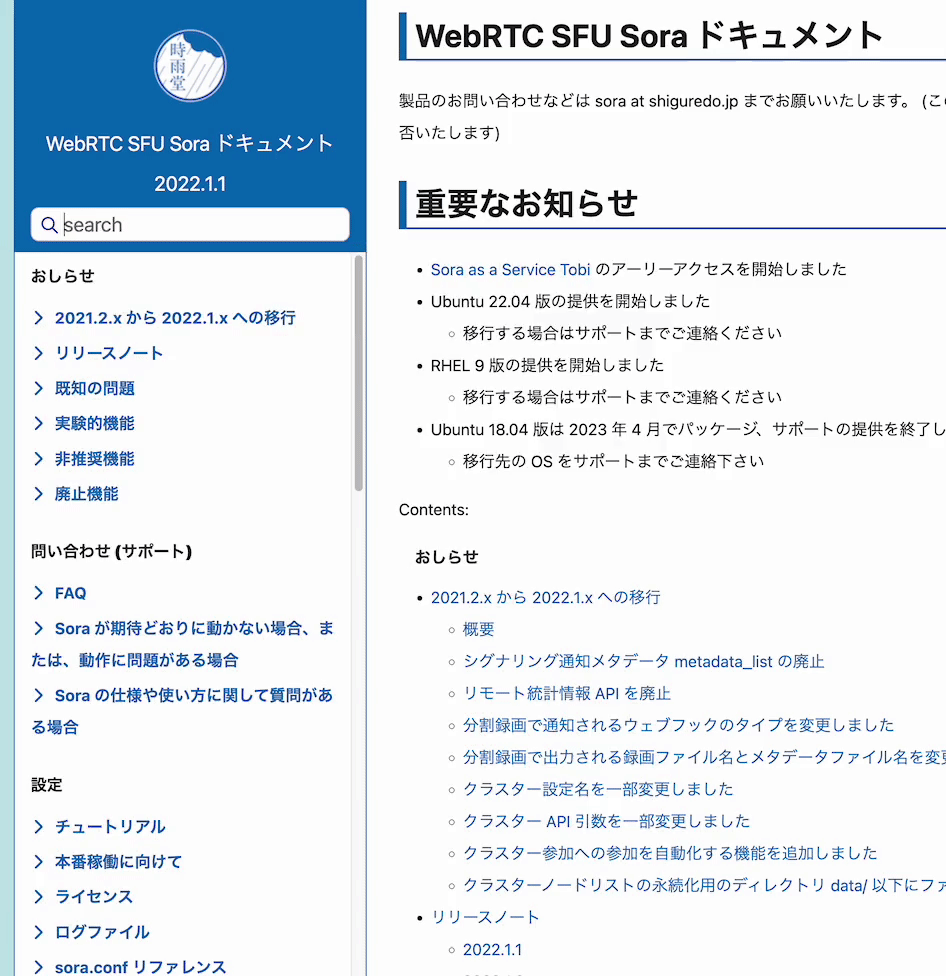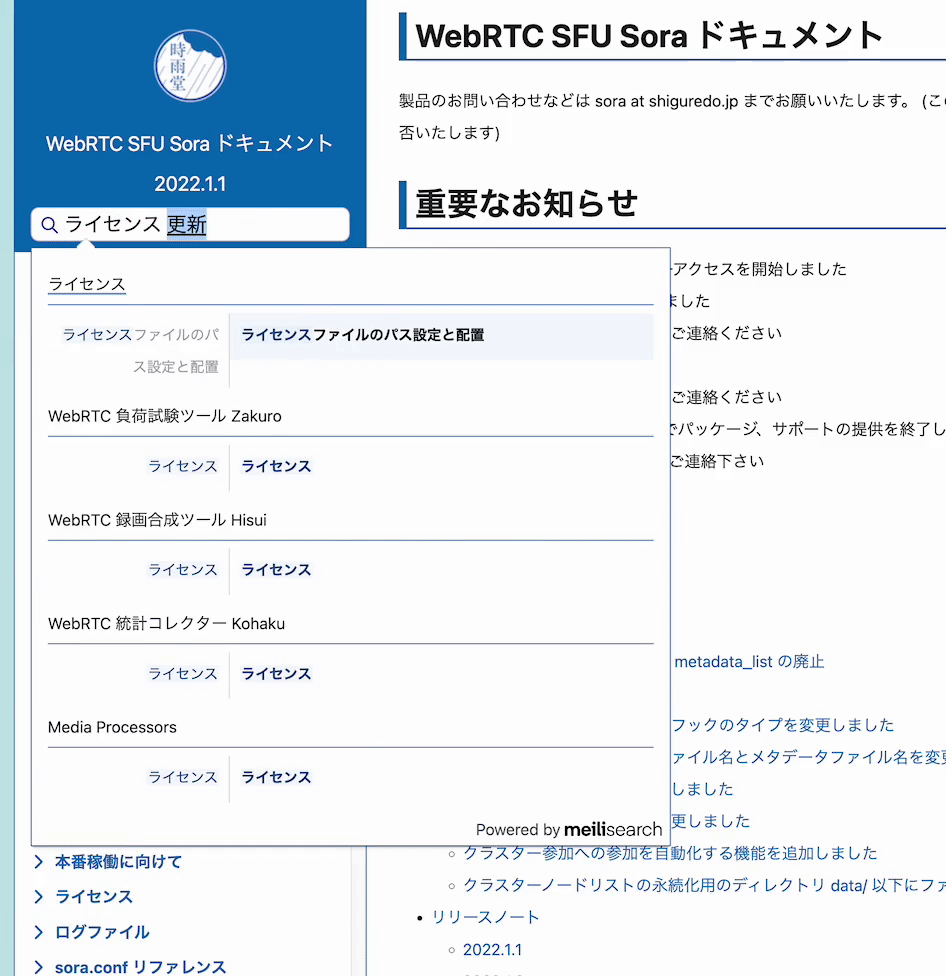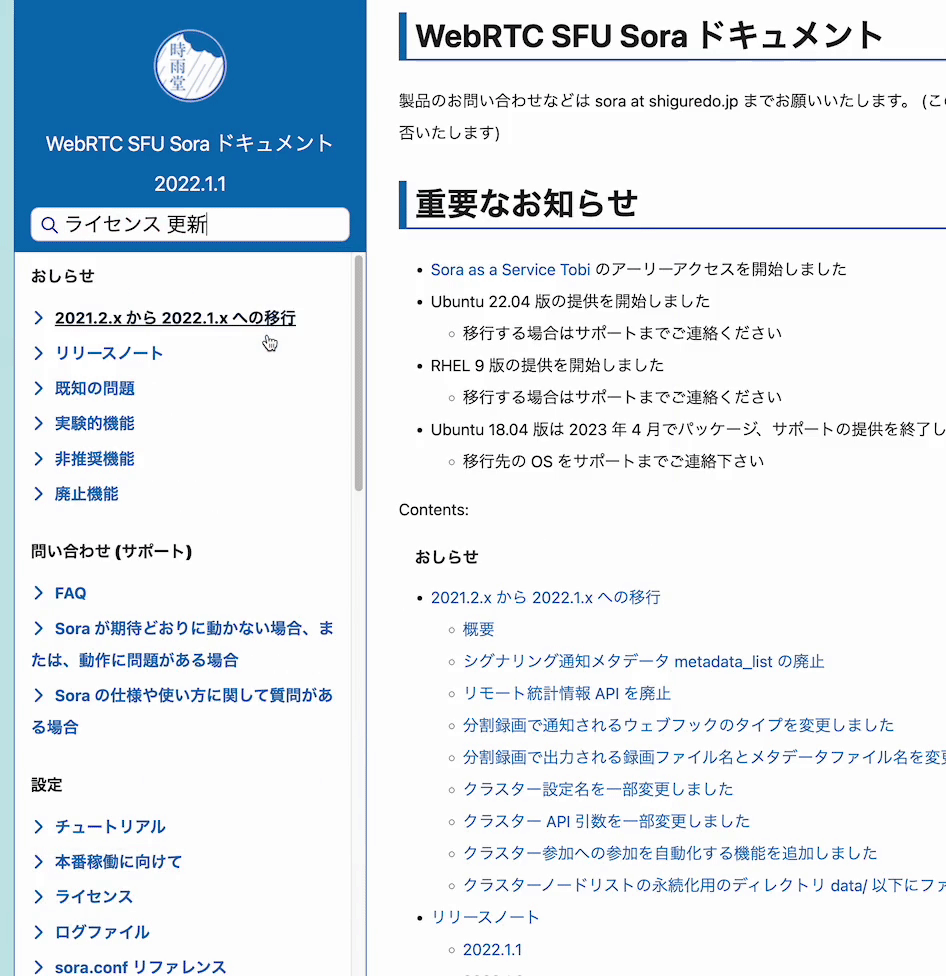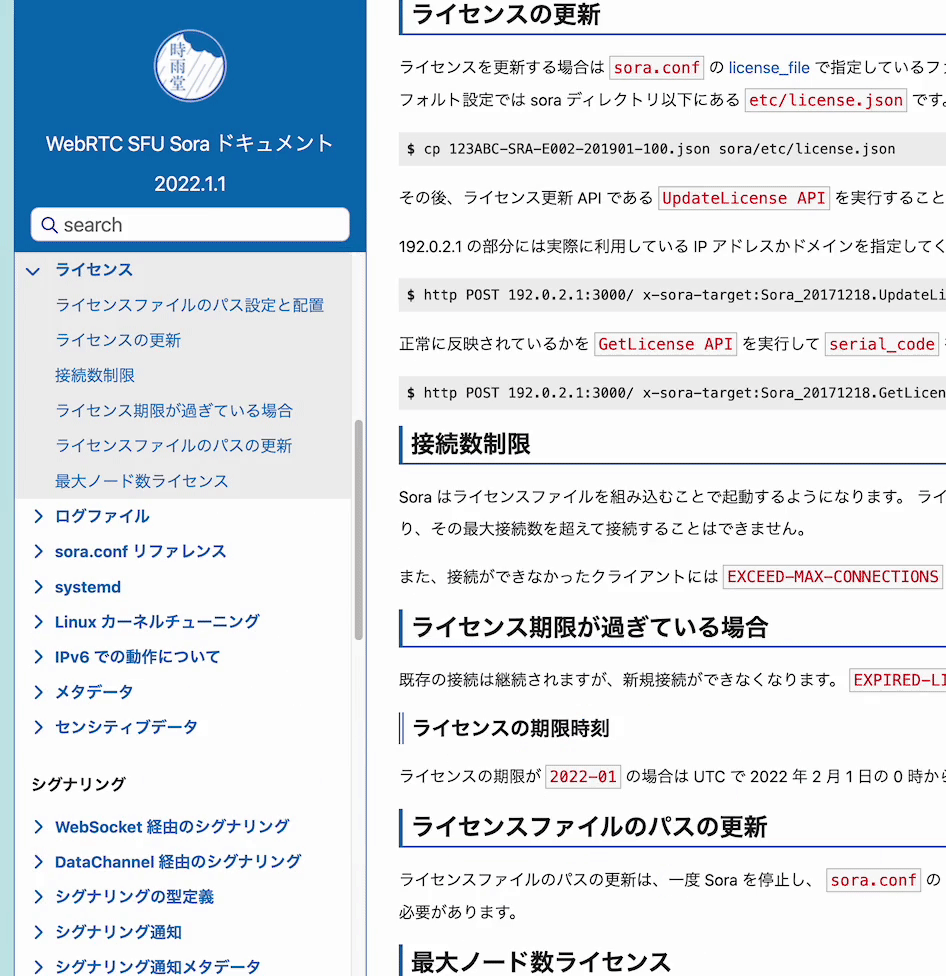
組み込み済みテーマ
shiguredo/sphinx_shiguredo_theme: 時雨堂 Sphinx テーマ
conf.py に Meilisearch の設定を追加するだけで利用可能。
html_theme_options = {
'meilisearch': True,
'meilisearch_api_key': 'xxx',
'meilisearch_host_url': 'https://meilisearch.example.com/',
'meilisearch_index_uid': 'doc'
}
Sphinx + Meilisearch over HTTP/3
GitHub Actions を利用して docs-scraper を動かす
-
Self-hosted runners を利用する
- Meilisearch と同居しているので 127.0.0.1:7700 でいける
- 深夜は検索されないので深夜にインデックスを更新する仕組みを追加
- 丑三つ時に動かす
- 手動でもインデックス更新を可能にする
- matrix を利用して複数ドキュメントに対応する
- docker を利用してるので楽すぎる
docs-scraper.yaml
on:
push:
paths-ignore:
- '**.md'
branches: [ "main" ]
pull_request:
branches: [ "main" ]
workflow_dispatch:
schedule:
# JST は 2:00 は UTC の 17:00
# 1-5 で 月曜日から金曜日
- cron: '0 17 * * 1-5'
jobs:
docs-scraper:
runs-on: [self-hosted, linux, x64]
strategy:
max-parallel: 1
matrix:
config: [sample1.json, sample2.json]
steps:
- uses: actions/checkout@v3
- name: Run scraper
env:
HOST_URL: ${{ secrets.MEILISEARCH_HOST_URL }}
API_KEY: ${{ secrets.MEILISEARCH_API_KEY }}
CONFIG_FILE_PATH: ${{ github.workspace }}/${{ matrix.config }}
run: |
docker run -t --rm \
--network host \
-e MEILISEARCH_HOST_URL=$HOST_URL \
-e MEILISEARCH_API_KEY=$API_KEY \
-v $CONFIG_FILE_PATH:/docs-scraper/config.json \
getmeili/docs-scraper:latest pipenv run ./docs_scraper config.json
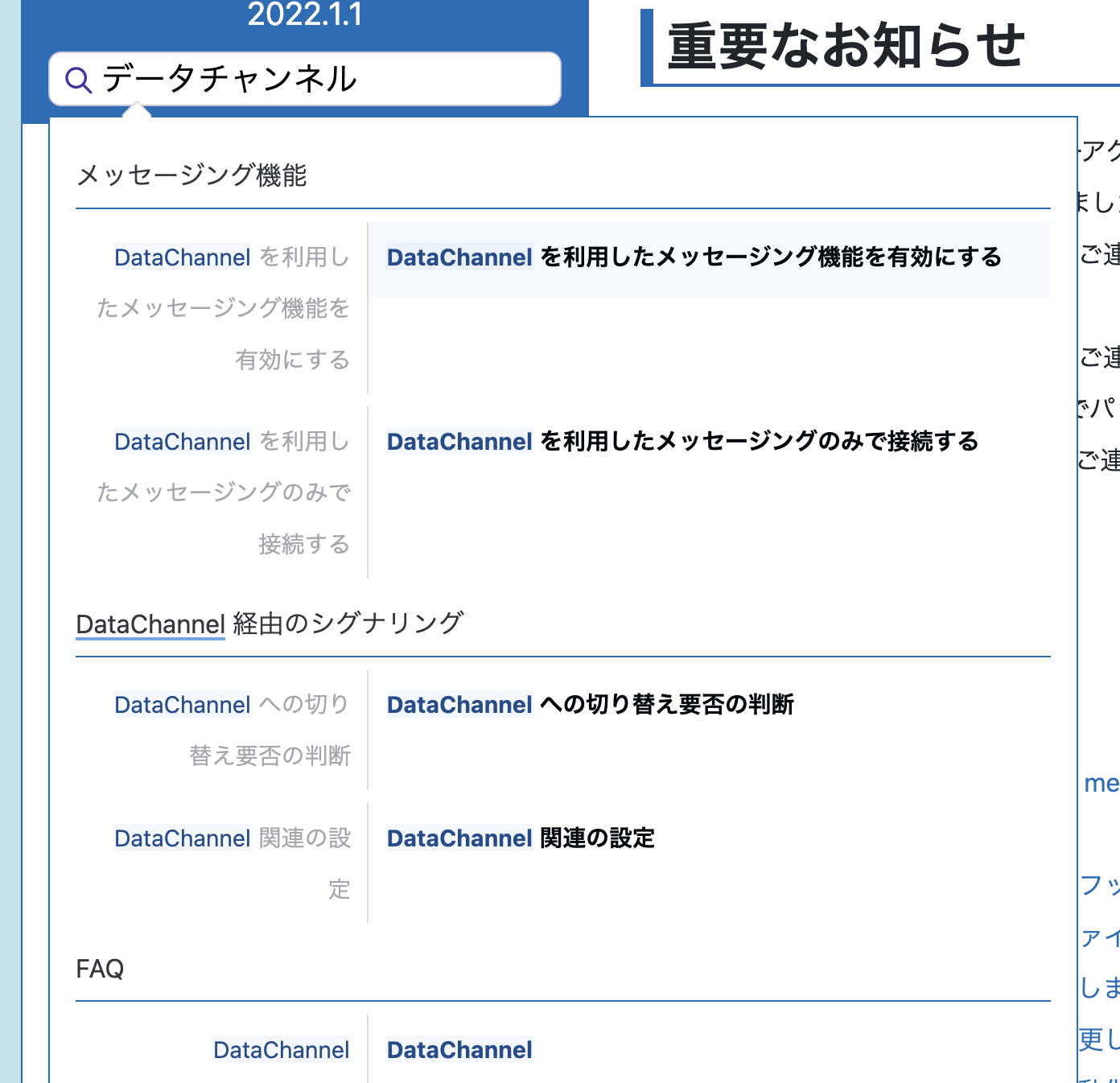
同意語に対応する
Synonyms については REST API を叩くだけで良い。
curl \
-X PUT 'http://localhost:7700/indexes/movies/settings/synonyms' \
-H 'Content-Type: application/json' \
--data-binary '{
"データチャネル": [
"datachannel"
],
"データチャンネル": [
"datachannel"
]
}'
Normalization ではなく One-way association が使いたかったので、サクッと登録。
{
"データチャネル": [
"datachannel"
],
"データチャンネル": [
"datachannel"
]
}
こんな感じの JSON ファイルを用意してあとは curl で叩いて登録する仕組みを GitHub Actions 経由で用意。JSON ファイルが更新されたら反映する仕組みを追加した。
このスクラップは2023/09/10にクローズされました