DeepFillV2 (Inpaint) をONNX化して、量子化する





概要
過去にSI業務にてふと消しゴムマジック的なものに関する要望をいただき、調査した内容
結局、話は流れたが、その際、業務外で調べた、ONNX化や量子化周りの話が面白かったので、整理する
(消しゴムマジック的なアプリは個人的に作成して、今年のどこかで公開したい)
選定
-
DeepFillv2
論文の著者のgithubリポジトリは https://github.com/JiahuiYu/generative_inpainting となる
但し、tensorflow実装となっており、contextual attentionに用いる、tf.extract_image_patchesがONNX化に対応していなかった (pytorch版も同様)
苦戦した結果として、extract_image_patchesを愚直に実装している以下リポジトリに辿り着いた
MITライセンスであったため、非商用目的としてforkし、onnx化可能となるよう編集し、今回公開した
尚、モデル学習は今回行わず、上記参考リポジトリ内URLにて共有される、checkpointから借用している
(今後、fine-tuning等、行っていきたい)
結論
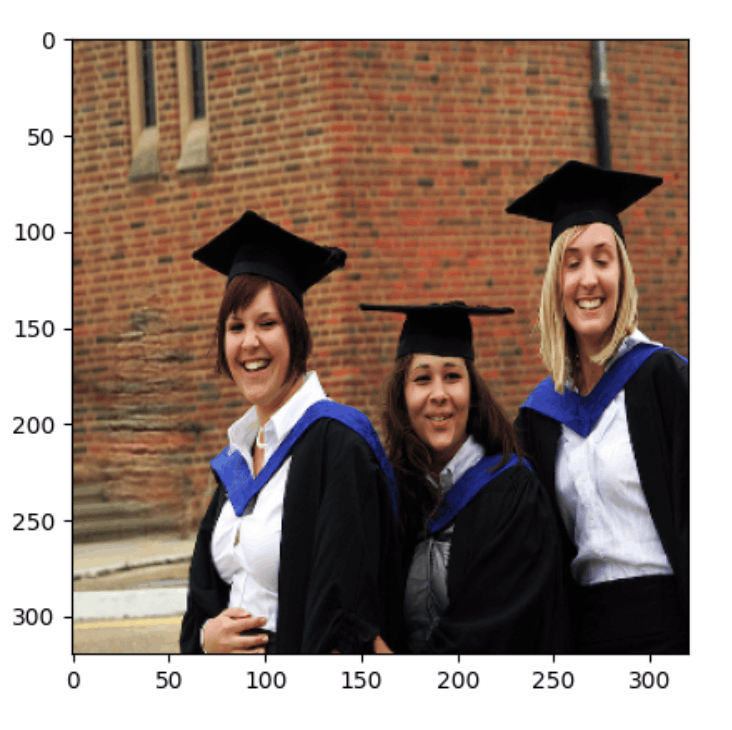
onnx生成 (73MB) -> simplify (65MB) -> Uint8量子化 (17MB)まで成功し
最終モデルは、Inpaintとしての出力を得た
| 元画像 | mask | 出力画像 |
|---|---|---|
 |
 |
 |
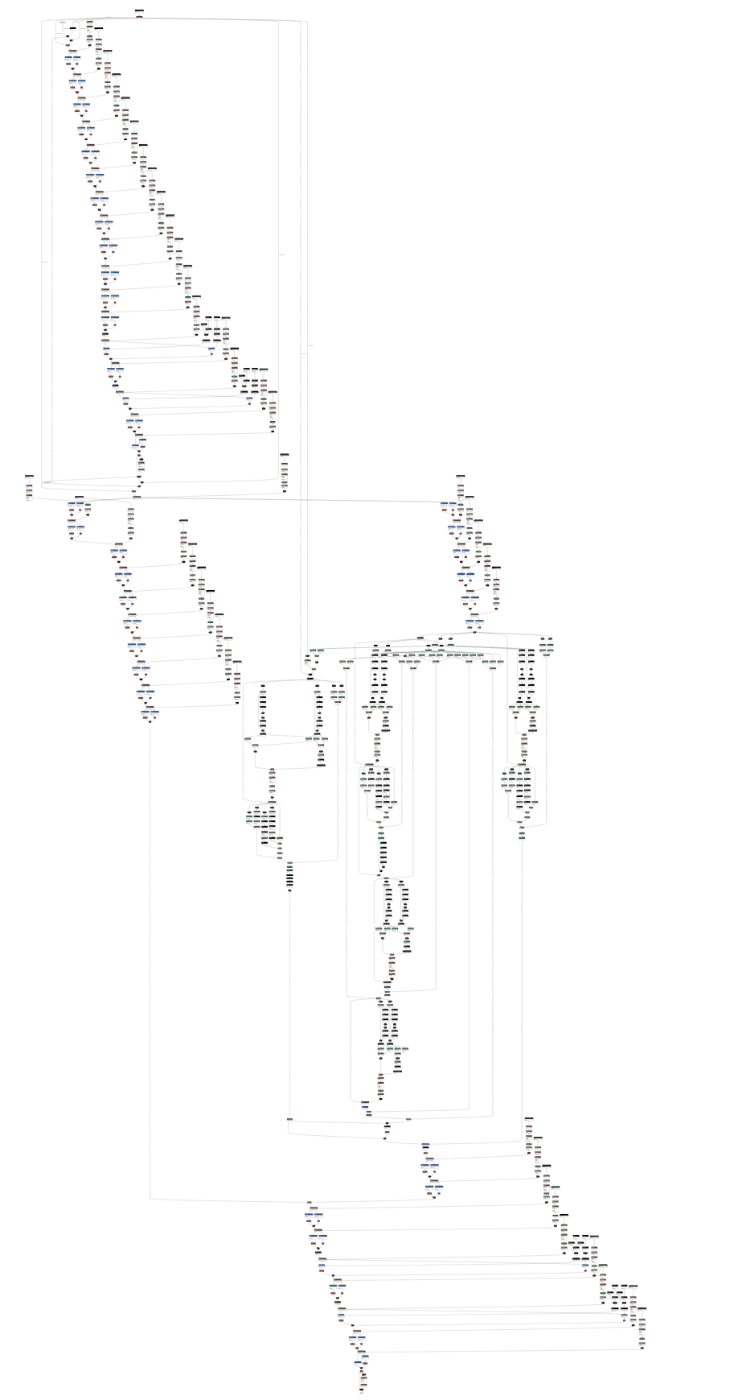
Netronにて、モデル構成を出力した結果が以下で、軽量化の変遷が伺えると思う
| onnx | onnx (simplified) | onnx (uint8) |
|---|---|---|
 |
 |
 |
内容
タスクとしては、いわゆるInpaintタスクとなる
「大きな欠陥領域(白抜き)を持つ画像を、もっともらしい合成画像で欠陥領域を埋めてあたかも欠陥がない画像にする」 参照
手順としては
- pretrained_modelからmodel.loadし、torch.onnx.exportする
- (1)のonnxファイルをonnxsimにて、simplifyする
- (2)のonnxファイルをuint8量子化する
- 動作確認
1. pretrained_modelからmodel.loadし、torch.onnx.exportする
少しだけ、OSS側を修正した
# width = w.view(height, -1).data.shape[1]
width = w.view(height, int(w.numel() // height)).data.shape[1]
# raw_w = raw_w.view(raw_int_bs[0], raw_int_bs[1], kernel, kernel, -1)
_ind = int(raw_w.numel() // (raw_int_bs[0] * raw_int_bs[1] * kernel * kernel))
raw_w = raw_w.view(raw_int_bs[0], raw_int_bs[1], kernel, kernel, _ind)
一部、viewにてreshape処理を行っている箇所にて
公式docにも、the size -1 is inferred from other dimensionsと記載がある通り、よしなに推測して指定されるのかと思いきや、実行時エラーが発生した為
numel (= total number of elements)を利用し、計算して指定する必要があった
後は、OSS側の実装依存によりcpu演算が指定できていなかった為
今回の目的はonnx exportであることから、cpu演算の指定を直接行うよう軽い調整を行っている
他のDeepFillv2関連のgithub repositoryを調査・検証していた際に課題となっていたextract_image_patchesに関しては、問題なくonnx exportされた
generator = utils.create_generator(opt).eval()
# pretrained_modelは参考repository内URLからダウンロードする
model_name = "./(input path)/deepfillv2_WGAN_G_epoch40_batchsize4.pth"
...
pretrained_dict = torch.load(model_name, map_location=device)
generator.load_state_dict(pretrained_dict)
model = generator
torch.onnx.export(model, (dummy_image, dummy_mask), f="./(output path).onnx")
上記手順にて、最初のonnxファイルが生成される
2. (1)のonnxファイルをonnxsimにて、simplifyする
onnx-simplifier (onnxsim)を用いて、モデル構造を機械的に最適化する
from onnxsim import simplify
model = onnx.load(os.path.join(os.path.dirname(__file__), "../../artifact/deepfillv2_mod.onnx"))
model_simp, check = simplify(model)
...
onnx.save(model_simp, output_path)
上記手順にて、simplifyされたonnxファイルが生成される
3. (2)のonnxファイルをuint8量子化する
onnxruntime.quantizationのquantize_dynamicにて量子化する
QInt8でなく、QUint8を指定する必要がある点に注意する
from onnxruntime.quantization import quantize_dynamic, QuantType
...
quantized_model = quantize_dynamic(src_model_path, dst_model_path, weight_type=QuantType.QUInt8)
上記手順にて、Uint8量子化されたモデルが生成される
4. 動作確認
結果として、3段階の過程を得て、onnxファイルの容量は73MB => 65MB => 17MBまで軽量化された
17MB程度であれば、私の体感としては、m1 mac等であれば、8GBメモリ程度でも、wasm, SIMDを上手く利用すれば、なんとかweb上でも動作可能レベル。という認識である

実際に量子化済みのモデルにて、画像の欠陥補完ができているのか、確認した
| 元画像 | mask | 出力画像 |
|---|---|---|
|
|
|
軽量化により、精度には懸念があるが・・補完としては機能し始めている
以降、調整していきたい
締め
LLM全盛の現在としては、隔世の感もあるが
軽量モデルの分野も、汎用性は無いが個別最適なソリューションとして地道に発展していくとは思う
分野としては、個人的に好きなので、ひっそりと趣味で調査していきたい
(以上)
Discussion