Owl/Crow:ModernBERTをゼロから学習したコード検索特化モデル
※追記(2025/11/19)
- 記事タイトルをより内容に即したものへ変更しました
- トークナイザの構築に関するセクションを新たに追加しました
- 言い回しを少し修正しました
はじめまして。
私は大学で コード特化言語モデルを利用したコード検索の研究を行っています。
概要
本記事では、従来の CodeBERT / GraphCodeBERT 系モデルでは扱いづらかった
- 最大 512 トークンという入力長の制約
- FlashAttention 非対応による学習・推論コストの高さ
- 事前学習・追加学習の再現性の低さ
といった課題を踏まえつつ、ModernBERT アーキテクチャを用いてスクラッチ学習(ゼロから学習)からコード検索向けの埋め込みモデルを自作・公開するまでをまとめました。
具体的には、以下の点を中心に紹介します。
- 既存のコード特化言語モデル(CodeBERT / GraphCodeBERT 等)の制約
- GitHub 由来のコード・関数を用いたデータセットの準備と前処理フロー
- ModernBERT をベースとしたコード検索用埋め込みモデルの学習方法
- 実際に構築した
- 実験を通じて得られた、コード検索モデルを作るうえでの実践的な知見
コード検索モデルを自前で構築してみたい方や、似たような研究をされている方の参考になれば幸いです。
動機(少し長いので読まなくても大丈夫です)
近年、LLM の進化によりコード生成モデルは目覚ましい発展を遂げています。しかしその一方で、埋め込みベクトルを用いたコード検索といった領域では、依然として CodeBERT や GraphCodeBERT といった やや古いモデルが研究の標準として使われ続けています。
埋め込みベクトルを用いたコード検索モデル自体は少しずつ増えてきているように見えますが、事前学習に使われたデータセットが公開されていなかったり、既存モデルに対してファインチューニングする形で新しいモデルが構築されているケースも多く見られます。その結果として、
- どのようなデータセットを使ったことで性能が向上したのか
- それとも、元々の事前学習が強力だったのか
といった点が 必ずしも明確ではない 場面もあると感じています。
もちろん、GraphCodeBERT のように追加の事前学習によって性能が向上した例もありますが、論文通りの手法で再現しようとすると非常に手間がかかることが多く、実際の再学習はかなり厄介です。また、CodeBERT / GraphCodeBERT は RoBERTa アーキテクチャを基盤としているため、
- 最大入力長が 512 トークンまで
- FlashAttention 非対応
- 学習時・推論時のメモリ使用量が大きい
- CodeBERT-baseの挙動が安定しないケースがある
といった課題もあり、追加の事前学習やファインチューニングを行うには 実行速度や GPU メモリ面で困難が多い のが現状です。
一方で、近年の LLM の発展に伴い、アーキテクチャや活性化関数などの改善、データセットの拡充も進んでおり、今の時代なら、より扱いやすく高性能なコード特化言語モデルを自作できる環境が整いつつあるとも感じています。
そこで私は、その第一歩として ModernBERT ベースのコード検索モデルを作成し、実際に公開してみました。
この記事では、これらのモデルの開発にあたって私が行った
- データセットの準備と前処理
- ModernBERT の訓練方法
- コード検索用の埋め込み学習
- 実験で得られた知見
などについて、可能な限り詳しく解説していきます。
データセットの構築と比較
まずは、今回のモデルの事前学習に用いたデータセットの作成方法について紹介します。
コード検索モデルの事前学習において代表的なのが CodeSearchNet です。
CodeBERT や GraphCodeBERT など、多くのコード特化モデルがこのデータセットを使って学習されています。
CodeSearchNet は以下の 2 種類のデータを含みます。
-
バイモーダルデータ:
関数レベルのコードと、それを説明するコメント(Python の Docstring や Java の JavaDoc など)のペア
→ 約 210 万件 -
ユニモーダルデータ:
関数レベルのコードのみ(テキスト説明なし)
→ しかし 公開場所が不明瞭(私の調査不足の可能性もあります)
バイモーダルデータの約 210 万件だけでは 近年の LLM 事情を考えると規模が十分とは言いづらく、またユニモーダルデータの公式公開情報が見つからないため、今回は 独自にデータセットを構築し、そのデータを用いて事前学習から行うことにしました。
データ抽出の方法
基本的には CodeSearchNet と同様のアプローチを取り、
- Tree-sitter を用いた言語ごとの関数抽出
- 関数内部の docstring / コメントを正規表現や AST ベースで抽出
- 言語ごとに専用パーサを実装し精度を調整
といった手順でデータを作成しています。
対象となる GitHub リポジトリ
抽出元のリポジトリは、以下の基準で選定しています。
- スター数が多い(一定以上の品質を期待できる)
- 再頒布の条件が緩い OSS ライセンスである
使用したライセンスは以下の通りです。
MITApache-2.0BSD-2-ClauseBSD-3-ClauseUnlicenseCC0-1.0ISC
このようにして、CodeSearchNet の構造を参考にしつつ、規模・言語多様性・コード長などをより現代的に拡張した独自データセットを構築しました。
また、関数の説明になっていないコメント(例:ファイル全体のライセンス表記、無関係なメタ情報など)や、極端に短すぎる関数(例:return None だけ、数行しかないテンプレート関数など)も除外しています。
これは、検索モデルの学習において コードと説明文の対応が薄いデータはむしろノイズになる ためです。
こうしたフィルタリングを行った結果、
- 収集した関数+説明コメントのペア:約 990 万件
- 実際に学習に使ったデータ:約 850 万件
となりました。
(Owl 系モデルでは、この 850 万件を中心に学習を行っています。)
850 万件は「コード特化モデル」として十分か?
このデータセットは、規模としてはかなり大きく見えます。しかし近年の LLM 事情を考えると、
- 850 万件は ファインチューニング用 としては十分
- 一方で、事前学習コーパスとしては比較的小規模
といった形です。
一方で、CodeBERT の学習データ構成と比較すると興味深い点があります。
CodeBERT は CodeSearchNet の バイモーダル(関数+docstring) と ユニモーダル(関数のみ) の両方を学習していますが、総量としてはこちらのデータセットとほぼ同じです。
さらに、こちらのデータセットは バイモーダルの対データのみに絞って構成されているため、
検索モデルに必要な「コードと説明の対応関係」を学習しやすい という利点があります。
そのため、量では CodeBERTと同程度であっても、より検索モデルを構築するのに適したデータセットとなっていると考えています。
こうした背景から、このデータセットのみで構築するモデル(Owl)とは別により広範な知識(ファイル単位で学習した知識)を持ったモデル(Crow)も構築したいと考えました。
StarCoder 系データ(BigCode)によるスケール拡張
そこで、StarCoder プロジェクトで公開されている大規模コードデータセットを活用することにしました。
これらは GitHub 上の大規模コードをライセンス準拠で収集したデータセットで、ファイル単位のデータセットになっています。とにかく量が大きく(数百GBレベルであり、かなり容量が圧迫される)、パラメータが150M程度のモデルの学習には十分な量だと思い採用しました。(Crowのモデルではこのデータセットで事前学習を行ったのち、先ほど抽出したデータセットを用いて学習を行うことで、モデルをコード検索に向けて特化していっています。)
ModernBERTアーキテクチャの採用理由
ModernBERT では、近年の LLM に対する技術的な改善が取り入れられている点がとても良いと感じています。
特に、最大入力長を 8192 トークンまで拡張できる RoPE、Flash-Attention への対応、GeGLU の採用、さらに Sliding Window Attention を用いた Global Attention と Local Attention の使い分けによるアテンション計算の最適化が挙げられます。
これらの改良によって、
- より長い関数や、CodeBERT が登場した当時には(あまり)行われていなかった ファイルレベルのプログラムによる事前学習
- コンシューマー向け PC での事前学習
が可能になるのではないかと考え、ModernBERT を採用しました。
特に後者は個人的に大きなポイントで、現代の LLM を事前学習から行うのは依然として難しいものの、数百M規模のパラメータであれば十分学習可能なのではないかと考えています。
とはいえ、本格的に行おうとするとやはり難しく、今回の Crow の事前学習においても、
- 入力長を 1024 トークンに制限
- 対応言語を
Python, JavaScript, TypeScript, Java, Go, Rust, PHP, Ruby, C++, C, SQL
のみに限定 - モデルパラメータを ModernBERT-base から やや軽めの構成(具体的にはModernBERT-baseの構成からBERT-baseと同じパラメータ)に調整
といった工夫を行ったものの、実行時間や容量の観点ではかなりギリギリの印象でした。
トークナイザの構築
トークナイザについても、ModernBERT や CodeBERT に付属している既存のものは使用せず、
今回抽出したデータセットをもとに 各言語から 50 万件ずつサンプリングして50000トークン前後になるよう(別の学習も試す予定があるためいろいろ特殊トークンを追加したりしていますが今回は未使用です)新しく学習しました。
これにより、今回のデータ(関数コード+説明コメント)により適合した
コード特化型トークナイザを作ることができます。
ただし正直なところ、この最適化がどの程度モデル性能に寄与しているのかは、
現時点では明確には言えません。
採用した方式は Byte-level BPE です。
この方式では、
- 空白や改行
- 語彙に存在しない文字(たとえば日本語など)
といったトークンも、複数トークンに分割されることで入力自体は可能です。
ただし今回のデータセット構築時には、
ASCII 以外の文字列を含む関数・コメントはフィルタリングで除外している ため、
実際には日本語などが含まれるケースはほとんどありません。
そのため、Byte-level BPE によって入力可能にはしているものの、
あくまで「入力が可能」なだけで、学習データとしてはほぼ ASCII のみで構成されています。
事前学習について
モデルは既存の ModernBERT-base の重みを流用せず、完全にランダム初期化された状態から学習を開始しました。
その際、コードに適応させるために、2 段階の事前学習を行いました。
また、事前学習時の入力形式としては、
「説明コメント(docstring)+関数コード」 をひとつの入力として結合して学習させています。
- 段階1: ランダムマスキングによる Masked Language Modeling
- 段階2: 行ごとのマスキングによる Span 型の Masked Language Modeling
どちらも「マスクされたトークンを予測する」という点では共通していますが、
段階2では 「行単位で情報を落とす」ことで、より強く文脈を考慮させる ことを狙っています。
段階1: ランダムマスキング
まずは Transformer ベースの事前学習として標準的な
Masked Language Modeling (MLM) を採用しました。
- 入力として説明コメント(docstring)+関数コードを与える
- その中の ランダムな 30% のトークンをマスク
- マスクされたトークンを予測するように学習
という、いわゆる BERT 系の基本的な MLM 設定です。
この段階の目的は、
- キーワード
- 演算子
- 識別子
- 制御構文
など、コードを構成するトークン同士のローカルな関係性を学習させることです。
段階2: 行ごとのマスキング
次に段階1と同じデータを、段階1のモデルが終わったに対して 「行ごとのマスキング」 による事前学習を継続しました。
直感的には、
「コードは行単位で意味を持つことが多いので、行まるごとを隠してそれを復元させるタスクにすると、
ただのランダムマスクよりも構造を意識した学習ができるのでは?」
という発想です。
段階1・段階2の事前学習が性能に与える影響
ここでは、前節で説明した「段階1(ランダムMLM)→段階2(行単位のマスキングMLM)」という二段階の事前学習が、実際のコード検索性能にどの程度寄与したのかを示します。
具体的には、Roberta(=CodeBERT に近いアーキテクチャ)と ModernBERT の両方について、同じ独自データセットを用いて事前学習を行い、その後 CodeSearchNet を用いてファインチューニングしたときのCodeSearchNetRetrievalのMRRによる性能差を比較しました。
直感的には、
「Roberta と ModernBERT を同一条件で事前学習したとき、段階1 と段階2でどれくらい性能差が出るか?」
を検証した形になります。
評価方法のMRRのイメージ図です。

性能比較(段階1 → 段階2 の改善量)
| Backbone | Max Token | 段階1 平均 | 段階2 平均 | 改善幅 |
|---|---|---|---|---|
| Roberta | 512 | 0.786 | 0.807 | +0.021 |
| ModernBERT | 512 | 0.805 | 0.827 | +0.022 |
| ModernBERT | 2048 | 0.803 | 0.825 | +0.022 |
※平均は(Python, Java, JavaScript, PHP, Ruby, Go)の6言語
-
Roberta / ModernBERT のどちらでも、段階2が段階1を上回る
- Roberta: +0.021
- ModernBERT (512): +0.022
- ModernBERT (2048): +0.022
→ アーキテクチャに関わらず、行単位のマスキング(段階2)による影響と考えられる。
-
ModernBERT は元の性能(段階1)も高く、さらに改善幅も安定している
→ ModernBERTの性能が高い要因は長い入力長によるものではなく、モデル構造や活性化関数によるものが大きいと考えられる。
この結果を言い換えると、段階2(行単位マスキング)による改善幅は、
アーキテクチャを Roberta → ModernBERT に変えたときの改善幅に匹敵するほど大きいとも言えます。
コード検索タスクにおけるファインチューニング手法
ファインチューニングには Multiple Negatives Ranking Loss(MNRL) を用いた対照学習を採用しました。
MNRL を選んだ理由は大きく次の 3 点です。
-
関数コードと説明コメントの“正解ペア”が明確に存在するため
- 今回のデータセットは「関数コード」と「その関数を説明するコメント」のペアで構成されている
-
大規模データに対してラベル付けやハードネガティブ選別が困難
- 今回のファインチューニングには数百万規模のデータを使用しています。
- 1つ1つにラベルを付けたり、手作業でハードネガティブを選ぶのは現実的ではありません。
- MNRL は バッチ内の他サンプルを “自動でネガティブ” に扱えるため、大規模学習と非常に相性が良いです。
-
“正解が1つではない”タイプの検索タスクとも相性が良い
- コード検索では、説明文 A に対してコード B が正解でも、
説明文 C も“概ね正しい”とみなせる場合があります。 - MNRL は 絶対的な 0/1 の分類ではなく、ランキング最適化のため、
このような曖昧性のあるデータにも適応しやすいという利点があります。
- コード検索では、説明文 A に対してコード B が正解でも、
他の手法との比較
実際には、以下のような 「正例=1・負例=0」 という
単純なバイナリ分類型の学習(ランダムネガティブを使った方式)も試しました。
- Positive: (関数コード, 正しいコメント)
- Negative: (関数コード, ランダムに抽出したコメント)
しかし、下図が示す通り、CodeBERT / ModernBERT-base のどちらのアーキテクチャでも、
バイナリ分類より MNRL のほうが明確に性能が高い という結果になりました。
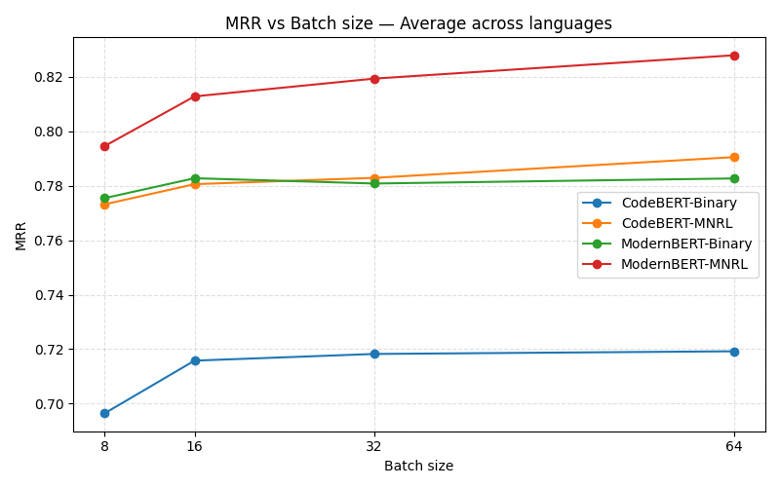
図からわかるように:
CodeBERT でも ModernBERT でも、MNRL のほうが検索精度が高い という傾向が得られました。
またMNRLではバッチサイズが大きくなるとモデルの性能が少しずつ良くなっている傾向もみられました。
このような理由から、コード検索のファインチューニング手法として Multiple Negatives Ranking Loss を採用しています。
性能評価
最後に、CodeSearchNetRetrieval を用いた評価結果を示します。
ここでは比較用として、CodeBERT-base と、本記事で紹介した
ModernBERT ベースのモデル(Owl-ph1 / Owl-ph2) をそれぞれ
CodeSearchNet から各言語 1 万件ずつ抽出し、同一条件でファインチューニングした結果をまとめています。
- Owl-ph1 … 段階1(ランダムMLM)まで事前学習したモデル
- Owl-ph2 … 段階2(行単位MLM)まで事前学習したモデル
評価指標は CodeSearchNetRetrieval の MRR(Mean Reciprocal Rank) です。
| 事前学習済みモデル | Go | Java | Python | PHP | JavaScript | Ruby | 平均 |
|---|---|---|---|---|---|---|---|
| CodeBERT-base | 0.932 | 0.708 | 0.870 | 0.828 | 0.709 | 0.772 | 0.803 |
| Owl-ph1 | 0.940 | 0.780 | 0.872 | 0.841 | 0.720 | 0.764 | 0.820 |
| Owl-ph2 | 0.943 | 0.801 | 0.879 | 0.833 | 0.729 | 0.774 | 0.827 |
結果のまとめ
- Owl-ph1 は CodeBERT-base をすべての言語平均で上回る(0.803 → 0.820)
- Owl-ph2 はさらに改善し、平均 0.827 を達成
- 特に Java・JavaScript・Go などで ModernBERT ベースのモデルの優位性が大きい
つまり、
ModernBERT + 2段階事前学習(特に行単位MLM)により、
CodeBERT 系モデルを一貫して上回る検索性能を達成できる
ことが確認できました。
Crow 系モデルの比較実験については、現在モデルを準備中のため、
後日結果を追記します。
おまけ:ModernBERT-base を使った追加実験
おまけとして、今回紹介したモデルとは別に、通常の ModernBERT-base に対して CodeSearchNet を用いて継続事前学習を行った実験結果も紹介します。
比較したモデルは次の 3 つです。
-
ModernBERT/base
→ 追加学習なし(初期状態の ModernBERT-base) -
ModernBERT/MLM
→ 通常のランダム MLM を用いて継続事前学習を実施 -
ModernBERT/Span
→ 行単位のマスキング(Span Masking)を用いて継続事前学習を実施
それぞれを CodeSearchNet から言語ごとに 1 万件ずつ抽出したデータでファインチューニングし、
最終的に CodeSearchNetRetrieval (MRR) を用いて評価を行いました。
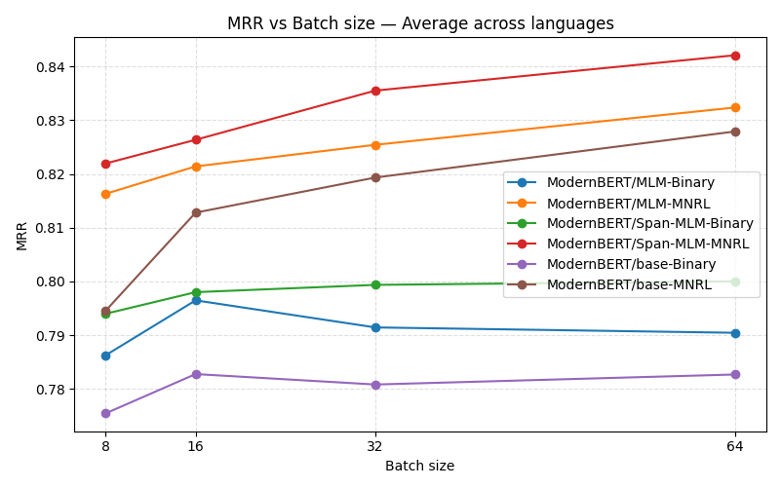
結果のポイント
- 継続事前学習(Continued Pretraining)は性能を向上させる
- その中でも Span-Masking(行単位 MLM)+ MNRL が最も高い MRR を達成
まとめ
本記事では、従来の CodeBERT / GraphCodeBERT 系モデルの制約を踏まえつつ、
ModernBERT を用いてコード検索向けの埋め込みモデルを自作した際の知見をまとめました。
-
独自データセットの構築
GitHub から関数と説明コメントを抽出し、約 850 万件のデータセットを整備。
加えて StarCoder 系の大規模コードデータセットも活用することで、より一般的なコード知識も取り込むことができました。 -
ModernBERT の採用による明確なメリット
RoPE・FlashAttention・GeGLU などの最新技術により、長いコンテキストや高速計算に強く、
コード検索モデルのベースとして非常に相性が良いことが実感できました。 -
2 段階の事前学習(ランダムMLM → 行単位MLM)の有効性
どのバックボーンでも約 +0.02 程度の改善が得られ、
行レベルで文脈を落とす事前学習が検索性能を底上げする という結果になりました。 -
MNRL を用いた対照学習が最も効果的
バイナリ分類よりも MNRL の方が CodeBERT / ModernBERT の双方で良い結果となり、
コード検索におけるランキング学習の重要性が改めて確認できました。
以上から、ModernBERT を利用すれば個人環境でも実用レベルのコード検索モデルを構築できる
という手応えを得ることができました。
個人的には、関数レベルのコード検索においては
トークン長の拡大によるメリットはそこまで大きくない という印象も得ています。
(ただしこれは “関数レベルで事前学習した場合” の話であり、Crow のように
ファイルレベルで事前学習した場合はまた違う結果になる可能性があります。)
今回は私の取り組みを中心にまとめましたが、
次回は 学習に必要な時間や GPU メモリ、速度の比較 など、
より定量的な観点からも深掘りしたいと考えています。
「コード検索モデルを自分で作りたい」
という方の参考になれば嬉しいです。
Discussion