Apache XTableを使ったAWS上でのOpen Table Format相互運用(Delta→Iceberg)
はじめに
AWS Community Builderのぺんぎん(@jitepengin)です。
最近、データ基盤のアーキテクチャでレイクハウスが採用されることも増えてきました。
その際、以下のOpen Table Format(OTF)が同時に使われるケースも珍しくないと思います。
- Delta Lake
- Apache Iceberg
- Apache Hudi
例えば、既存レイクハウスがDelta Lakeだけど、新規プロジェクトではIcebergを採用したい…といったケースもよくあります。
その際に課題となるのがOTF間の相互運用性です。
相互運用性とは、異なるレイクハウスやテーブルフォーマットを、スムーズかつシームレスに連携する考え方です。
例えば、Microsoft Fabricでは Iceberg Shortcutを使ってDelta ⇔ Icebergの一部同期を提供していますが、実際には型変換エラーが出るなど、双方向完全同期まではたどり着いていません。
こうした要求や課題を背景に、最近注目度が高まっているのがApache XTableです。
今回はXTableを使って、Delta LakeからIcebergへの変換・同期を試してみた内容を紹介したいと思います。
Apache XTableとは
Apache XTableは、以下のOTF間のシームレスな相互運用を実現するOSSプロジェクトです。
- Apache Hudi
- Delta Lake
- Apache Iceberg
ポイントは以下の通りです。
TableFormatSync
テーブルのメタデータを別フォーマットに変換する機能です。
例えばDelta LakeのテーブルをIcebergとして扱えるようになります。
CatalogSync
複数の外部カタログ間でメタデータ同期を行う機能です。
Hive Metastore(HMS)とAWS Glue Catalogなどの同期を実現します。
現状サポートはHMSとGlue Catalogですが、Unity、Polaris、Gravitino、DataHubなども近日サポート予定とのことです。
ちなみにPolaris CatalogもIcebergに特化した相互運用性を実現できるので注目のOSSだと思います
これにより、Hudiのリアルタイム性、Deltaの高機能性、Icebergの汎用性の強みを活かしたアーキテクチャを共通のカタログで管理することが可能になります!
AWS Glue Catalogと組み合わせて相互運用する
アーキテクチャ
今回は以下の構成で検証しました。
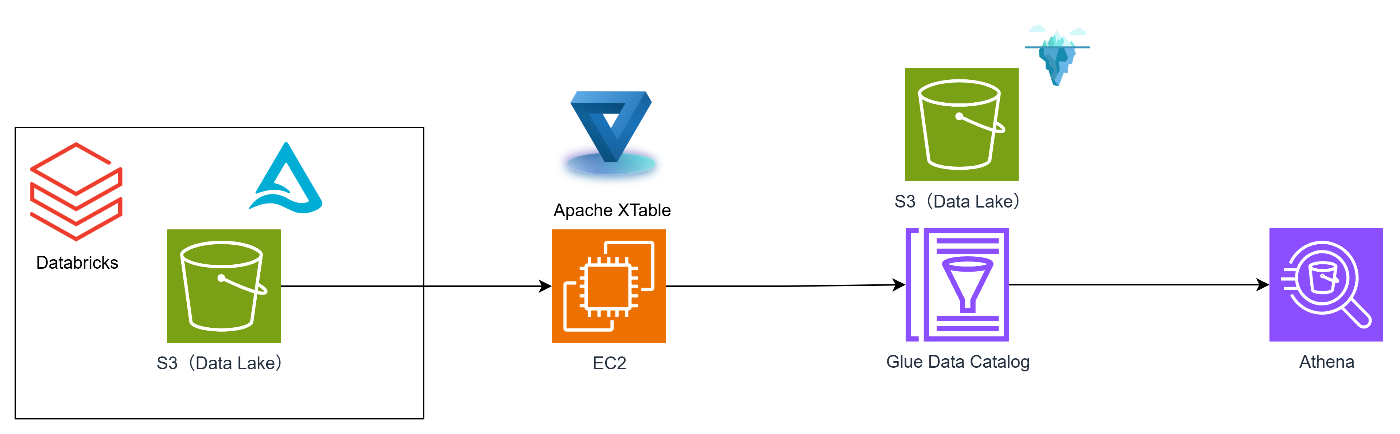
- DatabricksでDelta Lakeテーブルを作成(S3に配置)
- EC2にXTableを構成
- XTableでDelta→Icebergに変換し、IcebergをGlueCatalogに同期
本当はUnity Catalogをソースにしたかったのですが、こちらはまだ非対応のため、S3上のDelta Tableを直接扱う構成です。
設定内容
前述したようにsourceCatalogにストレージを指定、ターゲットカタログにGlueを指定しています。
datasetの設定でS3のDELTAテーブルからIcebergに変換を行います。
sourceCatalog:
catalogId: "source-catalog-id"
catalogType: "STORAGE"
catalogProperties: {}
targetCatalogs:
- catalogId: "target-catalog-id-glue"
catalogSyncClientImpl: "org.apache.xtable.glue.GlueCatalogSyncClient"
catalogProperties:
externalCatalog.glue.region: "ap-northeast-1"
datasets:
- sourceCatalogTableIdentifier:
storageIdentifier:
tableBasePath: "s3://your-source-bucket"
tableName: "source-table"
tableFormat: "DELTA"
targetCatalogTableIdentifiers:
- catalogId: "target-catalog-id-glue"
tableFormat: "ICEBERG"
tableIdentifier:
hierarchicalId: "db.delta_table"
起動方法
下記のようにxtable-utilitiesでRunCatalogSyncを実行します。
java -cp "xtable-utilities/target/xtable-utilities_2.12-0.2.0-SNAPSHOT-bundled.jar:xtable-aws/target/xtable-aws-0.2.0-SNAPSHOT-bundled.jar:hudi-hive-sync-bundle-0.14.0.jar" org.apache.xtable.utilities.RunCatalogSync --catalogSyncConfig my_config_catalog.yaml
実行結果
Databricks側

コマンド実行

Glue Catalog
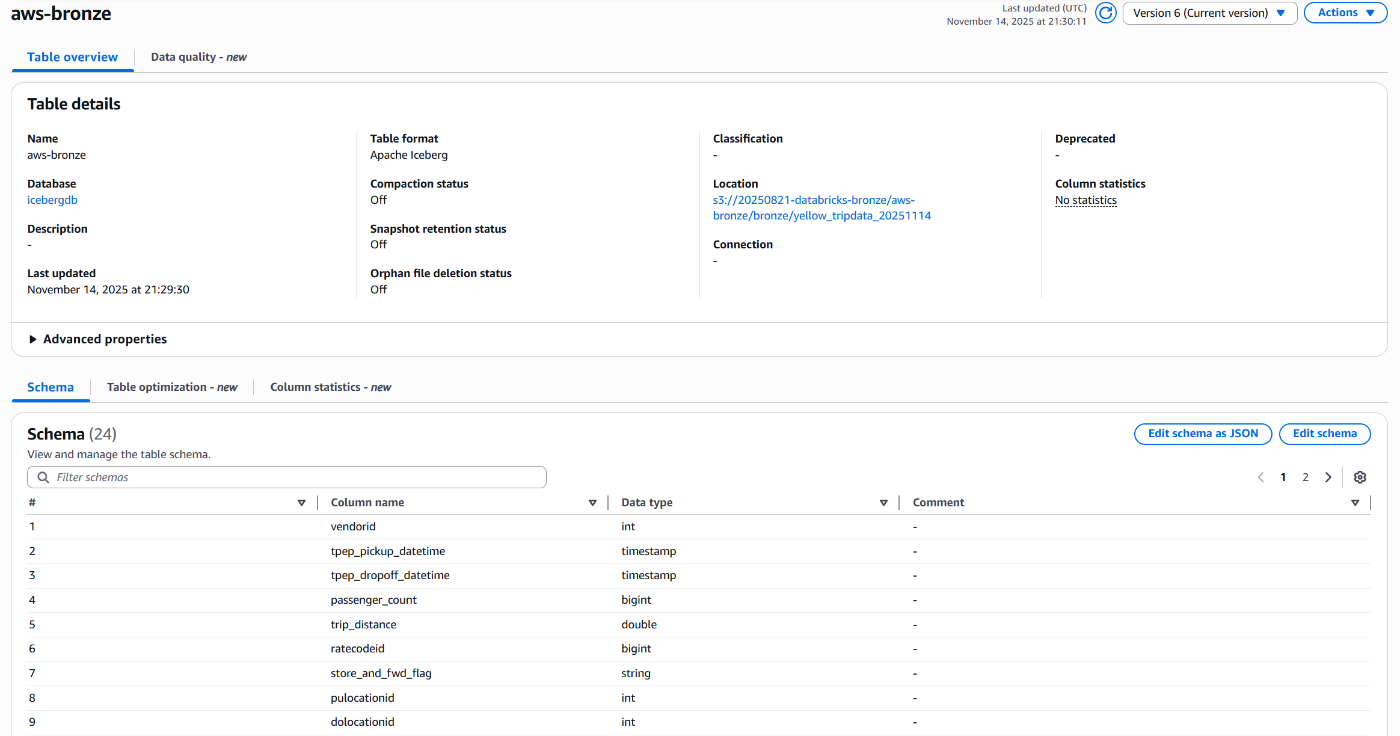
Glue Catalogにメタデータが反映され、Iceberg形式のテーブルが作成されています!
Athena

Glueカタログ経由でAthenaによるクエリも問題なく実行可能です!
その他のアプローチ(EventBridge×Lambda)
リアルタイム同期は難しいものの、EventBridgeとLambdaで定期同期を行う構成も検討できます。
また、ニアリアルタイム処理としてS3イベントで起動する構成も良さそうです。
スケジュール起動構成
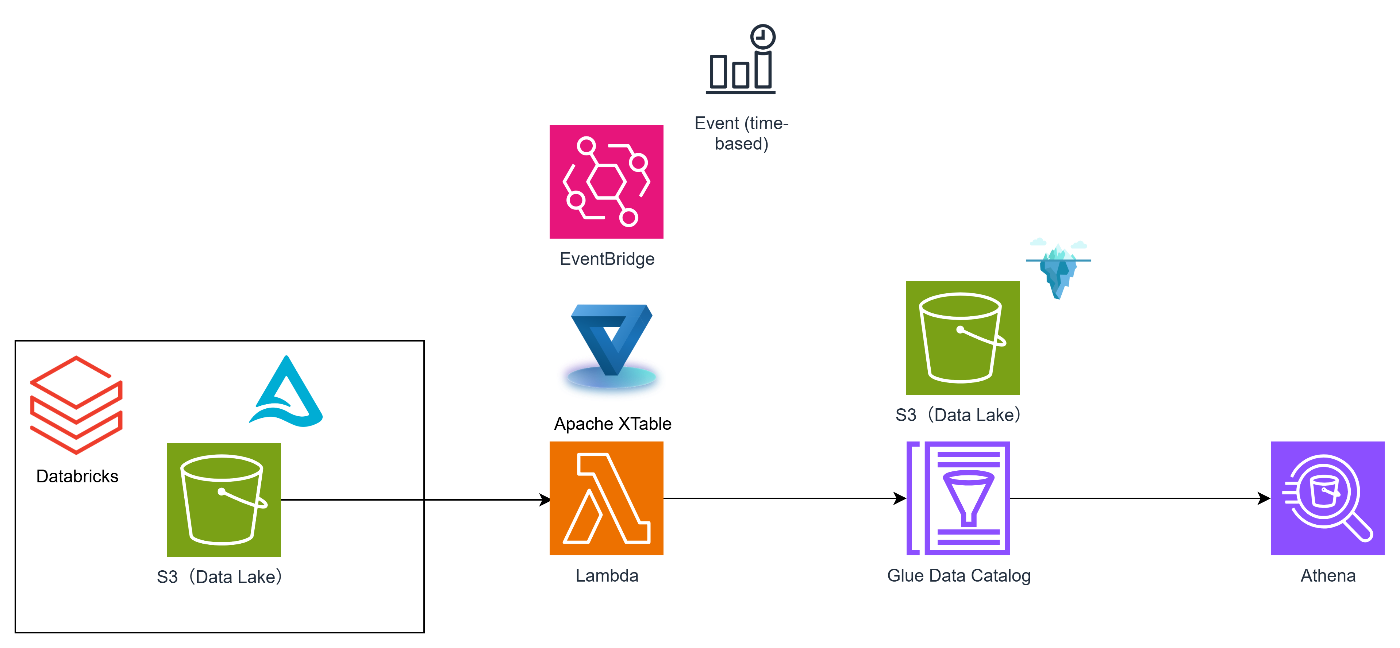
- Delta Lake(S3)にデータ登録
- EventBridge経由でLambdaを起動
- Lambda上でJPypeを使ってXTableのJavaライブラリを実行
- Iceberg/Deltaの変換タスクを実行し、Glue Catalogに同期
イベント起動構成

- Delta Lake(S3)にデータ登録
- ファイル更新をトリガにLambdaを起動
- Lambda上でJPypeを使ってXTableのJavaライブラリを実行
- Iceberg/Deltaの変換タスクを実行し、Glue Catalogに同期
これにより、ニアリアルタイムでの同期も可能です。
LambdaからGlue Catalog更新まで自動化できるので、コストを抑えた同期構成としてのアプローチに良いと思います。
XTableを使ってみて分かった課題点
実際にDeltaとIcebergの同期を試しながら見えてきた、ハマりポイントをまとめます。
EC2インスタンスサイズは小さいと厳しい
XTableは複数のOTFライブラリを読み込みます。
- Java11
- Maven
- hudi-hive-sync
- XTable 各種 JAR
これらの依存関係を扱うため、t3.micro / smallではメモリ不足で正常動作しません。
発生する問題例:
- Java ヒープ不足
- Spark 起動失敗
- JAR読み込みエラー
- クラス競合エラー
→ t3.medium〜large以上を推奨
サーバーレスで完結させたい場合もありますが、現状ではある程度のEC2リソースは必要です。
型のエラーが発生する可能性がある
Microsoft FabricのIceberg Shortcutでもよくある事象ですが、型変換のエラーが発生することが多々あります。
OTF間の型互換自体がまだ成熟していないため、どのサービス・OSSでも完全な双方向同期は難しいのが現状と言えるのかなと。
つまり、スキーマの進化が売りのOTFでも相互運用性を加味すると様々な考慮が必要ということです。
まとめ
今回はApache XTableについて紹介しました。
Apache XTableは、異なるOpen Table Formatを共通カタログ上で扱える強力な OSSです。
しかし実際に触ってみると、
- DeltaとIceberg間の型変換はまだ不安定
- EC2のスペックは十分必要(EC2の管理も必要)
- スキーマの進化に対応するには検証が必要
といった課題や考慮事項があり、現時点では本番利用には難しい部分が多いです。(incubatingなので当たり前と言えば当たり前ですが)
一方で、XTableは今もっとも活発に進化しているOTF間相互運用のソリューションであり、将来的にはレイクハウス間の壁を低くし、サイロ化を解消したより自由なデータ基盤構築を後押しする存在になる可能性があります。
今回の記事が、データ基盤の構築を検討している方の参考になれば幸いです。
Discussion