はじめに:本記事について
私の所属する部署では自動車にかかわる様々な開発をしています。その中でも私のチームでは、特にコネクテッドカー(Connected Car) にかかわるバックエンド開発を担当しています。その中で私は、映像の機械学習向けの処理を効率化/分散させるためにKubernetes (K8s)ベースのアーキテクチャ検討をしています。その取り組みの一環として、GPUを分割する手法について調査いたしました。この記事では、そこで得たノウハウの一部を共有いたします。
GPUの分割方式が複数存在する中で、それぞれの技術がどのようなユースケースに最適で、性能や分離レベルにどのようなトレードオフがあるのかが一覧化されている資料があまりありませんでした。
そこで本記事では、GPU分割手法の導入を検討されている方々の一助となるべく、各方式のメリット・デメリットを記述します。
本記事を読むと得られるメリット
- GPU分割手法であるタイムスライシング、MIG、MPSの違いが理解できる
- 用途によって使い分けが可能になる
前提
GPU分割手法の利点
GPU1枚あたりのリソース利用効率の向上が期待できます。
前提として、GPUは高額であるため、GPUリソースを余すことなく消費することが理想です。しかしながら、単一のワークロードのみでは、GPU1枚あたりの計算リソースやメモリリソースを完全に消費しきれないケースが少なくありません。
これは、GPUを利用するワークロードには「推論のように、必ずしもGPUを継続的に占有し続けないもの」と「学習のように、長期間GPUを占有し続けるもの」の2種類存在するためです。前者のような断続的なワークロードを実行する状況においては、GPU分割技術の導入によるリソース利用効率の向上が期待できます。
特にクラウドサービスでGPUを利用する場合、GPU1枚単位で提供されるのが一般的です。したがって、実行するワークロードのリソース消費量に応じてGPUの分割数を適切に調整し、GPU1枚あたりのリソースを最大限活用することが望ましいです。
※補足
AzureやAmazon Web Services(AWS)にはGPU分割済みのインスタンスが存在します。しかし、あらかじめ分割数が決まっており、ワークロードに応じてGPUリソースの割り当て量を調整することはできません。
GPU分割手法一覧
※NVIDIA製GPUを前提として記載しています
タイムスライシング
time-slicing より

概要
タイムスライシングは、GPUの処理時間を非常に短い時間(タイムスライス)に区切って各プロセスに順番に割り当てることで、あたかも複数のプロセスが同時にGPUを利用しているかのように見せる技術です。特別なハードウェアを必要とせず多くのNVIDIA GPUで利用可能なため、手軽に導入できるのが特徴です。
仕組み
GPUのスケジューラが各プロセスのコンテキストを切り替えながら処理を実行します。例えば、プロセスAとプロセスBに同じGPUを割り当てた場合、プロセスAがGPUを利用し、その後にプロセスBが利用する、というサイクルを高速で繰り返します。
メリット
- 幅広いGPUで利用可能: 多くのNVIDIA GPUで利用できます。
- リソースの有効活用が期待できる: GPUの割り当てが交互に発生するため、特定のプロセスがGPUを使用していない間に別のプロセスにGPUを割り当てることが可能です。そのため、CPUを用いた前処理、後処理の割合が大きいワークロードでは性能改善が見込めます。
デメリット
- コンテキストスイッチのオーバーヘッド増加: プロセスを切り替える際に、コンテキストスイッチ(GPUが処理するタスクの状態を保存・復元する処理)のオーバーヘッドが生じます。そのため、学習のように長時間GPUを占有し続けるワークロードでは、コンテキストスイッチのオーバーヘッド分処理時間が増えます。
- リソースの競合: 各プロセス間でGPUメモリが共有されるため、1つのプロセスが大量のメモリを消費すると、他のプロセスに影響を及ぼす可能性があります。
MPS
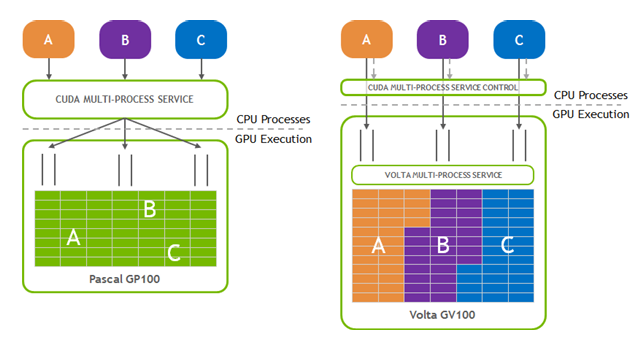
概要
MPS(Multi-Process Service)は、複数のCUDAプロセスが1つのGPUを効率的に共有し、スループットを向上させることを目的としたランタイムサービスです。
仕組み
MPSを有効にすると、GPUごとにmps-serverと呼ばれるサーバープロセスが立ち上がり、これが各GPUごとのスケジューラの役割を果たします。 複数のCUDAプロセスからのリクエストは、このmps-serverを経由して単一のCUDAコンテキストにまとめられ、GPU上で同時に実行されます。これにより、本来プロセスごとに必要だったコンテキストスイッチのオーバーヘッドが削減されます。
メリット
- コンテキストスイッチ削減によるスループットの向上: コンテキストスイッチのコストが削減されるため、特にGPUの利用時間が短いワークロードを複数回実施する状況においてスループットの向上が見込めます。
- GPU計算ユニットの利用率向上: タイムスライシングと違い、複数のプロセスが同時にGPUの計算ユニット(SM: Streaming Multiprocessor)を利用することが可能です。
デメリット
- GPUメモリの分離が完全ではない: プロセス間のメモリ空間は論理的には分離されますが、物理的には分離されません。したがって、1つのプロセスで発生したメモリ起因のエラーが、同じMPSサーバーに接続している他のプロセスに影響する可能性があります。
- エラー分離が完全ではない: 各プロセスがコンテキストを共有しているため、1つのプロセスでエラーが発生した場合に他のプロセスに影響を及ぼす可能性があります。
MIG

概要
MIG (Multi-Instance GPU) は、NVIDIA Ampere世代 (A100など) およびHopper世代 (H100など)、Blackwell世代のGPUで導入された機能で、GPUをハードウェアレベルで完全に分離・分割する技術です。
仕組み
1つの物理GPUを最大7つの完全に独立したGPUに分割します。 各GPUには、専用のGPUメモリ、キャッシュ、ストリーミングマルチプロセッサ(SM、GPU内で計算処理を行うユニット)といったコンピューティングリソースが物理的に割り当てられます。ハードウェアレベルで分離されているため、互いに干渉することがありません。
メリット
- 障害分離: ハードウェアレベルで分離されているため、分割したGPUを利用するプロセスがクラッシュしても、他のプロセスに影響を与えることはありません。
- パフォーマンスが予測可能: 割り当てられたリソースは専用であるため、タイムスライシングのようなリソース競合による性能低下の懸念がありません。
- 分割パターンを複数選択可能: あらかじめ用意された分割パターンの範囲で分割数を選択することが可能です。例えば、均等に7分割するのではなく、3:4のリソース割合でGPUを2つに分割するといったことも可能です。
デメリット
- 対応GPUが限られる: NVIDIA A100、H100などのAmpereまたはHopperアーキテクチャ以降の特定のデータセンター向けGPUに限定されます。
- 分割数の制限: 分割できる数に制約があります。最大でも7分割しかできません。
- リソースの動的割り当てができない: ハードウェアレベルで分離されているため、分割したGPUの一部がアイドル状態でも、その分のリソースを他のGPUに割り当てることはできません。
まとめ
| 技術 | 特徴 | メリット | デメリット |
|---|---|---|---|
| タイムスライシング (Time-Slicing) | 複数のプロセスにGPUの利用時間を順番に割り当てる | 特別なハードウェアを必要とせず、多くのGPUで利用可能。 | コンテキストスイッチのオーバーヘッドが生じる。リソース分離が不完全。 |
| MPS (Multi-Process Service) | 複数のCUDAプロセスがmps-serverを通じて1つのGPUを効率的に共有 |
特別なハードウェアを必要とせず、多くのGPUで利用可能。コンテキストスイッチのオーバーヘッドを削減できる。 | 論理的にはリソース分離されるが、物理的には分離されない。 |
| MIG (Multi-Instance GPU) | GPUをハードウェアレベルで物理的に最大7つに分割 | 各GPUが完全に分離され、互いに干渉しない。パフォーマンスが安定・予測可能。 | 対応GPUがNVIDIA A100やH100などに限定される。 |
GPU分割技術の使い分け
GPU分割技術は、それぞれに長所と短所があるため、用途に応じて使い分けることが重要です。以下では、使い分けの一例を記載します。
| シナリオ | 選択すべき分割手法 | 理由 |
|---|---|---|
| MIG対応のGPUかつ、分割数が7以下で十分な場合 | MIG | 分割した他のGPUリソースからの干渉が一切なく、安定したパフォーマンスが保証されるため、使用可能であればMIGの使用を第一に検討すべきです。特に、厳格なリソース分離が求められるマルチテナント環境や、ミッションクリティカルな処理を分割したGPUで実行したい場合に適しています。 |
| MIG対応していないGPU、もしくは分割数を8以上にしたい場合 | MPS | MIGのような厳密なハードウェア分離ではありませんが、多くのNVIDIA GPUで利用できることと、分割数を8以上に設定可能であることから、MIGが使用可能ではない状況下では選択肢となります。コンテキストスイッチのオーバーヘッドが削減可能であるため、小規模な推論処理を複数実行する場合に適しています。 |
| 手軽にGPU分割を試してみたい場合 | タイムスライシング | 特定のGPUアーキテクチャに依存しないこと、MPSやMIGと比べて設定が容易であることから、GPU分割を試してみたいときに適しています。ただし、リソース競合やコンテキストスイッチによる性能低下の可能性があるため、性能要件が厳しい本番環境での利用には注意が必要です。 |
おわりに
我々のチームでは自動車を軸に、R&Dから商用開発まで幅広に開発をしています。
** 興味がある方は **
** 自チームの取り組み紹介 **
** 過去の記事 **
** 本件に関するお問い合わせ先 **
株式会社NTTデータ
システムインテグレーション事業本部
ビジネスエンジニアリングサービス事業部
自動車開発統括部
E-mail:connected-car-cloud@hml.nttdata.co.jp

NTT DATA公式アカウントです。 技術を愛するNTT DATAの技術者が、気軽に楽しく発信していきます。 当社のサービスなどについてのお問い合わせは、 お問い合わせフォーム nttdata.com/jp/ja/contact-us/ へお願いします。