サーバー
リクエスト対応
Webサーバーは「リクエストの到着順に一つずつ処理している」わけではない。
代わりに 同時に複数のリクエストを処理できる仕組みであるマルチプロセス・マルチスレッド・イベント駆動を使っている。
リクエスト処理の仕組み(ざっくり)
- Webサーバー(Apache, Nginx, Node.jsなど)がHTTPリクエストを受け取る
- リクエストキューに一時的に貯める(受信順)
- 処理可能なプロセス/スレッド/イベントループで同時に複数を処理する
| サーバー | 方式 | 説明 |
|---|---|---|
| Apache | マルチプロセス / スレッド | リクエストごとに新しいプロセスやスレッドを使って並行に処理 |
| Nginx | イベント駆動・非同期I/O | 単一プロセスで大量のリクエストを効率的に処理(高性能) |
| Node.js | 単一スレッド + 非同期イベントループ | I/O操作をブロックせず、同時に多くのリクエストをさばく |
リクエストは基本的に到着順にキューに入る
でも、処理の完了順は異なる(重い処理が遅れる)
結果として同時並行で処理され、順番通りに返されるとは限らない
Node.jsがWebサーバーになる
Node.jsでは、自分でHTTPサーバーをコードで作成できる。
ApacheやNginxのような「設定ファイルベースのWebサーバー」とは違い、JavaScriptでWebサーバーを動かすという発想。
ApacheやNginxとの違い
| 特徴 | Node.js | Apache / Nginx |
|---|---|---|
| 開発スタイル | JavaScriptでコードを書く | 設定ファイルベース |
| 拡張性 | 高い(アプリに合わせて自由に書ける) | 高機能だが柔軟性に限界あり |
| 使われ方 | アプリケーションサーバー兼Webサーバー | 静的ファイルの配信が得意、Node.jsのフロントにも立てられる |
多くの本番環境では、Nginx + Node.js の組み合わせが主流。
Nginxがフロント(外部公開)
Node.jsがアプリ処理(APIなど)
という役割分担で、セキュリティや負荷分散を実現しつつ、Node.jsの柔軟性を活かせるから。
マルチプロセス・スレッド・非同期イベント駆動
| 方式 | 特徴 | メリット | デメリット |
|---|---|---|---|
| マルチプロセス | 複数のプロセスを同時に動かす | 安定・安全(プロセスごとに独立) | メモリ消費多い |
| マルチスレッド | 1つのプロセス内で複数のスレッドが並行処理 | 軽量で高速 | スレッドの競合や同期が難しい |
| 非同期イベント駆動 | 1スレッドでイベント(I/Oなど)に応じて動く | 軽量・効率的(Node.jsなど) | 書き方に慣れが必要(コールバック地獄など) |
マルチスレッド(例:Java、C++)
[プロセス]
├─ スレッド1:データ受信処理
├─ スレッド2:ログ記録
└─ スレッド3:UI更新
・同じメモリ空間を共有 → 速いけど競合も起こる
・CPUコアが複数あれば実際に並列で動くことも可能
マルチプロセス(例:PHP+Apache、Pythonのmultiprocessing)
[プロセス1]:ユーザーA処理
[プロセス2]:ユーザーB処理
[プロセス3]:ユーザーC処理
・各プロセスが独立している → 安全(1つ落ちても他に影響なし)
・プロセス間通信(IPC)は手間がかかる
非同期イベント駆動(例:Node.js)
[イベントループ(1スレッド)]
├─ 非同期I/O → WebAPIに任せて待たずに次へ
└─ コールバックを後で処理
・長い処理(ファイル読み込み・HTTP通信)を待たずに次の処理へ
・非同期関数はPromiseやasync/awaitで書きやすくできる
使い分け
| シチュエーション | 向いてる方式 | 備考 |
|---|---|---|
| 安定・安全重視 | マルチプロセス | WebサーバーのApacheなど |
| 処理速度と軽さ重視 | マルチスレッド | Javaアプリ、ゲームなど |
| 高速なI/O処理が多い | 非同期イベント駆動 | Node.js、チャット、APIサーバーなど |
ウェブサーバ(web server)
World Wide Web(WWW)の基盤となるインフラストラクチャの一部であり、クライアントからのリクエストを受け取り、レスポンスとして適切なリソースを提供するという役割を担う重要な要素。
ウェブサーバは、具体的には、Hypertext Transfer Protocol(HTTP)というルールに基づいて、ウェブからのリクエストを解釈し、適切なレスポンスを提供する特別なソフトウェアとも言えるが、同時にそれを実行する物理的なコンピュータそのものを指すこともある。
そして、特定のウェブサーバソフトウェアをコンピュータにインストールし、サービスとしてバックグラウンドで動作させることで、ウェブサーバとして機能し、インターネット上のユーザーからのリクエストに応じてレスポンスを返すことができる。
ウェブサーバは基本的にそのような特定のソフトウェアを使用してクライアント(通常はウェブブラウザ)からのリクエストに応じてウェブページやファイルを提供する。
ウェブサーバソフトウェアの代表的な例
・Apache HTTP Server
・Microsoft Internet Information Services(IIS)
・NGINX
また、ウェブアプリケーションを実行するためには、プログラムが動作する特定の環境、つまり「ランタイム環境」または「ウェブサーバライブラリ」が必要。
これらの環境は、ウェブリクエストを受け取り、処理する機能を提供する。
Node.js や Go はそのような機能を提供している。
Python などの一部のプログラミング言語では、HTTP リクエストを受け取り、適切に処理するための特別なツールやラッパーが存在する。uWSGI や mod_wsgi はそのようなラッパーの例で、それぞれ NGINX や Apache というウェブサーバソフトウェアと組み合わせて使われる。これらは HTTP リクエストとプログラム間で情報を伝達する役割を果たす。
ウェブサーバライブラリ例
| ライブラリ | 言語 | 説明 |
|---|---|---|
| Express | Node.js | HTTPサーバーの作成やルーティングが簡単にできる |
| Flask | Python | 軽量なWebアプリフレームワーク(実質的にWebサーバーも内包) |
| Sinatra | Ruby | 非常にシンプルなWebサーバ・フレームワーク |
| FastAPI | Python | API用の高速なWebサーバライブラリ |
| http.server | Python(標準) | 開発用に使える簡易Webサーバー |
クライアントとサーバ
最も典型的なクライアントは、HTTP を通じてファイルなどのリソースをリクエストすることに特化したウェブブラウザ。ウェブブラウザは、HTML、CSS、JavaScript などのウェブ言語を解釈し、ウェブページとしてユーザーに表示するためのレンダリングエンジンを内蔵している。これにより、ユーザーはウェブページを視覚的に理解し、ウェブページ上の情報を読み取り、リンクをクリックしたり、フォームを記入したりといったアクションを実行することが可能になる。
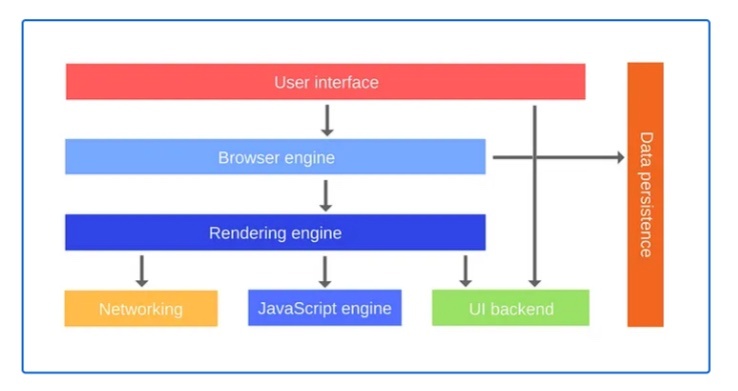
しかし、HTTP はただの通信プロトコルであり、ウェブブラウザだけがクライアントになるわけではない。さまざまなデバイスやプラットフォームから、ウェブサーバに対して HTTP リクエストを送ることが可能。デスクトップコンピュータ、スマートフォン、さらには IoT(モノのインターネット)デバイス向けのアプリケーションもクライアントとして機能する。
ウェブブラウザ以外のプラットフォームからリクエストが来た場合、サーバは通常、JSON というフォーマットのファイルを使用してデータを返す。クライアント側は、この JSON データを適切に解析し、使用する。
ウェブブラウザはユーザーに視覚的な情報を与えるため、HTML、CSS、JavaScript を返すことが多いが、JSON はデータの形式で、軽量で読みやすく、多くのプログラミング言語で扱うことができJSONが多く使用される。なお、ブラウザは SPA においては JSON を読み取り動的にページ内容を変更することも可能。
ウェブサーバは、インターネット全体の構成要素の一部となっており、それぞれが特定の計算作業を担当し、全体としてインターネットという大規模なネットワークシステムを支えている。
一つのホストウェブサーバに対して、複数のクライアントが接続する。ウェブサーバは一台のコンピュータ(サーバ)で運営されることもあるが、ウェブサイトの規模や需要に応じて、たくさんのサーバが組み合わさった「内部ネットワーク」を持つこともある。
これは、大量のユーザーが同時にアクセスしても、サーバがダウンすることなくスムーズに情報を提供できるようにするための工夫。これをスケーラビリティと呼ぶ。
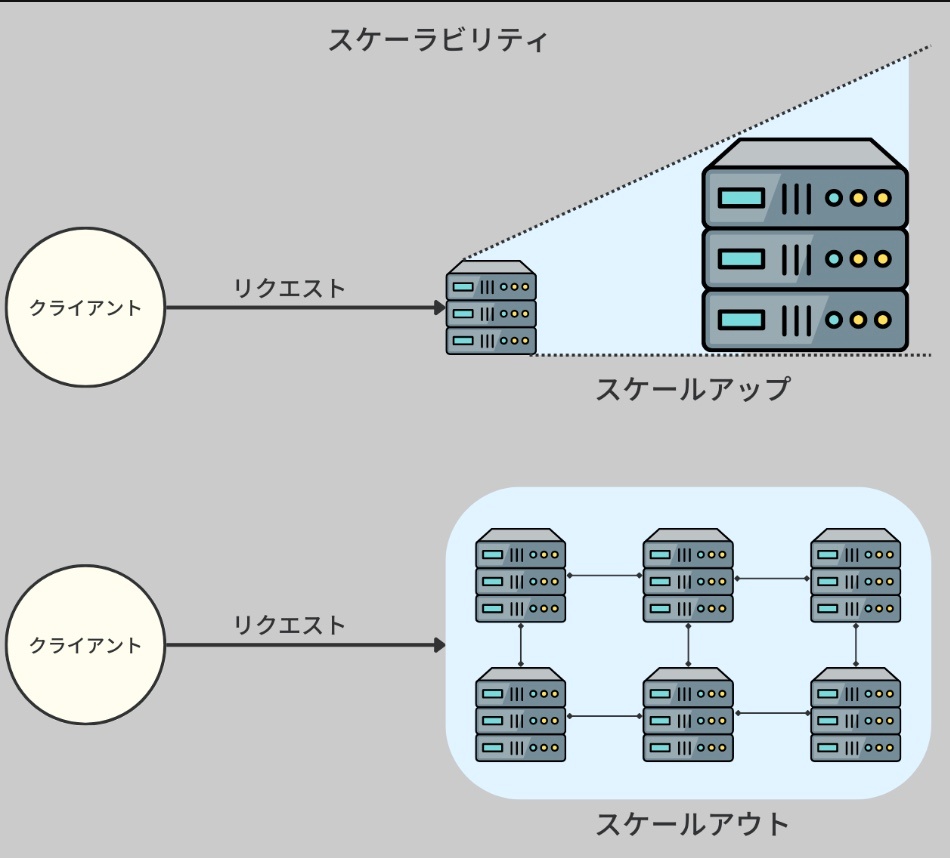
※https://recursionist.io/dashboard/course/33/lesson/1138 より画像引用
ウェブサーバの目的
ウェブサーバとクライアントのアプリケーションでは、サーバにアプリケーションのすべてのビジネスロジックが格納される。このロジックはクライアントからは見えないため、サーバはしばしばバックエンドと呼ばれる。これは、クライアントが直接触れることができないが、クライアントの要求を処理するために重要な役割を持つ。
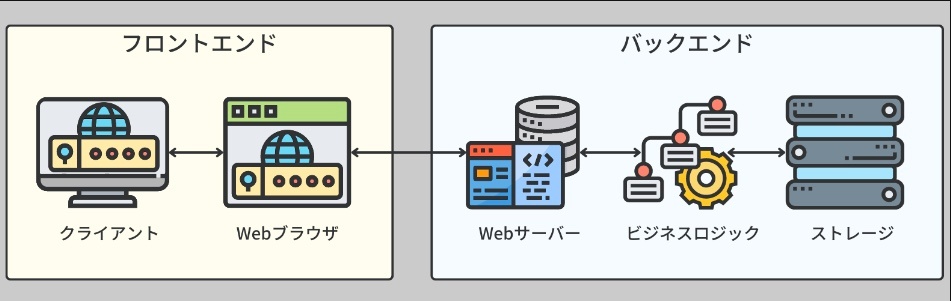
※https://recursionist.io/dashboard/course/33/lesson/1139 より画像引用
ウェブサーバは、クライアントからの HTTP リクエストを受け取り、その内容を解析する。
次に、それに応じて適切なアクションを実行し、リクエストを処理する。ウェブサーバ内には、リクエストを適切に処理するために必要なすべてのコードとプログラムが組み込まれている。
バックエンド開発者の主な仕事は、クライアントの要求を満たすための適切なコードとプログラムを開発すること。これは、ウェブサーバが機能するための重要な側面であり、バックエンド開発者はこのプロセスに不可欠な役割を果たす。
目的① リソースの管理と配信
ウェブサーバは、クライアントが要求する様々なリソースを保管し、管理し、提供する役割を果たす。
これらのリソースは、ウェブブラウザが解釈・表示するための HTML、CSS、JavaScript のようなウェブファイル、さらには画像、動画、PDF、JSON、ZIP ファイルなど、多種多様なファイル形式を含む。
ウェブサーバはこれら全てのリソースを保存し、クライアントのリクエストに基づき、求められたリソースを探し出して提供する。
クライアントはこれらのリソースを取得することで、ユーザはレンダリングしたり、ダウンロードすることができる。
これらのリソースを、クライアント側ではなくサーバ側に保管する理由(多岐にわたる)
理由①:動的コンテンツ
サーバ上にリソースを保管することで、リソースを動的に生成し、リクエストのパラメータやデータベースの状態によってそれを変化させることが可能になる。
例えば、HTML ファイルはユーザーが保存した情報に基づいて動的にレンダリングすることができる。
ウェブサーバは、ユーザーから提供された情報(例えば、フォームの入力値やログイン情報など)を元に、個々のユーザーに対して特化した HTML ファイルを生成することができる。
例えば、ログイン後のユーザーダッシュボードページは、そのユーザーの情報に基づいてレンダリングされる。
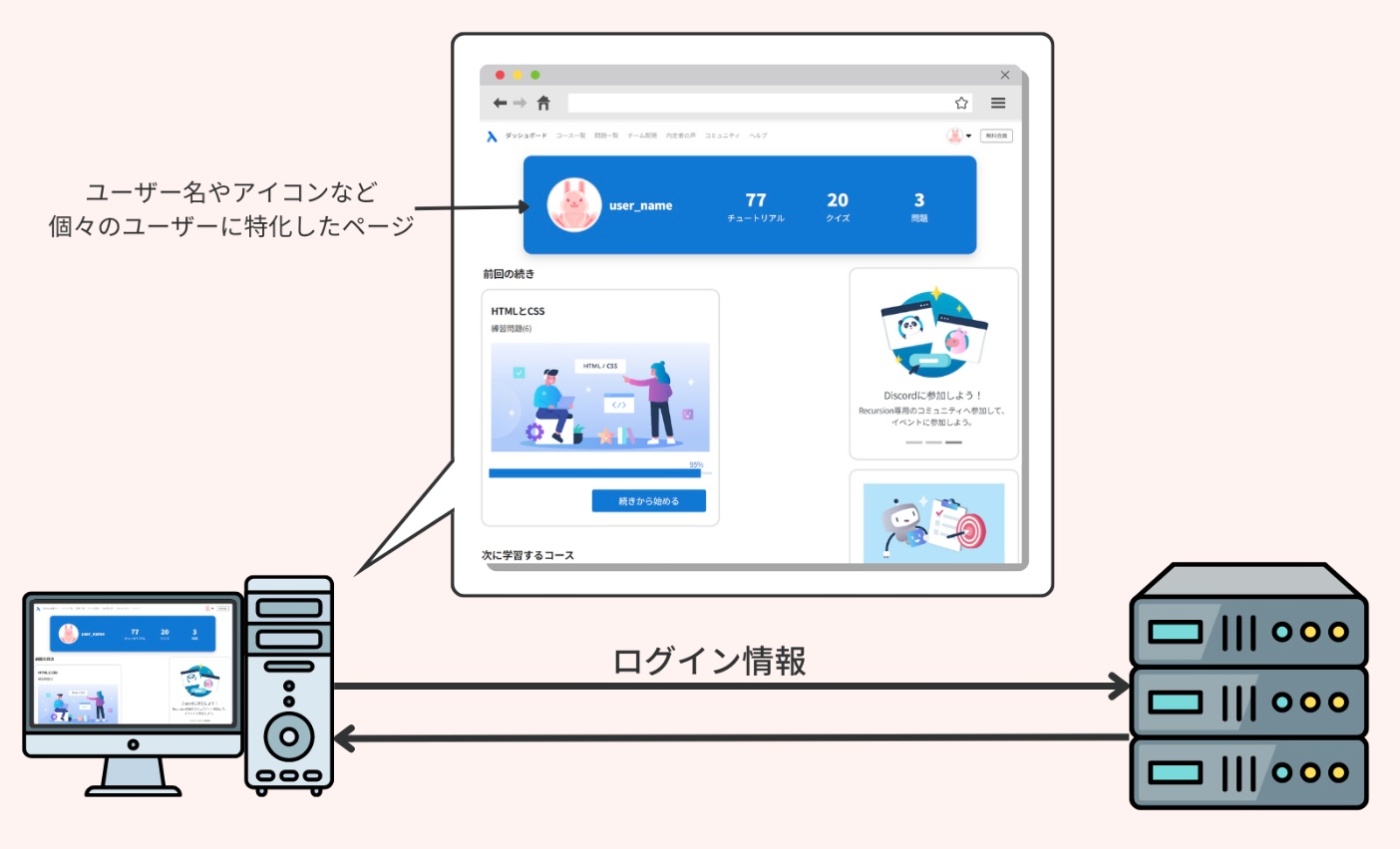
※https://recursionist.io/dashboard/course/33/lesson/1139 より画像引用
また、インターネット上のスクラップデータに基づいて PDF ファイルを生成することも可能。
例えば、ニュース記事をスクレイピングして、その情報を用いて PDF レポートを生成することができる。
さらに、MP4 ファイルはユーザーが投稿した動画と、バックエンドで行われた AI 変換の結果に基づいて新たに動画を生成することができる。これは、動画共有サービスや、AI を利用した動画編集サービスなどで使われる。
理由②:スケーラビリティ
全てのリソースをクライアント側に含めてしまうと、スケーラビリティに関する多くの問題が生じる。
例えば、全てのリソースをクライアント側に保存すると、そのリソースを保存するための大量のストレージスペースが必要になる。ユーザーのデバイスは限られたストレージ容量を持っているため、その限界を超えてしまうと、他のデータやアプリケーションの動作に影響を及ぼす可能性がある。
また、新たなリソースが追加されたとき、それを全てのクライアントがダウンロードして更新する必要がある。これは通信量や時間を必要とし、また全てのユーザーがそれを行なうことが保証されないため、最新のリソースを全てのユーザーに配布するのは難しいという問題がある。
例えば、Netflix が提供している映画の容量はとても大きく(何千テラバイトもの規模)、そして常に新しいコンテンツが追加されている。これら全てをユーザーのデバイスに保存することは、ストレージ容量や通信量の観点から非現実的。
理由③:リソースの共有
特定のユーザーやユーザーグループがウェブサーバ上の特定のリソース(例えば、データベース内のエントリーや共有ドキュメント)にアクセスして、その内容を変更することができる。そして、その結果がすぐに他のクライアント(そのリソースにアクセスする他のユーザー)に反映することができる。
理由④:アップデートの一元化
アプリケーションのアップデートは、すぐにユーザーに反映される必要がある。
ここでサーバは、ファイルの最新のアップデートやパッチを保存する中心的なリポジトリとして機能する。開発者や管理者は、更新されたファイルをウェブサーバにアップロードし、即座に配布できるようにすることが可能。
パッチとは、ソフトウェアやオペレーティングシステムに存在するバグを修正したり、新たな機能を追加したり、既存の機能を改善したりするためのソフトウェアのアップデートのことを指す。これはソフトウェアの特定の部分(パート)を「修繕」するもので、そこからパッチという名称が来ている。
ソフトウェア開発者やメンテナーは、問題の発見や新しい機能の導入に応じて、パッチを定期的にリリースする。これらのパッチは、ソフトウェアの安定性、パフォーマンス、セキュリティを向上させることができる。
理由⑤:セキュリティ
サーバへのアクセスを制限し、サーバレベルでのセキュリティ対策を実施することで、機密情報や専有リソースをより安全に保護することができる。
これは、権限のないユーザーに対して重要なリソースを公開するリスクを低減するための重要な手段であり、それはクライアント側として配布するのとは対照的なアプローチ。
すべてのリソースがクライアント側で保持されていると、そのリソースはクライアントのデバイスやネットワークのセキュリティに依存することになる。これは、悪意のあるユーザーがリソースにアクセスし、それを悪用する可能性を高める可能性がある。
ウェブサーバの目的
目的② データ処理
ウェブサーバは、データ処理の中心的な役割を果たす。
これは、サーバサイドのスクリプトの実行、データベースとの通信、そしてビジネスロジックの適用を含む。これらを通じて、ウェブサーバはユーザーからの入力やリクエストを処理し、必要な計算を行なう。
核となるビジネスロジックの大部分がクライアントではなくサーバ上で実行される理由
理由①:パフォーマンス
クライアントは多種多様なマシンに搭載されており、それぞれのハードウェアリソースは限られている。
そのため、クライアントがサービスの計算を処理するために必要な CPU パワー、ストレージ、帯域幅(ネットワークの速度)を常に保証することは簡単ではない。
特に、Google マップのルート検索のような複雑な計算を必要とするサービスでは、クライアントの行動や位置、交通情報などに基づいてデータを処理し、効率的にルートを最適化する必要がある。このような重いタスクや複雑なデータを処理するためには、ウェブサーバが垂直スケーリングや並列計算などの強力なインフラとスケーリング技術を活用することが求められる。
理由②:集中型のデータ処理
データの処理や操作は一つの場所、つまりサーバで行われ、それに対して各クライアントは結果を取得するためにこのサーバにアクセスする。この集中型のアプローチによってレンダリングコードとビジネスロジックコードが分離され、クライアントがどのようなデバイスやオペレーティングシステムを使用していても、サーバから提供されるサービスやデータの処理結果は均一になる。
理由③:データセキュリティ
サーバは高度なセキュリティ対策を実装することができ、機密性の高い業務やデータを保護する。
重要なロジックをサーバ上に保持することで、アクセス制御、認証メカニズムの実装、そして機密情報の暗号化といったセキュリティ対策を施すことが可能になる。
クライアント側のロジックはセキュリティの脆弱性や改ざんのリスクが存在し、重要な業務の安全性を確保するには不十分。一方、サーバレベルでは、データの完全性を確保するためにデータの検証など、より多くの保護層を実行することが可能。
理由④:知的財産の保護
企業の独自のアルゴリズムや計算に対するクライアントアクセスを制限するために、コアロジックはサーバ上に保管される。これにより、リバースエンジニアリング(ソフトウェアを解析して、ソースコードなどを調査すること)や不正使用のリスクが最小限に抑えられる。
サーバはクライアントやサードパーティのプログラムに対して、要求された操作が何を行なうのかは公開しているが、それがどのように行われるのかは公開していない。これにより、サーバは完全なブラックボックスとなり、企業の知的財産を保護する役割を果たす。
ウェブサーバの目的
目的③ 利便性
ウェブサーバは過去数十年間の進化を経て、現在ではクライアントサーバアーキテクチャにおけるサーバ設定の標準的な方法となった。開発者が簡単にアクセスできることから、クライアント間で一貫した体験を提供するまで、ウェブサーバは使いやすさを最重視して設計されている。
迅速な開発
複雑なビジネスロジックを分離することで、各チームは自分たちの専門分野に集中することができる。
つまり、バックエンドチームがビジネスロジックとモデルに焦点を当て、フロントエンドチームが対象プラットフォームのクライアントコードに焦点を当てることができる。
初期のプロトタイプはサーバと一つのクライアントにデプロイされ、ビジネスがスケールするにつれて、ビジネスロジックを維持したまま、ブラウザ、iOS、Android のアプリといった異なるプラットフォームを対象とすることができる。
構築済みインフラ
現在インターネットインフラは成熟している。つまり、プロトコル(HTTP/HTTPS)の標準化、主要なプログラミング言語は HTTP リクエストを送信するためのライブラリ等、インターネット技術を直接サポート、データ圧縮技術や暗号化などの組み込み最適化とセキュリティ、そして世界中の開発者やユーザーが情報を共有できる大規模なコミュニティエコシステムが存在する。
なお、HTTP プロトコル以外の通信方法が必要とされる状況も存在する。プロトコルはそれぞれ異なる特性を持っているため、使用状況によって最適なプロトコルを選ぶことがある。
例えば、HTTP プロトコルでは実現できないほどパフォーマンスが重要である一方でリソースの制限がある場合、UDP やオーバーヘッドの少ない TCP 接続で特定の最適化が施され、サーバ間通信に特化したようなカスタムプロトコルがそれ。
クロスプラットフォーム
クライアントのデバイスやオペレーティングシステムに関係なく、クライアントは標準化されたインターフェースを通じてサーバサイドのロジックにアクセスすることができる。
このクロスプラットフォームのサポートにより、ユーザーはウェブブラウザ、モバイルアプリケーション、デスクトップアプリケーションなど、さまざまなデバイスから同じ機能でアプリケーションにアクセスし、同期して操作できるため、ユーザビリティを向上させる。
アプリケーションサーバ統合
開発者向けサービスはブラックボックスとして提供されるため、開発者がサービスにアクセスするための最も便利な方法は何かということが問題になる。大量のソフトウェアサービスがその利便性のおかげでウェブ API を介して開発者に提供されている。そして、他の開発者向けにサービスを構築している場合、ウェブ API インターフェースが最も需要があるでしょう。
多くのソフトウェアサービスは、ウェブ API を通じて開発者に提供されている。
例えば、Instagram の API を使用すると、開発者は自分のアプリケーションから直接 Instagram の機能を利用できる。広く利用されるためには、ウェブ API が直感的で、開発者が簡単に利用できるように設計が必要。
他の開発者のためにサービスを提供する場合は、ウェブ API インターフェースを提供することが一般的。
これは、ウェブ API が広範で標準化されており、様々なプラットフォームやプログラミング言語で使用できるため。
静的サイトのウェブサーバ
企業のウェブサイト(静的サイト)
ウェブサイトはウェブサーバが一般的に使用される最も典型的なケース。
この場合、ウェブサーバの役割は至って明確。
例えば、企業のコーポレートサイトは、特定の情報をユーザーに一方向に伝えるためのウェブサイトを指す。この種のウェブサイトでは、主に企業のビジョン、ミッション、製品やサービスの情報、企業の組織構成、お問い合わせ方法等の情報を掲載する。
このような静的ウェブサイトは、情報が定期的に更新されることは少なく、一度ウェブサーバにアップロードされると、その内容は基本的に固定される。
サーバにアップロードされたウェブサイトへは、ユーザーはブラウザを通じて特定の URL を通じてアクセスする。ブラウザは HTTP リクエストを生成し、そのリクエストはウェブサーバに送信される。ウェブサーバは、リクエストに応じたリソースを返す。ウェブサーバソフトウェアはリクエストを処理するための設定を持っている。これらの設定は、管理者によって上書き可能。
例えば、ウェブサーバのエントリーポイントが www.example.com で、ディレクトリパスが /var/www/example.com/public に設定されているとする。
この設定では、すべてのファイルリソースへのアクセスが許可されている。ディレクトリパスはそのウェブサイトのコンテンツが物理的に保存されているサーバ内の位置を指す。
したがって、ブラウザが URL www.example.com/css/style.css にアクセスすると、ウェブサーバはディレクトリパスの /var/www/example.com/public と、URL の /css/style.css を組み合わせて、物理的には /var/www/example.com/public/css/style.css というパスのファイルを探す。そして、そのファイルをブラウザに送信する。
同様に、もしブラウザが www.example.com という URL だけを入力してウェブサイトにアクセスした場合、通常は /var/www/example.com/public/index.html というパスのファイル(ホームページとして慣例的に設定されている index.html)がブラウザに送信される。
ウェブサーバがブラウザからの HTTP リクエストを処理する方法の一部として、URL とサーバ内部のファイルパスを結びつけることがある。この処理は、クライアント(ここではブラウザ)がリクエストした特定のリソース(ここでは /css/style.css)をウェブサーバが見つけ出すための重要な手段。
ブラウザが URL(例えば、www.example.com/css/style.css)にアクセスすると、ウェブサーバはその URL を 2 つの部分に分解する。
・www.example.com: ドメイン名(またはエントリーポイント)で、特定のウェブサーバを指し示す。ドメインはDNSによってIPアドレスに変換され、サーバの位置を特定するために使用される。
・/css/style.css: リクエストされたリソース(この場合、CSS スタイルシート)の場所を表す。そのサーバ内のファイルパス
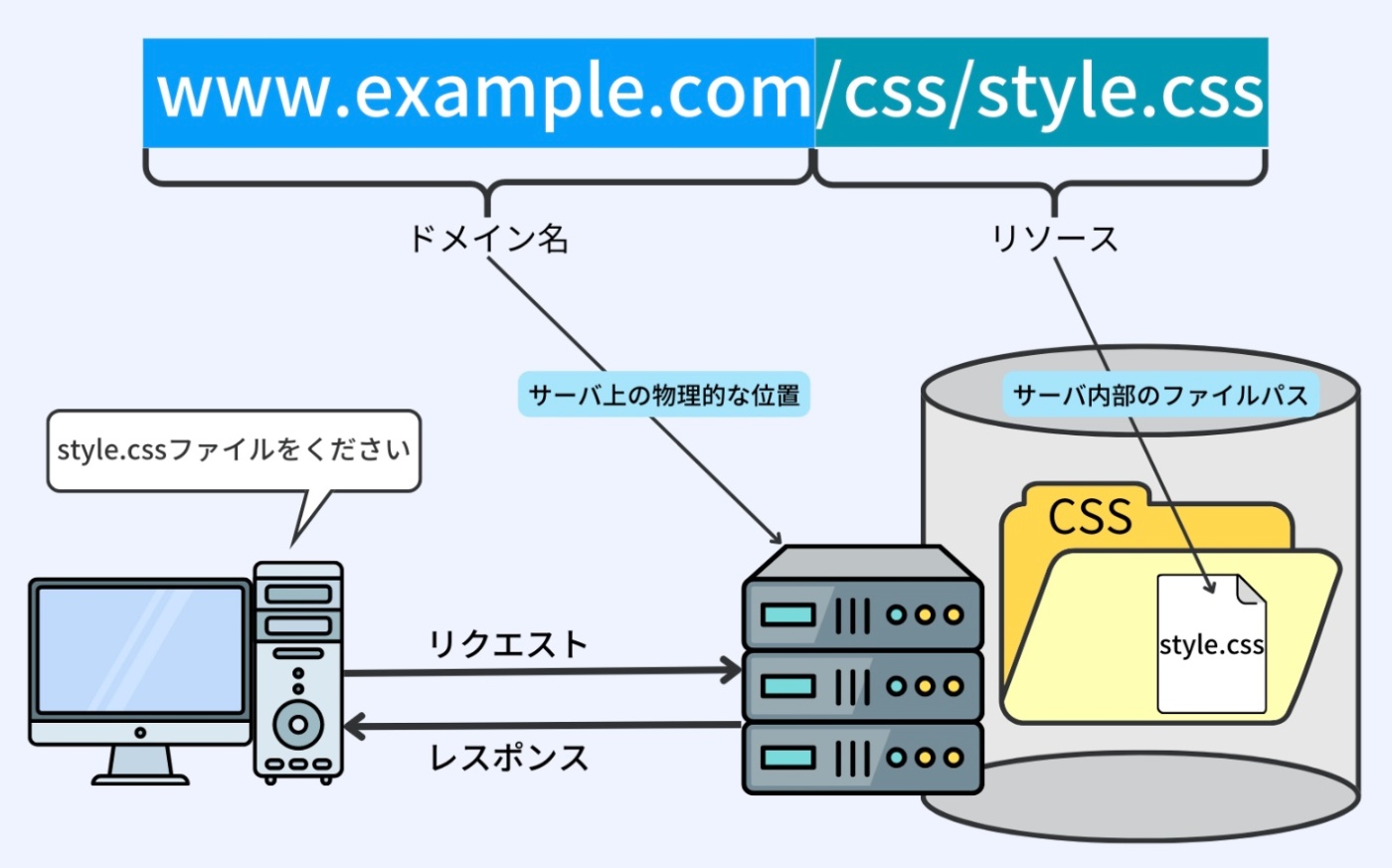
※https://recursionist.io/dashboard/course/33/lesson/1141 より画像引用
ウェブサーバには、www.example.com が指すディレクトリパス(例えば、/var/www/example.com/public)が設定されている。これはウェブサイトのコンテンツが保存されているサーバ上の物理的な位置を示す。
URL のリソース部分 /css/style.css は、このディレクトリパスに追加される。
したがって、ウェブサーバは物理的に /var/www/example.com/public/css/style.css というパスのファイルを探す。
このようにしてウェブサーバは、URL を元に内部のファイルシステム上の位置を特定し、リクエストされたリソース(ファイル)を見つけ出すことができる。そして、そのファイルの内容をブラウザに送信する。これが URL とサーバ内部のファイルパスを組み合わせるという仕組み。
Linux のファイルシステムの中では、Webサーバが即座にレスポンスできるように、HTML・CSS・JavaScript などの静的ファイルが「public」ディレクトリに格納されていることが一般的
企業のウェブサイトにおいては、HTML、CSS、JS ファイルや jpg/png/mp3/mp4 といったメディアファイルなど、全てのコンテンツファイルは public フォルダに格納されている。これにより、誰でもアクセスして閲覧することが可能となる。ブラウザにはこれらのファイルを表示する機能が組み込まれている。
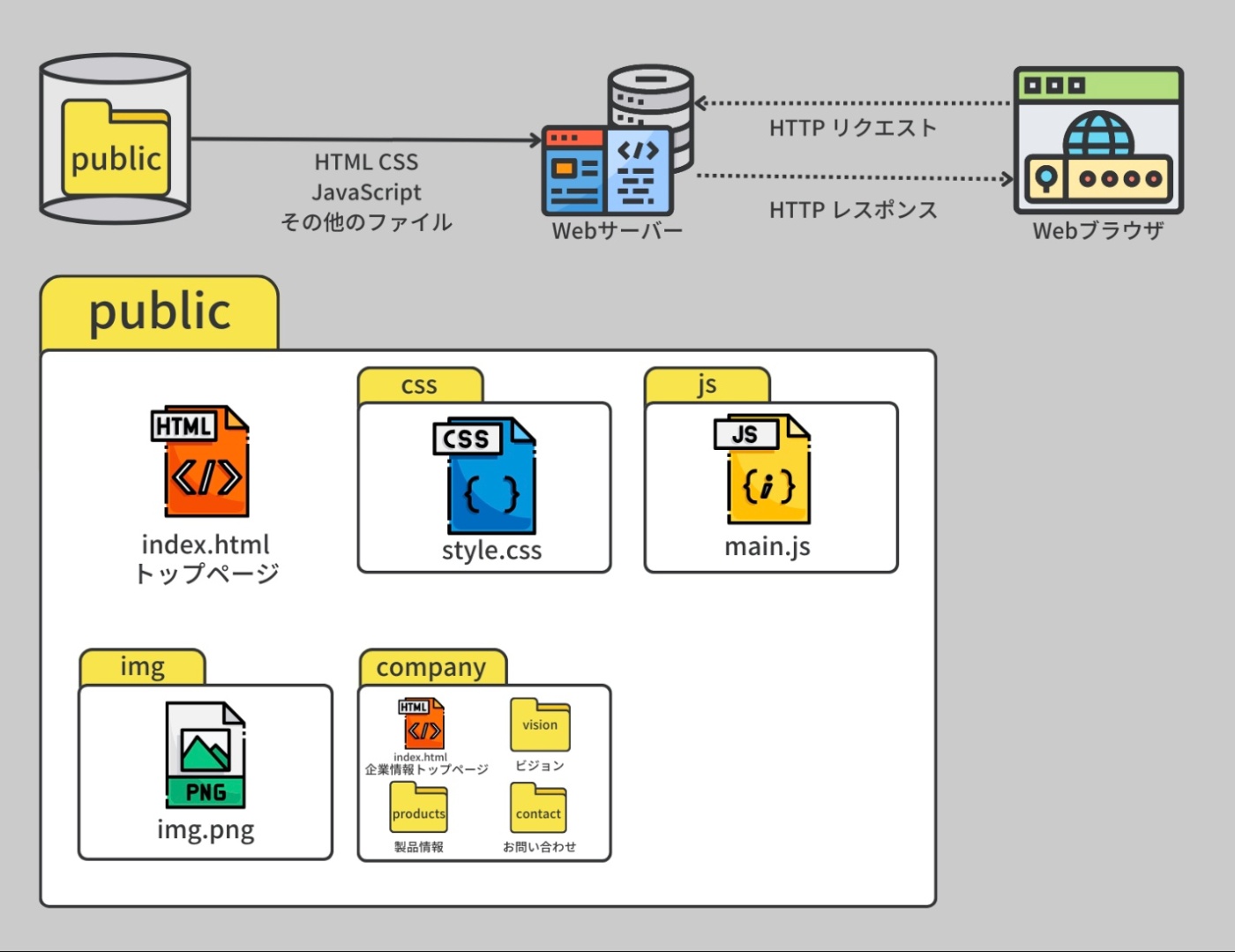
※https://recursionist.io/dashboard/course/33/lesson/1141 より画像引用
※同じサーバーを複数の企業や複数のウェブサイトで共有する場合
それぞれのサイト用に独立した publicフォルダ(または public_htmlなどの公開ディレクトリ)を複数用意し、個別に設定する。つまり、publicフォルダは1つではない。
ブロック・データ・ファイルの整理
・ブロック:ディスクにデータを読み書きするための最小単位(例:4KB、8KBなど)
・データ:ファイルの中身そのもの(文字列、画像、DBのレコードなど)
・ファイル:データのまとまり。OSのファイルシステム上の1つのエントリ
ディスクに保存されるのは「データ」であり、その保存単位が「ブロック」。
そして「ファイル」はそのデータの集合としてブロック単位で保存される。
物理的なディスクにデータを書き込む必要があるため、一定のサイズの塊(=ブロック)でしか扱えない
の。これは、ストレージデバイスのハードウェア構造や効率性に関係しています。
ディスク上ではデータは「ブロック単位」でバラバラに保存されている
OS(のファイルシステム)は、そのバラバラなブロックを集めて「1つのファイル」としてまとめて管理する
→ だからアプリケーションは「ファイル」というまとまりでデータを読み書きできる
なぜブロック単位になるのか?
理由①:物理的な制約(特にHDDの場合)
ハードディスク(HDD)は、中に「回転する円盤」と「読み書きヘッド」がある。
このヘッドは「セクタ」という最小単位ごとにデータを読み書きする。
このセクタが、一般的には512バイトや4096バイト(4KB)の固定サイズ。
つまり、「3バイトだけ書きたい」と言っても、実際には4KBまるごと読み書きしなきゃいけないというわけ。
理由②:効率性と耐久性(SSDの場合も)
SSDも内部的には「ページ」や「ブロック」と呼ばれる単位で読み書きする。
・読み出し単位 → 「ページ(例:4KB)」
・書き込みや消去単位 → 「ブロック(例:256KBや512KB)」
SSDでは「少しだけ変更したい」場合でも、一度大きな単位を消して書き直す必要がある。
理由③:OSやファイルシステムの設計が簡単になる
OSやファイルシステムは、ストレージが「等間隔の棚」みたいな構造だと管理しやすい。
「〇番目の棚にこのファイルの一部がある」というふうに、ブロック番号で管理すれば済む。
ブロックが使う容量は「ストレージ容量」に影響し、ファイル(特にサイズや数)は「CPU・メモリの負荷」にも影響を与える
ブロック単位での容量 ⇒ ストレージに影響
ストレージ(HDDやSSD)は「ブロック」という固定サイズの単位でしか読み書きできない。
(例)
ブロックサイズが 4KB のとき、ファイルが 1KB しかなくても、実際には 1ブロック=4KB が使われる(無駄な3KBが発生)
→ 内部断片化(internal fragmentation)と呼ぶ
つまり、小さなファイルがたくさんあると、実際のファイルサイズよりも多くのストレージ容量が使われる可能性がある
ファイルサイズ・数 ⇒ CPUやメモリに影響
ファイルを読み書きするには、OSが以下を処理する必要がある
・ファイルパスの解決(ディレクトリツリーの探索)
・inodeの取得と管理
・ファイルを開く・閉じる処理(open, close システムコール)
・キャッシュの管理
・データの整列やバッファリング
これらはすべて CPUやメモリの処理コストが発生する
(例)
大量の小さなファイルがあると、
・OSは毎回ファイルごとにinodeなどを管理
・ファイルオープン・クローズが頻発
・CPUやメモリの消費が大きくなる
非常に大きなファイルでも、読み込み・整形・メモリ展開時に多くのリソースが必要
| 要素 | ストレージへの影響 | CPU・メモリへの影響 |
|---|---|---|
| ブロックサイズ | 大きいほど空きが無駄になる(内部断片化) | ほぼ関係ない |
| ファイル数・サイズ | 多いとストレージ使用量は当然増える | 多いとディレクトリ管理やIO処理でCPU/メモリに負担 |
OSのファイルシステムとWebサーバのドキュメントルート
ファイルシステム全体
OS(たとえば Linux)のファイルシステムは、ルートディレクトリ / を起点に、階層構造になっている
/
├── bin/
├── etc/
├── home/
├── var/
│ └── www/
│ └── example.com/
│ └── public/ ← ここが Webサーバのドキュメントルート
└── ...
OS のファイルシステムは / を頂点とする大きなツリー構造となっている。
その中に Web サーバ専用に使われるディレクトリ(たとえば /var/www/...)がある。
Web サーバはその中の一部(たとえば /var/www/example.com/public)を「ドキュメントルート」として公開対象にする。
ドキュメントルートは、Webサーバ(Apache や Nginx)がクライアントからのリクエストに対応する公開対象ファイルを探しに行く起点となるディレクトリ
Webサーバ用に「公開用のトップディレクトリ」としてドキュメントルートがOSのファイルシステムの中の一部のパスとして割り振られる。
WebサーバーはHTTPリクエストを受け付けると、設定したドキュメントルートから指定されたパスへファイルを探しにいく。
リクエスト処理までの流れ
① ブラウザがHTTPリクエスト(例: GET /css/style.css)を送信
→ これは「このサーバーにある /css/style.css をください」という意味
② Webサーバー(ApacheやNginxなど)がそのリクエストを受け取る
③ Webサーバーはあらかじめ設定された DocumentRoot(例: /var/www/example.com/public) を基準にして、
DocumentRoot + リクエストパス = 実際のファイルパス
/var/www/example.com/public + /css/style.css
→ /var/www/example.com/public/css/style.css
④ そのパスにファイルが存在すれば、それをHTTPレスポンスとして返す。
⑤ ファイルが存在しなければ、404エラーを返す、またはアプリケーション側に処理を任せる(動的処理の場合)設定になっていることもある。
このような仕組みである理由
セキュリティのため、公開していいファイルだけを置く「ドキュメントルート」内だけを見に行くようになっている。
/etc/passwd など、絶対に公開してはいけないシステムファイルへのアクセスを防ぐため。
「アプリケーションサーバーがファイルを保存する」
「アプリケーションサーバーが保存している」という表現は、“そのアプリケーションの実行環境であり、責任を持って動作・管理している”という意味であり、
実際の物理ファイルは、当然ながらストレージに保存され、ファイルシステム上に存在している、というのが本当の構造
サーバーサイドのアプリケーション(PHP, Python, Java など)において、
・アプリケーションプログラムのファイル(=ソースコードや設定ファイル)は、物理的にはストレージ(HDDやSSD)上に保存されている。
・それらのファイルは OS のファイルシステムを介して管理される。
・「アプリケーションサーバー」がそれらのファイルを読み取り、処理し、動的にレスポンスを生成するという役割
サーバー用途でのLinuxの重要性
Linuxは多くのWebサーバー、アプリケーションサーバー、データベースサーバーなどで使われており、そのようなサーバーは一度に多数のクライアントからのリクエスト(HTTPリクエスト、DBアクセスなど)を処理する必要がある。
並行処理と並列処理の違い
| 処理の種類 | 説明 | 例 |
|---|---|---|
| 並行処理(Concurrency) | タスクを切り替えながら、見かけ上同時に複数のタスクを処理 | 1つのCPUで複数のリクエストを切り替えながら処理する |
| 並列処理(Parallelism) | 実際に同時に複数のタスクを同時処理 | 複数のCPUコアで別々のリクエストを同時に処理する |
重要な理由
① クライアントからの多数リクエストを処理するため
例えばWebサーバー(ApacheやNginx、Node.jsなど)は、同時に何百・何千ものリクエストを処理しなければならない。
リクエストの処理が遅れると、ユーザーの待ち時間が増え、UXが悪化する。
② ハードウェア性能を最大限に活かすため
マルチコアCPUが一般的になっている今、並列処理を活用することで、パフォーマンスを向上させることができる。
Linuxはマルチスレッドやプロセスの仕組みを使って、これをうまく制御している。
③ バックグラウンド処理やバッチ処理の効率化
サーバーはWebリクエストだけでなく、定期的なバッチ処理、ログのローテーション、ファイル圧縮などのバックグラウンド処理も行なう。
これらを非同期・並行に処理することで、サーバー全体の応答性が高まる。
共通のリソースを効率よく利用する重要性
サーバーが大量のリクエストを捌きながら自身の処理も行うためには、CPUやメモリ、I/O(ディスク・ネットワーク)などの「共通リソース」をいかに無駄なく効率よく使うかが極めて重要
共通リソースの種類
| リソース | 具体例 |
|---|---|
| CPU | リクエスト処理、暗号化処理、アプリのロジック実行 |
| メモリ | 各プロセスやスレッドの作業領域、キャッシュなど |
| ディスク | ログ書き込み、ファイル読み込み |
| ネットワーク | クライアントとの通信、外部APIとの接続 |
| DB接続 | 接続プールを使い複数リクエストで共有 |
効率よく使うことが重要な理由
① 無駄が多いとボトルネックになる
たとえば、全リクエストがディスクI/O待ちになるとCPUは暇になる。
逆に、CPUが1つの重い処理で占有されると他の処理が止まる。
② 大量リクエストに耐えられない
無駄にスレッドやプロセスを作るとメモリ不足になる。
1リクエストごとに新しいリソースを確保していたら、スケーラビリティが下がる。
③ 自身の処理と外部からのリクエストを両立するには工夫が必要
サーバー自身もログ出力やバックグラウンドジョブ、セキュリティチェックなどの自律的な処理を持っている。
それをやりつつ、リクエスト応答も落とさないためには、非同期処理、リソース共有、適切なスケジューリングが必要。
Webサーバーの効率的リソース活用
| 処理 | 効率化の仕組み |
|---|---|
| HTTPリクエスト受付 | 非同期I/O(epollなど) |
| DBアクセス | コネクションプール(再利用) |
| ログ書き込み | バッファリング、非同期書き込み |
| ファイル送信 | カーネル空間での送信(sendfile) |
| リクエスト分散 | プロセスやスレッドのロードバランス |
サーバーは「自身の処理」+「大量リクエスト」というマルチタスクをこなす必要があるため、共通リソース(CPU、メモリ、I/Oなど)を無駄なく効率的に使うことが不可欠。
これこそが、並行処理/並列処理+リソース管理(スレッドプール、非同期I/O、キャッシュ、制限付きキューなど)がLinuxサーバーで重視される理由。
Linuxにおける内部実装の特徴(プロセスとスレッドの関係)
clone() システムコール
Linuxでは、プロセスとスレッドの両方を作るのに clone() という低レベル関数を使う。
・clone() に渡すフラグによって、どこまで共有するかを細かく制御可能
・fork() は clone() を使ったラッパーで、メモリ非共有の完全な子プロセスを作る
・pthread_create() は clone() を使って メモリ共有のスレッド を作る
マルチスレッドとマルチプロセスの違いと使い分け
| 項目 | マルチプロセス | マルチスレッド |
|---|---|---|
| メモリ空間 | 独立 | 共有 |
| 安全性 | 高い(他の影響を受けにくい) | 低い(競合注意) |
| 通信コスト | 高い(IPCが必要) | 低い(変数をそのまま使える) |
| 作成/破棄コスト | 高い | 低い |
| 用途 | 安全性重視(Apacheなど) | パフォーマンス重視(Nginxなど) |
実用例
Webサーバー(Apache vs Nginx)
・Apache:マルチプロセス方式(各リクエストに対してプロセスやスレッドを割り当てる)
・Nginx:イベントループ + 少数スレッド(非同期I/Oによる高効率処理)
まとめ
| 要点 | 内容 |
|---|---|
| プロセス | 完全に独立した実行単位。安定性が高いが重い |
| スレッド | プロセス内での軽量な並行実行。効率がよいが、共有メモリの管理が難しい |
| Linux内部 |
clone() によってプロセスもスレッドも実現している |
| 使い分け | 安全性重視ならプロセス、性能重視ならスレッド(もしくは非同期) |
Linuxにおける並行処理の仕組み
1. プリエンプティブ・マルチタスク
Linuxカーネルは各プロセス/スレッドに CPU時間を短時間ずつ割り当てて切り替える。
これにより、実際は1つのCPUでも「同時に動いているように見える」並行処理が可能になる。
2. スレッドによる並行処理
pthread や std::thread(C++)などでスレッドを作成すれば、複数のタスクを並行して処理できる。
3. 非同期I/O(イベントループ)
非同期にリクエストを受け付け、I/Oを待っている間は他の処理に回る。
代表例:select, poll, epoll(高効率イベント通知)
※Nginx や Node.js がこのモデルを採用している
Linuxにおける並列処理の仕組み
1. マルチプロセッシング(MP)
Linuxカーネルが 複数のCPUコアにタスクを割り当てる。
例:Webサーバーがリクエストごとにワーカープロセスを生成して並列に処理
2. マルチスレッディング
スレッドが異なるCPUコアで同時実行されれば並列処理になる。
例:動画変換ソフトなどの重い処理を複数スレッドで同時進行
3. SMP(対称型マルチプロセッシング)
Linuxは複数CPU(コア)を均等に扱えるOS(SMP対応)。
タスクをどのコアに割り当てるかはスケジューラが自動的に判断。
並行処理と並列処理は両立する
実際のLinuxシステムでは、
・並行処理(多くのリクエストをスムーズに捌く)
・並列処理(重い処理を同時に走らせる)
の両方を 組み合わせて使うことがほとんど。
Webサーバーの例
| 処理 | 並行 or 並列 | 内容 |
|---|---|---|
| 複数リクエストの受信 | 並行処理 | epollでノンブロッキングに受信 |
| データベースアクセス | 並行処理 | 非同期またはコネクションプール |
| 圧縮処理 | 並列処理 | マルチスレッドで並列にGzip圧縮 |
開発時の意識ポイント
| ポイント | 説明 |
|---|---|
| 競合状態の回避 | 並行・並列どちらでも共有データへの同時アクセスは危険。排他制御(ミューテックス、セマフォ)が必要 |
| スレッドセーフ設計 | 並列実行に備えて、変数の扱いを安全に設計する必要がある |
| リソースの使いすぎに注意 | 並列処理=何でも高速化ではなく、CPUやメモリの制約を超えると逆効果 |
| スケジューラと親和性 | Linuxのスケジューラは公平性・効率を両立させるが、設計によってはうまく機能しないこともある |
※スレッドセーフとは、複数のスレッド(処理の単位)が同時にアクセスしても安全に動作すること
複数のスレッドが同じ変数やデータを同時に読み書きすると、データが壊れたり(不整合が起きる)、プログラムが予期せぬ動作をしたり、クラッシュしたり、という問題が起こる。
※スレッドセーフにする方法
・排他制御(mutexやロック)を使って、同時に一つのスレッドだけが操作できるようにする
・原子操作(atomic operation)を使って、一連の操作を中断できない形で実行する
・スレッドごとにデータを分ける(共有しない)
動的サイトのウェブサーバ
単純な静的ファイルを提供するウェブサイトには、その使い勝手に多くの制約が存在する。
具体的には、コンテンツを編集できるのは、対象となるリソースファイルに直接アクセス可能な人のみとなる。
Wiki 型ウェブページ(動的サイト)
動的サイトでは、コンテンツはサーバ側でリアルタイムに生成される。
WordPress のようなコンテンツ管理システムや、Wix や Squarespace のようなウェブサイト作成サービスを活用することで、技術的な知識がない人でもこのようなウェブサイトを操作することが可能。
例えば、動的なウェブサイトの一種であるウィキペディアのような Wiki 型のウェブページは、ウェブ上のコンテンツの作成と編集を多数のユーザーが行なうことを可能にしている。Wiki 型ウェブページは、ユーザーが自由に情報を追加、編集、削除することが可能。
これにより、ユーザーはコミュニティとして情報を共有、検討し、改善することができる。ウィキペディアのような大規模な Wiki 型ウェブサイトでは、世界中の数百万人のユーザーが共同でコンテンツを作成している。
Wiki 型のウェブページをはじめとする動的サイトでは、ウェブサーバは HTTP リクエストを受け取り、そのリクエストをウェブアプリケーションのエントリーポイントに渡す。そしてウェブアプリケーションは、そのリクエストを解析し処理する。
例えば PHP を使用する場合、エントリーポイントは通常ルートに配置される index.php になる。
ウェブアプリケーションは URL を特定の関数にマッピングし、その関数を呼び出す。これらのプロセスをルーティングと呼ぶ。
ルーティングは、特定の URL パスがアプリケーション内のどの機能(関数やメソッド)に対応するかを定義するもの。URL(リクエストされたパス)と、実行すべき処理(関数やコントローラーなど)を結びつける仕組みのこと。
=「URLパス+HTTPメソッド」と「Controllerの特定のメソッド」を結びつける
例えば、/users の URL がある場合、この URL を「ユーザーリストを表示する関数」にマッピングすることができる。
これらの関数はリクエストデータ、つまりデータやクッキーを含むリクエストのボディを解析する。
つまり、HTTP リクエストのボディ(つまり、送信されるデータ本体)を読み取り、適切な形式(通常はオブジェクトや連想配列など)に変換するプロセスを指している。
これにより、アプリケーションは送信されたデータを解析し、それに基づいて適切なアクション(ユーザー情報の更新、新規商品の登録など)を実行できる。
リクエストの処理が終わると、生成したリソース、例えば HTML コンテンツや JSON データ、あるいはダウンロード可能なファイルなどをクライアントに返す。
ウェブアプリケーションはページ生成に必要なデータを保存するため、データベースに接続することが一般的。
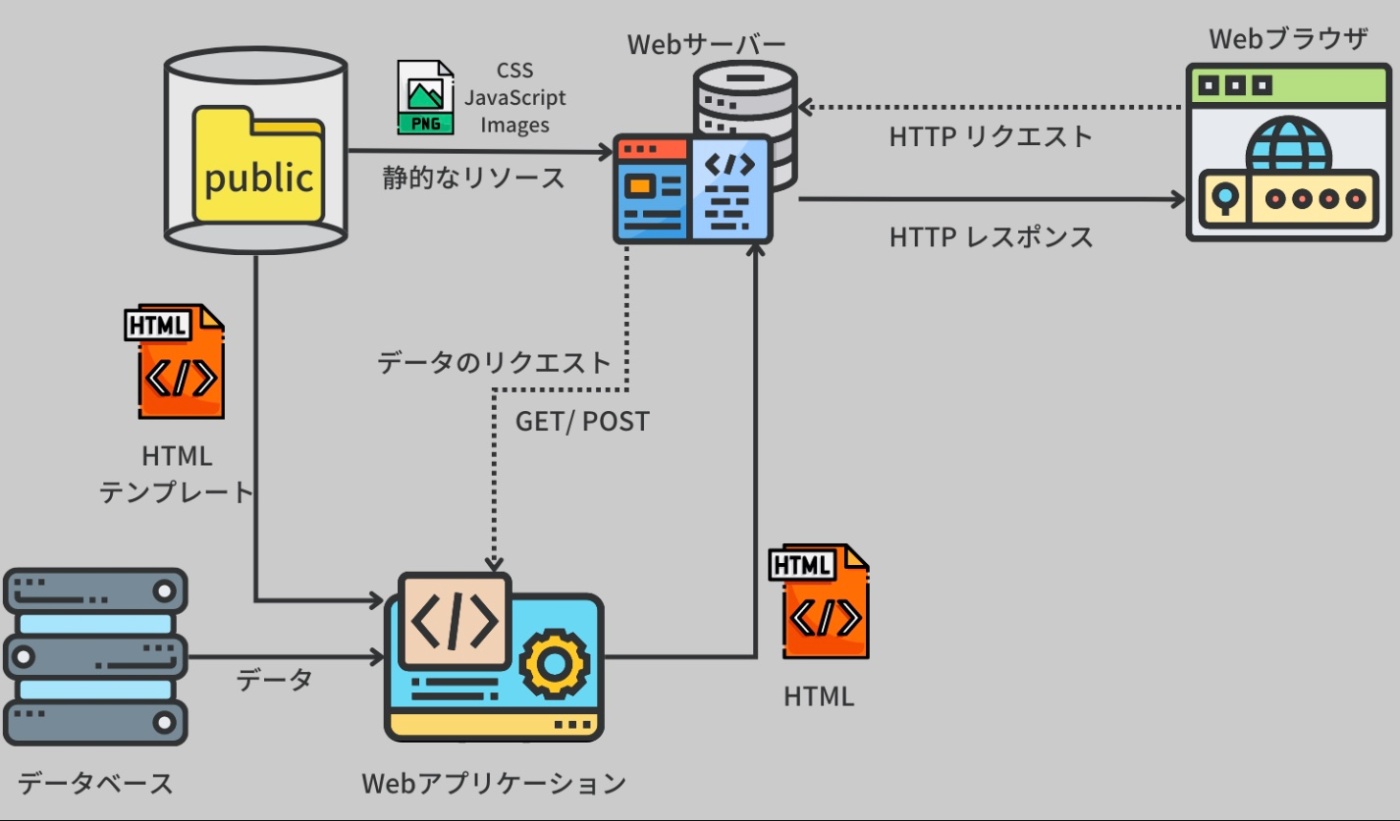
※https://recursionist.io/dashboard/course/33/lesson/1142 より画像引用
静的ウェブサイト
コンテンツ(HTML、CSS、JavaScript、画像、その他のメディアファイルなど)は直接ウェブサーバ上に保存され、ユーザーのリクエストに基づいてそのままの形で配信される。
そのため、静的ウェブサイトの内容は、直接ファイルを編集しない限り変更されない。
動的ウェブサイト
ウェブサーバはユーザーからの HTTP リクエストをウェブアプリケーションに渡し、ウェブアプリケーションがリクエストに応じてページの内容を動的に生成する。
ウェブアプリケーションは、データベースから情報を取得したり、ユーザー入力を処理したりすることができる。
動的ウェブサイトの場合、メディアファイルなどの静的なリソースはウェブサーバに保存されることが一般的だが、それらのリソースは動的に生成された HTML ページの一部として配信される。
一方、ユーザーが入力したデータやデータベースから取得したデータなど、動的に変更される情報は、ウェブアプリケーションによって処理される。
動的サイトの典型的な例: Wiki ページ
Wiki ページはコミュニティ全体で作成・編集され、すべてのユーザーがそのコンテンツに対して貢献することができる。Wiki には編集用のページが設けられており、通常は WYSIWYG(What You See Is What You Get)形式のエディタが使用される。
これらのページのフォームは HTTP POST メソッドを用いてウェブサーバにリクエストを送信する。
ウェブアプリケーションはそのリクエストを処理し、キーと一緒にデータベースにデータを保存する。
新しいページ(つまりキーを含む URL)にユーザーがアクセスすると、ウェブサーバはデータベースからデータを取得し、そのデータを処理して HTML ページに変換する。
このような動的なウェブサイトは、クライアント、サーバ上のバックエンドプログラム、そしてデータベースの 3 つの要素から成る三層アーキテクチャを採用している。
クライアントがプレゼンテーション層を、サーバアプリケーションがロジック層を、データベースがデータ層をそれぞれ担当。このように各層が役割を持つことで、柔軟なウェブサイトの運用が可能になる。
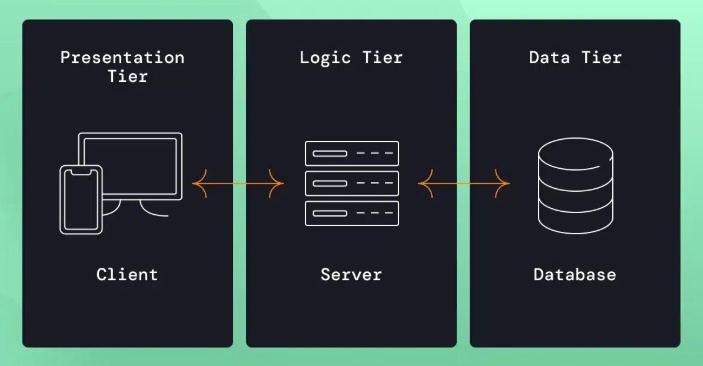
クライアント → Webアプリケーションへのリクエスト処理の流れ
1. クライアント(ブラウザやスマホアプリ)がリクエストを送る
2. Webサーバー(Nginx や Apache)が受け取る(通常 ポート80 or 443)
3. Webサーバーはリバースプロキシとして、ポート番号や設定に基づき、適切なアプリケーションサーバー(例: Node.js, Laravelなど)に転送する
4. アプリケーションサーバーは、受け取ったリクエストのURLなどを解析して、ルーティング設定に基づいて対応する関数(コントローラーなど)を実行
5. 関数は、リクエストボディ・クッキー・パラメータなどを処理し、結果を生成(HTML, JSONなど)
6. アプリケーションサーバーがレスポンスをWebサーバーへ返す
7. Webサーバーがそのレスポンスをクライアントに返す
| 自分の表現 | 解説 |
|---|---|
| Webサーバーが最初に受け取る | ✔️ Webサーバーが HTTP リクエストをポート 80/443 で受け取る |
| ポート番号をWebサーバが認識 | ✔️ proxy_passなどの設定により、どのアプリに転送するかを判断 |
| 該当のアプリケーションサーバに送る | ✔️ 該当アプリのポート(3000、8000など)にリクエストを中継 |
| URLを元にマッピングした関数を呼び出す | ✔️ ルーティングによってURLに対応する関数が実行される |
| リクエストデータを関数に渡す | ✔️ 関数はリクエストの内容(本文・パラメータなど)を受け取る |
| 関数が処理し、レスポンスを返す | ✔️ 処理結果(HTML、JSONなど)を作ってWebサーバーを経由して返却 |
Webサーバのポート
ポート 80 や 443 はWebサーバー自身がリクエストを受け付けるためのポート
ポート番号は、「どのアプリケーション(プロセス)に通信を渡すか」を識別する番号。
一つのサーバー(IPアドレス)上で、複数のサービス(Web、メール、SSHなど)を動かせるのは、それぞれが異なるポートを使うため
ポート番号は、OSレベルで「受信先アプリケーション」を選ぶための番号
具体的には、OSはネットワーク通信を受け取ると、「どのポートに届いたか」を見て、
そのポートを バインド(bind) して待機していたアプリケーションに渡す。
Webサーバーはどうやって「どのアプリケーションサーバのポートに転送するか」を判別するのか?
◎ポート番号の判別はWebサーバーの設定によって決まる
Webサーバーがリクエストを受け取った後、
受け取ったURLのパスやホスト名(ドメイン名)などの情報を元に、
どのバックエンドのアプリケーションサーバーに渡すか(=どのポートに転送するか)を事前に設定ファイルで決めている。
具体的な仕組み
① Webサーバーの設定ファイルにルールを書いておく
② URLのドメインやパスに応じて振り分け
③ 設定は柔軟にできる
Webサーバーは受け取ったリクエストの内容(URLのパスやドメイン)を見て、自分の設定に照らし合わせ、転送先(ポート番号)を決定する。
そのため、「リクエストからポート番号を判別する」のではなく、「リクエスト内容を元に設定ファイルのルールを使って転送先ポートを決めている」
アプリケーションサーバはHTTPリクエストをどのように認識して、どのようにルーティングにつなげるか
全体の流れ(概略)
① クライアント(ブラウザ)がHTTPリクエストを送信
② Webサーバー(Apache/Nginx)が受け取り、アプリケーションサーバーに転送
③ アプリケーションサーバーがリクエストの内容(ヘッダ・ボディ)を解析
④ ルーティング設定に基づいて、適切な処理(関数 or コントローラ)を呼び出す
例:Laravel
① HTTPリクエストは「文字列」として届く
HTTPリクエストは、TCP接続を通じてアプリケーションサーバーに「ただの文字列」として届きます。
POST /login HTTP/1.1
Host: example.com
Content-Type: application/json
Content-Length: 53
{
"email": "user@example.com",
"password": "pass123"
}
② アプリケーションフレームワークがパース(解析)する
ここで、フレームワーク(Laravel)のHTTPリクエストパーサーが登場する。
→ Laravel:\Illuminate\Http\Request クラスが受け取って処理
フレームワークがやること
・HTTPメソッド(GET, POST など)の抽出
・パス /login の抽出
・ヘッダ(Content-Type, Authorizationなど)のパース
・ボディ(フォーム、JSON、マルチパートデータ)のパース
・クッキーの取得
・セッションIDの抽出など
→ これらを全部、オブジェクトのプロパティとして整理してくれる
サーバーサイドのフレームワーク(Laravel、Express、Flaskなど)は、受け取ったHTTPリクエストの生データ(文字列)を解析して、「リクエストオブジェクト」を作成し、必要な情報をプロパティとして整理する。
=バラバラな文字列のかたまり(メソッド、ヘッダー、ボディなど)を構造化された1つのオブジェクトにまとめてくれるのが、フレームワークの役割
③ ルーティングにマッチングさせる
フレームワークは、URLとHTTPメソッドに対応するルーティングテーブル(定義)を持っている。
・POST /login にマッチ → AuthController@login() 関数を呼び出す
・GET /users/42 → UserController@show(42)
このとき、ルーティングパターンの定義に一致するかを確認し、マッチした関数(またはメソッド)を実行する
④ 関数にデータを渡す
マッチした関数には、以下のようなパース済みのデータが引数やオブジェクトとして渡される
・リクエストボディの中身(例:JSONデータ)
・URLのパラメータ(例:/users/42 の 42)
・クエリパラメータ(例:?page=2)
・ヘッダー情報
・セッション/クッキー情報
まとめ
① HTTPリクエストは文字列として届く
② フレームワークがこれをパースして、構造化したリクエストオブジェクトに変換
③ ルーティング情報と照らし合わせて、関数やコントローラを実行
④ その関数に、パース済みデータが渡される
Eコマースのウェブサーバ
Amazon や eBay といった E コマースサイトのようなユーザーが購入する商品を公開するような動的ウェブサイトの開発は、より複雑なプロセスを伴う。
これは各ユーザーが個別のデータを持つためで、例えば購入履歴、注文状況、請求明細、お気に入りリストなどがそれにあたる。
これにより、ユーザー認証とセキュリティが重要な要素となる。
さらに、アプリケーションは管理者、編集者、通常のアカウントといったユーザータイプを区別する必要がある。
また、E コマースアプリケーションはしばしばウェブ API を通じてサードパーティのサービスに接続することがある。
例えば、Stripe や Paypal のような全ての支払い処理インフラを持つ支払いゲートウェイが必要になることもある。
さらに、サプライチェーン管理、財務・会計、データ分析といった機能を提供する外部の ERP(Enterprise Resource Planning)ソフトウェアとの連携も必要となることもある。
また、ユーザーが Google、Facebook、Twitter などのサービスを通じて登録やログインを行なうことも視野に入れる必要がある。
このような視点から見ると、E コマースサイトのようなウェブサーバは他の複数のサービスを提供するサードパーティサーバのクライアントとも言える。
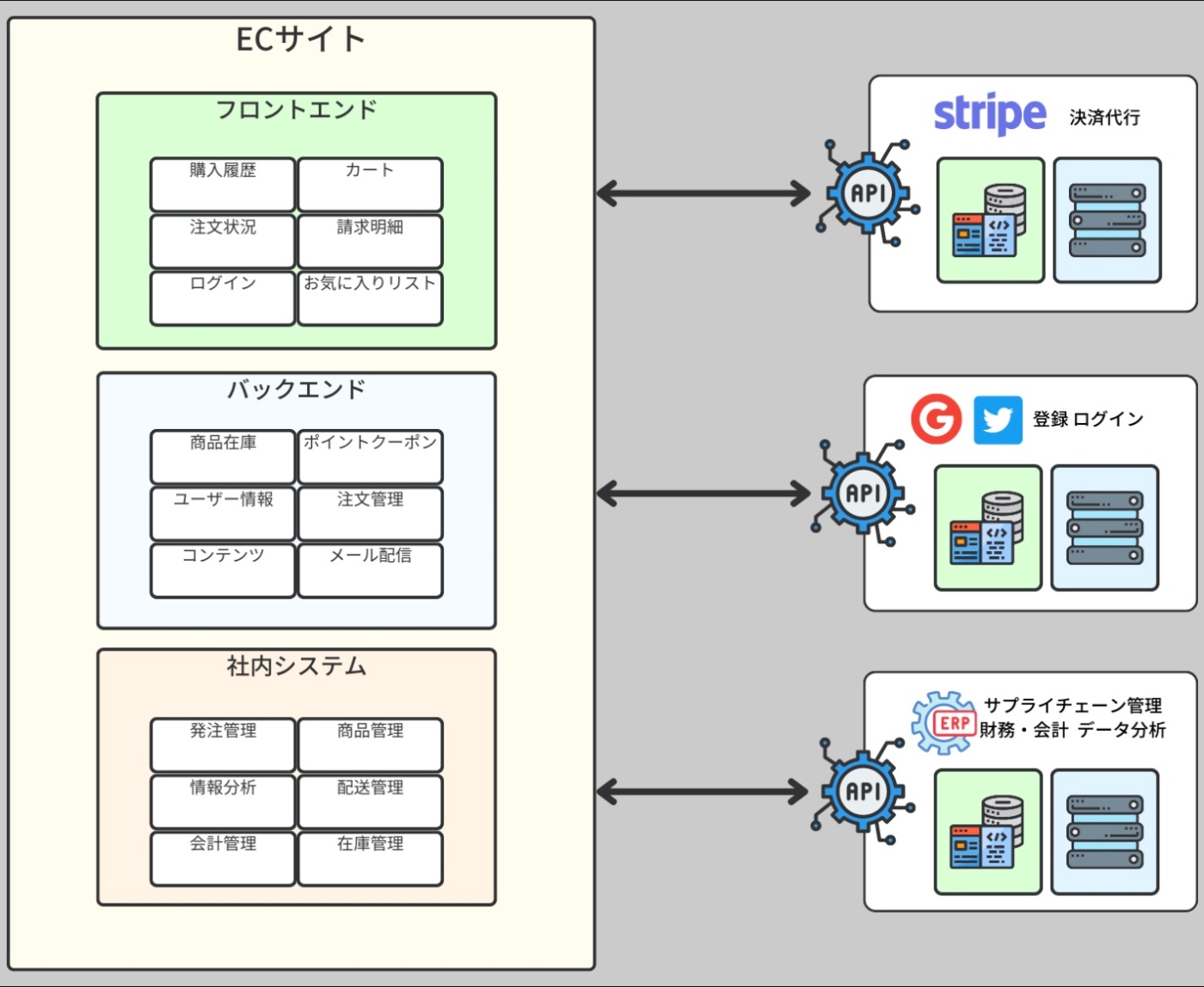
※https://recursionist.io/dashboard/course/33/lesson/1143 より画像引用
SNSのウェブサーバ
大規模なソーシャルネットワーキングサービス(SNS)である Facebook や Twitter のようなウェブサーバは、数億人のユーザーに対応する必要がある。
SNS は複数のターゲットプラットフォーム向けにクライアントアプリケーションを提供する。
これにはウェブブラウザ、iOS、Android、デスクトップ、さらにはスマートデバイスなどが含まれ、すべてが同じサーバに接続する。
こうした SNS では、ライブデータの同期をサポートするウェブソケットのような双方向データストリームを用いたり、ライブビデオやグループチャットのような追加機能を提供したりすることがある。
高性能なハードウェアを備えたウェブサーバは、一度に数千のリクエストを処理することができる。
しかしながら、大規模で人気のある SNS では、その何百倍もの同時接続が必要になる。
ウェブサーバのスケーリング
このような状況に対処するために、ウェブサーバのアーキテクチャを大規模に拡張する必要がある。
こういったハードウェアのアップグレードすることを、垂直スケーリング(vertical scaling)と呼ぶ。ハードウェアのアップグレードには非常にコストがかかり、上限がある。
このような垂直スケーリングによる限界を乗り越えるには、水平スケーリング(horizontal scaling)という手法を取ることができる。
つまり、サーバのハードウェアをアップグレードするのではなく、サーバノードを増やすことで対応する。
その実現方法の一つとして、ウェブサーバをリバースプロキシに変換するという手法がある。
リバースプロキシは、受け取ったリクエストをバックエンドのサーバノードの一つに転送し、そこでリクエストを処理する。リバースプロキシはバックエンドサーバのリストを保持し、ラウンドロビンなどのアルゴリズムを適用して負荷を均等に分散する(ロードバランシング(load balancing))。
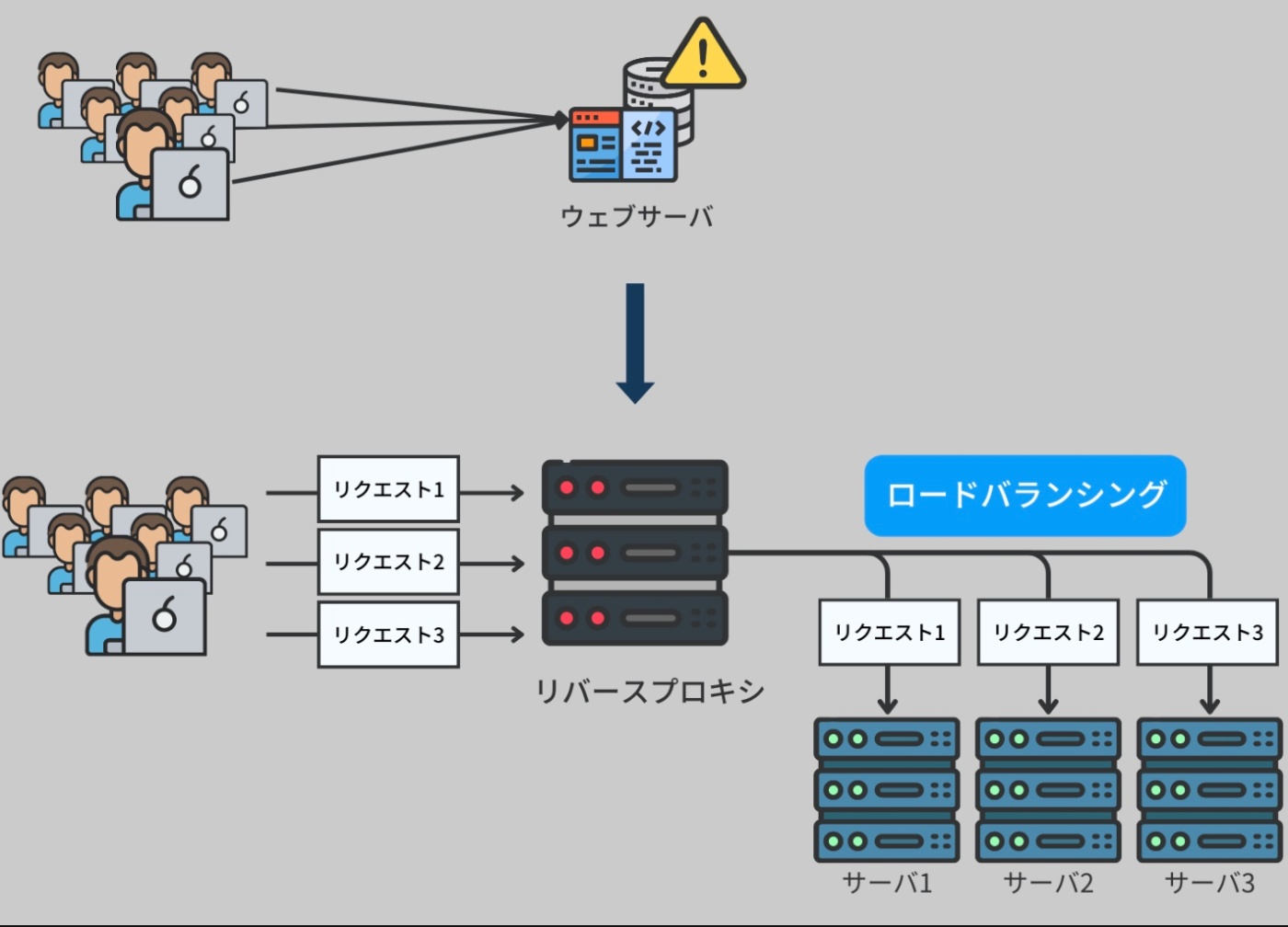
※https://recursionist.io/dashboard/course/33/lesson/1144 より画像引用
水平スケーリングが適用されたウェブサーバ環境では、各サーバがリクエスト処理に必要な全く同じコードを含んでいる。静的ファイルリソースについては、CDN(Content Delivery Networks:コンテンツデリバリーネットワーク)を使用することで、バックエンドの負荷をさらに減らすことができる。CDN は、ユーザーに近い場所に静的ファイルをキャッシュするサーバのことを指す。
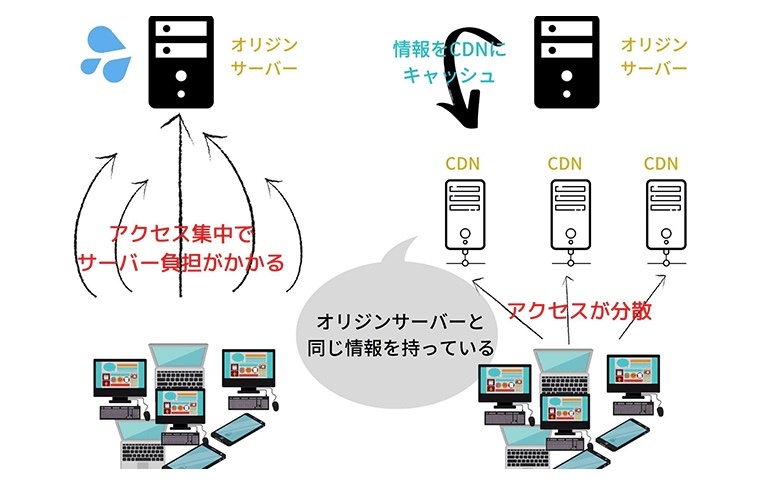
※https://digital-marketing.jp/seo/what-is-cdn/ より画像引用
リバースプロキシ = Webサーバ(Nginx / Apache)
・クライアントからのHTTPリクエストを一括で受け取る
・中身を見て、どのバックエンドに渡すか決定する(ロードバランシング)
・各アプリケーションサーバにリクエストを転送
・アプリケーションサーバのレスポンスをまとめてクライアントに返す
これを「リバースプロキシ兼ロードバランサ」として動かす
Web サーバ自身をリバースプロキシとして使う理由
・Nginx や Apache などの Web サーバは、リバースプロキシとしての機能も持っている
・わざわざ専用の別サーバを用意せずとも、Nginx を設定するだけで水平スケーリングが可能になる
・インフラ構成をシンプルに保てる
SNSのウェブサーバ
データベースのスケーリング
すべてのサーバは同じデータにアクセスする必要があり、また、サーバの負荷を軽減するためにデータベースにも水平スケーリングを適用する必要がある。アプリケーションによっては、データベースからの読み取りを増やすか、データベースへの書き込みを増やす必要があるかもしれない。
SNS では、読み込みが書き込みよりもずっと多いことが一般的。
このため、読み取りを多数のデータベースサーバに分散する必要があり、そのためにはマスタースレーブレプリケーションと呼ばれる技術が適用できる。ここでは、書き込みが行われるデータベースがマスターデータベースとなり、そのデータが複製されてスレーブデータベースに伝播する。
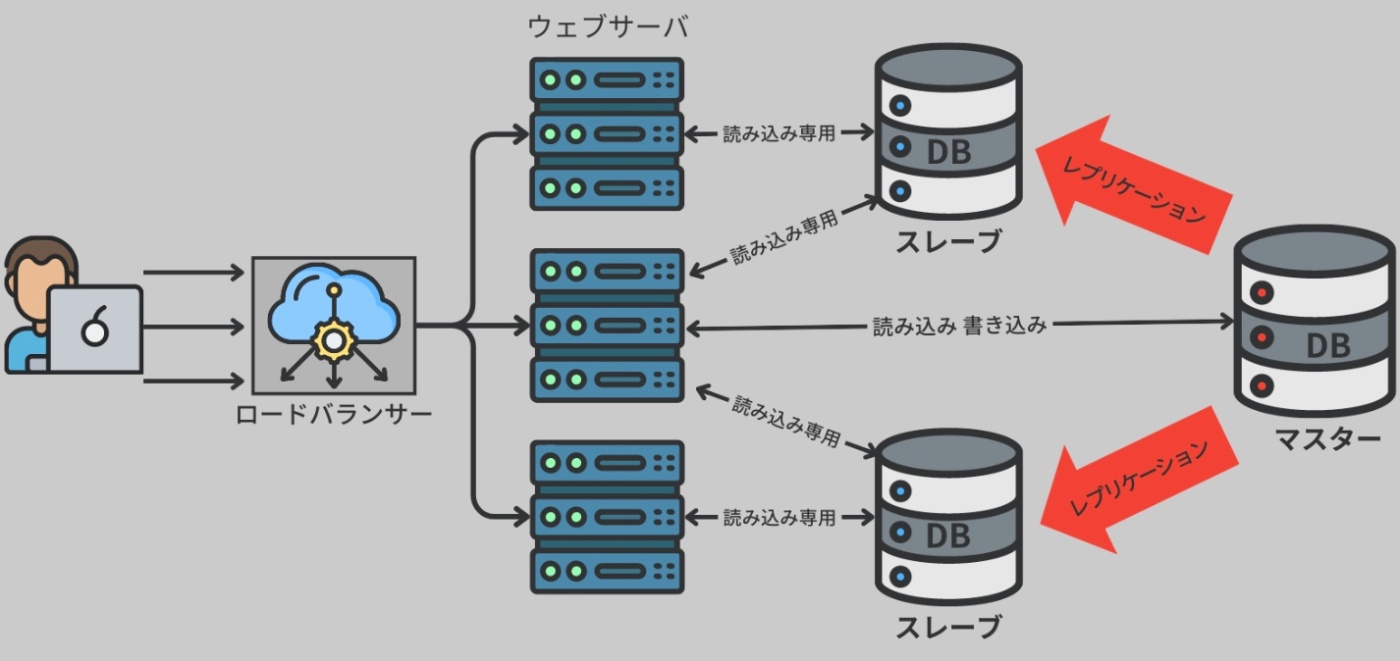
※https://recursionist.io/dashboard/course/33/lesson/1144 より画像引用
このような例では、ウェブサーバのアーキテクチャはより複雑になる。
サーバネットワークをスケーリングする際には、多くの利点と欠点を考慮する必要があり、アプリケーションの要件に基づいて様々な戦略が検討される。
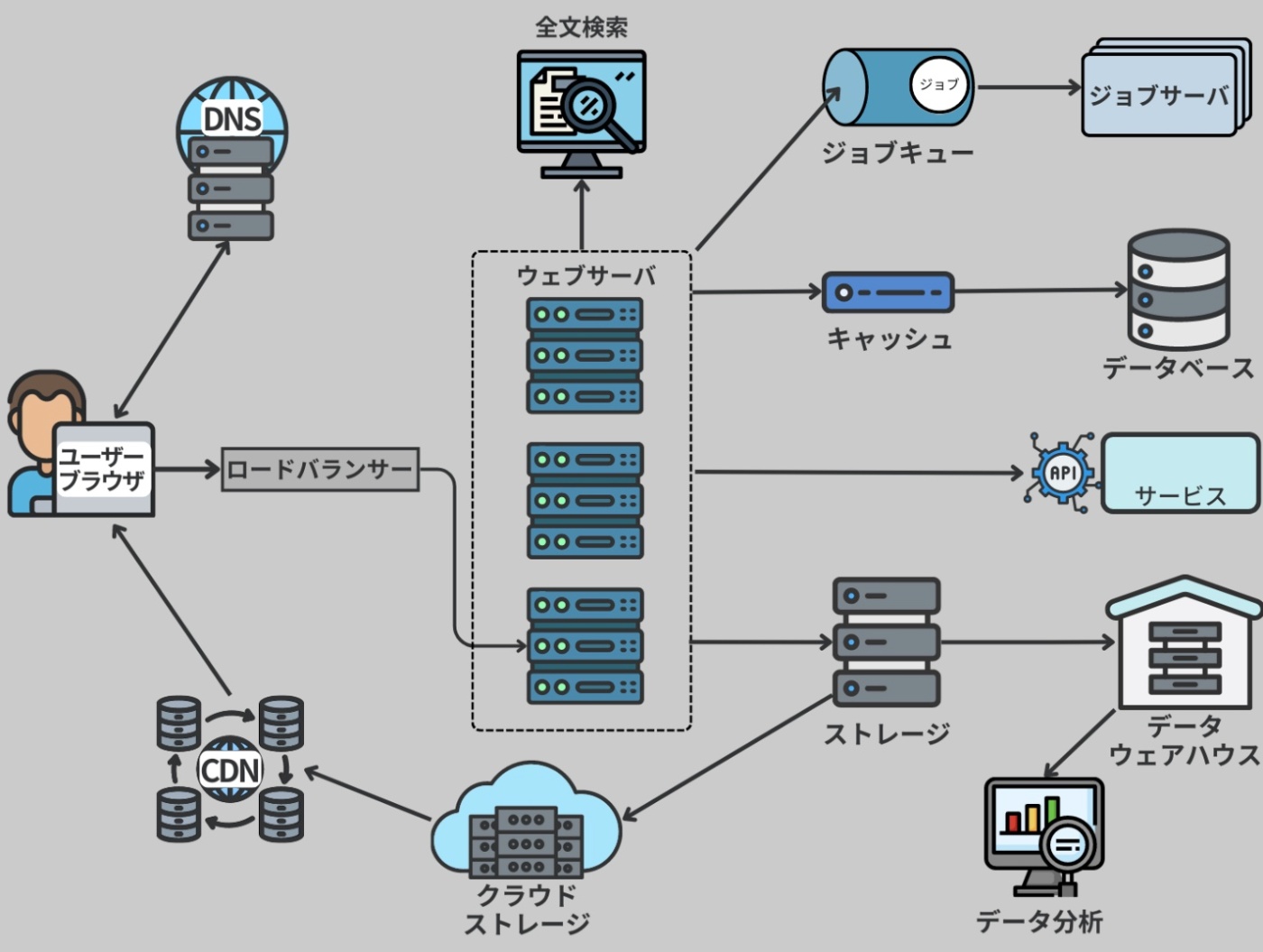
※https://recursionist.io/dashboard/course/33/lesson/1144 より画像引用
HyperText Transfer Protocol(HTTP)
インターネット上での通信のために最も一般的に使用されるプロトコル。
これは、クライアントとサーバがウェブを介して情報をやり取りするための手段を提供する。
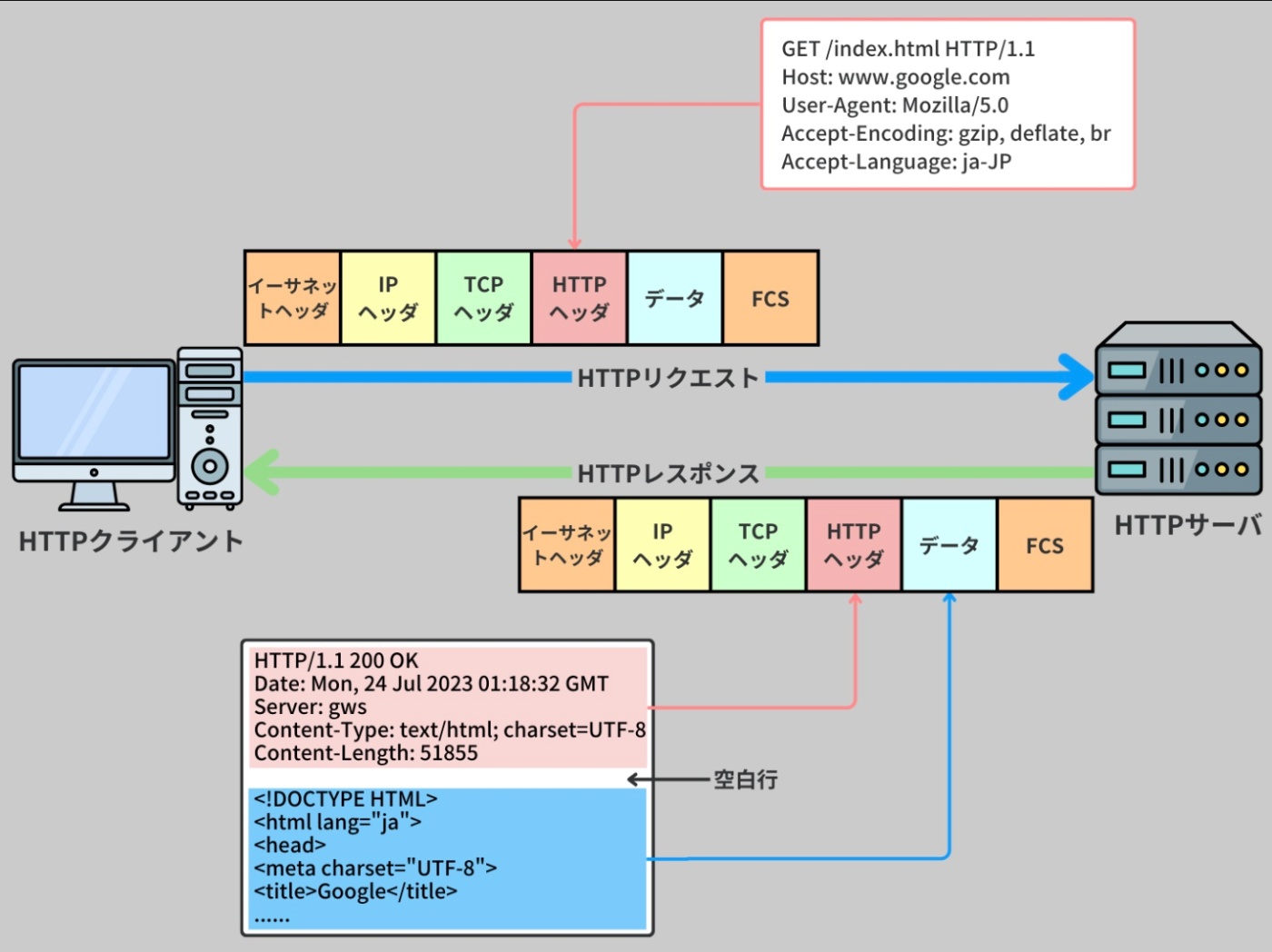
※https://recursionist.io/dashboard/course/33/lesson/1145 より画像引用
HTTP は当初、ハイパーテキスト(具体的には HTML ファイル)の伝送を目的として設計されたが、その汎用性と人気から進化を続け、多様なリソースの取り扱いに対応する新バージョンが次第に開発された。
最初の HTTP バージョンである 0.9 は非常にシンプルな設計で、TCP 接続後、"GET" というメソッドに続くパスをリクエストに含む形式が採用されていた。
例えば、"GET /page.html" のような形です。これにより、サーバはリクエストに応じて HTML ファイルの内容を ASCII 文字のバイトストリームとして返すことが求められた。
その後、HTTP は HTTP/1.0 という規格に統一され、現在の Web 上で広く採用されるようになった。HTTP/1.0 では多くの新たな構文が導入され、その後のバージョンである HTTP/1.1 ではそれらの構文に微細な調整が加えられた。
このプロトコルは、クライアントやサーバなどの多くのアプリケーションが使うアプリケーション層で標準化されており、安全で信頼性の高いパケットの送受信を可能にするために、UDP ではなく TCP/IP を使用する。
TCP にはヘッダとペイロードの二つの部分がある。
ヘッダ
パケットが正しく送られるための情報(どこから来て、どこへ行くかなど)を持つ。
ペイロード
ユーザーが実際に送りたいデータ(例えばウェブサイトの情報など)を持つ。
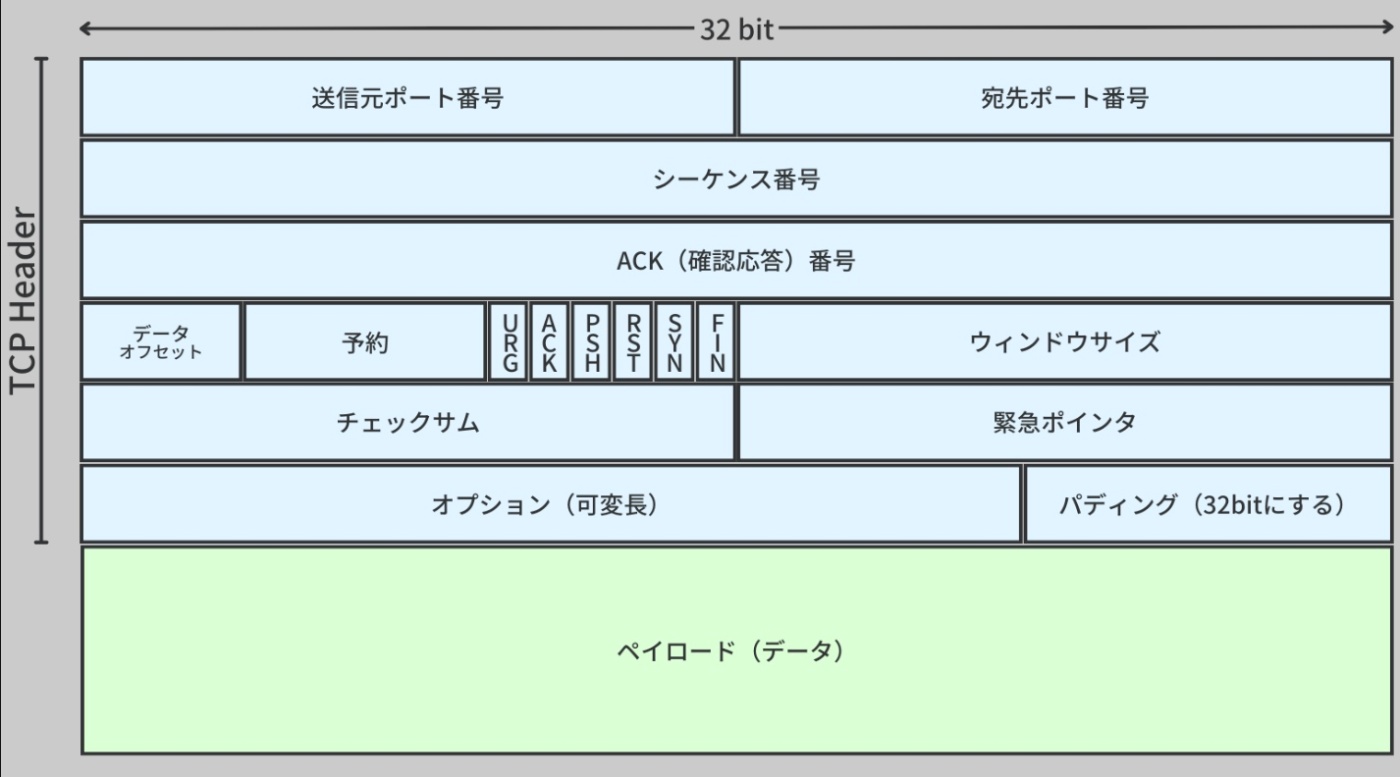
※https://recursionist.io/dashboard/course/33/lesson/1145 より画像引用
TCP/IPモデルのカプセル化はOS内で行われている
| TCP/IP層 | 主な役割 | 実行される場所(OS内か) |
|---|---|---|
| アプリケーション層 | HTTPやFTPなど、アプリのデータを生成 | アプリケーション + OS(Socket API 経由) |
| トランスポート層 | TCP/UDPでポート管理や信頼性保証など | OSのカーネル内部(TCP/IPスタック) |
| インターネット層 | IPアドレスを付けてルーティング | OSのカーネル内部 |
| ネットワークインタフェース層 | イーサネット等でMACアドレス処理・送信 | OS(ドライバ)+ ネットワークカード(NIC) |
PCのOS(たとえばmacOSやLinux、Windows)は
・Webアプリケーションやcurlなどのアプリから送られたデータを
・OS内部の ネットワークスタック(TCP/IPスタック) を通して
・各階層ごとに必要なヘッダ(TCPヘッダ、IPヘッダ、MACヘッダなど)を順番に追加して
・最終的にNIC(ネットワークインターフェースカード)に渡し、LANケーブルやWiFi経由で送信する
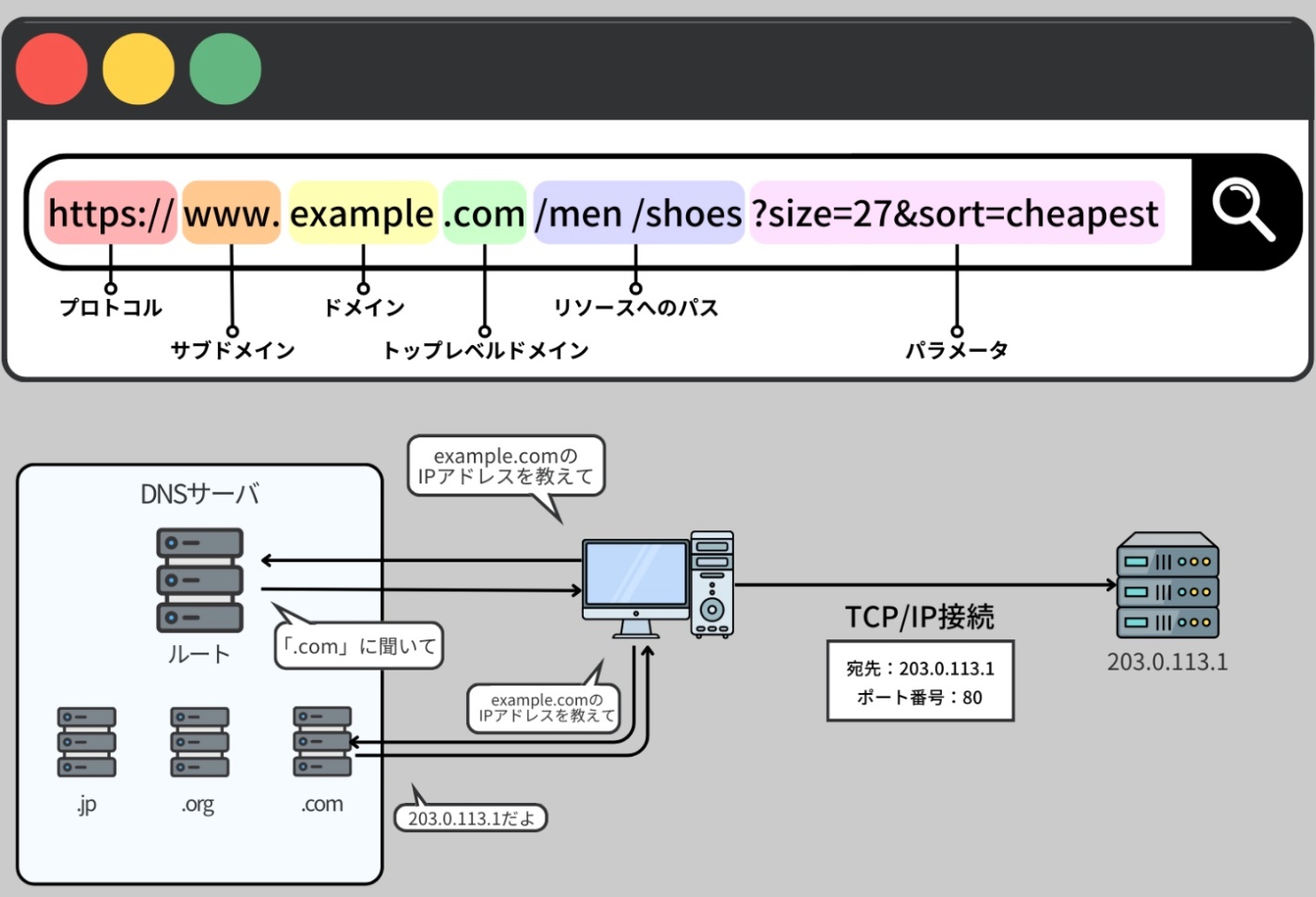
ブラウザがサーバとの間で通信を行なう手順
Step1
URL がブラウザのアドレスバーに入力される。
この URL は、
・どのように通信するか(HTTP/HTTPS)
・どのサイトに行くか(ドメイン名)
・そのサイトのどの部分(ファイルのパス)
・さらに特殊な条件(クエリパラメータ) などを示す。
ブラウザはドメイン名を DNS で検索し、対応するサーバの実際の IP アドレスを取得する。
また、ユーザーは直接 IP アドレスを入力することも可能。
※https://recursionist.io/dashboard/course/33/lesson/1146 より画像引用
Step2
ブラウザは、取得したサーバの IP アドレスとポート番号を利用して、TCP/IP 接続を開始する。
Step3
ブラウザとサーバはハンドシェイクを行ない、接続が確立する。
その後、ブラウザは HTTP リクエストメッセージを生成し、その中に method、scheme、path、cookies、accepted-language などのパラメータヘッダを埋め込み、サーバに送信する。
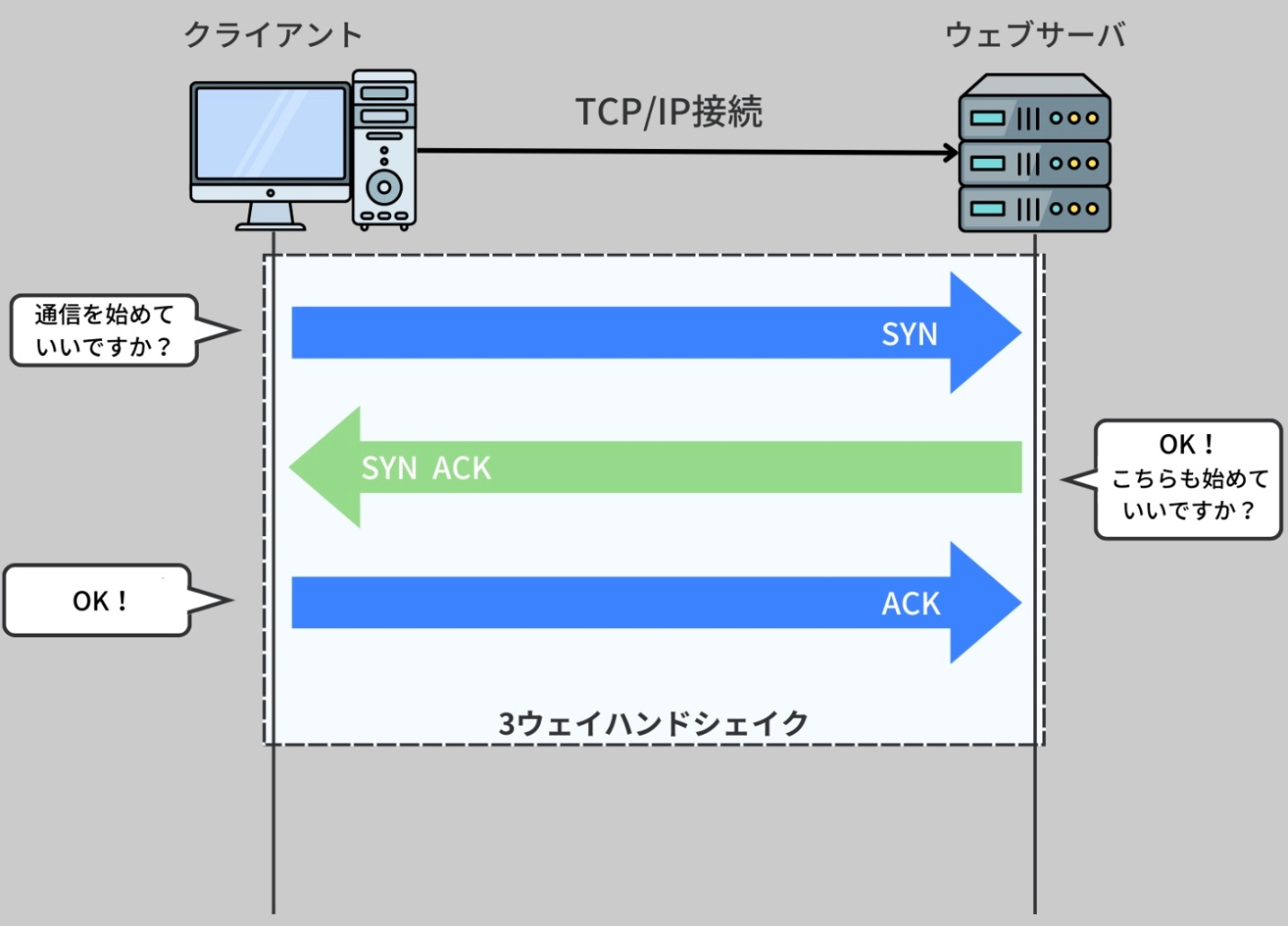
※https://recursionist.io/dashboard/course/33/lesson/1146 より画像引用
※ハンドシェイクとは、接続を確立するための通信プロトコルレベルでのやりとりを指す。
これはブラウザそのものが直接やるのではなく、その裏で動くOSのネットワークスタック同士(≒OSのTCP/IP層)が通信している。OSがパケットを組み立てて送信している。
※TLS通信(HTTPS)の場合
HTTPSでは、TCPでの接続確立(上記の3ウェイハンドシェイク)の後に、さらにTLSのハンドシェイク(鍵交換や証明書検証など)も行われる。
これも実際はアプリケーション(例:Chrome)とサーバ側のTLSライブラリ(例:OpenSSL)だが、
実際のデータ転送(パケット送信など)は OSの中のプロトコルスタックが担っている。
※TLSライブラリ
TLS(Transport Layer Security)通信を暗号化・復号・検証するためのソフトウェア部品(ライブラリ)のこと。
このライブラリは、Webサーバ(Apache、Nginxなど)やアプリケーションサーバの中で動いていて、
クライアント(ブラウザ)と安全なHTTPS通信を行う役割を担う。OpenSSLが最も有名。
Step4
サーバは受け取った HTTP リクエストを解析し、提供されたパス、メソッドタイプ、ボディなどの HTTP データを用いてリクエストを処理する。その後、HTTP レスポンスをブラウザに返し、リクエストを満たす。
Step5
ブラウザはサーバからの HTTP レスポンスを受け取り、レスポンスヘッダとボディの情報を使用してリソース(通常はウェブページ)をレンダリングする。
Step6
ウェブページに含まれる HTML、CSS、JavaScript などのウェブファイルがさらなるリソースを必要とする場合、ブラウザはそれらを取得するために追加の HTTP リクエストをサーバに送信する。
これにより、ウェブページに含まれるすべてのコンテンツ(画像、動画、スクリプトなど)が適切にロードされ、ユーザーが正確に閲覧できる。
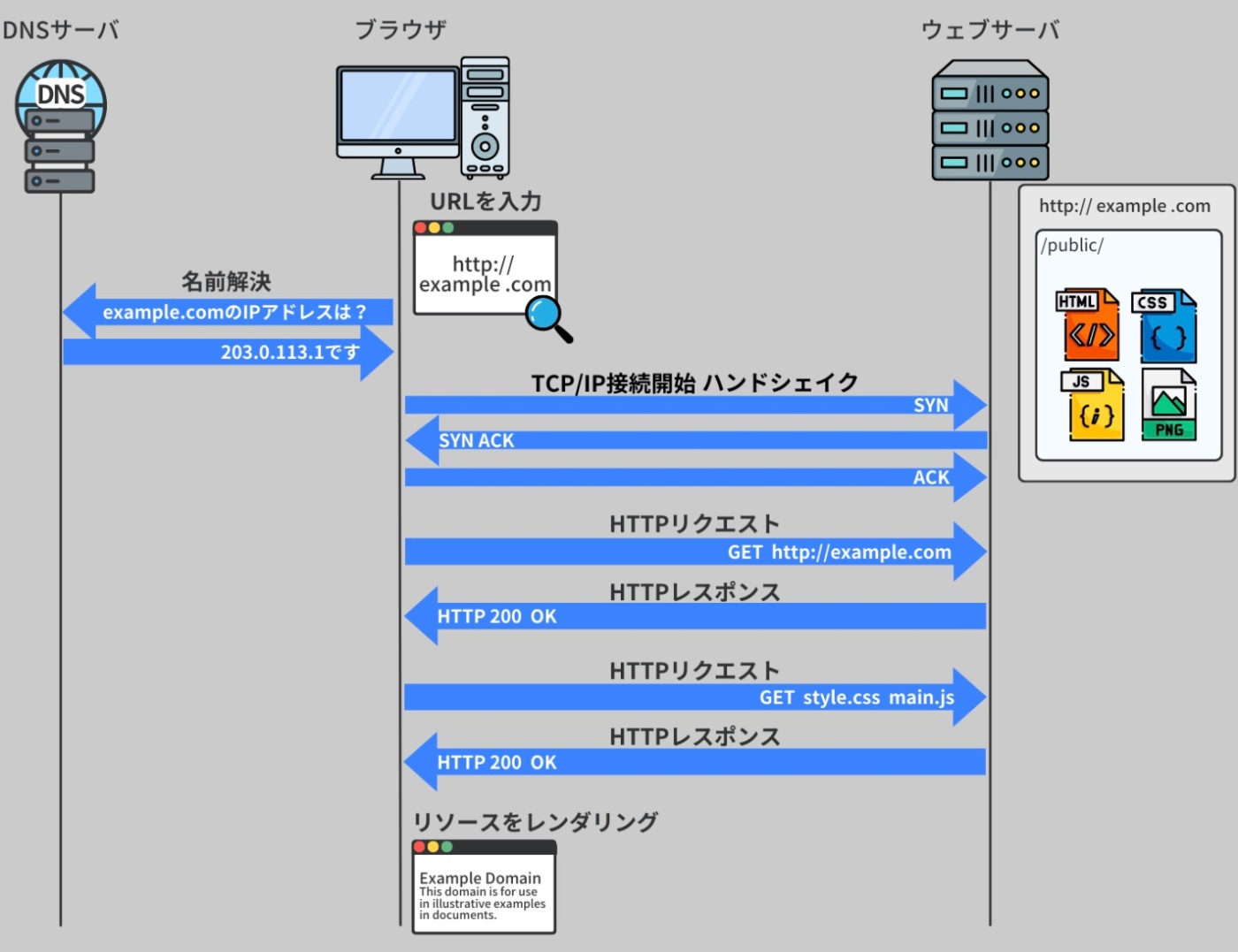
※https://recursionist.io/dashboard/course/33/lesson/1146 より画像引用
HTTP通信におけるポート
HTTP 通信を行なう際、通常は特定のポート番号が使用される。
ポートとは、コンピュータ内部でデータのやりとりを行うための仮想的な通信経路のようなもの。
HTTP は通常、ポート 80 を使用する。
データを暗号化して安全に通信する HTTPS(HTTP Secure)は、ポート 443 を使用する。
これにより、通信が暗号化され、第三者による情報の盗み見や改ざんを防ぐことができる。
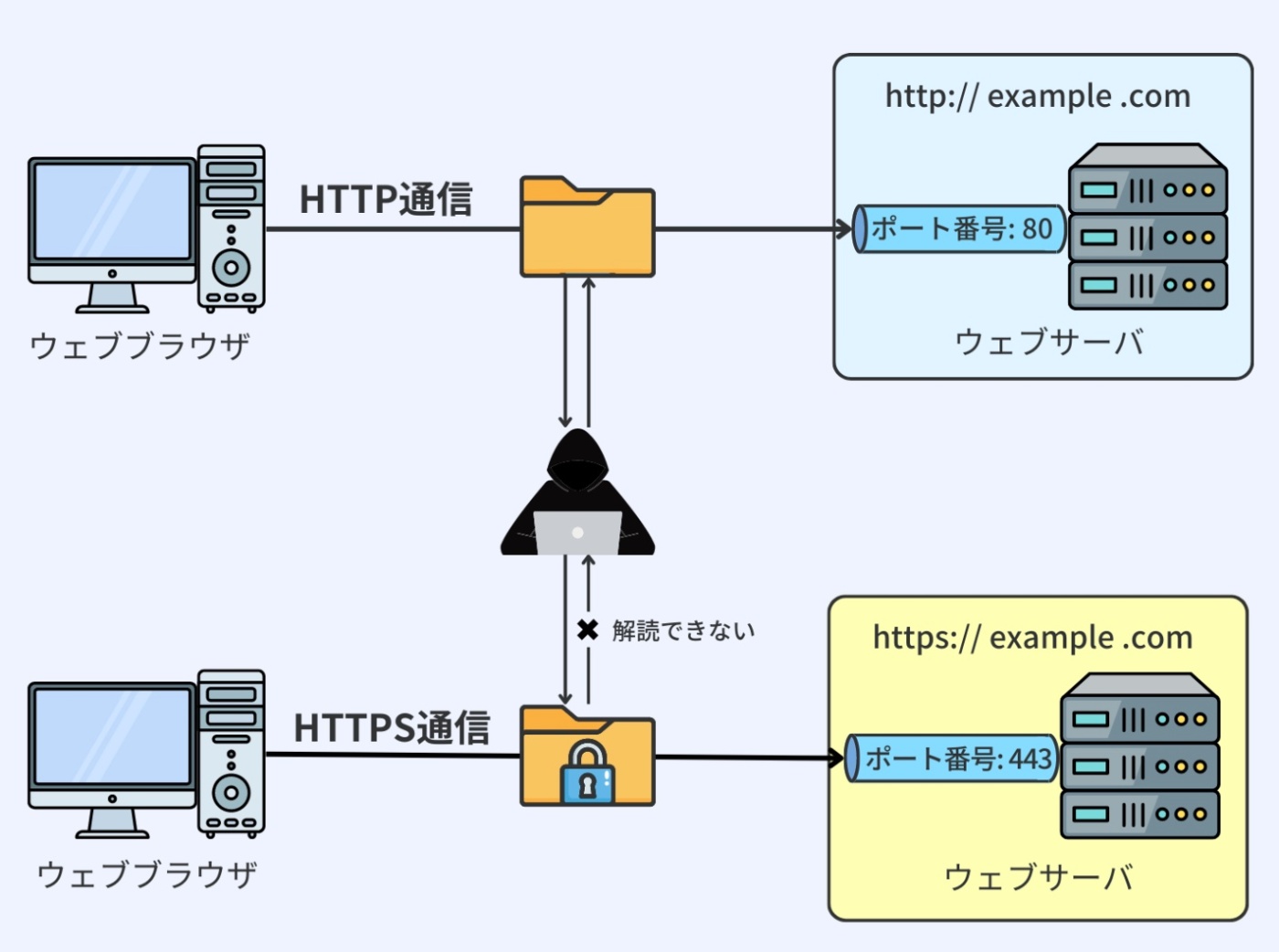
※https://recursionist.io/dashboard/course/33/lesson/1146 より画像引用
※HTTP リクエストと HTTP レスポンスを確認するツール
ブラウザには開発者向けのツールが組み込まれており、開発者コンソールを通じて HTTP リクエストと HTTP レスポンスを確認することができる。これは、ウェブアプリケーションのデバッグや問題解析に役立つ重要な機能。
具体的には、開発者コンソールを開き、「ネットワーク」タブをクリックすると、現在のブラウザセッションで行われているすべてのネットワーク活動を見ることができる。
例えば、www.google.com にアクセスした後、ページが完全に読み込まれると、メインの HTML ファイルやそれに関連する他のリソースを選択することで、それぞれの HTTP メッセージを詳細に見ることができる。これらのメッセージは、ブラウザがサーバと通信するための基本的なメカニズムを提供している。
さらに、HTTP を利用して World Wide Web 上でクライアントサーバ型のアプリケーションを開発する際には、メタデータの存在に注目することが重要。
これらのメタデータは、HTTPリクエストとレスポンスのヘッダフィールドに含まれ、リクエストの送信先、コンテンツタイプ、認証情報、キャッシュポリシーなど、多くの重要な情報を提供する。
サーバ側では、これらのヘッダフィールドを解析し、それに基づいて適切な手続きを行なう。
これにより、ユーザーの要求に対する最適なレスポンスを生成したり、セキュリティを保つための措置を講じたりする。
したがって、HTTP ヘッダはウェブ開発における重要な部分であり、その内容を理解していることが求められる。
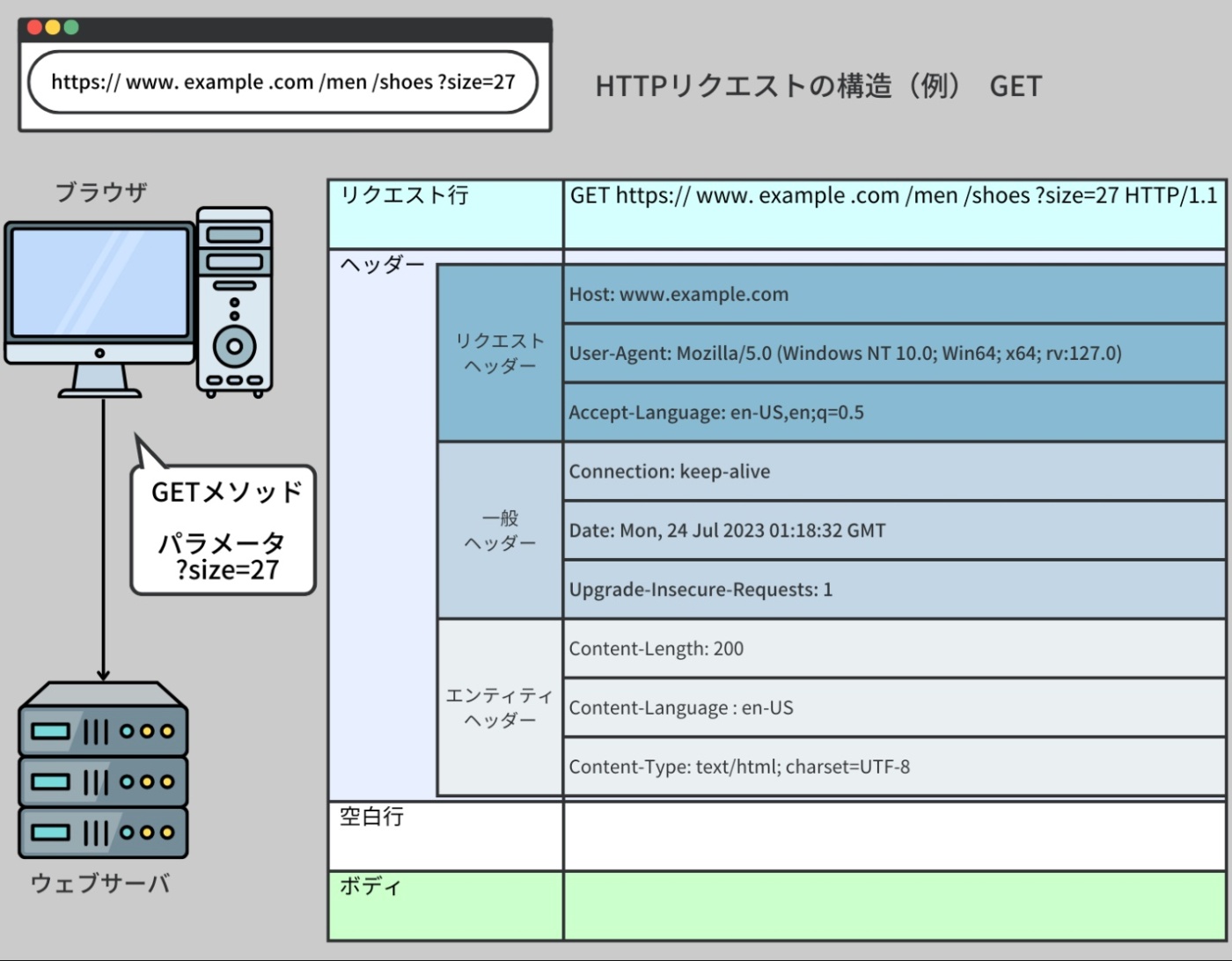
HTTPリクエスト
HTTP リクエストとは、クライアントがサーバに対して情報の取得や送信を依頼するための通信メッセージ
3つの主要な部分から成り立つ
① リクエスト行
② リクエストヘッダ
③ リクエストボディ
※https://recursionist.io/dashboard/course/33/lesson/1147 より画像引用
① リクエスト行
HTTP メソッド、指定されたパスまたはアクセスしたいリソース、使用される HTTP プロトコルのバージョンを含むリクエストの最初の部分。
例えば、GET /index.html HTTP/1.1 は、GET メソッドを使ってファイル 'index.html' にアクセスし、ブラウザが HTTP バージョン 1.1 をサポートしていることを意味する。
② リクエストヘッダ
リクエストやクライアントに関する指示や情報など、追加のメタデータをサーバに提供する。
一般的なヘッダ
【Host】
リクエストされたリソースのインターネットホストとポート番号を特定する
IPアドレスの端末ではなく、Hostはリクエスト対象のホスト名(ドメイン名)を示す文字列
リクエストしたいWebサイトの名前であって、その名前が指し示すIPアドレスの機械を指しているわけではない
【Accept-Language】
クライアントがレスポンスに使用する言語をサーバに知らせる
クライアントは「この言語が欲しいよ」と希望を伝え、サーバは可能な限りそれに応じてレスポンスを返すためのヘッダー
クライアント(ブラウザなど)がサーバに対して「どの言語のレスポンスを希望しているか」を伝えるためのもの
※クライアントが「必ずこの言語でレスポンスしろ」と命令しているわけではない。サーバが対応していればその言語で返すが、対応言語がなければ別の言語で返すこともある。
【Content-Type】
リクエストボディのメディアタイプ(フォーマット)を指定する
HTTP通信において 送信されるデータの「メディアタイプ(MIMEタイプ)」を示すもの
レスポンス(サーバ→クライアント)や リクエスト(クライアント→サーバ) のボディ(中身)がどんな種類のデータかを伝える。これにより受け取る側は、そのデータをどう処理・解釈すればいいか判断できる。
「送るデータが何の種類か」を明示するためのHTTPヘッダーであり、通信相手が適切に処理するために必要
【Authorization】
クライアントの身元を確認するための認証情報を伝える
HTTPリクエストで 「このリクエストは誰が送っているのか」や「このリクエストをする権限があるか」を証明するための情報をサーバに伝えるためのヘッダー
サーバ側で保護されたリソース(例えばログイン必須のページやAPI)へのアクセス時に、クライアント(ブラウザやアプリ)が認証情報を送信するために使用する。
認証トークンやユーザー名・パスワードなどの情報が入る。
【Connection】
現在のトランザクションが完了した後もネットワーク接続を開いたままにするかどうかを指定する
HTTP通信で 「この接続(通信回線)をどう扱うか」 をサーバーやクライアントに伝えるためのヘッダー
通信の接続を 持続(Keep-Alive)させるか、あるいは 通信終了(Close)するか を指定する。
③ リクエストボディ
サーバに送信したい実際のデータを含む。
特に POST リクエストの際によく使われる。POST リクエストは、サーバに対して新たな情報を送信するための HTTP メソッドで、データの作成や更新を要求する際に使用される。この POST リクエストの際に送信されるデータが、リクエストボディに格納される。
例えば、ウェブサイトのフォームを利用して新しいユーザーアカウントを作成する場合、ユーザーが入力した名前、メールアドレス、パスワードなどの情報はリクエストボディに含まれ、POST リクエストとともにサーバに送信される。サーバはその情報を用いて新たなユーザーアカウントを作成する。
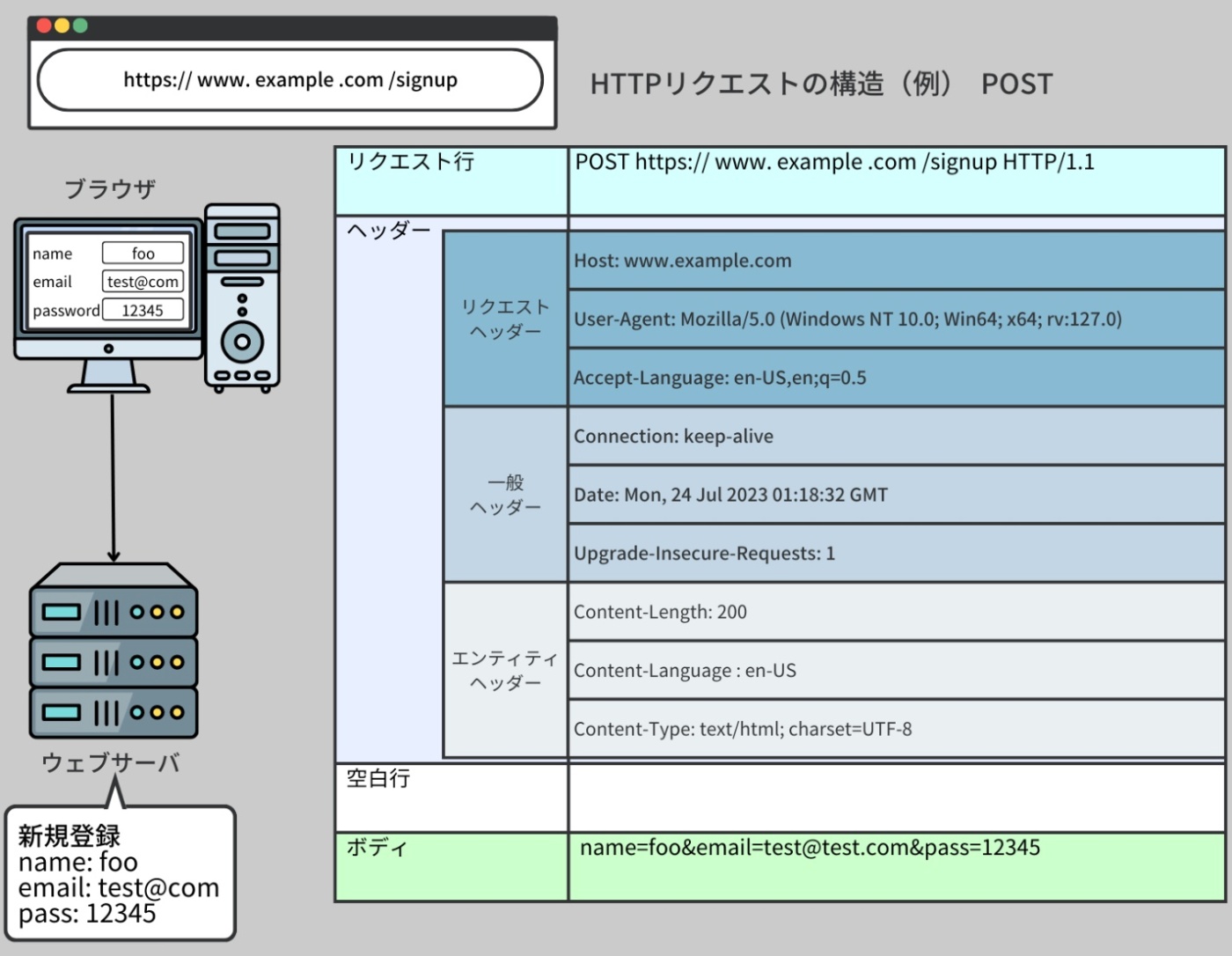
※https://recursionist.io/dashboard/course/33/lesson/1147 より画像引用
HTTPリクエスト
ウェブアプリケーションはデータベースとの間で情報を読み取り(Read)、作成(Create)、更新(Update)、そして削除(Delete)する。
この一連の操作は一般的に CRUD として知られ、これらはデータ管理の基本的な機能を表現している。
これらの CRUD 操作をウェブアプリケーションから行なうためには、HTTP リクエストというプロトコルが使用される。HTTP リクエストはウェブブラウザやアプリケーションがウェブサーバと通信するための標準的な方法。これらのリクエストはいくつかの形式があり、CRUD 操作と密接に関連している。
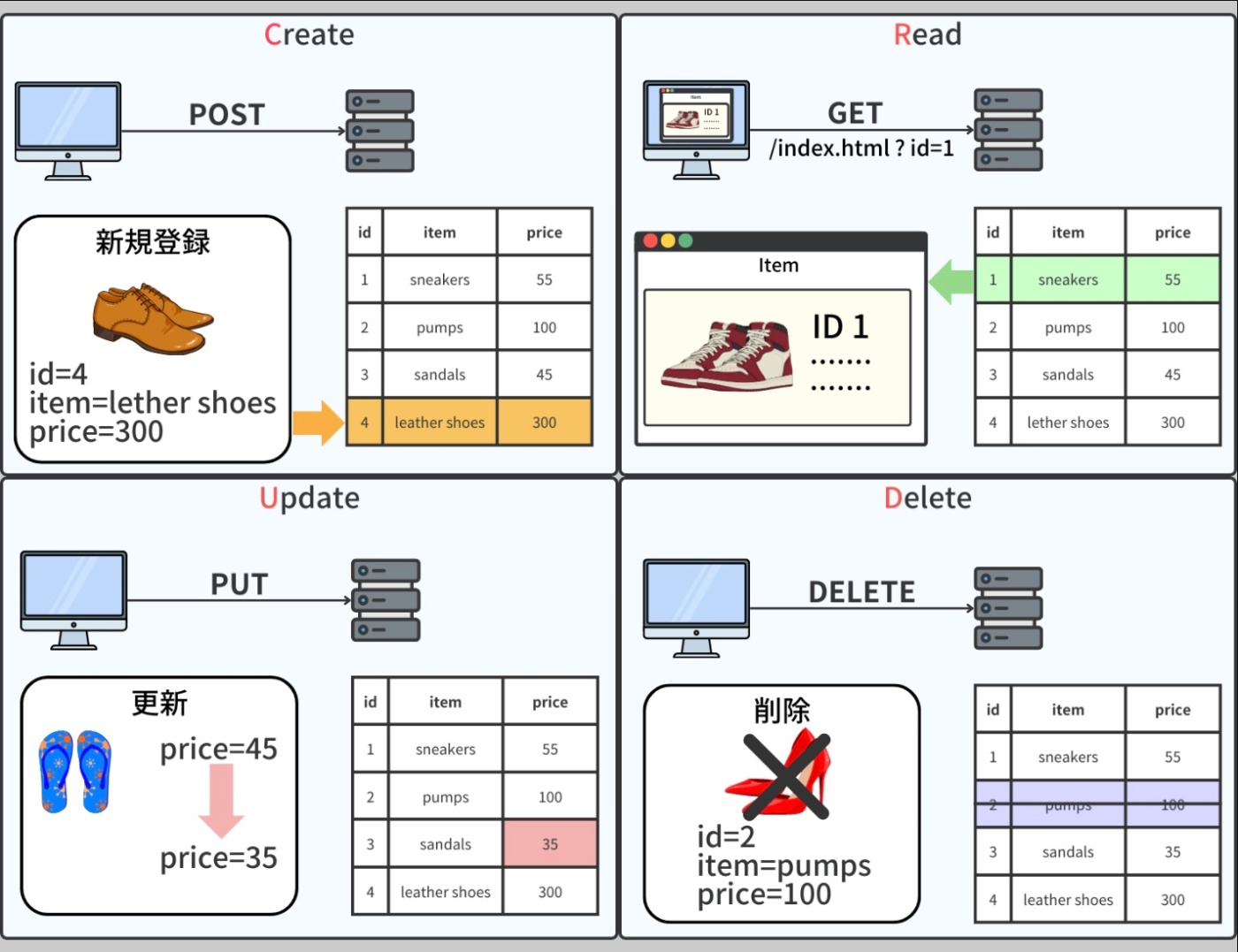
※https://recursionist.io/dashboard/course/33/lesson/1147 より画像引用
【HTTPメソッド】
GET:Read 操作に対応
リソースからデータを要求する。
フィルタリング用のパラメータを URL で渡すことができる。
POST:Create 操作に対応
リソースを更新するためにデータをサーバに送信する。
正確なアクションは URL とリクエストボディによって決定される。
PUT:Update 操作に対応
新しいリソースを作成するか、既存のリソースを置き換える。
DELETE:Delete 操作に対応
指定したリソースを削除する。
これらの HTTP メソッドは、REST(Representational State Transfer)アーキテクチャの原則に従うウェブ API の設計において特に重要。
RESTful な API は、HTTP メソッドを使用してデータベースとの間でデータのやり取りを行なう。
これにより、ウェブアプリケーションはデータベースとの相互作用を円滑に行なうことができる。
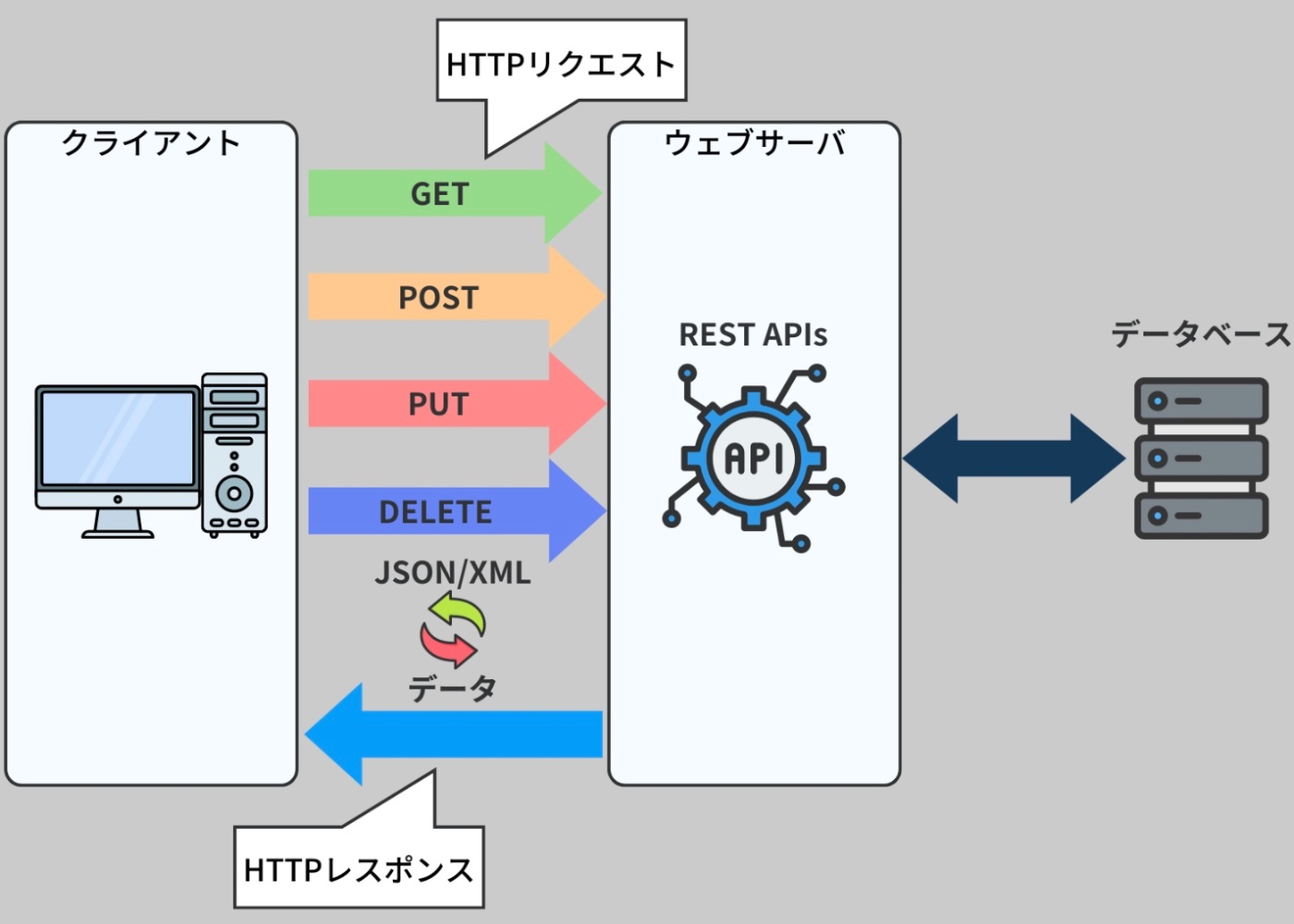
※https://recursionist.io/dashboard/course/33/lesson/1147 より画像引用
RESTとRESTful
REST(Representational State Transfer)
Webの仕組みに従って、リソース(情報)をやりとりする設計の考え方
=RESTは、Webの基本的な通信ルール(HTTP)を最大限に活かす設計原則
RESTの6つの原則(Constraints)
1. クライアント・サーバー(Client-Server)
・役割を分ける:クライアント(利用者)とサーバー(提供者)は明確に分離される。
・クライアントは UI を担当し、サーバーはデータやロジックを担当する。
→ これにより、開発や拡張がしやすくなる。
(例)スマホアプリ(クライアント)がデータを取得するためにAPIサーバーにリクエストを送る
2. ステートレス(Stateless)
1つ1つのリクエストは独立して完結している。
各リクエストには、必要な情報(認証、状態など)を全て含める必要がある。
サーバー側はクライアントのセッションや状態を保存しない。
(例)ログイン状態を保持するのではなく、毎回トークンを送るAPI(例:JWTなど)
→ ログイン状態(セッション)をサーバーで管理せず、クライアントが毎回自分の身分証(トークン)を送って認証される、という方式
※セッション認証よりトークン認証の方が状態を持たない分サーバは楽
3. キャッシュ可能(Cacheable)
レスポンスには、キャッシュしてよいかどうかの情報を含める。
キャッシュ可能なレスポンスは、クライアント側や中間ノードに保存できる。
ネットワーク負荷軽減、パフォーマンス向上に効果的。
(例)HTTPヘッダの Cache-Control や ETag を使って、再利用を判断する
4. 統一インターフェース(Uniform Interface)
APIのインターフェースを統一して、使いやすく・理解しやすくする。
これがRESTの最も特徴的な原則
【統一インターフェースを構成する4つの要素】
・リソースの識別:URLでリソースを一意に表す(例:/users/1)
・リソース操作の標準化:HTTPメソッド(GET, POST, PUT, DELETEなど)を使う
・表現による操作:レスポンスの形式(JSON, XMLなど)はクライアントが理解できるように
・自己記述型メッセージ:リクエストやレスポンスには必要な情報(ヘッダなど)を含む
(例)GET /books/1 がどんなAPIでも「本の1番を取得する」意味になると、分かりやすい。
5. 階層構造システム(Layered System)
クライアントはサーバーの内部構造を知らない。
実際には中間にプロキシやゲートウェイ、ロードバランサーなどが存在してもよい。
(例)リクエストは実際のサーバーではなく、リバースプロキシで処理されるかもしれないが、クライアントには見えない。
6. コードオンデマンド(Code on Demand)※任意
サーバーは、必要に応じてクライアントにコード(JavaScriptなど)を送ることもできる。
クライアントはそれを実行して動的に処理を拡張できる。
(例)ウェブページに含まれるJavaScriptコードを実行することで、UIが動的に変わる。
※これは唯一「任意の制約」なので、使わなくてもRESTfulと見なされる
RESTful
RESTの考え方をちゃんと守っているWeb API
RESTfulな例
| 操作 | HTTPメソッド | URLパス | 意味 |
|---|---|---|---|
| ユーザー一覧取得 | GET | /users |
ユーザーの一覧を取得 |
| ユーザー詳細取得 | GET | /users/123 |
ID=123のユーザーを取得 |
| 新規ユーザー作成 | POST | /users |
新しいユーザーを作成 |
| ユーザー更新 | PUT | /users/123 |
ID=123のユーザーを更新 |
| ユーザー削除 | DELETE | /users/123 |
ID=123のユーザーを削除 |
HTTPレスポンス
HTTP レスポンスとは、サーバがクライアントの HTTP リクエストに応じて送り出すメッセージ。
これは HTTP リクエストと同じような構造を持っており、ステータス行、レスポンスヘッダ、レスポンスボディという 3 つの主要な部分から構成される。
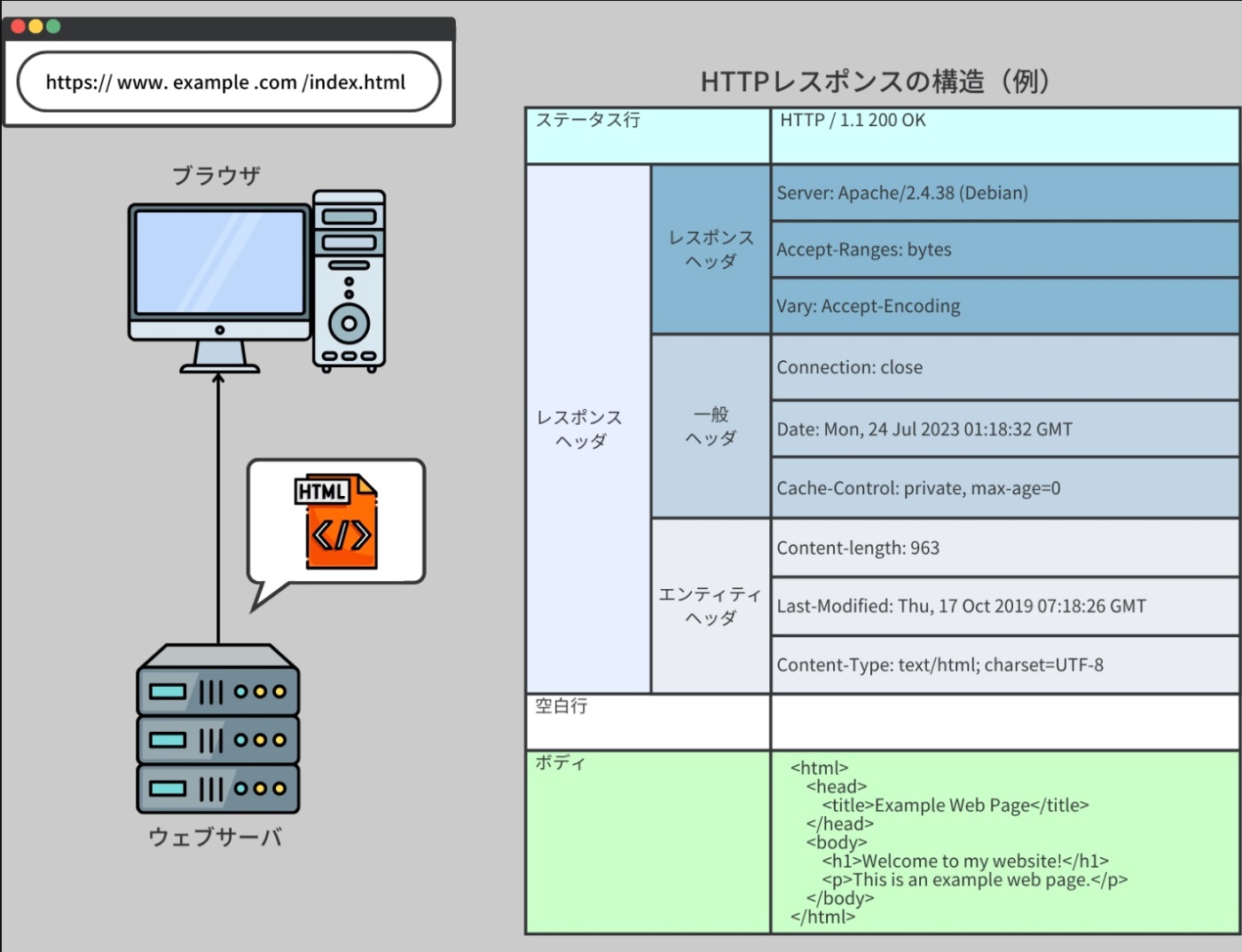
※https://recursionist.io/dashboard/course/33/lesson/1148 より画像引用
【ステータス行】
ステータス行はレスポンスの開始部分で、使用される HTTP プロトコルのバージョン、ステータスコードという数値、そしてそのステータスコードを説明するテキストフレーズが含まれている。
HTTP ステータスコードは、レスポンスの種類を表し、大きく5つのカテゴリに分けられる
1xx(情報)
100 Continue や 101 Switching Protocols のように、途中経過を示すレスポンス
2xx(成功)
200 OK や 201 Created のように、リクエストが成功したことを表す
3xx(リダイレクト)
301 Moved Permanently や 302 Found のように、追加のアクションが必要なことを示す
4xx(クライアントエラー)
400 Bad Request や 404 Not Found のように、クライアントのリクエストに問題があることを伝える
5xx(サーバエラー)
500 Internal Server Error や 503 Service Unavailable など、サーバ側に問題があることを示す
参考URL:https://www.rfc-editor.org/rfc/rfc9110#name-introduction
【レスポンスヘッダ】
レスポンスヘッダは、レスポンスやサーバに関する追加情報を提供する。
一般的なヘッダ
Cache-Control
キャッシュの動作を制御する
値には
・'public'(公開キャッシュに保存可能)
・'private'(特定のユーザー専用のキャッシュに保存可能)
・'no-cache'(キャッシュを前もって検証する必要がある)などがある
Content-Disposition
クライアントがレスポンスの内容をダウンロードする際のファイル名を指定する
Content-Encoding
レスポンスボディで使用されているエンコーディング方式を示す
'gzip'、'deflate'、'br'(Brotli)などのエンコーディング方式がある。
これは、レスポンスボディのデータを効率よく送信するためのもの。
Content-Length
レスポンスボディのサイズをバイト単位で示す
これにより、クライアントは受信データの全体長を事前に知ることができる。
Content-Type
レスポンスのメディアタイプを指定する
(例)
・'text/html' :HTML ドキュメント
・'application/json' :JSON 形式のデータ
・'image/jpeg' :JPEG 形式の画像データ を示す
Expires
このヘッダはレスポンスがキャッシュとしてどれだけの期間新鮮なものとして保持されるかを示す
指定された日時を過ぎると、キャッシュは古いとみなされる。
Last-Modified
レスポンス内容が最後に変更された日時を示す
この値は、サーバとクライアントがコンテンツの新鮮さを判断するために使われる。
Location
このヘッダはクライアントを別の URL にリダイレクトするために使用される
これは主に 3xx の HTTP ステータスコード(リダイレクト)と共に使用される。
Server
リクエストを処理するサーバが使用するソフトウェアとそのバージョンを示す
Set-Cookie
クライアントのブラウザにクッキーを設定する
これは、サーバがクライアントに特有の情報を保持し、その後のリクエストでその情報を再利用するためのもの。
※参考URL:https://developer.mozilla.org/en-US/docs/Web/HTTP/Reference/Headers
【レスポンスボディ】
レスポンスボディは、サーバがクライアントのリクエストに応答する形で返す具体的な内容。
ボディの内容の形式は、ヘッダ内の Content-Type フィールドによって定義される。
ウェブブラウザは、これらの内容をバイトとして解釈し、さまざまなメディアタイプを処理することができる。
HTTP/1.1
HTTP/1.1 は、Web 通信の中心となるプロトコルであり、その仕様は 1997 年に初めて発表された。HTTP/1.1 は、より高速で効率的な通信を実現するために、その前のバージョンである HTTP/1.0 からいくつか重要な進化を遂げた。しかし、この HTTP/1.1 は、今日の Web の需要に完全に応えることができていないという問題も存在する。
HTTP/1.1 の一部の問題点の一つに、Head-of-line blocking(HOL blocking)と呼ばれる問題がありる。
HTTP/1.1 では、各リクエスト・レスポンスは TCP 接続を必要としていた。
そのため、全てのデータが受信されてから次のデータを要求する、いわゆる "ブロック" が発生する。
例えば、あるドメインから 10 個の異なるリソースをリクエストする場合、それぞれのリクエストが完全に満たされるまで待たなければならないという状況になる。
HTTP/1.1 は1つの接続上で1リクエストずつしか扱えない。
そのため、前のリクエストのレスポンスが終わらないと、次のリクエストを送れない or 受け取れない
HOLブロッキング
HTTP/1.1 では、1つのTCP接続に対してリクエストを順番に送る設計になっていて、これを キューに入れる(直列処理) という形で管理している。
サーバに複数のリクエストを送りたい場合、順番に送って順番にレスポンスを待つ
前のリクエストのレスポンスが返ってこないと、後ろのリクエストも進まない
同じリソースに対して同時に多数のリクエストが来た場合、サーバ側の処理能力やプロトコルの制限(特にHTTP/1.1)によって、レスポンスが遅くなる原因になる(HOLブロッキング)
近年の Web ページは多数の小さなリソース(例えば、画像、スクリプトなど)を必要しているため、特に問題となっていた。各リソースが個別のリクエストを必要とし、そのために新たな TCP 接続の確立に時間がかかってしまう。
そのため、10 個の異なる TCP 接続を作成し、それぞれを通じてリソースをリクエストするという対策が取られてきた。
※https://recursionist.io/dashboard/course/33/lesson/1149 より画像引用
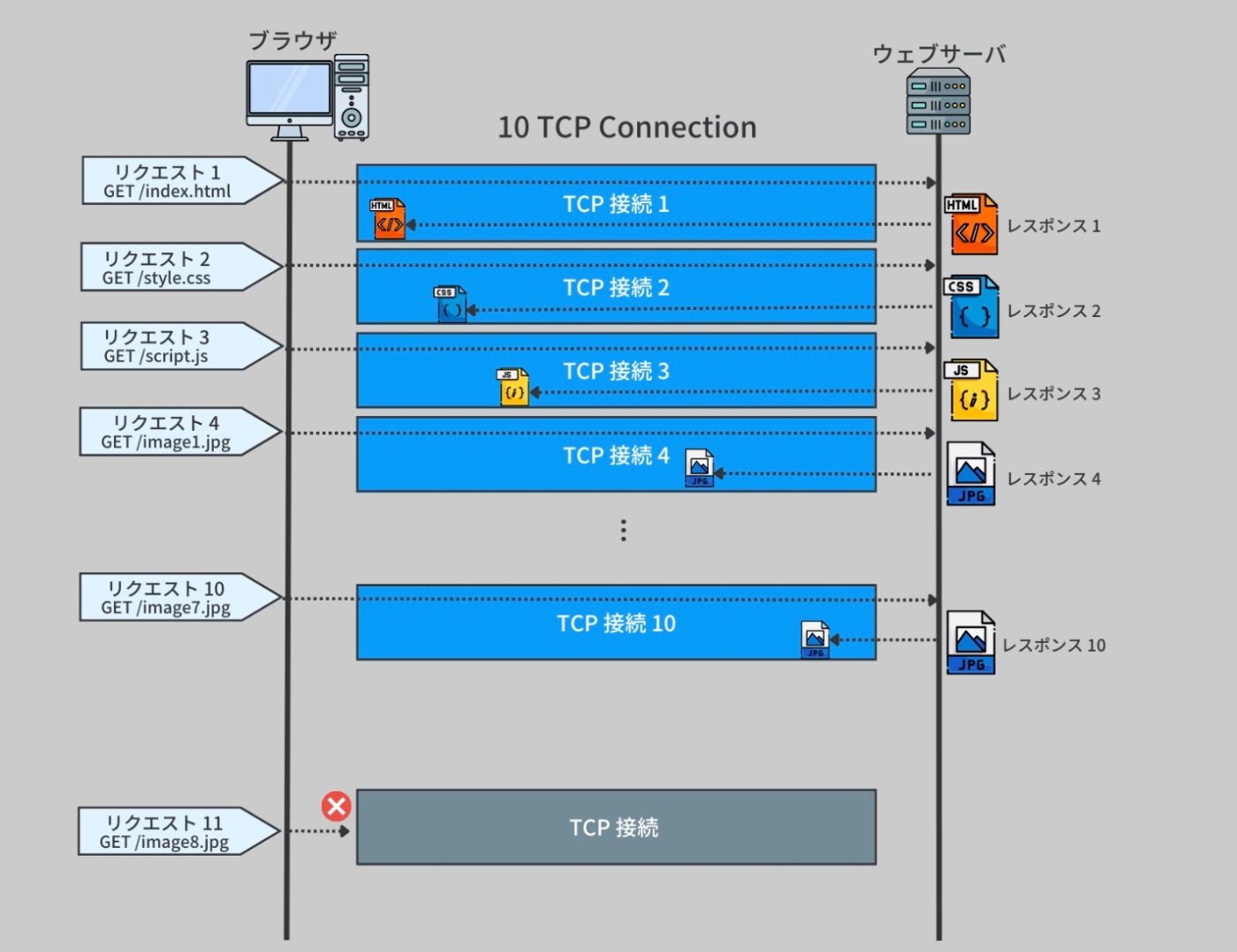
この手法により、各リクエストは並行して実行されるが、それぞれの TCP 接続がハンドシェイクを必要とし、サーバが同時に扱うことのできる接続数には限界があるため、この方法にはオーバーヘッドが生じる。
HTTP/1.1 では、HTTP メッセージは TCP パケットとして一度に全体が送信される。すべてのデータが送信されるとレスポンスが完成し、クライアント側はこれを content-length フィールドや TCP 接続の終了を通じて確認する。
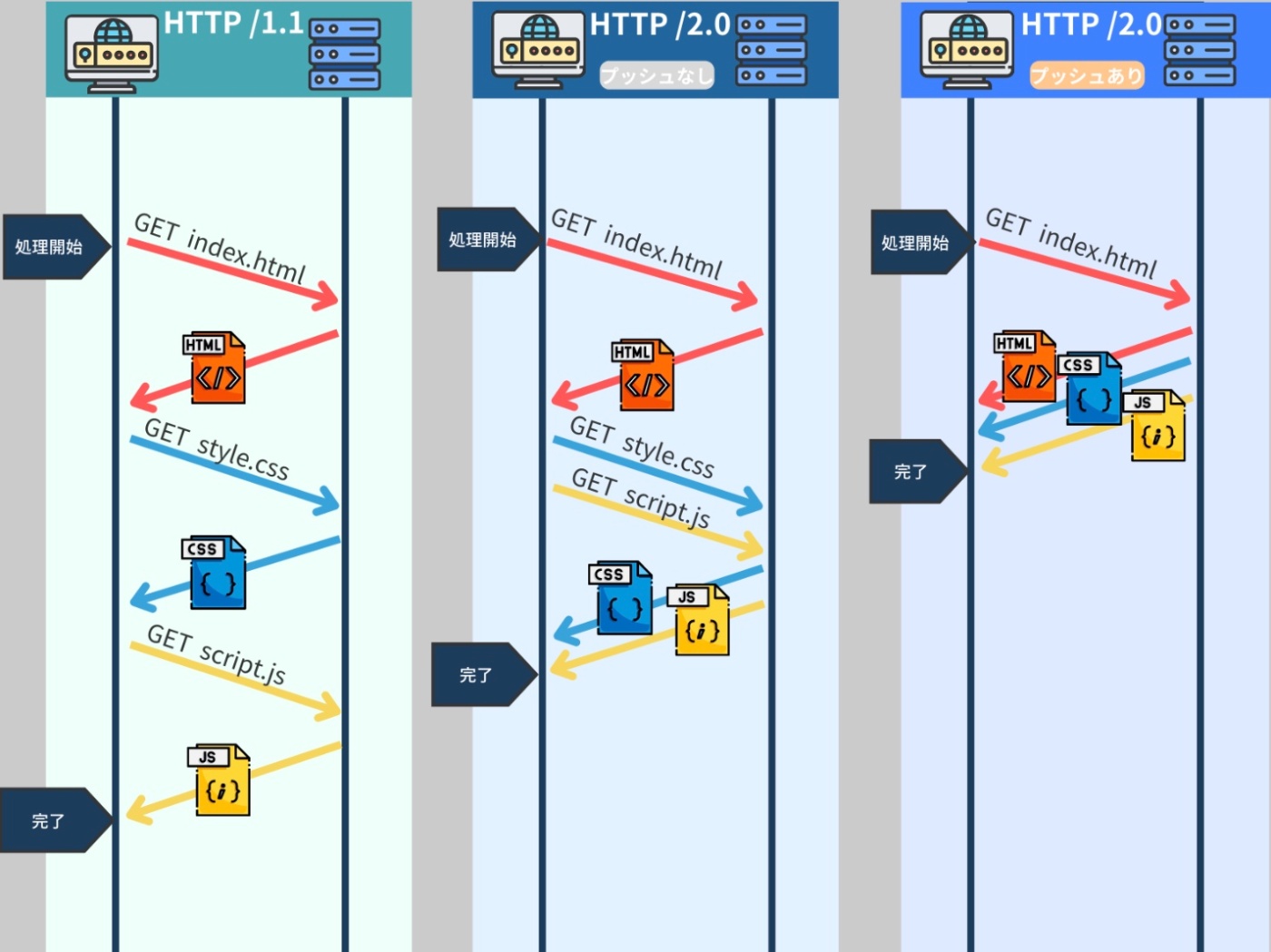
HTTP/2
HTTP/1.1 で問題となっていた HOL blocking は、ウェブページのロード時間を大幅に増加させ、ユーザーエクスペリエンスを損なう可能性がある。特に、大量のデータや複数のリソースを要求する現代のウェブアプリケーションでは、この問題はより顕著になる。
これらの問題を解決するために、HTTP/2 では多くの強化を導入。
例えば、マルチプレクシング、リソースの優先付け、ヘッダ圧縮、サーバプッシュなど。
バイナリプロトコルとフレーム
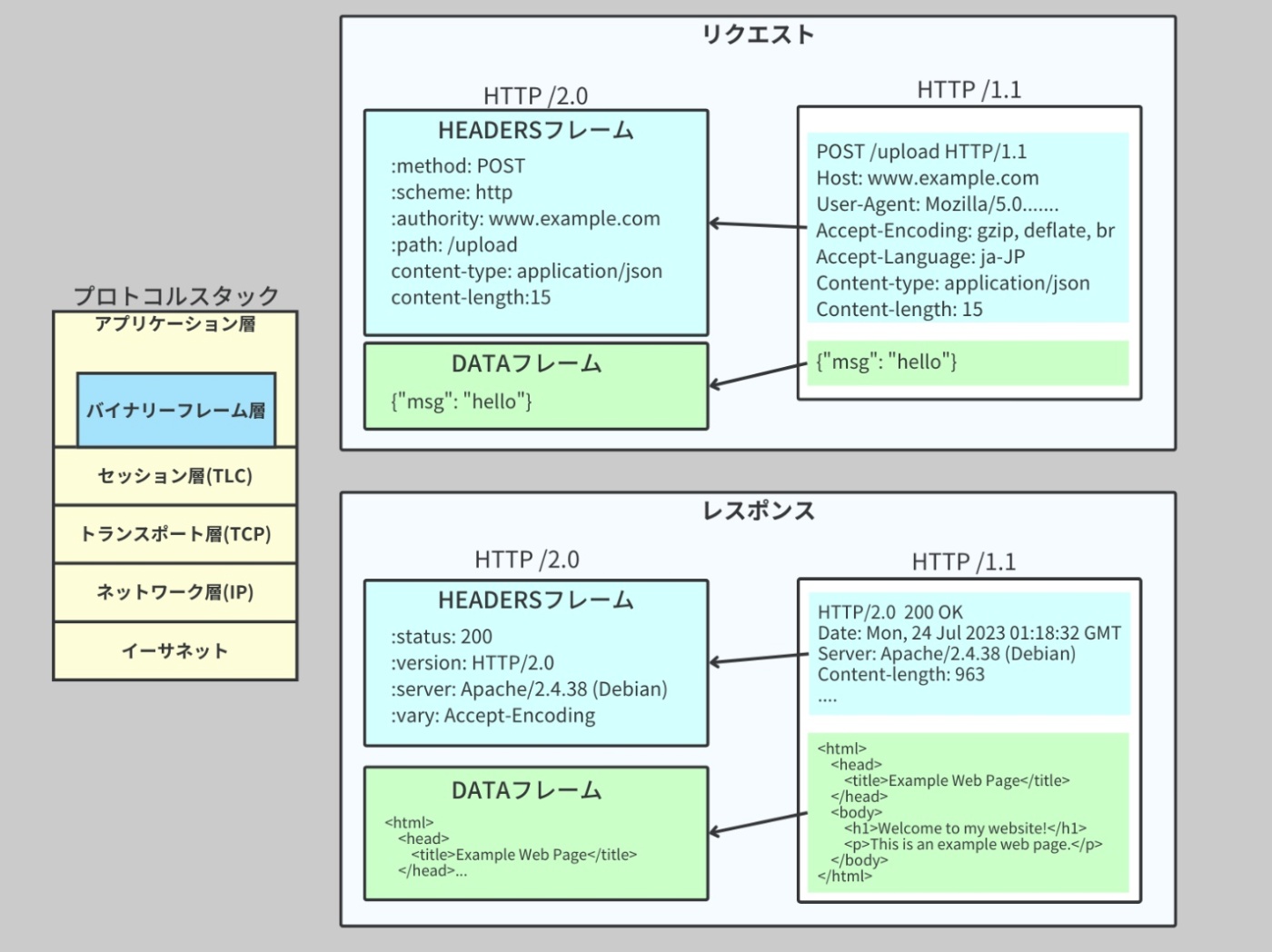
HTTP/2 では新たにバイナリプロトコルとフレームという概念が導入された。
HTTP/2 では、HTTPリクエストやレスポンスの構造が HTTP/1.x とは大きく変わり、「フレーム(frame)」という単位でデータをやりとりする仕組みになっている。
HTTP/2 ではこのフレーム化された情報を、アプリケーション層(=Webサーバやフレームワーク)で
・HEADERSフレーム → ヘッダー情報に分解して取得
・DATAフレーム → ボディとして読み込む
というように扱う。つまり、HTTP/2のアプリケーション層では、各フレームを組み立てて元のHTTPリクエスト/レスポンスを再現しているということ。
→ バラバラに届いたフレームを組み立ててリクエスト・レスポンスをつくっているということ
バイナリプロトコル
データをバイナリ形式(0 と 1 の列)で送受信する通信規約のことで、これによりデータの送受信効率が向上。
フレーム全体のデータを小さな単位である「フレーム」に分割し、それぞれが個別に送信される。
フレーム
データ送信の単位のことで、大きなデータを小さなフレームに分割して送信することで、通信効率とレスポンスの速度を向上させることができる。
このフレーム単位での送信が終了すると、全体のデータの送信が終了したと認識される。
これは TCP の送信処理と同じような挙動だが、ここで重要な違いは、この挙動が TCP が動作する「トランスポート層」ではなく、HTTP が動作する「アプリケーション層」で行われているところ。
【フレームの分割と再構築の流れ】
・送信側(クライアントやサーバ):HTTP/2のレイヤーでフレームを作成し、TCPに渡す
・受信側(サーバやクライアント):TCPで届いたバイナリを、HTTP/2層で解析して元のフレームに組み立てる
※TCPは中身が何か知らずにバイト列として運ぶだけで、「順序保証」「再送制御」「コネクション管理」などを担当する
※https://recursionist.io/dashboard/course/33/lesson/1150 より画像引用
なお、現代のブラウザ、例えば Google Chrome などには、ネットワークデータを JSON に記録する //net-exportや、各フレームのデータを視覚化できるツール netlog-viewer が内蔵されている。
net-export
chrome://net-export
Google Chrome の特別な機能で、ユーザーがブラウザで行なったネットワーク活動(ウェブサイトへのアクセス、データのダウンロードなど)を JSON 形式(一種のデータ形式)で記録することができる。
この機能を使うと、ネットワーク通信の詳細を確認したり、問題の原因を探ることができる。
netlog-viewer
ウェブベースのツールで、https://netlog-viewer.appspot.com からアクセスできる。
このツールを使うと、//net-export で生成したログを視覚的に解析することができる。
特に、HTTP/2 の「フレーム」単位の通信を視覚的に確認することができ、各フレームがどのように送受信されているかを理解するのに役立つ。
HTTP/2
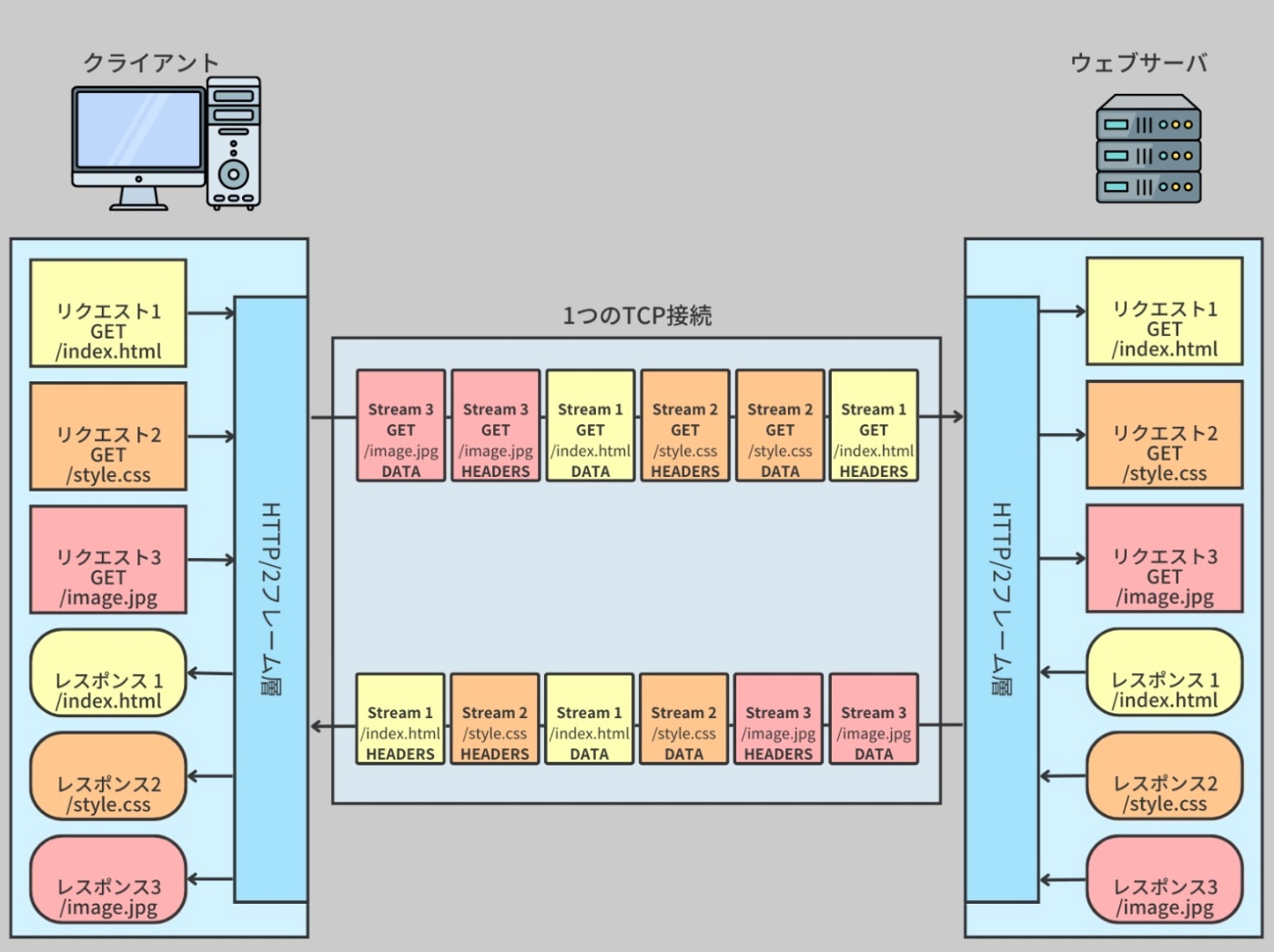
マルチプレキシング
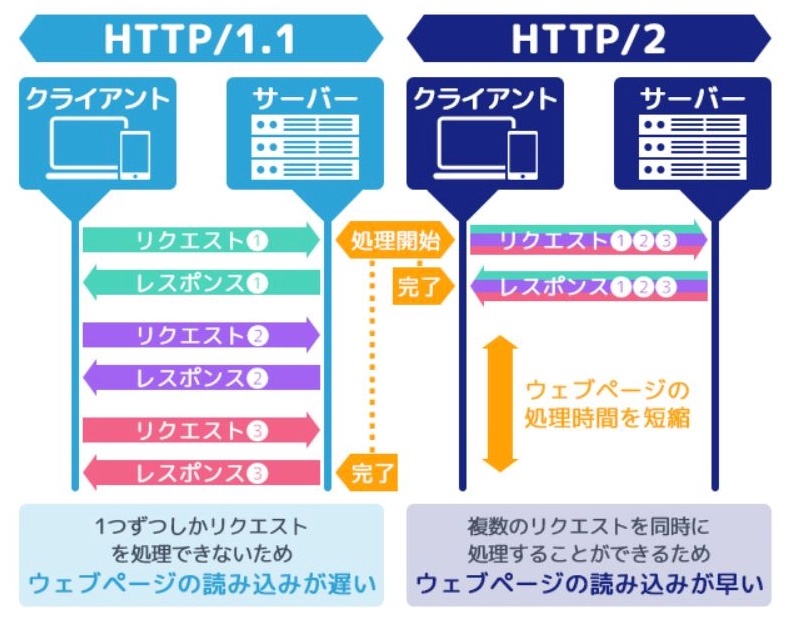
フレームの導入で、マルチプレキシング(多重化)が可能になった。
マルチプレキシング
複数のリクエストとレスポンスが単一の TCP 接続を共有できる機能。
つまり、一つの TCP 接続上で複数のリクエストとレスポンスを並行して処理できるようになった。
これにより、HTTP/1.1 で見られる HOL blocking の問題を回避できる。
例えば、あるウェブページに 10 個の画像があるとする。HTTP/1.1 では、これらの画像を一つずつ順番にダウンロードしなければならないのに対し、HTTP/2 では、1 つの接続上で全ての画像を同時にダウンロードすることが可能。これにより、ウェブページの読み込み時間が大幅に短縮される。
※https://arakan-pgm-ai.hatenablog.com/entry/2019/04/25/004000 より画像引用
HTTP/2
リソースの優先付け
マルチプレキシングが可能になったことで、単一の接続上で複数のリクエストとレスポンスが行われる。
しかし、すべてのリソースが等しく重要ではないため、HTTP/2 では各ストリーム(リクエスト/レスポンスのペア)に優先順位を付けることが可能となった。
この優先順位付けにより、重要なリソースが先に送信され、ウェブページのパフォーマンスが向上する。
優先順位は「PRIORITY」フレームを使って設定される。
クライアントはこのフレームを使って、どのリクエストが他のリクエストよりも重要であるかをサーバに伝えることができる。また、優先順位は動的に変更することも可能で、これによりクライアントはリソースのロード順序を最適化することができる。
例えば、ウェブページのレンダリングに重要な CSS や JavaScript を最初にダウンロードし、その後で画像などのその他のリソースをダウンロードする、といった制御が可能となる。
これにより、ユーザーがウェブページの情報を可能な限り早く見ることができる。
HTTP/2 がどのように作動するかを視覚的に示した図
※https://recursionist.io/dashboard/course/33/lesson/1151 より画像引用
HTTP/2
ヘッダ圧縮
ヘッダ圧縮とは、リクエストやレスポンスに含まれるHTTPヘッダの情報を効率よく圧縮する仕組みのこと
HTTP/1.1 では、データはテキスト形式で送信されるが、HTTP/2 ではデータはバイナリ形式で送信されるようになった。
バイナリ形式は、テキスト形式と比べてより効率的にデータを圧縮できるため、ネットワーク上でのデータ転送が高速化する。
特に、ヘッダ情報(リクエストやレスポンスに含まれるメタデータ)が大量に存在する場合、この効果は顕著になる。
1回目:
GET /home
Host: example.com
User-Agent: Chrome
Cookie: abc
2回目:
GET /about
Host: example.com
User-Agent: Chrome
Cookie: abc
// 1回目
[全部のヘッダを送信] → テーブルに保存
// 2回目
[GET /about は新しいけど、他のヘッダは前と同じなので番号だけ送信]
HTTP/2 では HPACKという独自のヘッダ圧縮方式を採用している
【動的テーブルによる差分管理】
過去に送信したヘッダは テーブルに保存される。
同じヘッダを再度送るときは、「あのヘッダの2番目ね」のように インデックス番号だけ送信する。
【静的テーブルの活用】
よく使われる一般的なヘッダ(例::method, :path, host)は最初から用意されており、それを番号で参照できる。
【圧縮(エンコード)+差分だけ送る】
新しいヘッダが出てきたときだけ、その部分を圧縮して送る。
同じ内容なら毎回送る必要がなく、通信量が大きく削減される。
HTTP/2
サーバプッシュ
HTTP/2 はサーバプッシュという機能を導入している。
サーバプッシュとは、HTTP/2 の新たな特性の一つで、サーバ側からクライアント側に対して、クライアントがまだ明示的に要求していないリソースを予測的に送信する機能を指す。
例えば、ウェブブラウザ(クライアント)があるウェブページ(例えば、HTML ページ)を要求したとする。
この HTML ページは、画像や CSS、JavaScript など、その他の追加的なリソースを必要とする。
サーバプッシュでは、サーバがクライアントに、クライアントがまだ要求していないデータ(たとえば、特定のウェブページで使用される画像や CSS)を予測的に送信することを可能にする。
この機能は一方向性を持っている。
つまり、サーバがクライアントに対して予測的にデータを送信するものであり、クライアントからサーバに対して同様の操作を行なうことはない。
※https://recursionist.io/dashboard/course/33/lesson/1151 より画像引用
HTTP/3
HTTP/2 が多くの改善をもたらしたにもかかわらず、それでも一部の問題が残った。
特に TCP(Transmission Control Protocol)を基盤とすることによる制約が指摘されている。
TCP は信頼性の高いデータ転送を提供するが、一部の状況ではパフォーマンス上の課題がある。
具体的な問題① HOL blocking
HTTP/2 は TCP 上で動作するが、TCP 自体は HOL blocking 問題を完全に解決していない。
HTTP/2 が一つの TCP 接続で複数のリクエストとレスポンスを扱えるようにしたため、HTTP レベルの HOL blocking は緩和されたが、TCP レベルでは依然として存在する。
これは、パケットが順序どおりに到着しないと、後続のパケットがブロックされるという問題で、これがウェブパフォーマンスに影響を与える可能性がある。
具体的な問題② TCP 接続の設定とウォームアップ
TCP 接続を確立するためにはハンドシェイクが必要であり、それには時間がかかる。
また、TCP は輻輳制御というメカニズムを使用してネットワークの混雑を管理するが、これにより接続速度が最初は遅く、徐々に速度が上がる「ウォームアップ」が必要になる。これもパフォーマンスに影響を与える。
これらの問題を解決するために、HTTP の最新のバージョンである HTTP/3 では、従来の TCP(Transmission Control Protocol)を使わずに、QUIC(Quick UDP Internet Connections)プロトコルという新しいプロトコルを使用している。
QUIC は UDP(User Datagram Protocol)をベースに作られているが、一部の特性は TCP に近い。
通常、TCP は信頼性の高い接続を保証し、データの順序付けや再送信などを行なう。
一方、UDP はこれらの機能を提供しない代わりに、より高速なデータ転送が可能。
QUIC はこの UDP の高速性を保ちつつ、TCP のような信頼性の高さも持つように設計されている。
具体的には、データの再送信や順序付けなどの機能を実装している。
※https://recursionist.io/dashboard/course/33/lesson/1152 より画像引用
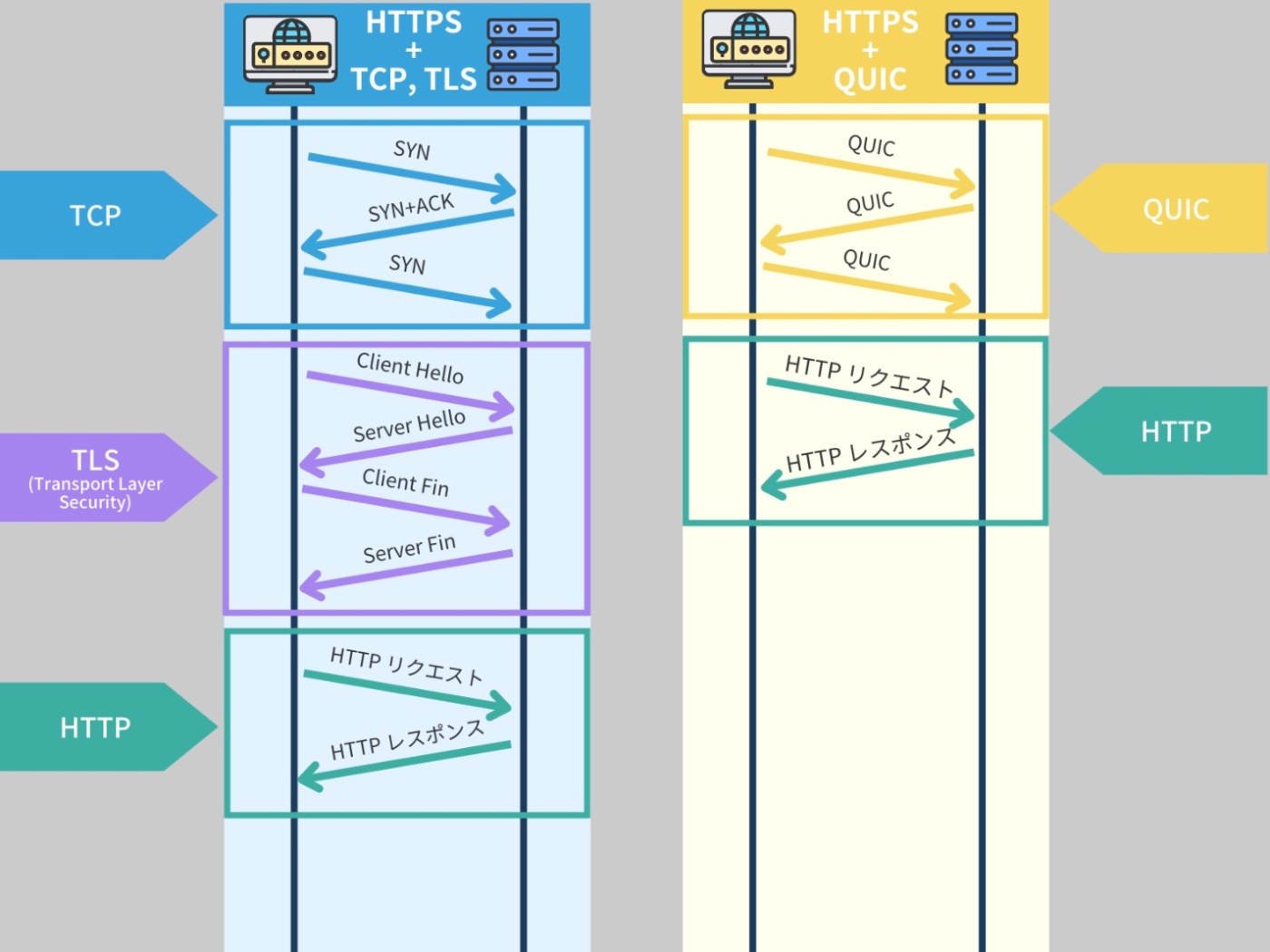
また、QUIC は接続確立時間の短縮、輻輳制御(ネットワークの混雑を抑えるための機能)の改善、IP 間の切り替え(例えば、スマートフォンがWi-Fiからモバイルデータへ切り替えるときなどの切り替え)をスムーズに行なうなど、TCP 以上の利点を提供している。
最新のウェブブラウザやアプリケーションはすでに QUIC、そして HTTP/3 をサポートしており、また、多くの大規模なインターネットサービス提供者もサーバ側を HTTP/3 に対応させている。
これにより、ユーザーは HTTP/3 の利点を享受でき、より高速で信頼性の高いインターネット接続を体験できる。
ウェブサーバを展開する際に気をつけること
ウェブサーバを展開する前には、適切な運用環境を準備することが必要。
サーバサイドアプリケーションの開発において、実際の運用環境を設定することは極めて重要で、これを行なうことは強く推奨される。
システムの機能要件はシステムが何を達成すべきかを定義する一方、非機能要件はシステムがどのように動作すべきか、またはシステムの品質特性を定義する。
ウェブサーバにおいては、サーバの運用環境とウェブアプリケーションのアーキテクチャが、非機能要件の決定に大きな影響を与える。
本番環境において重要となる 2 つの非機能要件は「利便性」と「信頼性」
利便性
ウェブサーバは、エンジニアが作業を行ないやすいような環境を提供する必要がある。
具体的な要素① 直感的なユーザインターフェース
ウェブサーバはエンジニアがサーバの設定を容易に変更し、その状態を確認し、様々な管理作業を簡単に行なえるような環境を提供すべき。
このインターフェースは、エンジニアがすぐに理解し、適切に操作できる形であることが重要。
具体的な要素② 豊富なドキュメンテーションと信頼性の高いツール
エンジニアがソフトウェアの実装を効率的に進められるよう、そして、問題が発生した場合でもすぐに原因を特定し解決策を見つけられるよう、ウェブサーバは十分なドキュメンテーションと信頼性の高いツールを提供すべき。
信頼性
ウェブサーバは確実に稼働し、エラーや問題に対してしっかりと対処する必要がある。
ハードウェアの最大限の利用
ウェブサーバは、提供されたハードウェアリソースを最大限に活用し、最良のパフォーマンスを達成することが求められる。
スケーリング能力
多数のユーザーからの要求に対して適応するため、ウェブサーバはその需要に応じてリソースを増減させる能力を持つべき。
フェイルオーバー機能
主要なシステムに問題が発生した場合でもサービスを続行するために、予備のシステムが自動的に動作を引き継ぐフェイルオーバー機能を設けることが必要。
監視と警告システム
信頼性に影響を及ぼす可能性のある問題や異常を迅速に識別し、対応するためには、事前に計画された監視と警告システムの設置が重要。
効率的なエラー処理と復旧策
エラーが発生した場合でも、ウェブサーバは迅速に問題を解決し、サービスを元に戻すための計画を持つべき。これにより、サービスのダウンタイムを最小限に抑えることができる。
これらの要件を満たすために、ウェブサーバの運用環境として Linux ディストリビューションを推奨される。
Linux ディストリビューション
Linux カーネルと一緒にパッケージ化されたソフトウェアの集まりのこと
Linux カーネルは OS の中心部で、ハードウェア(CPU、メモリ、ディスクなど)とソフトウェア(アプリケーションなど)の間の情報のやり取りをコントロールする。
しかし、カーネル自体には直接ユーザーと対話するための機能やインターフェースがほとんど含まれていない。
例えば、ウェブブラウザやテキストエディタ、画像エディタ、音楽プレーヤーといった具体的なアプリケーション、あるいはデスクトップ環境やファイルマネージャなどのユーザーインターフェースはカーネルには含まれない。これらは通常、カーネルの上に構築されるソフトウェア。
そこで Linux ディストリビューションは、Linux カーネルに各種のソフトウェアやツール、アプリケーションなどを追加して、わたしたちが使いやすい形にまとめている。
有名な Linux ディストリビューションとしては、Ubuntu、Debian、Fedora、Red Hat Enterprise Linux、CentOS、Arch Linux などがある。
これらは、それぞれ異なる目的や設計原則に基づいて開発され、パッケージ管理システム、デスクトップ環境、インストールプロセス、デフォルトで提供されるソフトウェアの選択、ハードウェアのサポートなどに違いがある。
仮想マシン(Virtual Machine)
Linux ディストリビューションを実行するための環境の 1 つ
仮想マシンは、物理的なコンピュータをソフトウェアレベルでエミュレートするもの。
これにより、一つの物理的なサーバやホストマシン上で複数の OS を同時に実行することが可能となる。
※https://recursionist.io/dashboard/course/33/lesson/1154 より画像引用
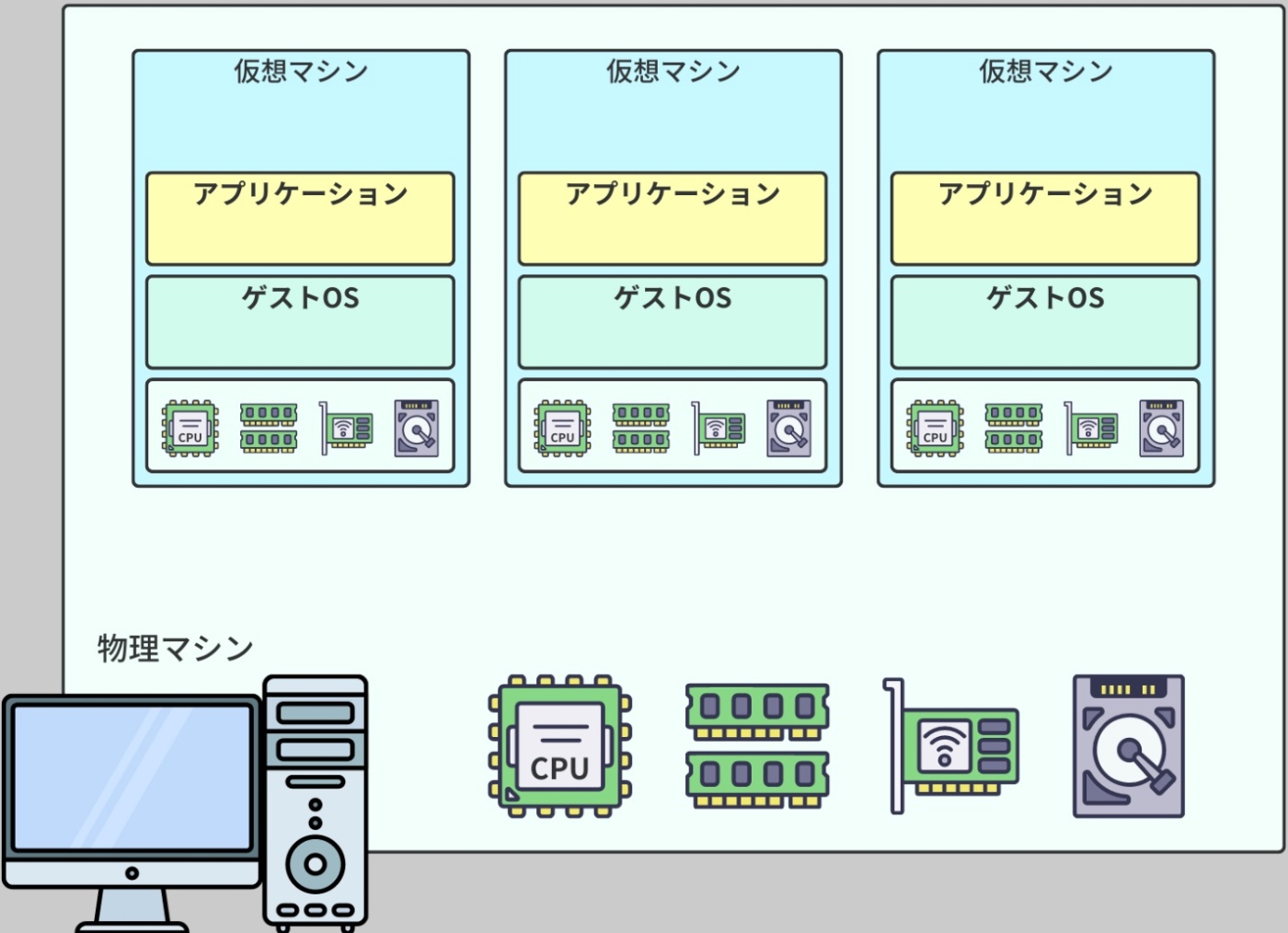
各仮想マシンは独立した環境として動作し、まるでそれぞれが独立した物理マシンであるかのように、自身の OS やアプリケーションを実行する。
仮想マシンは Linux ディストリビューションを実行できる環境として機能できる。
利便性
仮想マシンの一つの大きな利点は、設定とデプロイ(展開)が素早く行なえること。
エンジニアは、設定済みのテンプレートやイメージを使用して、仮想マシンを迅速に作成、複製、またはデプロイすることが可能。
さらに、VirtualBox などの仮想マシン用ソフトウェアは、仮想マシンの監視、操作、管理を行なうための直感的なインターフェースとツールを提供している。
信頼性
仮想マシンは、信頼性の観点からも有利。
テスト用の独立した環境を提供するとともに、スナップショットや仮想マシンイメージのレプリケーションを通じて、仮想マシンの複製やバックアップを容易に行なうためのツールも提供する。
これにより、ハードウェアの障害やシステムのクラッシュが起きた場合でも、サービスを素早く回復することが可能となる。
パーソナルコンピュータやデスクトップなどの個人的な環境で仮想マシンを稼働させても、そのような環境は通常、商用の要求(例えば高い可用性、99.99% の稼働時間、信頼性など)を満たすことは簡単ではない。
理由は、停電やインターネット接続の問題、アプリケーションのスケーリングに伴うパフォーマンス問題など、個々の環境で対応できない問題が発生する可能性があるため。
クラウド仮想マシン(cloud virtual machine)
より強固なインフラストラクチャが必要となり、その一例としてクラウドベースの仮想マシンが挙げられている。クラウド仮想マシンは、クラウドサービスプロバイダが提供する仮想的なコンピュータを指す。
これらはデータセンターの物理サーバ上でホストされ、インターネットを経由してどこからでもアクセスや管理が可能。
※https://recursionist.io/dashboard/course/33/lesson/1154 より画像引用
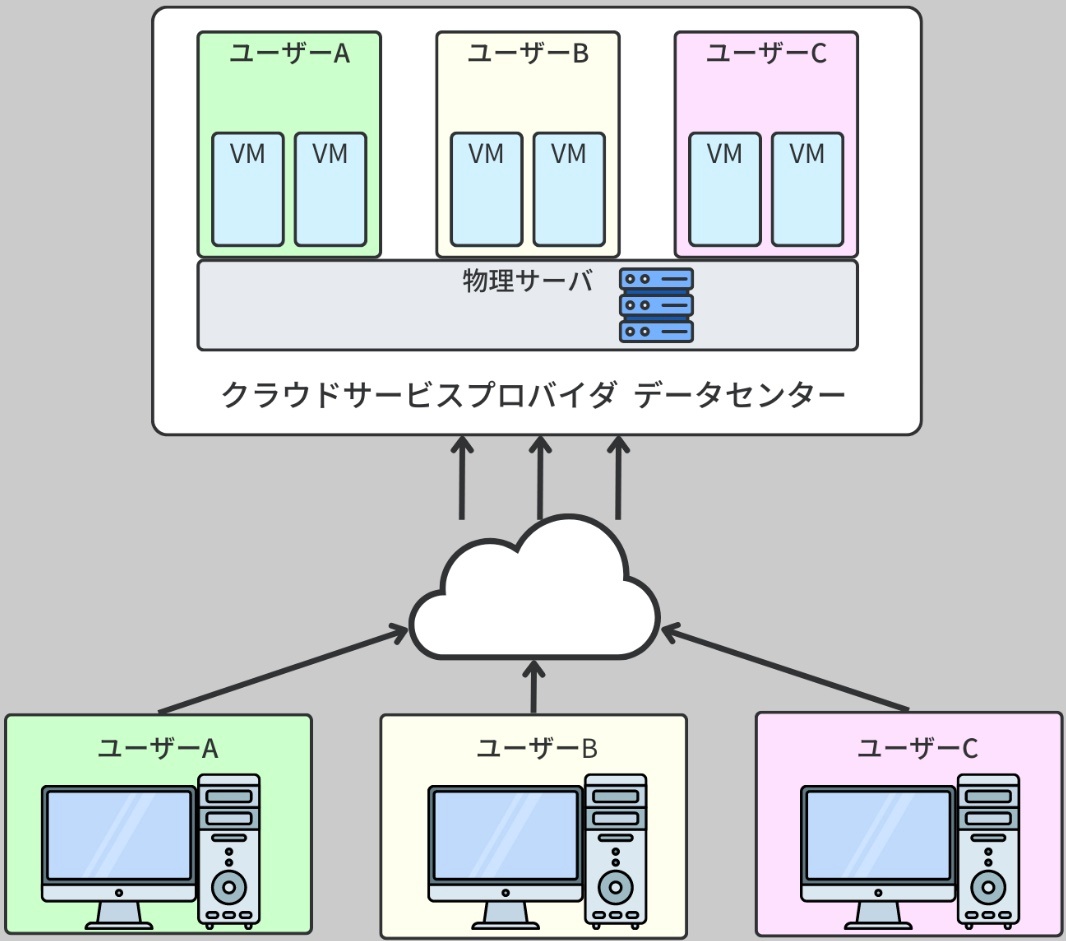
クラウド仮想マシンの利点は、個々の仮想マシン(VM インスタンス)とそれが動いている物理的なコンピュータ(ハードウェア)を、クラウドサービスプロバイダが一元的に管理してくれるところ。
これにより、企業は自社で物理的なインフラストラクチャを所有、運用、管理する必要がなくなる。
【クラウド仮想マシンの利点】
稼働率
主要なクラウド仮想マシンプロバイダは、少なくとも 99.99% のサーバ稼働率という信頼性を保証する。
自社で同じレベルの可用性を実現するためには、大規模なリソースが必要になる。
垂直スケーリング
ユーザーは必要に応じて仮想マシンに割り当てるリソースを調整できる。また、大きな停止時間や中断なしに、仮想マシンのCPU、メモリ、ストレージ容量を増減できる(弾力性)。
水平スケーリング
必要に応じてインスタンスを作成したり、削除したりすることが可能。
これはスナップショットの複製や、サーバノードを内部ネットワークに追加することを含む。
インフラストラクチャの構築
クラウド仮想マシンの物理サーバは、高速なインターネット接続、強力な電源、最新のコンピュータハードウェアが揃ったデータセンターに設置されている。
また、仮想化環境を保護するためのセキュリティ措置、ネットワーク隔離、暗号化、ファイアウォールなどのセキュリティとコンプライアンス機能もある。
※ハードウェア上の VM を使用してサーバをホストすることも可能だが、本番用のサーバを構築するためには、ホストコンピュータでネットワーク設定(静的 IP や予約済み DHCP リースなど)やファイアウォールなどのサイバーセキュリティ設定を追加的に行なう必要がある
ログの種類
| 種類 | 内容 | 主な目的 |
|---|---|---|
| アプリケーションログ | アプリの内部動作の記録 | デバッグ・障害調査 |
| アクセスログ | HTTPリクエストの記録 | 利用状況分析・不正アクセス監視 |
| エラーログ | 処理エラーの記録 | 障害特定 |
| システムログ | OS/サービスの動作ログ | サーバー異常の確認 |
| 監査ログ | 操作・変更の履歴 | セキュリティ対応・証跡保存 |
アプリケーションログ(Application Log)
アプリケーションの内部処理に関するログ
エラー、例外、処理の開始・終了などを記録する
INFO: ユーザー登録開始 user_id=123
ERROR: ユーザー登録失敗 user_id=123 reason=メールアドレスが重複
【目的】
・障害調査(バグ、例外の原因究明)
・仕様通りに処理されたかの追跡
・利用状況や傾向の把握
アクセスログ(Access Log)
クライアントからのリクエスト内容を記録するログ(主にWebサーバ)
127.0.0.1 - - [31/May/2025:10:12:56] "GET /login HTTP/1.1" 200 154
【目的】
・いつ・誰が・どこにアクセスしたかを把握
・セキュリティ監査(不審なアクセスの検知)
・パフォーマンス分析(レスポンスタイム、リクエスト頻度)
エラーログ(Error Log)
サーバやアプリケーションがエラーを出したときに記録するログ
[error] 502 Bad Gateway: PHP-FPMが応答しません
【目的】
・システムトラブルの特定(500エラー、DB接続失敗など)
・フロント側からは見えないエラーの把握
システムログ(System Log)
OSやサーバーそのものに関するログ(Linuxの syslog など)
May 31 10:12:01 server-name CRON[12345]: (root) CMD (/usr/bin/php /app/cron.php)
【目的】
・再起動、停止、ユーザーのログイン履歴などの記録
・サーバー自体の問題(リソース不足、サービス停止)の特定
監査ログ(Audit Log)
ユーザーの操作や管理者の設定変更などの記録
[Audit] Admin user "alice" changed user role of user_id=123 to "admin"
【目的】
・セキュリティ監査(だれが何をしたか)
・万が一のインシデント対応に必要な証跡