OCRモデル「Chandra」を試す
先週、私たちのOCRファミリーの最新モデルであるChandraをリリースしました 🚀
OCRリリースが忙しい週だったにもかかわらず、独立したベンチマークでトップを獲得し、素晴らしいコミュニティからのフィードバックを受け取りました。
Chandraは、パイプライン方式からフルページデコーディングへの移行を行い、複雑なレイアウト全体での忠実度を向上させます。
いくつかのエキサイティングなハイライト:
- 画像抽出 + キャプション付けによるレイアウト認識
- チャート → 構造化テーブル解析
- より強力な数式 + 手書きOCR
- ノイジーな入力からのより優れたテーブル + フォーム復元
パフォーマンス面では:
- 1台のH100で最大345Kページ/日
- オンプレミスおよび低遅延用途向けの量子化8B + 2Bバリアント
- 大規模時でも最小限の精度トレードオフ
オープンウェイト、ベンチマーク、APIアクセスはこちら → https://github.com/datalab-to/chandra
その構築、訓練、ベンチマークの方法が気になりますか?
@VikParuchuriの記事をこちらで詳しくお読みください:https://datalab.to/blog/introducing-chandra
公式のブログ
Dia によるまとめ。
Chandraは「ページ全体を理解して読む」ことに特化した次世代OCRだよ。
ざっくり:Chandraって何者?
Chandra は、Datalabが新しく作ったOCRモデルで、画像やPDFの「ページ全体」をそのまま読んで、文字・図・表・チェックボックス・数式までまとめて理解して取り出すタイプ。従来の「ブロック分けして順番に読む」方式じゃなく、ページのレイアウトを意識して一気に解読するのがキモだし、ベンチマークでもトップでウケるやつ。使われ方も増えてて、歴史資料の解読やAPI提供、HuggingFaceでトレンド入りとか、マジ勢いある。
- Chandra (https://github.com/datalab-to/chandra)
- read historical letters (https://x.com/VikParuchuri/status/1982426439707451599)
- trended on Huggingface (https://huggingface.co/datalab-to/chandra)
- gone live on our API (https://www.datalaahttps//x.com/VikParuchuri/status/1979240389799219523b.to/)
なんで新モデル作ったの?(背景)
前作の Surya / Marker はオープンソースで早くてカスタマイズ性も高いから人気だったんだけど、やり方は「ページをブロックに分割→各ブロックを個別に推論→合成」っていうパイプライン方式。これ、スピードは出るけど以下みたいな複雑ドキュメントで破綻しがちだったのよね。
- 手書きが混ざるフォーム。
- 多言語や旧フォントの混在。
- 表や図の構造化抽出(画像の切り出しやキャプション付与含む)。
- 数式の厳密再現(記号の取り違えが命取り)。
だから「ブロック分け前提」を捨てて、ページ全体をレイアウト込みで読むフルデコード型に舵切りした、って感じ。
- Surya (https://github.com/datalab-to/surya/)
- Marker (https://github.com/datalab-to/marker)
キー機能(ここがテンション上がる)
- レイアウト認識(Layout awareness)
ページ上の「何がどこにあるか」を理解して、テキストだけじゃなく画像や図も認識・抽出・キャプション付けができる。たとえば図表なら、画像そのものの切り出し+表構造のデータ化までいけるのが強いでしょ。- 数学(Math support)
実データ+合成データでがっつり鍛えてて、手書きの数式や旧フォントでも再現力が高い。細かい間違いが話題になるくらいの精度だけど、総合ではハイレベル。数式は1文字ズレるとアウトだから、この分野で強いのはガチ有利。- 表とフォーム(Tables & Forms)
昔はセル分割して各セルを推論してたけど、斜め文字やセル跨ぎの注記で情報落ちがち。Chandraはフルページで読むから、複雑な表でも構造・文字をまとめて認識しやすい。フォームも同様で、チェックボックスの有無みたいなUI要素まで拾ってくれるのがイイ感じ。旧世代との違いをひと言で
- パイプライン型(Surya/Marker): 速いけど、ページをバラして読むから関係性や位置情報が弱い。
- Chandra(フルページ+レイアウト認識): ページの文脈と構造を丸ごと掴めるから、画像・表・フォーム・数式までまとまりで正しく取り出せる。
メタファーで言うと、前者は「写真をバラしてパズルにしてから読む」、後者は「写真そのままを見て、その場の配置や空気感ごと読む」だもん。
どんな場面で刺さる?
- 官公庁・金融などの申請フォーム(手書き混在、チェック有無、印影など)。
- 研究資料や古文書の歴史的PDF(旧字体・旧フォント・紙焼けもあるある)。
- 学習教材・論文の数式入りドキュメント(Latex的再現が必須)。
- 論文や報告書の図表抽出→構造化(画像切り出し+テーブルをJSON/CSVへ)。
- マルチランゲージの実務書類(日本語+英語+数字+記号が混在、でもいける)。
はじめ方(リンク)
- モデル概要・デモなど: Chandra (https://github.com/datalab-to/chandra)
- 歴史資料の事例: read historical letters (https://x.com/VikParuchuri/status/1982426439707451599)
- モデル配布系の動向: trended on Huggingface (https://huggingface.co/datalab-to/chandra)
- 実務投入するなら: gone live on our API (https://www.datalaahttps//x.com/VikParuchuri/status/1979240389799219523b.to/)
- 参考: 旧モデルの思想や使い分け: Surya (https://github.com/datalab-to/surya/) / Marker (https://github.com/datalab-to/marker)
まとめ(超ざっくり)
- Chandraはレイアウトを理解してページを丸ごと読むから、画像・図・表・フォーム・数式を「つながりごと」取り出せる。
- 手書きや旧フォント、複雑表やチェックボックスみたいな現場の沼ポイントに強い。
- パイプライン型で詰まりがちな案件を、フルページ解読で突破する設計だし、ベンチでも強いから実務導入の本命。
ウチ的には、「現場にある“混沌PDF”をちゃんと料理できるOCR」って感じ。リア充案件でも地味案件でも、これ一台で回せるのはテンション上がるわ。
そういえば、以前にSurya試したことあった記憶(記事にはしてないけど)。流石にもう覚えてない・・・
GitHubレポジトリ
READMEから抜粋(翻訳はPLaMo翻訳)
Chandra
Chandraは、画像やPDFを構造化されたHTML/Markdown/JSON形式に変換しつつ、レイアウト情報を保持する高精度なOCRモデルです。
主な機能
- 詳細なレイアウト情報を保持したまま、文書をMarkdown/HTML/JSON形式に変換可能
- 手書き文字の認識精度が高い
- チェックボックスを含むフォームを正確に再構築
- 表形式データ、数式、複雑なレイアウト構成にもしっかり対応
- 画像や図表を抽出し、キャプションや構造化データとともに取得可能
- 40言語以上をサポート
- 推論モードとしてローカル環境(HuggingFace)版とリモート環境(vLLMサーバー)版の2種類を用意
ホスティングAPI
ベンチマーク結果
これらのスコアはolmocrベンチマークテストにおける総合結果です。
referred from https://github.com/datalab-to/chandra/詳細なスコアはこちらをご覧ください。
使用例
referred from https://github.com/datalab-to/chandra/
種類 名称 リンク 表形式 水害被害報告書 閲覧 表形式 10Kファイリング 閲覧 フォーム 手書きフォーム 閲覧 フォーム リース契約書 閲覧 手書き文書 医師の診断書 閲覧 手書き文書 数学の宿題 閲覧 書籍 地理教科書 閲覧 書籍 練習問題 閲覧 数学 注意図表 閲覧 数学 ワークシート 閲覧 数学 EGAページ 閲覧 新聞 ニューヨーク・タイムズ 閲覧 新聞 ロサンゼルス・タイムズ 閲覧 その他 トランスクリプト 閲覧 その他 フローチャート 閲覧


商用利用について
本コードはApache 2.0ライセンスを採用しており、モデルの重みデータには修正版OpenRAIL-Mライセンスが適用されています(研究用途・個人利用・200万ドル未満の資金調達/収益規模のスタートアップは無料利用可能。ただし、当社APIと競合する用途での使用はできません)。OpenRAILライセンスの制約を解除する場合、またはより広範な商用ライセンスをご希望の場合は、当社の価格ページこちらをご覧ください。
ベンチマーク比較表
モデル ArXiv Old Scans Math Tables Old Scans ヘッダー/フッター処理 多列処理 長文テキスト処理 ベースライン 総合スコア 出典 Datalab Chandra v0.1.0 82.2 80.3 88.0 50.4 90.8 81.2 92.3 99.9 83.1 ± 0.9 自社ベンチマーク Datalab Marker v1.10.0 83.8 69.7 74.8 32.3 86.6 79.4 85.7 99.6 76.5 ± 1.0 自社ベンチマーク Mistral OCR API 77.2 67.5 60.6 29.3 93.6 71.3 77.1 99.4 72.0 ± 1.1 olmocrリポジトリ Deepseek OCR 75.2 72.3 79.7 33.3 96.1 66.7 80.1 99.7 75.4 ± 1.0 自社ベンチマーク GPT-4o (アンカー付き) 53.5 74.5 70.0 40.7 93.8 69.3 60.6 96.8 69.9 ± 1.1 olmocrリポジトリ Gemini Flash 2 (アンカー付き) 54.5 56.1 72.1 34.2 64.7 61.5 71.5 95.6 63.8 ± 1.2 olmocrリポジトリ Qwen 3 VL 8B 70.2 75.1 45.6 37.5 89.1 62.1 43.0 94.3 64.6 ± 1.1 自社ベンチマーク olmOCR v0.3.0 78.6 79.9 72.9 43.9 95.1 77.3 81.2 98.9 78.5 ± 1.1 olmocrリポジトリ dots.ocr 82.1 64.2 88.3 40.9 94.1 82.4 81.2 99.5 79.1 ± 1.0 dots.ocrリポジトリ
ライセンスはちょっと注意が必要かな。
なおモデルは以下。9B。
セットアップについては、READMEやモデルカードを見る限り、提供されているPyPIパッケージをインストールすることで、以下のような使い方ができるみたい
- CLI
- StreamlitのWebアプリ
- vLLMサーバ
- Pythonコードから利用(パッケージ単体 or Transformers)
今回はローカルのUbuntu−22.04サーバ(RTX4090)で試す。
uvでPython仮想環境作成
mkdir chandra-ocr-work && cd $_
uv venv -p 3.12 --seed
source .venv/bin/activate
パッケージ追加。PyTorchもインストールされるので --torch-backend=autoをつけたほうが良さそう。
uv pip install chandra-ocr --torch-backend=auto
(snip)
+ chandra-ocr==0.1.8
(snip)
これでいくつかのCLIコマンドがインストールされているはず。
ls -l .venv/bin/chandra*
-rwxrwxr-x 1 kun432 kun432 331 11月 1 22:54 .venv/bin/chandra
-rwxrwxr-x 1 kun432 kun432 335 11月 1 22:54 .venv/bin/chandra_app
-rwxrwxr-x 1 kun432 kun432 342 11月 1 22:54 .venv/bin/chandra_screenshot
-rwxrwxr-x 1 kun432 kun432 332 11月 1 22:54 .venv/bin/chandra_vllm
CLIの基本は chandra の様子。Usageを見てみる。
uv run chandra --help
Usage: chandra [OPTIONS] INPUT_PATH OUTPUT_PATH
Options:
--method [hf|vllm] Inference method: 'hf' for local model,
'vllm' for vLLM server.
--page-range TEXT Page range for PDFs (e.g., '1-5,7,9-12').
Only applicable to PDF files.
--max-output-tokens INTEGER Maximum number of output tokens per page.
--max-workers INTEGER Maximum number of parallel workers for vLLM
inference.
--max-retries INTEGER Maximum number of retries for vLLM
inference.
--include-images / --no-images Include images in output.
--include-headers-footers / --no-headers-footers
Include page headers and footers in output.
--save-html / --no-html Save HTML output files.
--batch-size INTEGER Number of pages to process in a batch.
--paginate_output
--help Show this message and exit.
上記のオプションやざっとコードを見た限り、ざっくり以下のような感じらしい。
-
chandra- CLI
- 2つの方法が使える
- HuggingFaceからダウンロードしたローカルモデルを使って推論
- 後述のvLLMサーバを起動しておくと、クライアントとして機能する。デフォルトはこちら。
-
chandra_vllm- vLLMサーバを起動してChandraをサーブ
-
chandra_app- Streamlit製のGUIアプリ
-
chandra_screenshot- OCR結果のスクショを取りやすくしたFlask製GUIアプリ?
CLI
とりあえずCLIで試す。CLIは2つの方法があって、
- vLLMサーバを起動してモデルをロード、
chandraコマンドはそこにアクセスするクライアントとして使う。 -
chandraコマンドからTransformersで直接モデルをロードして、推論。
デフォルトは前者のようなので、まずはそちらで。
まずchandra_vllmコマンドでvLLMのサーバを起動する。
chandra_vllm
どうやらvLLMはDockerで起動するみたい。イメージはそこそこ大きいようで結構時間がかかるので気長に待つ。
Starting vLLM server with command: sudo docker run --runtime nvidia --gpus device=0 -v /home/kun432/.cache/huggingface:/root/.cache/huggingface --env VLLM_ATTENTION_BACKEND=TORCH_SDPA -p 8000:8000 --ipc=host vllm/vllm-openai:latest --model datalab-to/chandra --no-enforce-eager --max-num-seqs 32 --dtype bfloat16 --max-model-len 32768 --max_num_batched_tokens 65536 --gpu-memory-utilization .9 --served-model-name chandra
(snip)
[sudo] kun432 のパスワード:
Unable to find image 'vllm/vllm-openai:latest' locally
latest: Pulling from vllm/vllm-openai
8f84a9f2102e: Pull complete
b95112eaf283: Pull complete
030ef8250936: Pull complete
(snip)
そして・・・
(EngineCore_DP0 pid=182) ERROR 11-01 09:33:36 [core.py:708] torch.OutOfMemoryError: CUDA out of memory. Tried to allocate 4.69 GiB. GPU 0 has a total capacity of 23.49 GiB of which 3.57 GiB is free. Including non-PyTorch memory, this process has 19.69 GiB memory in use. Of the allocated memory 19.12 GiB is allocated by PyTorch, and 97.79 MiB is reserved by PyTorch but unallocated. If reserved but unallocated memory is large try setting PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True to avoid fragmentation. See documentation for Memory Management (https://pytorch.org/docs/stable/notes/cuda.html#environment-variables)
chandra_vllmコマンドのコードを見ると、パラメータはほぼいじれない感じに見える。
ログやコマンドを見る限りDockerコマンドを実行しているだけのようなので、少しパラメータを下げて、あとイメージ側にbitsandbytesもインストールされているようなので量子化を有効にして直接実行したら起動した。
docker run \
--runtime nvidia \
--gpus device=0 \
-v /home/kun432/.cache/huggingface:/root/.cache/huggingface \
-e VLLM_ATTENTION_BACKEND=TORCH_SDPA \
-p 8000:8000 \
--ipc=host \
vllm/vllm-openai:latest \
--model datalab-to/chandra \
--no-enforce-eager \
--max-num-seqs 4 \
--dtype bfloat16 \
--max-model-len 16384 \
--max_num_batched_tokens 32768 \
--gpu-memory-utilization 0.9 \
--quantization bitsandbytes \
--served-model-name chandra
別ターミナルを開いて続きはそちらで。
サンプルとして、神戸市が公開している観光に関する統計・調査資料のうち、「令和5年度 神戸市観光動向調査結果について」のPDFを使用する。
PDFをダウンロード
wget https://www.city.kobe.lg.jp/documents/15123/r5_doukou.pdf
ではPDFと出力先ディレクトリを指定してchandraコマンドを実行。
chandra r5_doukou.pdf ./output
今回の場合は約6分程度で完了。
Chandra CLI - Starting OCR processing
Input: r5_doukou.pdf
Output: output
Method: vllm
Loading model with method 'vllm'...
Model loaded successfully.
Found 1 file(s) to process.
[1/1] Processing: r5_doukou.pdf
Loaded 21 page(s)
Processing pages 1-21...
Saved: output/r5_doukou/r5_doukou.md (21 page(s))
Completed: r5_doukou.pdf
Processing complete. Results saved to: output
以下のような感じで出力される。
tree output/
output/
└── r5_doukou
├── 087aaef3d76916f3e926235a1804bff5_10_img.webp
├── 087aaef3d76916f3e926235a1804bff5_5_img.webp
├── 110b9b35c6b4f2b242633288a7b1d177_5_img.webp
├── 28ccfe0c904ba7fb9646aac569e67a67_5_img.webp
├── 28ccfe0c904ba7fb9646aac569e67a67_6_img.webp
├── 51b747205412b28733d1080a16f86ce7_5_img.webp
├── 91f4aee53dd430d6f99d99cedbcbc85a_6_img.webp
├── 91f4aee53dd430d6f99d99cedbcbc85a_7_img.webp
├── abfbcfd7303e34a0bd36761dc8748eed_5_img.webp
├── b9a65ecb9e05ae98b6b2a43507770170_5_img.webp
├── c193c3df5df2a1f86a576ac3899d99eb_1_img.webp
├── c193c3df5df2a1f86a576ac3899d99eb_2_img.webp
├── cd97808baaaadfd18952d50e1ccff5a5_5_img.webp
├── cf63cc45158cff50b3189200f03216a2_5_img.webp
├── d67dee79c6a4bb03167fe2c6f7af0bf9_6_img.webp
├── e02d5ff0a3e4602db9d4af68162f6bab_6_img.webp
├── e4130c6e4dde264c3684286d09afa6c6_5_img.webp
├── f267bf89bca75df13be368c2983f4500_7_img.webp
├── f267bf89bca75df13be368c2983f4500_8_img.webp
├── f69ec88e40ac9add7f1ae992a11fe39c_11_img.webp
├── f69ec88e40ac9add7f1ae992a11fe39c_6_img.webp
├── f8a56515820892e199fa5e6ec6fb47b5_6_img.webp
├── r5_doukou.html
├── r5_doukou.md
└── r5_doukou_metadata.json
1 directory, 25 files
なるほど、全ページ分まとめて、HTMLとMarkdownで出力される。webpはページ内に含まれる画像みたい。あとメタデータのJSONファイルがある・
HTMLをChromeで表示してみた結果。


MarkdownをVSCodeでプレビュー表示してみた結果。


HTML・Markdown内に画像へのリンクが含まれているのでビューワーなどでも参照できているのがわかる。あと画像部分についてもどうやら読み取ろうとしているのがわかる。
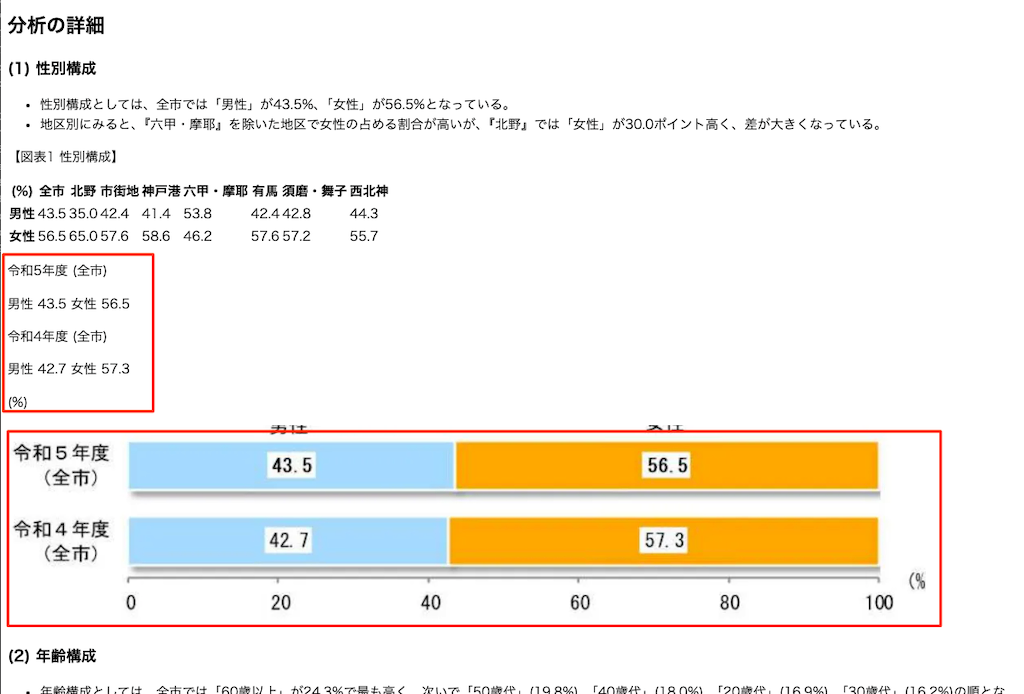
ただここはちょっと完璧ではなくて、以下のように英語で説明されてしまっているものもあったりする。まあなんというかLLMらしさみたいに感じる。ここは良し悪しかも。

その他気になったところとしては、
- 表組みは少し崩れてるところもあったが、概ね良い感じに思える。
- Markdownでは表はtableタグで表現される。
- Markdownの場合、表・画像の直後に見出しタグがあるケースでは、改行されずに表に続けて出力されてしまっているようで、その場合は見出しが正しくレンダリングされない。
というところかな。全体として読み取り精度は高そうな印象。
あとメタデータファイルには各ページごとのトークン数などが含まれている様子。
{
"file_name": "r5_doukou.pdf",
"num_pages": 21,
"total_token_count": 37058,
"total_chunks": 176,
"total_images": 22,
"pages": [
{
"page_num": 0,
"page_box": [
0,
0,
1587,
2246
],
"token_count": 1719,
"num_chunks": 10,
"num_images": 0
},
{
"page_num": 1,
"page_box": [
0,
0,
1587,
2246
],
"token_count": 1581,
"num_chunks": 19,
"num_images": 0
},
(snip)
CLIのオプションも参照されたし。
ただここはちょっと完璧ではなくて、以下のように英語で説明されてしまっているものもあったりする。まあなんというかLLMらしさみたいに感じる。ここは良し悪しかも。
処理後のコンテンツとしては良し悪しなのかもなーと思いつつ、グラフ部分そのものの認識はちゃんと読めてる気がする。グラフのプロットなんかを正しく取得するするのって結構難しい気がするので、別で試してみたい。
vLLMサーバを使わずに、直接transformesでモデルをロードして推論する場合は以下
chandra r5_doukou.pdf ./output --method hf
まあこちらの場合、コマンド実行ごとにモデルをロードすることになると思うので、1回だけしか実行しない、とかでなければvLLMサーバ使うほうがいいかなぁという気はする。量子化みたいなオプションもなさそうだしね。
Streamlit
デモ用としてStreamlitのWebアプリも用意されている。以下で起動。
chandra_app
ブラウザでアクセス。モデルをvLLM / hf(Transformers)のどちらでロードするかを指定。vLLMの場合は chandra_vllm を実行しておく必要がある。

PDFをアップロードしてOCRを実行。
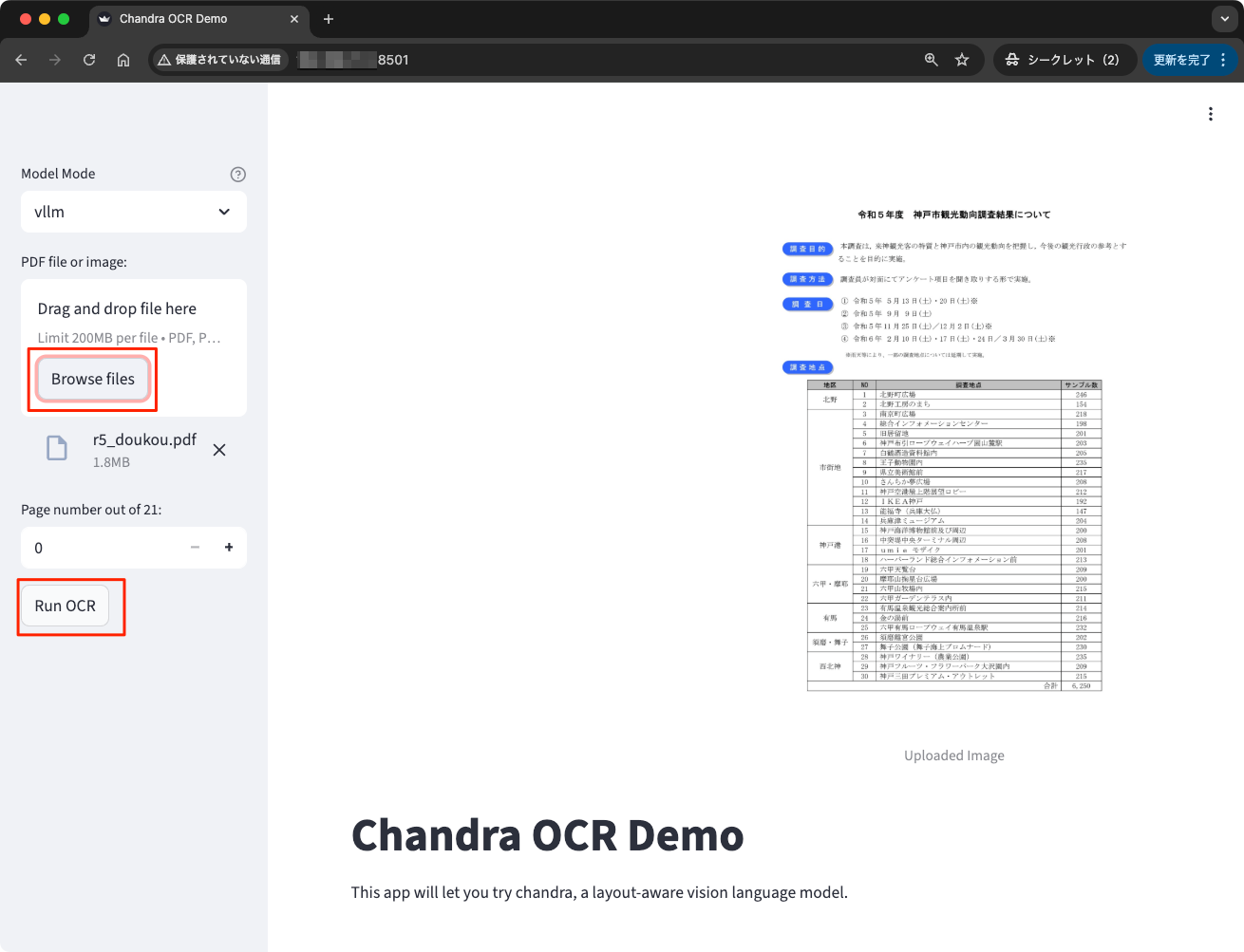
こんな感じでPDFのプレビューとHTMLの出力を並べて見れる。

あと、タブを切り替えると、OCRの認識部分にバウンディングボックスをつけたものも確認できる。
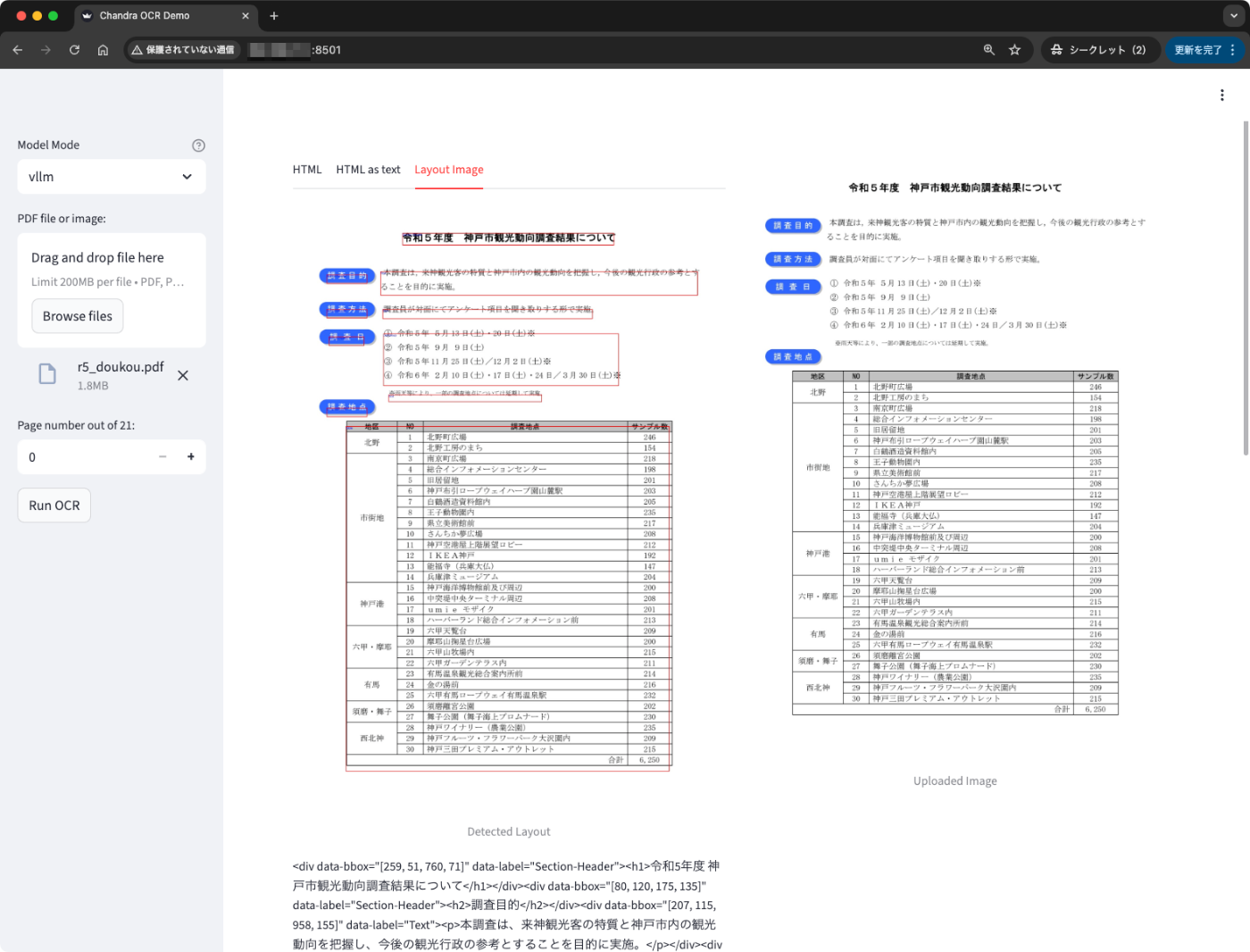
なお、このデモではページ単位でOCRを実行しないといけない模様。ページを切り替えるには左メニューの下で切り替えてOCRすればよい。

まとめ
そこまできっちり比較したわけではないけど、精度はまあ良さそうかな。ベンチマークでは dots.OCR などよりも精度が高いことを謳っているようだし。
ただ、過去にdots.ocrを試した際の記憶からすると、dots.ocrのほうがVRAM要件なども多分低いと思うし、推論速度も速かったと思う。あと使い勝手もdots.ocrのほうがいいかなーという気がするので、まあ劇的に良いか、というと、個人的にはどっちでもいいかなーというところ。OCR化したいドキュメントによって変わってきそうな気もするので、実際に試して判断するべしかな。
ただ、最近はOCR用途で高精度なモデルが立て続けに出てきているので、競争が激しくていいね。