Qwen3-VL Cookbooksを試す ②Powerful Document Parsing Capabilities(高度な文書解析機能)
以下の続き
今回は「高度な文書解析機能」
ノートブックの冒頭部分には以下とある。(翻訳はPLaMo翻訳)
Qwen3-VLによる文書解析機能の紹介
本ノートブックでは、当社のモデルが備える高度な文書解析機能をご紹介します。このモデルはあらゆる画像を入力として受け取り、HTML、JSON、Markdown、LaTeXといった多様な形式でその内容を出力可能です。特に注目すべきは、以下の2つの独自フォーマットです:
- Qwenvl HTMLフォーマット:各構成要素に位置情報を追加することで、文書の正確な再構築と操作を可能にします。
- Qwenvl Markdownフォーマット:画像全体の内容をMarkdown形式に変換します。このフォーマットでは、すべての表をLaTeX形式で表現し、各表の前に座標情報を明示します。また、画像は座標ベースのプレースホルダーに置き換えられ、正確な配置が可能になります。
これにより、非常に詳細で柔軟な文書解析と再構築が可能となります。
なるほど、文書構造とレイアウトを保持した出力ができると。
前回同様、ノートブックはDashScopeでのAPI利用が前提になっているので、Transformersを使う形に書き換えて試すことにする。Colaboratory & Qwen3-VL-8B-Instructで。
パッケージインストールや推論コードは前回と同様なので割愛。興味があれば以下。
パッケージインストールなど
!pip install -U transformers
!pip install qwen-vl-utils
!pip install flash-attn --no-build-isolation
!pip freeze | egrep -i "^(transformers|qwen-vl-utils|flash_attn)"
flash_attn==2.8.3
qwen-vl-utils==0.0.14
transformers==4.57.1
from transformers import Qwen3VLForConditionalGeneration, AutoProcessor
model_path = "Qwen/Qwen3-VL-8B-Instruct"
processor = AutoProcessor.from_pretrained(model_path)
model = Qwen3VLForConditionalGeneration.from_pretrained(
model_path,
dtype="auto",
device_map="auto",
attn_implementation="flash_attention_2",
)
import torch
from transformers import (
LogitsProcessor,
LogitsProcessorList,
)
from qwen_vl_utils import process_vision_info
class PresencePenaltyProcessor(LogitsProcessor):
"""
Apply a presence penalty: discourage generating tokens that have already appeared
in the generated sequence (not frequency-based, but presence-based).
This mimics OpenAI-style presence_penalty in a simple way by subtracting a fixed
penalty from logits of any token present at least once in the generated tokens.
"""
def __init__(self, presence_penalty: float):
super().__init__()
if presence_penalty < 0:
raise ValueError("presence_penalty must be >= 0.")
self.presence_penalty = presence_penalty
def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor) -> torch.FloatTensor:
# input_ids shape: (batch, cur_len)
# scores shape: (batch, vocab_size)
batch_size = input_ids.shape[0]
for b in range(batch_size):
seen = set(input_ids[b].tolist())
if len(seen) == 0:
continue
# Subtract penalty from logits of seen tokens
# Note: scores[b] is (vocab_size,)
# Efficient masking
indices = torch.tensor(list(seen), device=scores.device, dtype=torch.long)
# Clamp indices to valid range just in case
indices = indices[(indices >= 0) & (indices < scores.shape[-1])]
if indices.numel() > 0:
scores[b, indices] -= self.presence_penalty
return scores
def inference(
messages,
max_new_tokens=16384,
do_sample=True,
top_p=0.8,
top_k=20,
temperature=0.7,
repetition_penalty=1.0,
presence_penalty=1.5
):
"""
Generates a response from the Qwen3-VL model based on the provided messages and generation options.
Args:
messages (list): A list of message dictionaries in the expected format.
max_new_tokens (int): The maximum number of new tokens to generate.
do_sample (bool): Whether to use sampling.
top_p (float): The cumulative probability for top-p sampling.
top_k (int): The number of highest probability vocabulary tokens to keep for top-k sampling.
temperature (float): The temperature for sampling.
repetition_penalty (float): The penalty for repeating tokens.
presence_penalty (float): The penalty for tokens that have already appeared.
Returns:
str: The generated text response.
"""
text = processor.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
images, videos, video_kwargs = process_vision_info(
messages,
image_patch_size=16,
return_video_kwargs=True,
return_video_metadata=True
)
if videos is not None:
videos, video_metadatas = zip(*videos)
videos, video_metadatas = list(videos), list(video_metadatas)
else:
video_metadatas = None
inputs = processor(
text=text,
images=images,
videos=videos,
video_metadata=video_metadatas,
return_tensors="pt",
do_resize=False,
**video_kwargs
)
inputs = inputs.to(model.device)
logits_processors = LogitsProcessorList()
if presence_penalty and presence_penalty > 0:
logits_processors.append(PresencePenaltyProcessor(presence_penalty))
generated_ids = model.generate(
**inputs,
max_new_tokens=max_new_tokens,
do_sample=do_sample,
top_p=top_p,
top_k=top_k,
temperature=temperature,
repetition_penalty=repetition_penalty,
logits_processor=logits_processors,
)
generated_ids_trimmed = [
out_ids[len(in_ids) :]
for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed,
skip_special_tokens=True,
clean_up_tokenization_spaces=False
)
return output_text[0]
使う場合はこんな感じで。qwen-vl-utilsを使うと画像や動画の処理が色々便利になるっぽい。詳しくはここ。
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"image": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg",
},
{"type": "text", "text": "この画像について説明して。"},
],
}
]
response = inference(messages)
print(response)
この画像は、穏やかな夕暮れ時のビーチで、女性と犬が楽しそうに遊んでいる様子を捉えたものです。
主な描写:
人物とペット:
- 女性は、チェック柄のシャツと黒いパンツを着用し、砂浜に座っています。
- 彼女は笑顔で、手を広げて前足を上げた犬と「ハイタッチ」をしているように見えます。
- 犬は黄色いラブラドール・レトリバーで、カラフルなハーネスをつけています。前足を上げて女性と触れ合っており、非常に親しみやすい姿勢です。
背景と環境:
- 背景には穏やかな海と、夕日が沈む空が広がっています。
- 夕日の光が柔らかく、全体に温かみのあるオレンジ色のトーンを与えています。
- 海の波が優しく岸辺に打ち寄せているのが見えます。
雰囲気:
- 画像全体からは、平和で心地よい、人間とペットの絆を感じさせる穏やかな瞬間が伝わってきます。
- ライトの演出により、ドラマチックかつロマンティックな印象も加わっています。
この画像は、ペットとの楽しい時間や、自然の中で過ごすリラックスした日常を表現しており、視覚的にも心地よい印象を与える作品です。
ではまず画像を解析してHTMLとして出力する。サンプルの画像はこんな感じ。
import IPython.display
IPython.display.Image("https://ofasys-multimodal-wlcb-3-toshanghai.oss-cn-shanghai.aliyuncs.com/Qwen3VL/demo/omni_parsing/179729.jpg", width=600)
有価証券報告書かな?

ではこれを使って推論する。
import requests
from io import BytesIO
import os
import base64
from PIL import Image
# 画像を取得して保存
img_url = "https://ofasys-multimodal-wlcb-3-toshanghai.oss-cn-shanghai.aliyuncs.com/Qwen3VL/demo/omni_parsing/179729.jpg"
response = requests.get(img_url)
img_name = os.path.basename(img_url)
image = Image.open(BytesIO(response.content))
image.save(img_name)
# qwen-vl-utilsだと、URL / ローカルパス / PIL.Image.Image / Base64エンコードなどで指定すれば
# よしなにモデルへの入力を処理してくれる様子。他にも画像サイズの指定やリサイズなどのオプションがある様子。
# 今回はbase64エンコードで。
def encode_image(image_path):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode("utf-8")
base64_image = encode_image(img_name)
min_pixels = 512*32*32
max_pixels = 2048*32*32
messages=[
{
"role": "user",
"content": [
{
"type": "image",
"min_pixels": min_pixels,
"max_pixels": max_pixels,
# BASE64エンコードされた画像データを引数として渡してください。
# なお、画像形式(例: image/{format})は、サポートされている画像形式リストのContent Typeと一致している必要があります。
# "f"は文字列フォーマットのメソッドを表します。
# - PNG: f"data:image/png;base64,{base64_image}"
# - JPEG: f"data:image/jpeg;base64,{base64_image}"
# - WEBP: f"data:image/webp;base64,{base64_image}"
"image": f"data:image/jpeg;base64,{base64_image}",
},
{"type": "text", "text": "qwenvl html"},
],
}
]
response = inference(messages)
print(response)
qwen-vl-utilsを使うと、メッセージ内に画像や動画が含まれている場合、モデルの入力に合うようによしなに処理してくれるようだが、コメントにあるようにいろいろなフォーマットで指定ができたりサイズの指定やリサイズなどもできたりするみたい。今回のサンプルではBase64でエンコードしている。
あとプロンプトが特殊なもの(qwenvl html)に見えるのだけど、これはHTMLで出力させたい場合に固定で指定すべきものかどうかはわからない。
結果。
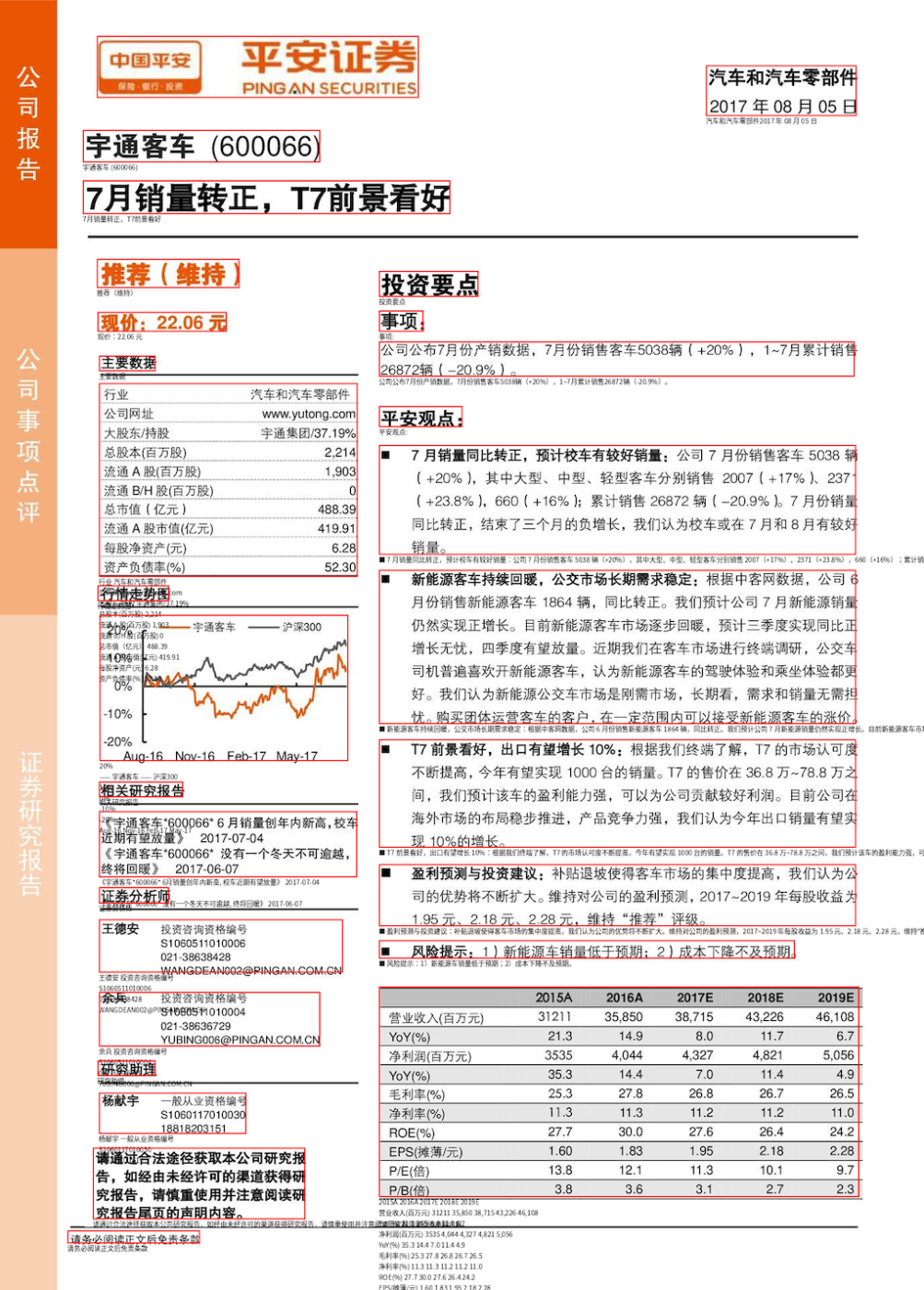
```html
<html><body>
<div class="image" data-bbox="105 28 453 76"><img data-bbox="105 28 453 76"/></div>
<div class="image" data-bbox="764 51 927 90">汽车和汽车零部件<br/>2017 年 08 月 05 日</div>
<div class="image" data-bbox="90 101 346 126">宇通客车 (600066)</div>
<div class="image" data-bbox="90 140 487 166">7月销量转正,T7前景看好</div>
<div class="image" data-bbox="105 201 259 223">推荐(维持)</div>
<div class="image" data-bbox="106 242 245 257">现价:22.06 元</div>
<div class="image" data-bbox="107 276 168 288">主要数据</div>
<div class="image" data-bbox="107 297 387 447">行业 汽车和汽车零部件
公司网址 www.yutong.com
大股东/持股 宇通集团/37.19%
总股本(百万股) 2,214
流通 A 股(百万股) 1,903
流通 B/H 股(百万股) 0
总市值(亿元) 488.39
流通 A 股市值(亿元) 419.91
每股净资产(元) 6.28
资产负债率(%) 52.30</div>
<div class="image" data-bbox="106 454 183 466">行情走势图</div>
<div class="image" data-bbox="108 477 377 590">20%
—— 宇通客车 —— 沪深300
10%
0%
-10%
-20%
Aug-16 Nov-16 Feb-17 May-17</div>
<div class="image" data-bbox="107 606 198 618">相关研究报告</div>
<div class="image" data-bbox="107 629 386 680">《宇通客车*600066* 6月销量创年内新高, 校车近期有望放量》 2017-07-04
《宇通客车*600066* 没有一个冬天不可逾越, 终将回暖》 2017-06-07</div>
<div class="image" data-bbox="107 688 183 700">证券分析师</div>
<div class="image" data-bbox="107 713 371 754">王德安 投资咨询资格编号
S1060511010006
021-38638428
WANGDEAN002@PINGAN.COM.CN</div>
<div class="image" data-bbox="107 769 346 811">余兵 投资咨询资格编号
S1060511010004
021-38636729
YUBING006@PINGAN.COM.CN</div>
<div class="image" data-bbox="106 822 168 834">研究助理</div>
<div class="image" data-bbox="107 847 266 879">杨献宇 一般从业资格编号
S1060117010030
18818203151</div>
<div class="image" data-bbox="101 890 330 945">请通过合法途径获取本公司研究报告,如经由未经许可的渠道获得研究报告,请慎重使用并注意阅读研究报告尾页的声明内容。</div>
<div class="image" data-bbox="410 210 518 230">投资要点</div>
<div class="image" data-bbox="410 241 458 257">事项:</div>
<div class="image" data-bbox="410 265 925 292">公司公布7月份产销数据,7月份销售客车5038辆(+20%),1~7月累计销售26872辆(-20.9%)。</div>
<div class="image" data-bbox="410 315 500 331">平安观点:</div>
<div class="image" data-bbox="410 345 926 430">■ 7 月销量同比转正,预计校车有较好销量:公司 7 月份销售客车 5038 辆(+20%),其中大型、中型、轻型客车分别销售 2007(+17%)、2371(+23.8%),660(+16%);累计销售 26872 辆(-20.9%)。7 月份销量同比转正,结束了三个月的负增长,我们认为校车或在 7 月和 8 月有较好销量。</div>
<div class="image" data-bbox="410 442 926 561">■ 新能源客车持续回暖,公交市场长期需求稳定:根据中客网数据,公司 6 月份销售新能源客车 1864 辆,同比转正。我们预计公司 7 月新能源销量仍然实现正增长。目前新能源客车市场逐步回暖,预计三季度实现同比正增长无忧,四季度有望放量。近期我们在客车市场进行终端调研,公交车司机普遍喜欢开新能源客车,认为新能源客车的驾驶体验和乘坐体验都更好。我们认为新能源公交车市场是刚需市场,长期看,需求和销量无需担忧。购买团体运营客车的客户,在一定范围内可以接受新能源客车的涨价。</div>
<div class="image" data-bbox="410 573 926 657">■ T7 前景看好,出口有望增长 10%:根据我们终端了解,T7 的市场认可度不断提高,今年有望实现 1000 台的销量。T7 的售价在 36.8 万~78.8 万之间,我们预计该车的盈利能力强,可以为公司贡献较好利润。目前公司在海外市场的布局稳步推进,产品竞争力强,我们认为今年出口销量有望实现 10%的增长。</div>
<div class="image" data-bbox="410 670 926 718">■ 盈利预测与投资建议:补贴退坡使得客车市场的集中度提高,我们认为公司的优势将不断扩大。维持对公司的盈利预测,2017~2019 年每股收益为 1.95 元、2.18 元、2.28 元,维持“推荐”评级。</div>
<div class="image" data-bbox="410 729 860 743">■ 风险提示:1)新能源车销量低于预期;2)成本下降不及预期。</div>
<div class="image" data-bbox="410 765 930 928">2015A 2016A 2017E 2018E 2019E
营业收入(百万元) 31211 35,850 38,715 43,226 46,108
YoY(%) 21.3 14.9 8.0 11.7 6.7
净利润(百万元) 3535 4,044 4,327 4,821 5,056
YoY(%) 35.3 14.4 7.0 11.4 4.9
毛利率(%) 25.3 27.8 26.8 26.7 26.5
净利率(%) 11.3 11.3 11.2 11.2 11.0
ROE(%) 27.7 30.0 27.6 26.4 24.2
EPS(摊薄/元) 1.60 1.83 1.95 2.18 2.28
P/E(倍) 13.8 12.1 11.3 10.1 9.7
P/B(倍) 3.8 3.6 3.1 2.7 2.3</div>
<div class="image" data-bbox="73 954 216 964">请务必阅读正文后免责条款</div>
</body></html>
```
HTMLっぽいのだが、バウンディングボックスの情報が含むタグが含まれている。これがQwenVL独自のHTMLフォーマットらしい。
このバウンディングボックス情報を使って画像描画したり、バウンディングボックス情報を取り除いてくクリーンなHTMLだけを抽出するためのヘルパー関数が用意されている。
# Notoフォントのインストール
!apt-get install fonts-noto-cjk
import requests
from PIL import Image, ImageDraw, ImageFont
from io import BytesIO
from bs4 import BeautifulSoup, Tag
import re
import IPython.display
# HTMLコンテンツに基づいて画像上にバウンディングボックスとテキストを描画する関数
def draw_bbox_html(image_path, full_predict):
"""
Qwenvl HTMLのdata-bbox枠を可視化し、テキストを表示します。座標は0-1000の相対値で指定します。
フィルタリング規則:<ol>要素はスキップし、<li>項目およびその他の要素のみを描画します。
"""
# 画像の読み込み
if image_path.startswith("http"):
response = requests.get(image_path)
image = Image.open(BytesIO(response.content)).convert("RGB")
else:
image = Image.open(image_path).convert("RGB")
width = image.width
height = image.height
soup = BeautifulSoup(full_predict, 'html.parser')
elements_with_bbox = soup.find_all(attrs={'data-bbox': True})
# 元のフィルタリングロジックを保持
filtered_elements = []
for el in elements_with_bbox:
if el.name == 'ol':
continue # <ol>要素はスキップ
elif el.name == 'li' and el.parent.name == 'ol':
filtered_elements.append(el) # <ol>内の<li>項目のみを保持
else:
filtered_elements.append(el)
# フォントの互換性処理
try:
font = ImageFont.truetype("NotoSansCJK-Regular.ttc", 10)
except Exception:
font = ImageFont.load_default()
draw = ImageDraw.Draw(image)
# バウンディングボックスとテキストの描画
for element in filtered_elements:
bbox_str = element['data-bbox']
text = element.get_text(strip=True)
try:
x1, y1, x2, y2 = map(int, bbox_str.split())
except Exception:
continue
bx1 = int(x1 / 1000 * width)
by1 = int(y1 / 1000 * height)
bx2 = int(x2 / 1000 * width)
by2 = int(y2 / 1000 * height)
if bx1 > bx2:
bx1, bx2 = bx2, bx1
if by1 > by2:
by1, by2 = by2, by1
draw.rectangle([bx1, by1, bx2, by2], outline='red', width=2)
draw.text((bx1, by2), text, fill='black', font=font)
# Colaboratoryだと image.show() は動かないっぽいので、
# IPythonでPIL Imageオブジェクトを直接表示
#image.show()
IPython.display.display(image)
# Markdownコンテンツに基づいて画像にバウンディングボックスを描画する関数
def draw_bbox_markdown(image_path, md_content):
"""
Markdown内の <!-- Image/Table (x1, y1, x2, y2) --> 形式の座標ボックスのみを可視化します(座標は0-1000の相対値)。
テーブルは緑色のボックスで、画像は青色のボックスで表示されます。
"""
if image_path.startswith("http"):
response = requests.get(image_path)
image = Image.open(BytesIO(response.content)).convert("RGB")
else:
image = Image.open(image_path).convert("RGB")
width = image.width
height = image.height
pattern = r"<!-- (Image|Table) \(\s*(\d+)\s*,\s*(\d+)\s*,\s*(\d+)\s*,\s*(\d+)\s*\) -->"
matches = re.findall(pattern, md_content)
draw = ImageDraw.Draw(image)
for item in matches:
typ, x1, y1, x2, y2 = item
x1, y1, x2, y2 = map(int, [x1, y1, x2, y2])
bx1 = int(x1 / 1000 * width)
by1 = int(y1 / 1000 * height)
bx2 = int(x2 / 1000 * width)
by2 = int(y2 / 1000 * height)
if bx1 > bx2:
bx1, bx2 = bx2, bx1
if by1 > by2:
by1, by2 = by2, by1
color = 'blue' if typ == "Image" else 'red'
draw.rectangle([bx1, by1, bx2, by2], outline=color, width=6)
# Colaboratoryだと image.show() は動かないっぽいので、
# IPythonでPIL Imageオブジェクトを直接表示
#image.show()
IPython.display.display(image)
# HTMLコンテンツをクリーニングして整形する関数
def clean_and_format_html(full_predict):
soup = BeautifulSoup(full_predict, 'html.parser')
# style属性内の'color'スタイルにマッチする正規表現パターン
color_pattern = re.compile(r'\bcolor:[^;]+;?')
# style属性を持つすべてのタグを検索し、'color'スタイルを削除
for tag in soup.find_all(style=True):
original_style = tag.get('style', '')
new_style = color_pattern.sub('', original_style)
if not new_style.strip():
del tag['style']
else:
new_style = new_style.rstrip(';')
tag['style'] = new_style
# すべてのタグから'data-bbox'と'data-polygon'属性を削除
for attr in ["data-bbox", "data-polygon"]:
for tag in soup.find_all(attrs={attr: True}):
del tag[attr]
classes_to_update = ['formula.machine_printed', 'formula.handwritten']
# divタグ内の特定クラス名を更新
for tag in soup.find_all(class_=True):
if isinstance(tag, Tag) and 'class' in tag.attrs:
new_classes = [cls if cls not in classes_to_update else 'formula' for cls in tag.get('class', [])]
tag['class'] = list(dict.fromkeys(new_classes)) # 重複を削除してクラス名を更新
# 特定クラス名のdivタグの内容をクリアし、クラス名を変更
for div in soup.find_all('div', class_='image caption'):
div.clear()
div['class'] = ['image']
classes_to_clean = ['music sheet', 'chemical formula', 'chart']
# 特定クラス名のタグの内容をクリアし、'format'属性を削除
for class_name in classes_to_clean:
for tag in soup.find_all(class_=class_name):
if isinstance(tag, Tag):
tag.clear()
if 'format' in tag.attrs:
del tag['format']
# 手動で出力文字列を構築
output = []
for child in soup.body.children:
if isinstance(child, Tag):
output.append(str(child))
output.append('\n') # トップレベル要素ごとに改行を追加
elif isinstance(child, str) and not child.strip():
continue # 空白テキストノードは無視
complete_html = f"""```html\n<html><body>\n{" ".join(output)}</body></html>\n```"""
return complete_html
モデルの出力を元に画像にバウンディングボックスを描画。
draw_bbox_html(img_name, response)
クリーンなHTMLとして取り出し。
print(clean_and_format_html(response)[:1000]) # 先頭1000文字部分だけ
```html
<html><body>
<div class="image"><img/></div>
<div class="image">汽车和汽车零部件<br/>2017 年 08 月 05 日</div>
<div class="image">宇通客车 (600066)</div>
<div class="image">7月销量转正,T7前景看好</div>
<div class="image">推荐(维持)</div>
<div class="image">现价:22.06 元</div>
<div class="image">主要数据</div>
<div class="image">行业 汽车和汽车零部件
公司网址 www.yutong.com
大股东/持股 宇通集团/37.19%
总股本(百万股) 2,214
流通 A 股(百万股) 1,903
流通 B/H 股(百万股) 0
总市值(亿元) 488.39
流通 A 股市值(亿元) 419.91
每股净资产(元) 6.28
资产负债率(%) 52.30</div>
<div class="image">行情走势图</div>
<div class="image">20%
—— 宇通客车 —— 沪深300
10%
0%
-10%
-20%
Aug-16 Nov-16 Feb-17 May-17</div>
<div class="image">相关研究报告</div>
<div class="image">《宇通客车*600066* 6月销量创年内新高, 校车近期有望放量》 2017-07-04
《宇通客车*600066* 没有一个冬天不可逾越, 终将回暖》 2017-06-07</div>
<div class="image">证券分析师</div>
<div class="image">王德安 投资咨询资格编号
S1060511010006
021-38638428
WANGDEAN002@PINGAN.COM.CN</div>
<div class="image">余兵 投资咨询资格编号
S1060511010004
021-38636729
YUBING006@PINGAN.COM.CN</div>
<div class=
次はMarkdownで出力。こちらもQwenVL独自の座標を含むMarkdownフォーマットとして出力され、
- すべての表はLaTeX形式で出力、個々の表の前に座標情報が付与される
- 画像は座標ベースのプレースホルダーに置き換えられる
となる。
こちらは以下のような画像が使用されている。
IPython.display.Image("https://ofasys-multimodal-wlcb-3-toshanghai.oss-cn-shanghai.aliyuncs.com/Qwen3VL/demo/omni_parsing/120922.jpg", width=1024)
期末試験の問題かな?段組みになっていて、表や図が複数含まれている。

では推論。こちらもやや特殊なプロンプトが使用されている点に注意。
import requests
from io import BytesIO
import os
import base64
from PIL import Image
img_url = "https://ofasys-multimodal-wlcb-3-toshanghai.oss-cn-shanghai.aliyuncs.com/Qwen3VL/demo/omni_parsing/120922.jpg"
response = requests.get(img_url)
img_name = os.path.basename(img_url)
image = Image.open(BytesIO(response.content))
image.save(img_name)
def encode_image(image_path):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode("utf-8")
base64_image = encode_image(img_name)
min_pixels = 512*32*32
max_pixels = 4608*32*32
messages=[
{
"role": "user",
"content": [
{
"type": "image",
"min_pixels": min_pixels,
"max_pixels": max_pixels,
"image": f"data:image/jpeg;base64,{base64_image}",
},
{"type": "text", "text": "qwenvl markdown"},
],
}
]
response = inference(messages)
print(response)
結果。Markdonwとしては出力されているのだけど、表の座標とかそういうものは出力されていない。
```markdown
荣德基
点拨
训练
# 第二学期期末测试卷
九年级化学·下(KX版) 时间:90分钟 满分:100分
可能用到的相对原子质量:H:1 C:12 O:16 Na:23 Cl:35.5 Ca:40
## 一、选择题(本题包括15小题,每小题3分,共45分。每小题的4个选项中只有1个符合题意)
1. 把少量下列物质分别放入足量水中,充分搅拌,可以得到无色溶液的是 ( )
A. 氯化铁 B. 氢氧化镁 C. 小苏打 D. 汽油
2. 下列有关物质的俗称、化学式、类别及常见用途的说法中,完全正确的一组是 ( )
| 选项 | 俗称 | 化学式 | 类别 | 常见用途 |
|---|---|---|---|---|
| A | 消石灰 | Ca(OH)$_2$ | 碱 | 用作建筑材料 |
| B | 石灰石 | CaO | 氧化物 | 用作食品干燥剂 |
| C | 小苏打 | NaHCO$_3$ | 酸 | 用于焙制糕点 |
| D | 纯碱 | Na$_2$CO$_3$ | 碱 | 用于玻璃、洗涤剂的生产 |
3. 化学实验室常需要配制溶液,下列说法正确的是 ( )
A. 配制溶液时,只能用水作溶剂
B. 配制硝酸铵溶液的过程中,溶液的温度会下降
C. 用浓硫酸配制稀硫酸时,应将水缓缓注入浓硫酸中
D. 将10g氯化钠溶于100g水中,得到质量分数为10%的氯化钠溶液
4. 浓盐酸和浓硫酸对比,下列叙述正确的是 ( )
A. 两者均具有挥发性
B. 两者均具有刺激性气味
C. 两者均具有腐蚀性
D. 两者均是黏稠状液体
5. 关注健康,预防疾病。下列叙述错误的是 ( )
A. 人体胃液正常的pH范围在0.9~1.5
B. 人体缺乏维生素A会引起坏血病
C. 香烟的烟气中含多种对人体有害的物质
D. 人体缺碘会引起甲状腺肿大,碘过量也会引起甲状腺肿大
6. 下列实验现象描述正确的是 ( )
A. 氢氧化钠固体放置于空气中:表面潮湿并逐渐溶解
B. 高锰酸钾放入汽油中:很快溶解形成紫色溶液
C. 将二氧化碳通入紫色石蕊溶液中:紫色石蕊溶液变蓝色
D. 涤纶和羊毛燃烧:都可闻到一股烧毛发的焦糊味
7. 下列各组物质中,能用紫色石蕊溶液鉴别的是 ( )
A. 稀硫酸和醋酸溶液
B. 稀盐酸和氯化钠溶液
C. 碳酸钠溶液和氢氧化钠溶液
D. 稀氨水和澄清石灰水
8. 除去下列物质中的少量杂质,方法错误的是 ( )
| 选项 | 物质 | 所含杂质 | 除杂质的方法 |
|---|---|---|---|
| A | CO | CO$_2$ | 通过足量的氢氧化钠溶液、干燥 |
| B | Cu | Fe | 加入足量的稀硫酸、过滤、洗涤、干燥 |
| C | CaO | CaCO$_3$ | 加入适量的稀盐酸、过滤、洗涤、干燥 |
| D | KCl溶液 | CuCl$_2$ | 加入适量的氢氧化钾溶液、过滤 |
9. 归纳推理是一种重要的化学思维方法。下列归纳推理正确的是 ( )
A. 碱溶液能使酚酞溶液变红,那么能使酚酞溶液变红的溶液一定是碱溶液
B. 镁、锌、铁能与盐酸反应生成氢气,那么它们与稀硫酸反应也能生成氢气
C. 中和反应生成盐和水,那么生成盐和水的反应一定是中和反应
D. 碳酸盐与盐酸反应放出气体,所以与盐酸反应放出气体的物质一定是碳酸盐
10. 甲、乙、丙、丁四种金属,只有丙在自然界中主要以单质形式存在,用甲制的容器不能盛放丁盐的水溶液,用乙制的容器却可以盛放丁盐的水溶液。由此推断四种金属的活动性由强到弱的顺序是 ( )
A. 丙>乙>甲>丁
B. 甲>丁>乙>丙
C. 丁>甲>乙>丙
D. 甲>乙>丁>丙
11. ZnSO$_4$饱和溶液的溶质质量分数随温度变化的曲线如图所示。下列说法正确的是 ( )
A. N点对应的ZnSO$_4$溶液升温或降温均可能析出晶体
B. M点对应的ZnSO$_4$溶液是不饱和溶液
C. ZnSO$_4$饱和溶液的溶质质量分数随温度升高而增大
D. 40℃时,ZnSO$_4$的溶解度为41g
12. 小明向盛有盐酸和MgCl$_2$溶液的烧杯中加入一定量的NaOH溶液,为判断反应后溶液的成分,他分别取少量反应后的溶液a于试管中,用下表中的试剂进行实验,相应结论错误的是 ( )
| 选项 | 试剂 | 现象和结论 |
|---|---|---|
| A | Zn粉 | 有气泡产生,则溶液a一定含MgCl$_2$ |
| B | CuO粉末 | 无明显现象,则溶液a中一定有两种溶质 |
| C | NaOH溶液 | 无明显现象,则溶液a中可能有NaOH |
| D | CuSO$_4$溶液 | 有蓝色沉淀,则溶液a中一定有两种溶质 |
13. 硝酸钾的溶解度随温度升高而增大。如图是有关硝酸钾溶液的实验操作及变化情况,下列说法正确的是 ( )
A. 操作I一定是降温
B. 操作I一定是加溶质
C. ①与③的溶质质量可能相等
D. ②与③的溶质质量分数相等
14. 图中“—”表示相连的两种物质能发生反应,“→”表示一种物质能转化成另一种物质,部分反应物、生成物及反应条件未标出,则不可能出现的情况是 ( )
A. 甲是H$_2$,乙是O$_2$
B. 甲是HNO$_3$,丙是NaNO$_3$
C. 乙是CO,丙是CO$_2$
D. 乙是Cu(OH)$_2$,丙是CuSO$_4$
15. 向一定质量的甲中连续加入乙至过量,此过程中溶液的总质量与加入乙的质量之间的关系,符合如图所示曲线的是 ( )
| 选项 | 甲 | 乙 |
|---|---|---|
| A | 稀硫酸 | 氢氧化钠溶液 |
| B | 稀盐酸 | 碳酸钙粉末 |
| C | 稀盐酸 | 锌粒 |
| D | 硝酸银溶液 | 铜粉 |
## 二、填空题(本题包括5小题,共30分)
16. (4分)写出符合下列要求的化学符号:
(1) 实验室中最常用的溶剂 ___________。
(2) 导电性最好的金属 ___________。
(3) 天然气主要成分 ___________。
(4) 熟石灰中的阴离子 ___________。
17. (7分)2019年12月以来,我国部分地区突发新冠肺炎疫情。严重威胁着人们的生命安全。科学防疫,从我做起。
(1) 饮食:合理膳食,保证营养均衡,可以提高人体对新冠肺炎的抵抗力。下表是小明家里某天午餐的食谱。
| 主食 | 米饭 |
|---|---|
| 副食 | 红烧牛肉、炒鸡蛋、咸味花生 |
| 饮品 | 酸奶 |
① 红烧牛肉中富含的营养物质是 ___________。
② 从营养均衡的角度分析,该食谱中还缺少的有机营养物质是 ___________。
(2) 消毒:84消毒液是一种以次氯酸钠(NaClO)为主要有效成分的高效消毒剂。
① 次氯酸钠属于 ___________(填“氧化物”或“盐”)。
② 次氯酸钠中氯元素的化合价为 ___________。
③ 次氯酸钠的相对分子质量为 ___________。
④ 欲用溶质质量分数为5%的次氯酸钠溶液配制1000g溶质质量分数为0.5%的次氯酸钠溶液。需加水 ___________g。
(3) 救治:为救治病人需要提供氧气。氧烛能持续放出高效氧气,其主要化学成分发生如下反应:2NaClO$_3$=2X+3O$_2$↑,则X的化学式为 ___________。
18. (7分)根据如图实验回答问题:
<!-- Image -->
(第18题)
(1) 图1:两金属片相互刻划,根据划痕,说明黄铜比铜的硬度要 ___________。
-85-
```
ここはちょっとわからないけど、ノートブックでは DashScope の "pre-qwen3vl-235A22-instruct-0918-model"というモデルを使っていて、8Bではダメなのかもしれないし、あと pre- とか指定されてたりしているので公開されているモデルとは違ったりするのかもしれない。残念。
続き