re:Invent 2024: GE AerospaceのRedshiftマルチクラスター活用事例
はじめに
海外の様々な講演を日本語記事に書き起こすことで、隠れた良質な情報をもっと身近なものに。そんなコンセプトで進める本企画で今回取り上げるプレゼンテーションはこちら!
📖 AWS re:Invent 2024 - Scaling to new heights with Amazon Redshift multi-cluster architecture (ANT339)
この動画では、Amazon Redshiftのマルチクラスターアーキテクチャについて、GE Aerospaceの事例を交えながら詳しく解説しています。シングルクラスターでは複数ワークロードが同一コンピュートを共有することで生じる課題を示し、Hub and spokeアーキテクチャによってワークロードを分離する解決策を提示します。GE Aerospaceは3年前にオンプレミスからAWSに移行し、1日あたり175,000以上のクエリ、20,000以上のユーザーの需要に対応しています。また、AWS Lake Formationを活用した一元的なガバナンス管理や、Zero-ETL統合によるデータ共有の実装方法についても、Any Companyという架空の小売企業を例にした具体的なデモを通じて説明しています。
※ 動画から自動生成した記事になります。誤字脱字や誤った内容が記載される可能性がありますので、正確な情報は動画本編をご覧ください。
※ 画像をクリックすると、動画中の該当シーンに遷移します。
re:Invent 2024関連の書き起こし記事については、こちらのSpreadsheet に情報をまとめています。合わせてご確認ください!
本編
Multi-clusterアーキテクチャの概要とセッションアジェンダ


みなさん、ありがとうございます。本日のアジェンダについてご説明させていただきます。Multi-clusterアーキテクチャと、それが解決しようとするスケールに関する課題についてお話しします。 まず、いくつかのリファレンスアーキテクチャについて説明します。皆様がこれらのリファレンスアーキテクチャを持ち帰り、独自の方法で応用して、その経験を私たちと共有していただけることを期待しています。Multi-clusterアーキテクチャを可能にする仕組みの裏側もご紹介します。その後、GE AerospaceのAlcuin Weidusが、彼らの取り組みについてお話しします。GE Aerospaceは約3年前にオンプレミスからAWSに移行し、私たちに素晴らしいフィードバックを提供しながら、新たな高みへとスケールしてきた素晴らしいパートナーです。

Anusha Challaが、このセッションのために用意した素晴らしいデモで全体をまとめ、シングルクラスターからMulti-clusterへの移行方法とベストプラクティスをご紹介します。最後の10分間はQ&Aの時間を設けており、セッション後も質問がある方には対応させていただきます。質問と言えば、会場の中でAmazon Redshiftをすでに使用されている方はどのくらいいらっしゃいますか?ほとんどの方ですね。 シングルクラスターアーキテクチャを使用している方は?こちら側に何人かシングルクラスターユーザーがいらっしゃいますね。部屋のこちら側にはMulti-clusterのエキスパートがいらっしゃるようで、Q&Aセッションが楽しみになりそうです。ぜひ皆様の知見をシェアしていただければと思います。
シングルクラスターからMulti-clusterへ:アーキテクチャの進化

では、本題に入りましょう。これはシングルクラスターアーキテクチャの一般的なパターンです。データウェアハウスの導入初期では、異なるワークロードが単一のコンピュートを共有することがよくあります。この例では、ストリーミングインジェストとバッチインジェストという2つの書き込みワークロードがコンピュート上で実行され、さらにコンシューマーレポーティング、BI、サイエンスワークロードが動作しています。ある程度までは垂直方向と水平方向にスケールできますが、複数のワークロードが実行されている場合、バックグラウンドでは同じCPUとネットワークI/Oを使用しているため、ワークロード間で干渉が発生する可能性があります。タイムスタンプの述語を追加し忘れたり、結合条件を指定せずにカーテシアン結合を実行したりするユーザーがいて、その影響が広範囲に及ぶことを経験された方もいらっしゃるかもしれません。これは多くのリソースを消費し、他の重要なレポートに影響を与え始める可能性があります。下流のレポートがインジェストジョブに依存している場合、インジェストジョブに影響が出るのは避けたいものです。
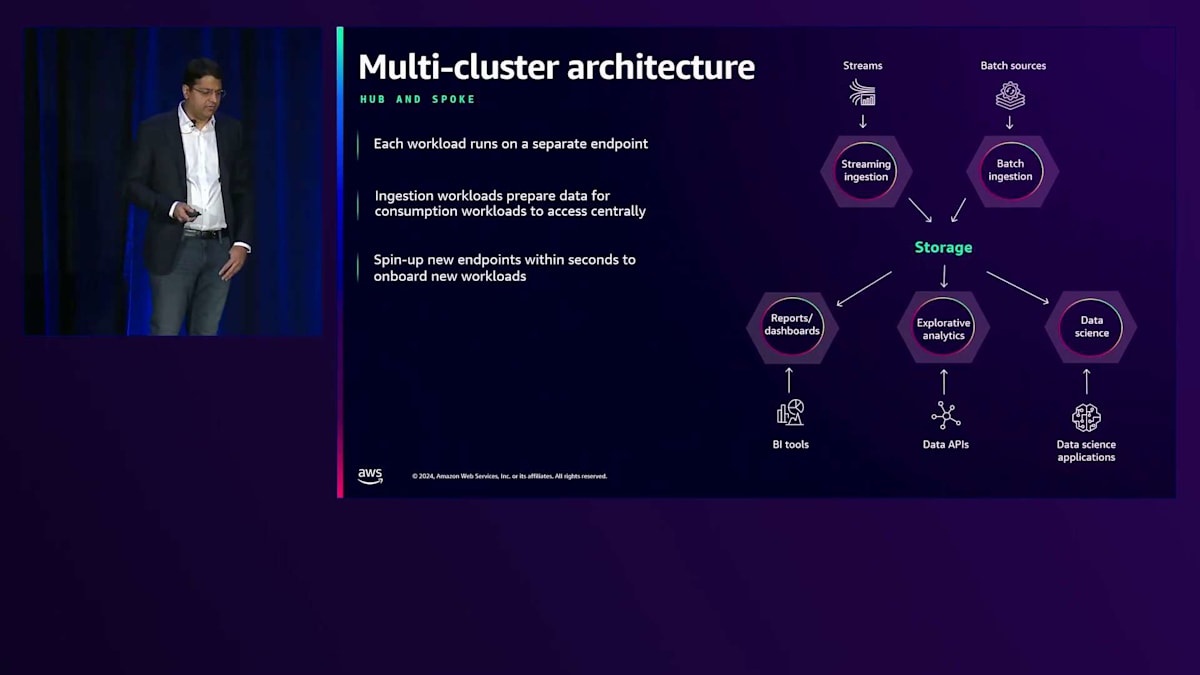
では、Multi-clusterによる解決策はどのようなものでしょうか?単一の大きなコンピュートを表す大きな六角形を、複数の異なるエンドポイントに分割します。ここでは、ストリーミングインジェストとバッチインジェストという2つの書き込みワークロードが分割され、同じテーブルまたは異なるテーブルにデータを書き込んでいます。下部には3つの異なるコンシューマー、サイエンスワークロードがあり、それぞれが独自のエンドポイントを持っています。これにより、各ワークロードの固有のSLAとニーズに基づいてエンドポイントのサイズを設定できるというメリットがあります。このようなアーキテクチャを構築する際は、現在のニーズだけでなく、将来のニーズにも対応できる拡張性を確保することが重要です。このアーキテクチャでは、さらにコンピュートを追加したい場合、同じ共有データを利用する追加のエンドポイントを数秒で起動できます。これをHub and spokeアーキテクチャと呼んでいます。Hubは書き込みを管理する中央チーム、Spokeは様々なコンシューマーを指します。ここでは、ストリーミングライターとバッチインジェストという2つのHubがあります。先週まで、特定のNamespaceに書き込めるコンピュートは1つだけでしたが、先週発表したのは、異なるコンピュートから同じデータセットに書き込める機能です。別のアーキテクチャパターンも見てみましょう。

これは、財務、営業、マーケティングなど、多くの組織のサイロや部門を持つ典型的な大企業で見られるパターンかもしれません。この場合、すべての部門が同じ大規模なコンピュートインフラストラクチャを使用しています。このような状況では、いくつかの妥協が発生します。多くの場合、すべての使用のピークに対応するようにコンピュートが過剰にプロビジョニングされ、結果としてコストが高くなります。また、企業におけるChargebackの観点からも、財務、営業、その他の部門のコンピュート使用量に基づいて料金を請求する要件がお客様からよく寄せられます。

この例では、FinanceとR&Dが、Sarbanes-Oxley法やその他の規制に関して同じComputeを使用しているのが分かります。Financeには7年間のデータ保持要件があるかもしれませんが、R&Dにはそれほど長期の保持は必要ありません。しかし結局は、すべてのユーザーのニーズを満たすために妥協して、おそらくすべてのユーザーに対してより長い保持期間を設定することになってしまいます。 これらの課題を克服するために、大きな六角形が小さな部分に分割されていくパターンが見られ始め、各部門やチームが独自のEndpointを持つようになります。違いは、各部門がデータオーナーとして自身のデータを管理し、他部門と共有したいデータの側面を決定できることです。これは、社会保障番号や機密性の高い給与データなど、SalesやMarketingと共有すべきではない情報を扱うHuman Resourcesのようなケースで重要となります。


彼らは何を共有すべきか、何を共有したいかを管理します。最も良い点は、これらすべてのユニット間でデータの統合ビューを持つことで、依然としてCustomer 360ビューを得られることです。そのため、MarketingがSalesデータに基づいてキャンペーンを実施する場合でも、データを移動することなくそれを実行できます。 では、これらのMulti-cluster Architectureを支えている仕組みを見てみましょう。私たちはデータの移動やコピーが不要だという話をしました。 分析ニーズのためにデータの複数のコピーを作成している状況があれば、それを慎重に検討することを強くお勧めします。なぜなら、コピーは管理が難しく、同期が取れなくなり、ガバナンスが悪夢のようになるからです。
Amazon Redshift Multi-clusterアーキテクチャの仕組みと利点


Multi-cluster Architectureの中核となるのは、分析用のカラムナーストレージに高度に最適化されたRedshift Managed Storageレイヤーです。分析クエリを非常に高速かつコスト効率よく実行することを目的として、さまざまな最適化が施されています。 Computeレイヤーでは、大規模な並列処理が可能で、2つのオプションがあります。必要なノード数とインスタンスタイプを指定するProvisioned Compute、あるいはインフラストラクチャを管理する必要がなく、必要なRedshift Processing Units(RPU)数を指定するだけのServerless Compute です。
利点は、ニーズに応じてServerlessとProvisionedのComputeを組み合わせることができ、Computeサイズを選択できることです。この例では、同じデータに対して、あるComputeは8 RPUだけを使用し、別のComputeは1024 RPUを使用しています。バッチ取り込みの場合は1024までスケールアップしたいかもしれません。Amazonのインテリジェントスケーリングにより、スケーリングをAutoに設定して、ワークロードに適したサイズをRedshiftが判断するようにできます。さらに、これらのComputeレイヤーは同じAWSアカウント内である必要はなく、アカウントをまたがることができます。これは独自のアカウント分離を持つパートナーチームにとって有益です。異なるRegionからデータを利用することもでき、これはデータをRegionや国内に留めておく必要があるGDPRコンプライアンスに役立ちます。
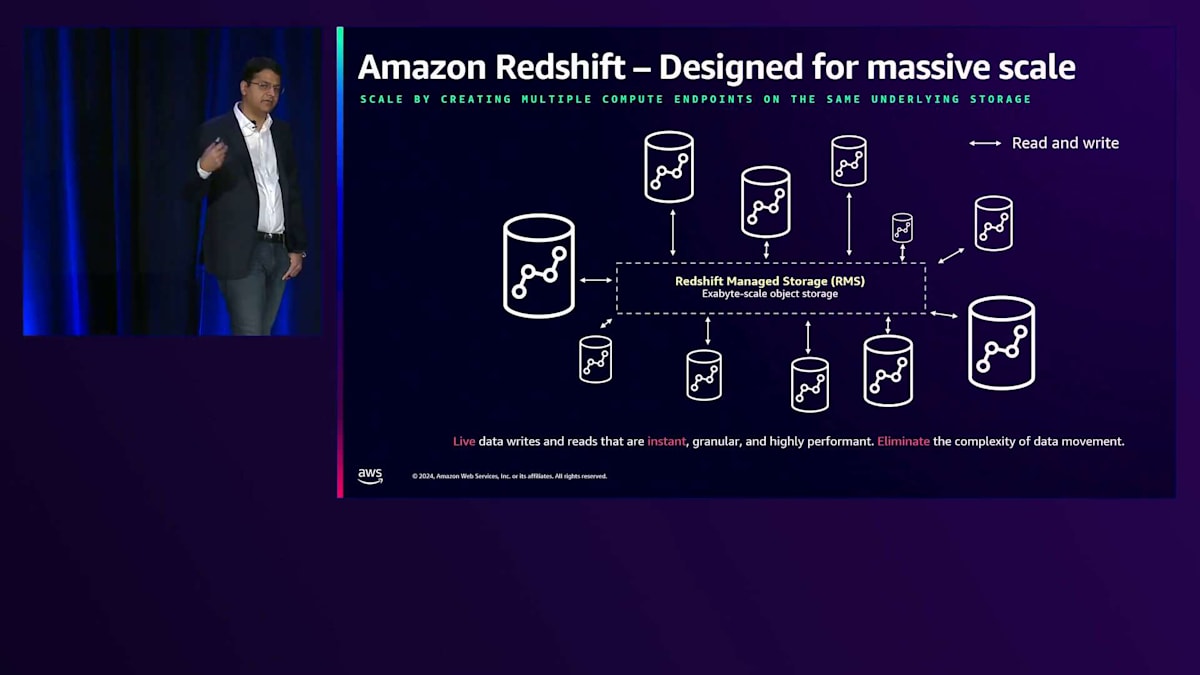
このCross-Region機能により、あるRegionのServerless Computeが別のRegionに保存されているデータを読み取ることができます。例えば、Virginiaに保存されているデータをEUのComputeで読み取ることができます。 これらのComputeレイヤーの1つが書き込み操作を実行すると、異なるアカウントやRegionにある他のComputeインスタンスでも、同じトランザクション整合性のあるデータを即座に読み取ることができます。Redshiftはスナップショット分離を提供し、データの鮮度を損なうことがないため、これはニアリアルタイムの意思決定を行うアプリケーションにとって重要です。

マルチテナンシーに関して、多くのお客様がマルチテナントアーキテクチャを実装しています。大規模なクライアントに対しては、専用のエンドポイントを用意し、その利用料を個別に請求することができます。つまり、すべてのテナントに同一のサービスを提供する必要はなく、このマルチクラスターアーキテクチャを使用することで、データ移動を気にすることなく、異なるサービスを提供できるのです。 異なるコンピュートレイヤーを通じて単一のデータコピーにクエリを実行する場合、ガバナンス、アクセス制御、権限について疑問に思われるかもしれません。

各コンピュートレイヤーで権限を設定することは可能ですが、多くのお客様は、Amazon RedshiftとAWS Glue Data Catalogを使用した一元化されたガバナンスレイヤーで簡単にスケールすることを好みます。データのオーナーは、AWS Glue Data Catalogとデータを共有または公開するかどうかを決定します。 ParquetやIcebergなどの外部テーブルの検出にAWS Glue Data Catalogを使用することはよく知られていますが、現在ではAmazon Redshiftのテーブルの検出にも使用できるようになりました。

AWS Lake Formationのアクセスポリシーを使用することで、テーブル、列、行レベルでアクセス制御を設定できます。例えば、社会保障番号を含むHRの例では、HRユーザーのみが完全な社会保障番号を見ることができるようにマスキングポリシーを設定することができます。また、ユーザーの組織内での役割に基づいて、どの行のサブセットを表示できるかどうかを制御するロールレベルのポリシーも実装できます。 これらのポリシーは一度設定され、ロールに関連付けられます。例えば、Jillがアナリストである場合、彼女はIAMユーザーとして、またはIdentity Centerを使用してOkta、Ping Federate、Active Directoryなどの企業ディレクトリにフェデレーションすることができます。
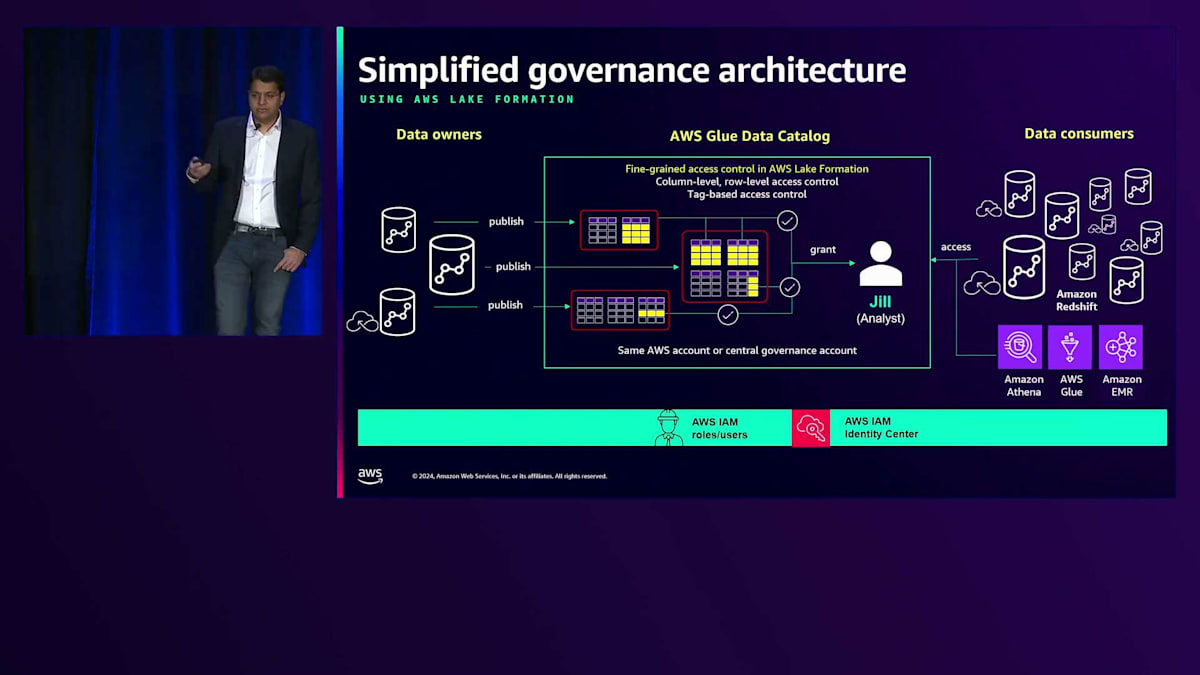
Jillの組織内での役割が変更された場合でも、すべての権限を再設定する必要はありません。 JillがAmazon Redshift、Athena、EMR、GlueなどのLake House機能の一部である任意のコンシューマーにログインする際、同じIDで認証を行います。カタログが彼女の権限とアクセス制御を決定します。コンシューマーを追加しても、中央のガバナンスは一貫性を保ちます。
この時点で、コンシューマーを追加しても、中央のガバナンスは intact のままで、監査性とポリシーがすべて一箇所に集中していることを保証します。中央集中型のアクセス制御とデータ移動が不要なことを組み合わせることで、マルチクラスターアーキテクチャの設定が非常に容易になります。では、Alcuin Weidusが GE Aerospaceの事例について説明する実例を見てみましょう。
GE Aerospaceの事例:ビジネスとデータの進化

Nareshさん、ありがとうございます。このステージで私たちのストーリーを共有する機会をいただき、感謝いたします。私はGE AerospaceのSenior Principal Data ArchitectのAlcuin Weidusです。本日は皆様と一緒にお話を進めていきたいと思います。 まず私たちのビジネスについて少しお話しした後、私たちのRedshiftに関する取り組みについてご紹介し、Redshiftでどのようにスケールしてきたか、そしてNareshが先ほど説明した複数のマルチクラスター戦略をどのように活用してきたかをハイライトしていきます。

まず始めに、GE Aerospaceという企業について、私たちの目的から説明させていただきたいと思います。 「私たちは、飛行の未来を創造し、人々を高みへと導き、そして安全に家まで送り届けます」。これはシンプルな言葉ですが、非常に深い意味を持っています。この言葉は、私を含むGE Aerospaceの全従業員が日々の業務で担う重大な責任を体現しています。

私たちは、ジェットエンジンをはじめ、航空機の接続システムやその他のコンポーネントを提供する世界トップクラスの企業です。GE Aerospaceと聞くと、エンジンだけでなく、航空機の様々な部分に私たちの技術が使われています。企業としては、長年にわたるイノベーションの歴史があります。製品開発だけでなく、業界全体を前進させるような革新を数十年にわたって続けてきました。そしてそれは、net-zero flightのような未来志向の目標にも反映されています。

これはRedshiftのセッションですので、私たちのビジネスをデータのスライドで表現させていただくのが最適だと思います。会場の皆さんのほとんどがデータに携わる方々ですね。ここでNareshさんのように質問させていただきますが、re:Inventに参加するために飛行機を使って来られた方は手を挙げていただけますでしょうか。会場を見渡すと、ほとんどの方が手を挙げていらっしゃいますね。これは、飛行機が私たちをこの会場で結びつけているだけでなく、皆さんとGE Aerospace、そして私たちの使命とも結びつけているということです。世界のどこかで2秒に1回、私たちの技術を搭載したエンジンや航空機が離陸しています。これは離陸の4分の3に相当し、このプレゼンテーションが始まってからだけでも、どれだけの飛行機が離陸したか想像できるでしょう。常時約90万人の人々が、私たちの技術を信頼して安全な帰路につけることを期待しながら、世界中を飛行しています。

ここで、GE Aerospaceという企業についての説明から、私たちのRedshiftの取り組みについてお話しさせていただきます。私は幸運にも、複数年にわたって、Redshiftプラットフォームへの私たちの取り組みの異なる段階について講演する機会をいただいてきました。オンプレミスからクラウドへの移行を経て、今日お話しさせていただくのは、クラウドでの私たちのフットプリントをどのように進化させ続け、エンドユーザーのニーズにどう応えてきたかについてです。この進化は、ビジネス全体のデータとアナリティクスの消費者である私たちのお客様に適切なサービスを提供することを目的としています。私は「現代のニーズ」というものをまとめてみましたが、これはGE Aerospaceに特有のものではないと思います。会場の皆さんも、データとアナリティクスシステムに対する同様のニーズを経験されていると思いますが、これらのニーズこそが、私たちにRedshiftでの異なるスケーリング方法を考えさせるきっかけとなりました。その最初の一つは、日々増加し続ける需要に関するもので、1日あたり175,000以上のクエリ、20,000以上のユーザーがアナリティクスを要求しているという状況です。
GE Aerospaceのデータ戦略:課題とMulti-clusterへの移行
日々増加するユーザーが、メイン環境での分析やクエリアクセスを求めており、新しいワークロード、新しいユースケース、そして新しい顧客グループが私たちのシステムに期待を寄せるにつれ、その需要は拡大の一途をたどっています。航空宇宙産業では、フライトレポートを大量に扱いますが、これはクラスター上で独特の課題をもたらします。これらのレポートは、従来型や従来からある分析よりもはるかに幅広く深いテーブルを扱う必要があり、それらを同時に処理しなければなりません。
私たちには、両方のワークロードを同時に処理しながら、ますます厳しくなる遅延時間の制約内で顧客に結果を提供できるシステムとアーキテクチャが必要です。2年前なら1日かかっても許容されていたタスクや、数ヶ月前なら1時間かかっても問題なかったタスクが、近い将来には数分以内に完了する必要があるかもしれません。このように短縮される遅延時間の要求に対応し続けていく必要があります。
クラウドに移行し、完全なクラウドネイティブのエンタープライズウェアハウスを構築してみると、スケーリングの様相が異なることに気づきました。ビジネス全体のあらゆるワークロードに対応するために、単一のクラスターを単純にスケールアップすることはできませんでした。その代わりに、発想を変えてスケールアウトを検討する必要がありました。顧客の声に耳を傾け、後ほど詳しく説明するメトリクスを分析した結果、単一クラスターでのキュー時間とクエリ処理時間がビジネスの要求を満たしておらず、レポートが厳しい時間枠に間に合わないほどの待ち時間が発生していることがわかりました。

画面に表示されているのは、その進化の過程ですが、実際には図が示すほど単純ではありませんでした。2014年から2021年まで、私たちは従来型のオンプレミスモノリスを使用しており、すべてが1つの領域で動作していました。そこでは、計算リソースの競合、分離の欠如、そして事前の予測と過剰なプロビジョニングの必要性といった、よくある問題に直面していました。これはコストがかかる方式でした。
クラウドに移行した際、まず最初にWriterとReader、つまりデータ所有者とデータ消費者を分離しました。これにより、環境に入ってくるデータと、そこから価値を引き出そうとする人々との間の競合リスクを排除することができました。この方式は2021年第1四半期から2022年第4四半期まで私たちを支えました。その後、クラウドスケールアウトパターンを導入し、2つの特定のワークロードを共有クラスターから分離して、事業部門ごとのAmazon Redshiftクラスターに移行しました。
クラウドデータのエコシステムの図は、先ほどNareshが示した六角形が分離していく図と非常によく似ています。これはハブアンドスポークとポイントツーポイント、あるいはメッシュデザインを組み合わせたものを表しています。環境内でプロデューサーからデータを読み取るだけでなく、ポイントツーポイントの接続も可能で、共有ストレージを通じてある事業部門が別の事業部門と直接データを共有し、協力することができます。

図で素晴らしいストーリーが語られていますが、いつ、どのようにして変更が必要だと判断したのか気になるかもしれません。私たちのプラットフォームグループが異なるアプローチを取るきっかけとなった、スケールの必要性を示す2つの具体的な例を紹介したいと思います。1つ目は、リフトアンドシフトによるクリティカルな運用ワークロードの例です。これはみなさんにも見覚えがあるかもしれません。上流・下流のデータが環境に入ってくる際の厳密な依存関係があり、データ消費にも厳しいレイテンシーの制約があり、長年かけて90以上のSQL関数が積み重ねられていました。コードは何年もかけて引き継がれてきたため、必ずしも適切にドキュメント化されていませんでした。
彼らはビジネス要件を満たす必要があり、私たちはそのコードをすべて解体して書き直すよう依頼することはできませんでした。そこで、このチームに専用の適切なサイズの計算リソースを提供する、最初の事業部門専用クラスターを導入しました。これにより、クラスター上で他のチームと競合することなく、適切なサイズ設定が可能となり、レイテンシーの要件を満たすことができました。
もう1つの例は、ほぼ正反対のケースです。すべてを見直す意欲のあるチームでした。オンプレミスのデータウェアハウスを運用していたグループが、事業部門全体を近代化し、Amazon Redshiftを中心とした分析の取り組みを開始しようとしていました。彼らはチームの育成に投資し、コードを解体してSQLを書き直していました。その過程で、Redshiftクラスター上で実行されるワークロードの組み合わせ全体を見直しました。私たちは喜んで専用の計算リソースを提供し、「これはあなたたちのものです」と伝えました。新しいやり方に取り組み、チームに投資する意欲があったことで、大きな成果を上げることができました。全体のオブジェクトと総パイプライン時間をそれぞれ50%削減することができました。これは管理すべき対象が減り、より厳しい時間枠を満たすことができ、運用の負担も軽減されたことを意味します。さらに、オンプレミスで運用していた時と比べてコストを40%削減することができました。このチームは初期のパートナーとなり、私たちは彼らが今後どのように投資を続け、進化していくのかを注目し続けています。
Multi-clusterアーキテクチャ導入の学びと今後の展望

ユースケースとお客様の声に耳を傾け、彼らが将来に向けて何を必要としているのかを聞きながら、その需要に応える新しい方法を考えることが重要です。 ここで、私たちの学びについてお話ししたいと思います。この過程では多くの学びがありました。時には痛みを伴うこともありました - レポートが時間枠内に収まらないときは誰も幸せではありません。下の図は現在の組織の姿を表しています。チーム間でデータを共有し、協力し合う人々の姿があり、私たちはこれを誇りに思い、適切にスケールしていくと確信しています。
最初から私たちが学んだのは、クラウドへの移行を単なるLift and Shiftとして考えるべきではないということです。クラウドにLift and Shiftするだけでは、機会を逃し、多くの可能性を手つかずのまま残してしまいます。すべての人がクエリを書き直せるわけではありませんが、顧客と協力して、問題を単に別の場所に移動させるのではなく、設計を調整する方法を見つける必要があります。これを実現するには、ワークロードを深く分析することです。データが入ってくる環境のエントリーポイントを分析し、主要な大規模消費者グループを分析します。そうすることで、効率的なスケーリングと成長を確保するために専用のコンピュートを割り当てることができる機会を示すホットスポットが見えてきます。
これらのワークロードを分割することで、ノード数とノードタイプを変える柔軟性が得られます。共有クラスター環境では重いノードタイプが必要ですが、より軽量なビジネスラインであれば、より小さなノードタイプで運用できます。これらを分割することで、各消費者グループに最適な対応が可能となり、コストの観点から非常に有利になります。私たちはこれを、重要な指標を測定することで実現しました。KPIを採用し、クラスターを監視し、環境で何が起きているかを監視し、エンドカスタマーにとって重要な何かを監視する方法を見つける必要があります。私たちにとって最も役立った指標には、クラスターの待機時間の把握、クラスター間で実行中または待機中のクエリ数の把握、そして待機が発生したクエリの割合を測定するKPIの構築が含まれていました。これらは問題を発見し、アクションを起こすべきタイミングを判断する上で、非常に重要でした。
もう一つの異なる観点として、コストを可視化して評価する方法を見つけることがあります。これは重要な学びでした。他のトピックとは異なるように見えますが、これを行うことで多くの良い行動を促すことができました。クエリ数、実行時間、スキャンされたデータ量、ディスクスピルなどの指標を可視化し透明化しました。これらの指標に基づいてコストを評価し、それらがどのように相関しているかを顧客に説明することで、顧客はより良いSQLを書き、時間とともにより効率的で安価に実行できるコードを書くようになりました。これは大きな学びであり、Amazon Redshiftとのパートナーシップにより、意味のある数値を確実に関連付けることができました。

これらの学びを超えて、いくつかの考察があります。その最初の一つは、私が繰り返し言ってきたことですが、クラウドでのスケールは異なって見えるということです。単一のクラスターを上に向かってスケールするのではなく、常に多くのクラスターを外に向かって展開することを考えるべきです。少なくとも私たちの場合は、多くのクラスターを外に向かって展開することを考えました。これを実現する方法は、ワークロードを実行している信頼できる顧客の声に耳を傾けることです。問題が発生すると、顧客は通常、うまくいかないときに連絡してくるので、耳を傾けていれば問題がわかります。そのため、顧客の声に耳を傾け、新しい戦略やクラスター設計を採用する意思を持つことが重要です。
エコシステムを設計してください。これはもはや単一のデータシステムではありません。相互に連携する部分から成るエコシステムなのです。ビジネス機能にマッピングしてエコシステムを設計すると、ビジネスのモデル化方法やグループがデータを通じてどのように協力するかを正確に表現できるため、非常に強力になります。コストや効率の観点から、私たちは業界用語の「ベースは所有し、スパイクはレンタルする」という考え方を採用しました。ワークロードを分析し、KPIにマッピングし、顧客を理解することで、特定のクラスターで特定の時間に繰り返し実行されるワークロードを把握できます。Provisioned Nodeやリザーブドインスタンス、クラスターに適切なコスト対策を促す設計を通じて、コスト効率の良いソリューションを適用できます。
予測不可能なワークロードが常にシステムに入ってくる可能性があります。そのような場合、私たちのインスタンスでは Concurrency Scaling のような機能を活用し、また GE Aerospace では近い将来実装を予定している Serverless 機能を活用することで対応します。これらの機能によって、スパイク時の需要を高度な技術で賄うことができます。両者を組み合わせることで、非常にコストパフォーマンスの高い効率的なフットプリントを実現でき、他の皆様にもぜひ同様のアプローチを推奨したいと思います。

今後も、このような勢いは続くと予想しています。 最も重要なポイントは、データ共有に関するものです。これは私たちのチーム間のコラボレーションとコミュニケーションの在り方を表しており、非常に強力な意味を持っています。チームが、データプロデューサーとデータコンシューマーとしての役割と、それに伴う固有の責任をより深く理解するようになると期待しています。これは非常に強力な考え方であり、チームが単一の大きなクラスターの表面下に隠れていた状態から、データオーナーとしての意識を持って異なる行動を取るようになっている初期の兆候に、私たちは励まされています。
これらのドメインクラスター(小規模なものであれ、大規模な事業部門のクラスターであれ)は、データの重力を再設定し始めます。このようなビッグデータシステムには、ユーザーやユースケースを引き寄せる重力のような性質があります。クラスターを分割すると、重力と秩序が再設定され始めます。これは私たちにとって次に起こるべきことを表しているため、とても心強く感じています。生成系AIに関しては、GE Aerospace で実行している初期の生成系AIワークロードと、それらが Redshift に保存されているデータに対して持つ強い需要に、非常に励まされています。今週の re:Invent で発表された Redshift と SageMaker Lakehouse の統合を活用できることで、これらのクラスターに存在する価値の高いビジネスデータを使って、生成系AIや Bedrock のワークロードを継続的に提供できる機会が得られます。最近の発表内容は、これらの高度な本番アプリケーションとデータを統合する方法を提供するものであり、私たちは2024年という早い段階でこれを実現できると考えています。

私たちは2024年という早い段階で、最初の生成系AI本番ユーザーが Amazon Redshift 内のデータへのアクセスを要求したり、エージェントとの対話を望んだりする様子を目にしました。これも同様に心強い動きです。最後に、Data and Infrastructure Services 担当VP の Justin Henderson の言葉を引用させていただきたいと思います。
「グローバルなアナリティクスコミュニティからのプラットフォームへの要求は、かつてないほど高まっています。Amazon Redshift のマルチクラスターアーキテクチャを採用することは、今日の顧客ニーズに応えながら、明日に向けて継続的にスケールしていくための重要な鍵となります。」彼の言葉は素晴らしいと思います。このデザインによって、顧客の要求に応えられる状態に到達できたことを非常に心強く感じているため、この言葉で締めくくりたいと思いました。さらに素晴らしいのは、需要が増え続けても、このアプローチで引き続きスケールできると考えていることです。1年後に、すべてを完全に作り直す必要があるという話をする必要がないのです。
Anushaにバトンを渡す前に、会場にいないGE Aerospaceのチームメンバー全員に感謝の意を表したいと思います。また、長年にわたってこれらのスケーリングイニシアチブに取り組んでこられた全てのグループの皆様、そして本日ご参加の皆様に感謝申し上げます。それでは、デモと追加コンテンツのプレゼンテーションをAnushaに引き継ぎたいと思います。
Any Companyの事例:シングルクラスターからMulti-clusterへの移行デモ

Alcuin、ありがとうございます。皆様、こんにちは。Senior Analytics Specialist Solution ArchitectのAnushaです。先ほどAlcuinから、シングルクラスターアーキテクチャの課題や、マルチクラスターおよびスケールアウトアーキテクチャがもたらすメリットについてお話がありました。この後のセグメントでは、そのデモをご覧いただきます。デモでは、架空の小売企業「Any Company」を例に取り上げます。Any Companyには、Sales、Finance、Marketing、Supportという4つのビジネスユニットがあります。これは、複数のビジネスユニットや複数のテナントが同じData Warehouseを共有している多くの組織の代表的な例といえます。
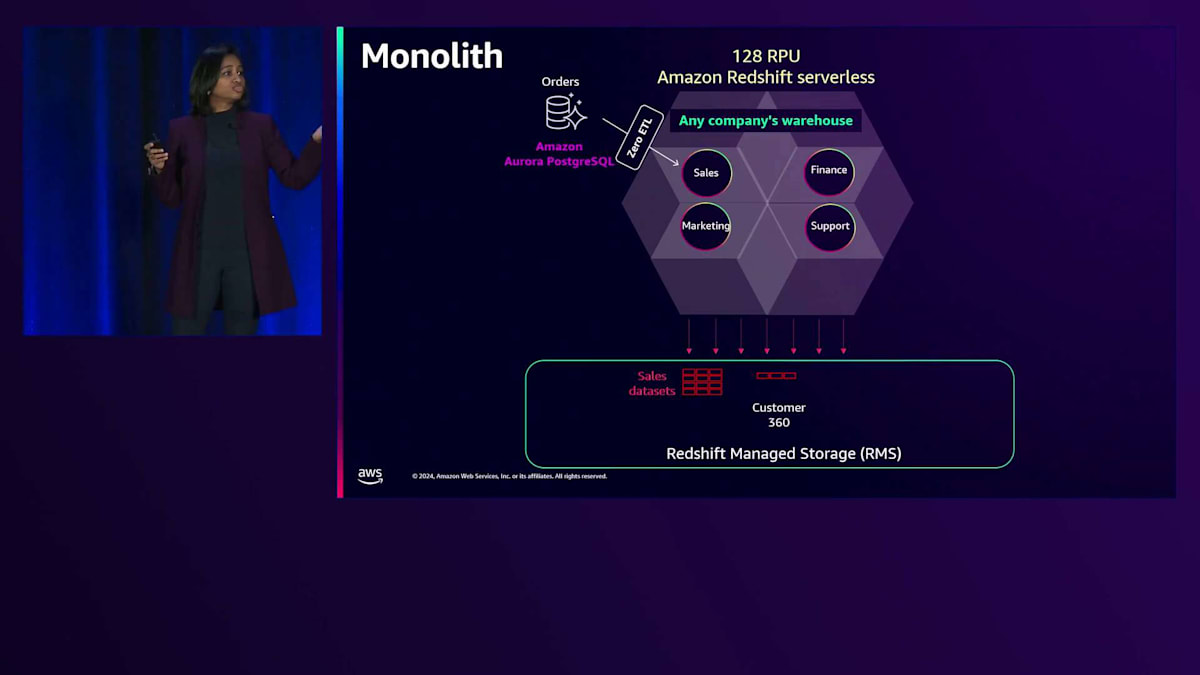

まず、全てのビジネスユニットが同じモノリシックなコンピュートを使用した場合に、Any Companyが直面する課題を見てみましょう。ご覧の通り、このモノリス上では複数の処理が同時に実行されています。Salesは、Zero-ETL統合を使用して、PostgreSQLデータベースから注文データをこのモノリシックエンドポイントにインジェストしています。Zero-ETLについてご存じない方のために説明しますと、これはソースデータベースからAmazon Redshiftへのデータを継続的なレプリケーションでインスタントにコピーする機能です。同様に、Financeも請求書や支払いデータをこのエンドポイントにZero-ETL統合を使用してロードしています。



Marketingは、Kinesis Data Streamsを使用してClickstreamデータをストリーミングインジェストし、Supportはサポートケース、カスタマーレビュー、サポート関連データをS3からAmazon Redshiftへのコピーコマンドを使用してバッチインジェストしています。これらのインジェストは全て同時に行われています。さらに、これらのビジネスユニット全てが、ビジネスユニット間の全ての顧客インタラクションを統合したCustomer 360という共通テーブルをロードしています。データがロードされると、これらのビジネスユニットは様々なBIツール、Data API、データサイエンスアプリケーションを使用して、このデータを分析し、インサイトを導き出します。


では、Amazon Redshiftの観点から、Alcuinが説明したメトリクスやKPIの観点から、これがどのように見えるか確認してみましょう。これがAny Companyのワーハウス、つまりモノリスです。まず、Any Companyワーハウスで行われているインジェストを見てみましょう。そのために、Zero-ETL統合を確認します。Any Companyワーハウスに向かう3つの統合が確認できます。1つ目は、PostgreSQLからの販売データで、継続的にレプリケーションされています。残りの2つは、Amazon DynamoDBからの支払いデータです。


これらのIntegrationの1つを見てみると、ソースからレプリケートされたテーブル数や行数など、さまざまなメトリクスを確認できます。画面が更新されると、カウントが増え続けているのが分かり、データが継続的に取り込まれていることを示しています。同様に、Amazon DynamoDBからのデータも同じエンドポイントに継続的に取り込まれています。では、Any Companyのデータウェアハウスに接続して、他のデータセットも確認してみましょう。まずは、Clickstreamからデータを取得しているマーケティングデータを見てみましょう。


Amazon Redshift内で「Website Clickstream」というテーブルとしてそのストリームを確認できます。このClickstreamには、Materialized Viewがあり、Clickstreamからのデータを継続的にこのMonolithに取り込んでいます。このMaterialized Viewの行数を確認してみましょう。シンプルなカウントクエリを実行すると、約96,500行あることが分かります。カウントを更新すると、このストリームから継続的にデータが取り込まれているため、数が増加しています。


次に、カスタマーレビューとサポートケースを含むサポートデータセットがあります。サポート関連の両方のデータセットとそれぞれの行数を確認できます。この事業部固有の取り込みに加えて、Customer 360へのロードも行われています。すべての組織のロード状況を組織別のカウントで確認できます。データの取り込みに加えて、かなりの量のクエリアクティビティも発生しています。このクエリアクティビティを確認するために、Query Historyテーブルに対してクエリを実行してみましょう。これはシステムテーブルで、クエリ実行時点での過去1時間のすべてのアクティビティを確認できます。


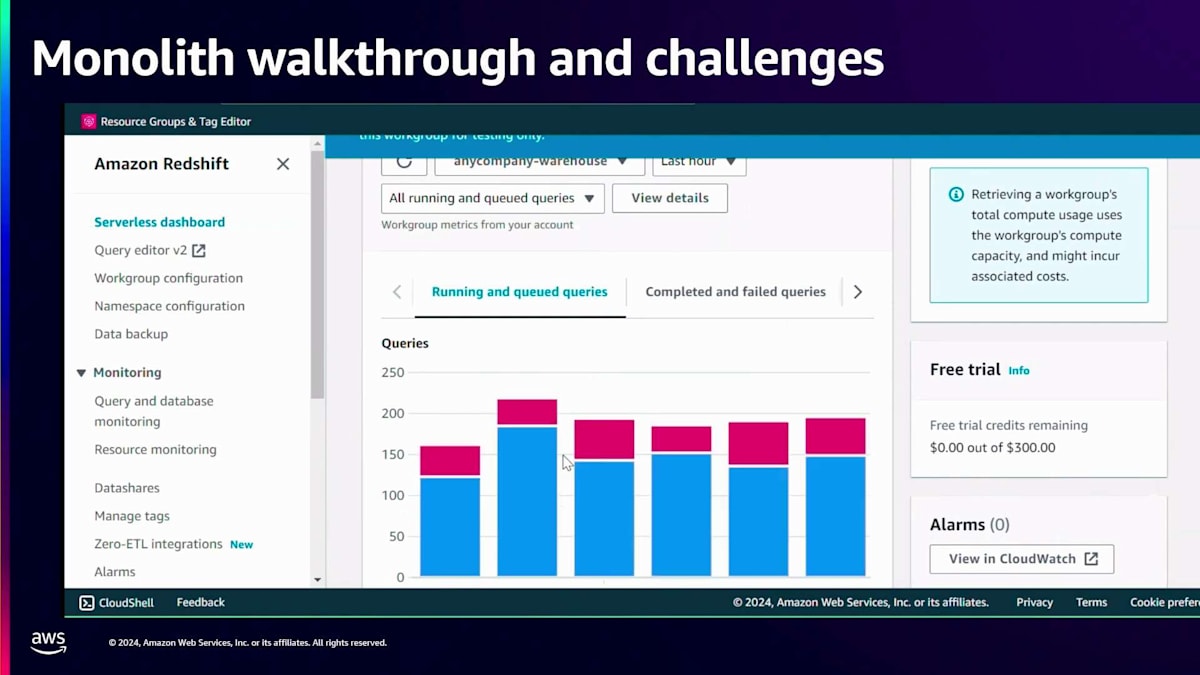
出力を見ると、クエリ実行時に6つのクエリがキューイングされており、過去1時間で数十万のクエリが正常に実行され、クエリ実行時には約28のクエリが実行中だったことが分かります。これは1つのMonolithでかなりの量のアクティビティが発生していることを示しています。これがメトリクスにどのように反映されているか見てみましょう。先ほど言及したKPIの1つをここで確認します。Any Companyの過去1時間の実行中およびキューイング中のクエリを見ると、多くの赤い表示があります。赤はキューイングを示しており、これはリソースの競合が発生していることを示しています。


このClusterのメトリクスの詳細を見ることができます。確認できるメトリクスの1つは、1秒あたりに完了するクエリ数です。このMonolithの現在のクエリスループットは約15クエリ/秒で、1つの不適切なクエリがこれに影響を与える可能性があります。ここに、結合条件のない5つの異なるテーブルを結合する不適切なクエリがあります。これはデカルト積を生成することになります。このクエリを実行すると、クエリスループットへの即時の影響が確認できます。以前は1秒あたり約15クエリだった完了率が、ごく短時間で10クエリ/秒まで低下したことが分かります。


これは、同じエンドポイント上で全てのワークロードが実行されている場合に、不適切なクエリが全体のワークロードに及ぼす可能性のある深刻な影響です。このデモでは、このアーキテクチャにおける課題が明らかになりました - リソースの競合が発生し、単一の不適切なプロセスが全体のワークロードに影響を与え、さらにコスト配分の観点から見ると、各事業部門の使用量に応じて料金を請求することが非常に困難です。では、これらの課題にどのように対処すればよいのでしょうか?私たちはアーキテクチャを通じてこれに対処します。Amazon Redshiftは、コンピュートとストレージの分離機能を備えているため、マルチクラスターアーキテクチャへの再構築が非常に容易です。
再構築後は、各事業部門が独自のエンドポイントを持つようになります。Sales、Marketing、Finance、Supportがそれぞれ専用のエンドポイントを持ちます。これにより、各部門固有の要件に基づいてサイズを設定できる柔軟性が得られます。Supportはバッチ取り込みと重いクエリを実行するため、64 RPUのより大きなコンピュートを割り当てられています。一方、MarketingとFinanceは低レイテンシーの取り込みを行い、重いクエリを実行しないため、16 RPUの小さなコンピュートで十分です。これらのエンドポイントはそれぞれ独自のコンピュートを使用して自身のデータセットを取り込み、コンピュートとストレージが分離されているため、共通のCustomer 360テーブルへの書き込み機能も維持されます。
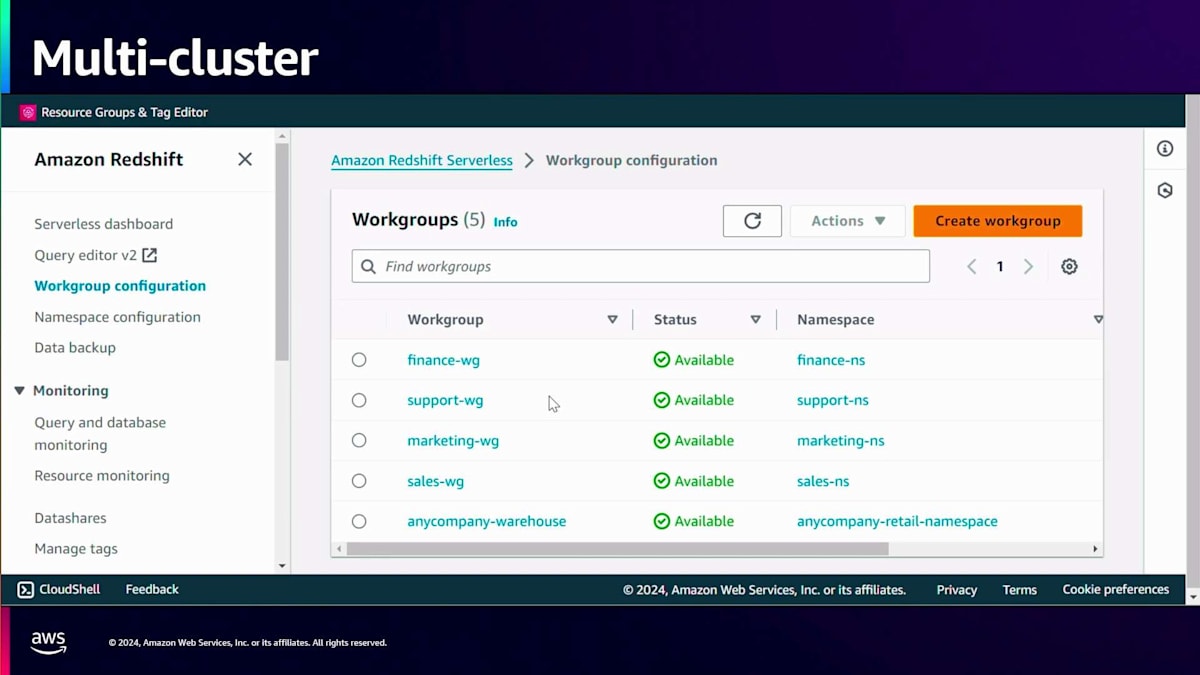

では、Amazon Redshiftでこれがどのように見えるか確認してみましょう。アーキテクチャの変更後、各事業部門向けに4つの新しいエンドポイントが作成されました - これはテナントごとに作成することもできます。これらがSales、Marketing、Support、Financeのエンドポイントで、以前は同じエンドポイントにロードしていたZero-ETL統合が、今では対応する独自のエンドポイントにロードするようになっています。更新された構成をご覧ください - Amazon DynamoDBからのFinanceデータはFinanceネームスペースに、Amazon Aurora PostgreSQLからのSalesデータはSalesネームスペースに送られています。同様に、Marketingデータは Marketingネームスペース、SupportデータセットはSupportネームスペースに送られています。

複数のコンピュートが共通のデータセットに書き込める新機能について説明しましたが、ここでCustomer 360の共通データセットと、複数のエンドポイントがこの共通テーブルに書き込む方法を見てみましょう。このデモでは、画面上の4つのボックスがそれぞれ異なる事業部門を表しています - 左上がSales、そしてFinance、Marketing、Supportです。Customer 360テーブルは最初にSalesによって作成され、現在は空で、Salesのみがアクセス権を持っているとします。

Salesは2つの簡単なステップで、この共通テーブルへのアクセス権を他のすべての部門に付与できます。まず、このCustomer 360テーブルを含むデータシェアをinsert権限付きで作成し、次にSalesが他の事業部門 - Finance、Marketing、Support - に対して、usage権限を付与してこのデータシェアへのアクセスを許可します。この2つの簡単なステップで、Salesは他のエンドポイントにこの共通テーブルへの書き込み権限を与えることができます。消費側のエンドポイント - Finance、Marketing、Support - では、このデータシェアを指すローカルデータベースインスタンスを作成するだけです。
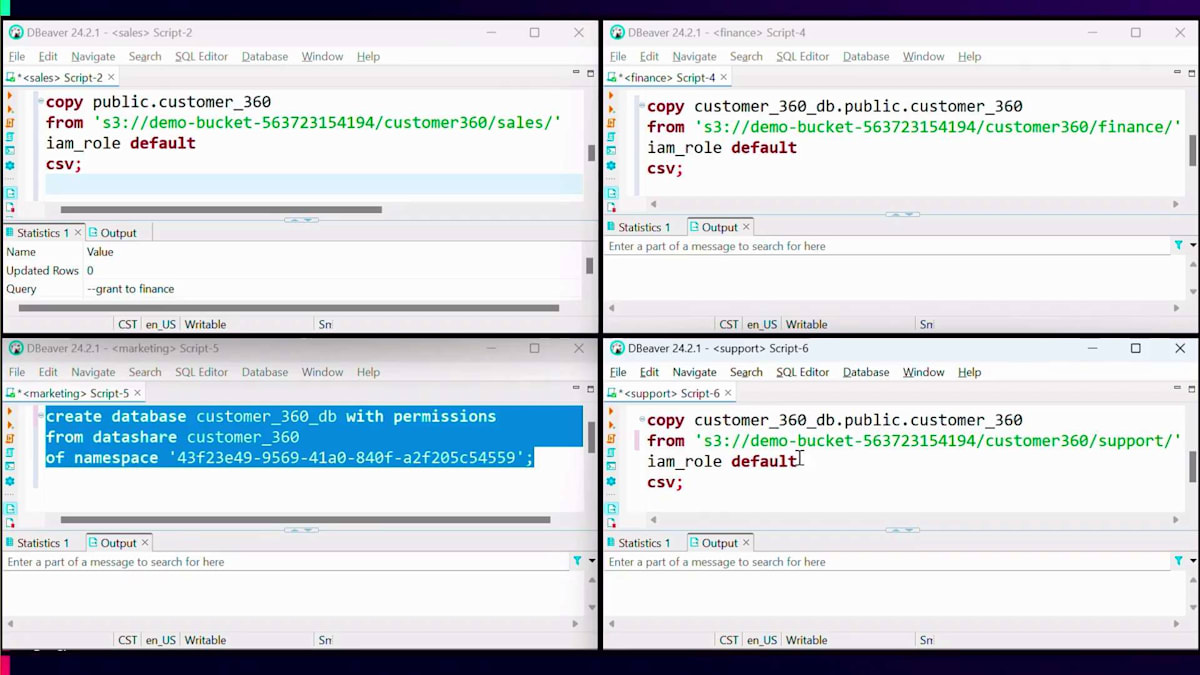

ローカルデータベースインスタンスが利用可能になったら、お好みのロード方法を使用できます。ここではバルクロードメカニズムであるcopyコマンドを使用していますが、insertやその他の挿入メカニズムを使用してテーブルにデータをロードすることもできます。これらのcopyコマンドは全て同時に同じテーブルにロードしているのがわかります。ロードが完了すると、画面でご覧いただけるように、他のすべてのエンドポイントがトランザクションの一貫性を保ちながらデータを参照できます。Salesエンドポイントからそのクエリを実行すると、ロードが完了次第、データが利用可能になっているのがわかります。

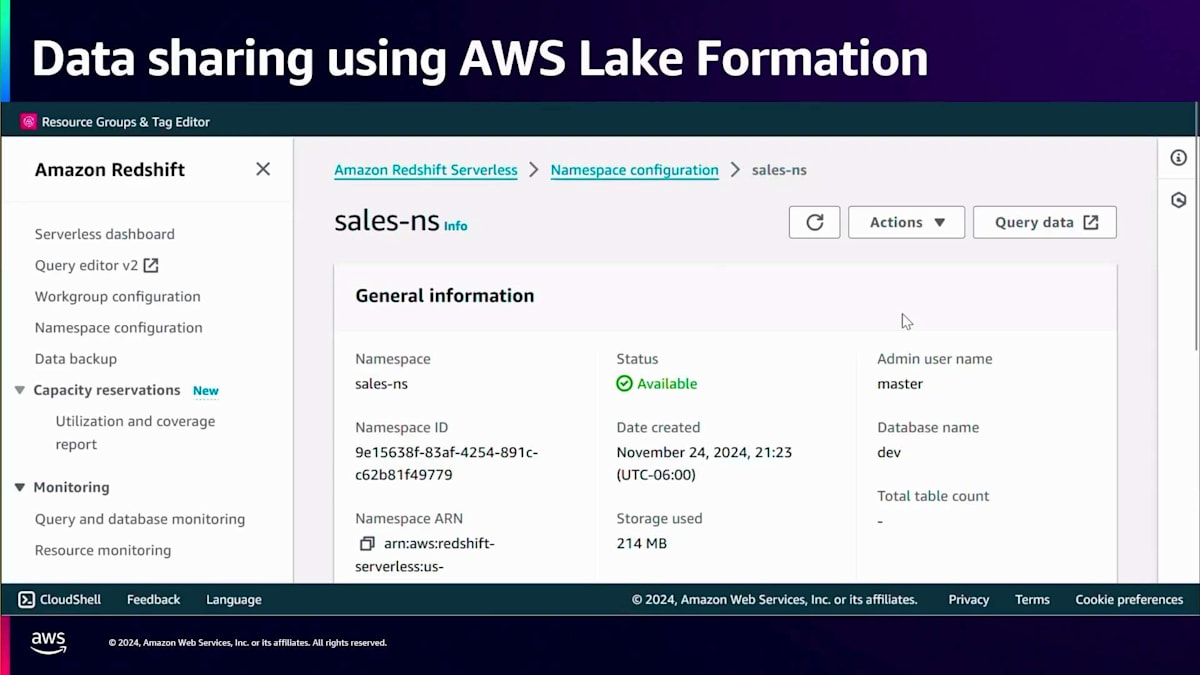
このように、すべてのデータインジェクションは分離されています。各ビジネスユニットは完全に分離された形で、それぞれのデータアセットのインジェクションを実行しています。このデモのパートでご覧いただいたのは、Amazon RedshiftからAmazon Redshiftへのデータ共有です。Nareshが、AWS Lake Formationを使用してこれらすべてを一元的に管理する方法について説明しました。では、その方法を見ていきましょう。例えば、Salesが自分たちのデータテーブルを持っていて、Financeにセールステーブルへの権限を付与したい場合を考えてみましょう。Financeがアクセスを必要とするcustomerというテーブルがあります。




これを実現するために、Salesは自分のNamespaceでData Catalogへの公開を行います。Data Catalogは同じアカウント内でも、別の集中管理用アカウントでも構いません。公開されると、管理者はAWS Lake Formation カタログにアクセスし、リクエストを確認してSalesカタログを作成します。このカタログに適切な権限を持つIAMロールを紐付けてカタログを作成します。カタログが作成されると、そのカタログの下にすべてのSalesテーブルが表示されます。
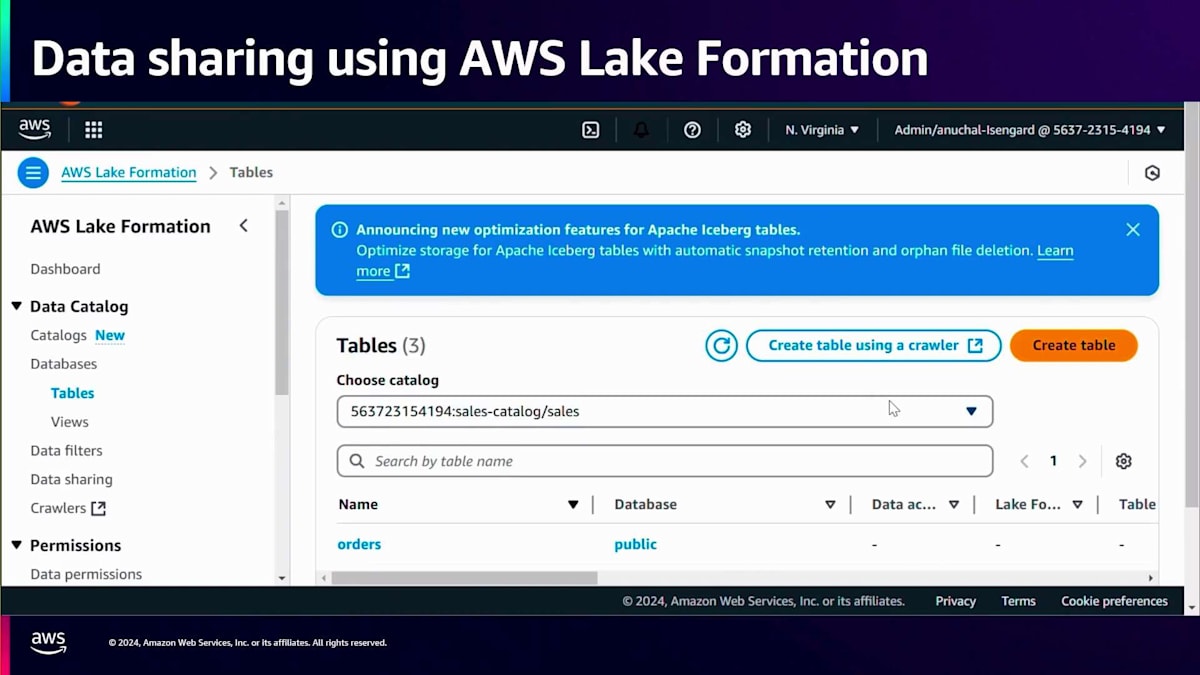


Salesカタログがあり、それを選択してテーブルを表示すると、すべてのSalesテーブルが表示されます。カタログを開くと、orders、customer、line itemsが表示され、ここでcustomerテーブルを選択してこのcustomerテーブルに対する権限を付与できます。ここではFinanceアナリストに権限を付与しています。テーブル全体へのアクセス権を付与したり、個別の列や個別の行を選択したり、きめ細かなアクセス制御を実装したりできます。


権限の付与が正常に完了したら、Financeアナリストとしてアマゾン Redshiftにログインしてみましょう。Financeアナリストに何が見えるか確認してみましょう。Financeアナリストは、Financeワークグループへのアクセス権を持っているので、Federatedユーザーとしてログインします。ログインすると、追加の設定なしで、アクセス権を付与されたSalesデータベースとcustomerテーブルが表示されます。これらのシンプルなステップ - Namespaceをカタログに公開し、AWS Lake Formationを使用して権限管理を行い、そのビジネスユニットのデータアセットに対してアクセス権を付与する - だけで、必要な人がアクセスを得ることができます。このように、各ビジネスユニットは誰が何を見ることができるかを制御し、データアセットを共有する際のコンプライアンス要件を遵守することができます。
このアップデートされたアーキテクチャでは、1つのエンドポイントで問題のあるクエリが発生しても、コンピュートが完全に分離されているため、他のエンドポイントには影響を与えません。影響範囲がはるかに小さくなり、問題のあるプロセスの影響は特定のエンドポイントに限定されます。各エンドポイントは、それぞれ固有の要件に基づいてスケールアップ・ダウンが可能です。

分離を実装した後のメトリクスを見てみましょう。グラフを見ると、以前のバージョンでは赤い指標が多く表示されていましたが、現在ではほとんど赤い部分が見られないことがわかります。これは、リソースの競合が大幅に減少したことを示しています。さらに、これらの各エンドポイントは、それぞれのコストセンターにタグ付けすることができ、チャージバックのプロセスが容易になります。


コスト配分を見てみましょう。タグ付けを行うと、Cost Explorerで営業、財務、マーケティング、サポートなど、各ビジネスユニットごとのコストを確認できます。これにより各ビジネスユニットへのコスト配分が簡単になります。ここでベストプラクティスをまとめてみましょう。Amazon Redshiftのマルチクラスターアーキテクチャを設計する際は、各ワークロードまたはグループごとに個別のエンドポイントを作成し、そのワークロードの固有の要件に基づいてエンドポイントのサイズを設定します。Serverlessを使用すれば、AI駆動のスケーリングを活用してエンドポイントのサイズを自動的に決定できるため、この作業が容易になります。そして、AWS Lake Formationを使用して、一元的なデータガバナンスとアクセス権限の管理を行います。
マルチクラスターアーキテクチャへの移行ステップとまとめ

シングルクラスターアーキテクチャを使用している方もいらっしゃるようですが、私たちはすべての処理を1つのエンドポイントで処理するシンプルな構成から始めるお客様も見てきました。このような状況にある場合、あるいはすでにシングルクラスターアーキテクチャを使用している場合、4つのステップでマルチクラスターアーキテクチャに変換する方法を見てみましょう。ここで示しているのは、ETL、レポート、データサイエンス、アドホッククエリという4つの一般的なデータウェアハウスのワークロードがすべて同じエンドポイントで実行されているシングルクラスターアーキテクチャの例です。




これをHubとSpokeのアーキテクチャに変換する方法を見てみましょう。最初のステップは、各ワークロードまたはグループごとにスナップショットを作成してリストアすることです。この例では、ETLはHubに残し、レポート、ダッシュボード、データサイエンスという他の3つのワークロードに対して、スナップショットを作成してリストアし、3つの個別のエンドポイントを作成します。次に、消費アプリケーションの接続先を、モノリスから作成した個別のエンドポイントに変更します。それが完了したら、これらのエンドポイントから関係のないスキーマを削除すると、HubとSpokeの準備が整います。最後のステップは、Hubから消費エンドポイントへデータを共有することです。これら4つのシンプルなステップで、シングルクラスターアーキテクチャをマルチクラスターアーキテクチャに変換することができます。

後ほど参照できるマルチクラスターアーキテクチャについて、いくつかのブログをご紹介します。ここで少し時間を取りますので、このの画面を撮影して、後でこれらのブログを参照してください。本セッションにご参加いただき、ありがとうございました。アプリでアンケートへのご回答をお願いいたします。このような内容をご紹介できて大変嬉しく思います。ご質問がございましたら、お気軽にお申し付けください。
※ こちらの記事は Amazon Bedrock を利用することで全て自動で作成しています。
※ 生成AI記事によるインターネット汚染の懸念を踏まえ、本記事ではセッション動画を情報量をほぼ変化させずに文字と画像に変換することで、できるだけオリジナルコンテンツそのものの価値を維持しつつ、多言語でのAccessibilityやGooglabilityを高められればと考えています。
Discussion