カレンダーアプリとFitbitのデータを分析するために、dbtでディメンショナルモデリングをしてみた
背景
先日、勉強を兼ねてカレンダー形式のタスク管理&プロジェクト管理アプリを作成しました。
このアプリは「プロジェクト作成」「予定カレンダー作成」「タイマー記録」の3画面から構成されています。
既存カレンダーアプリとの大きな違いは、登録した予定と実際の行動記録を比較できることです。
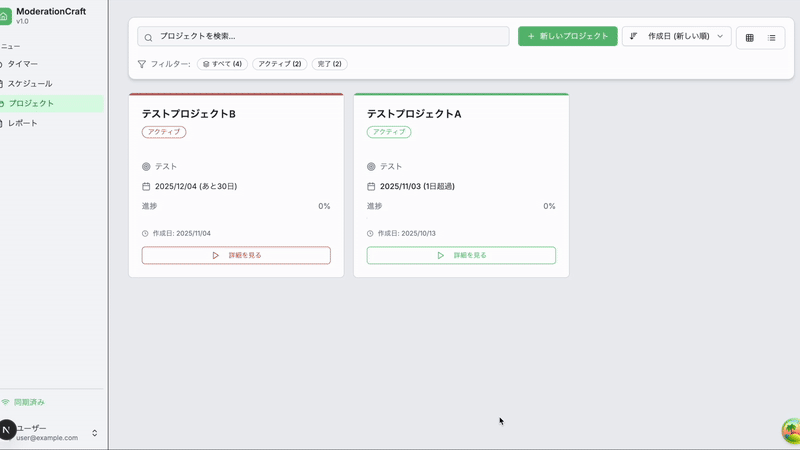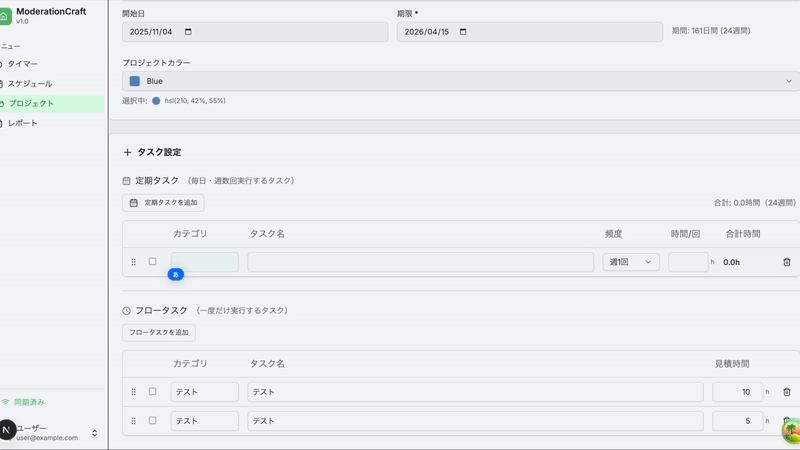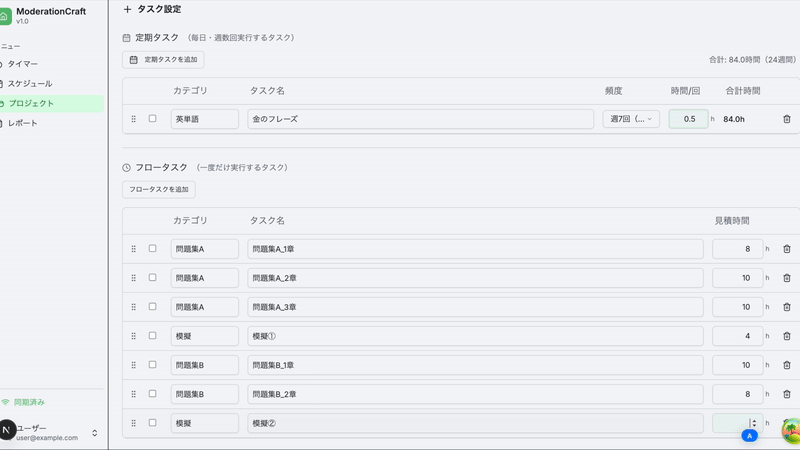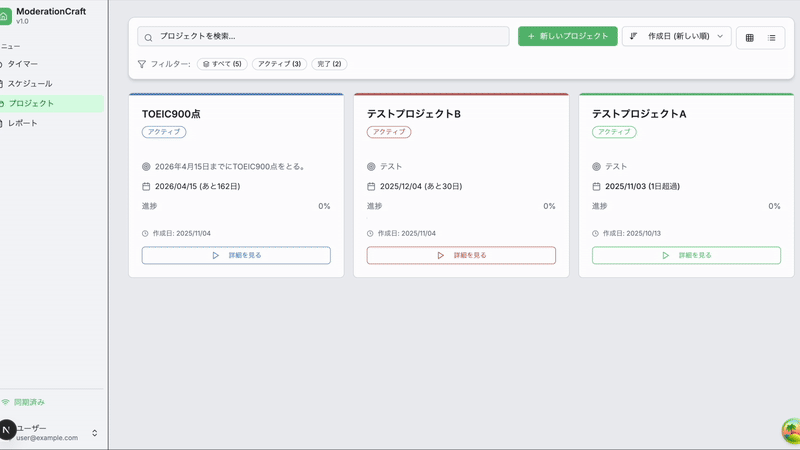
プロジェクトを作成して、
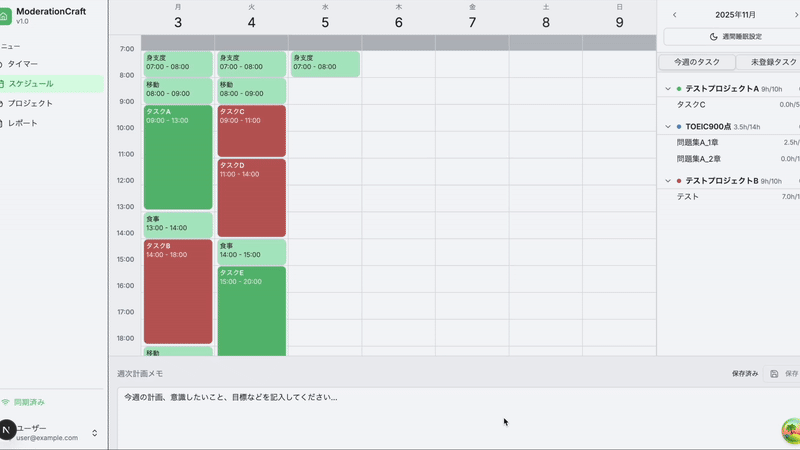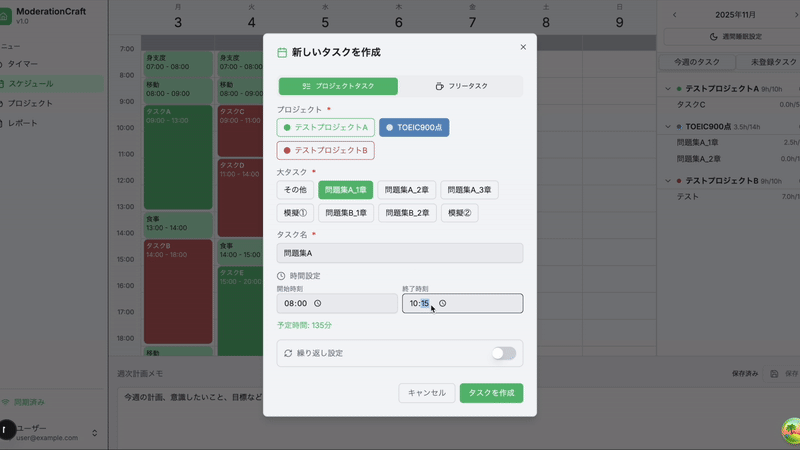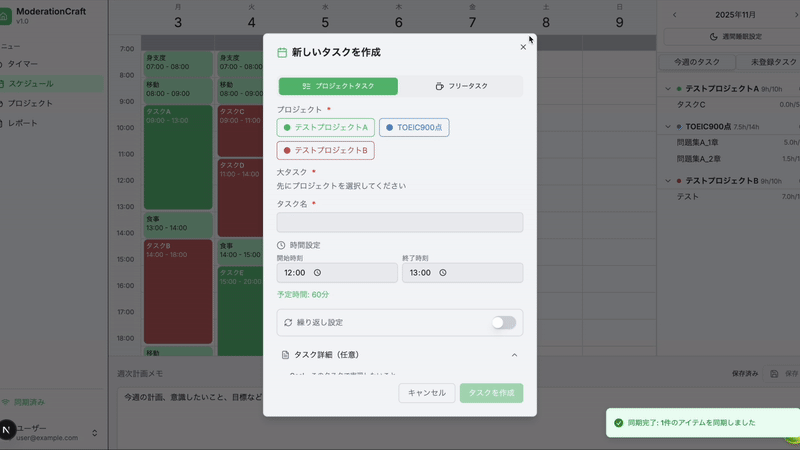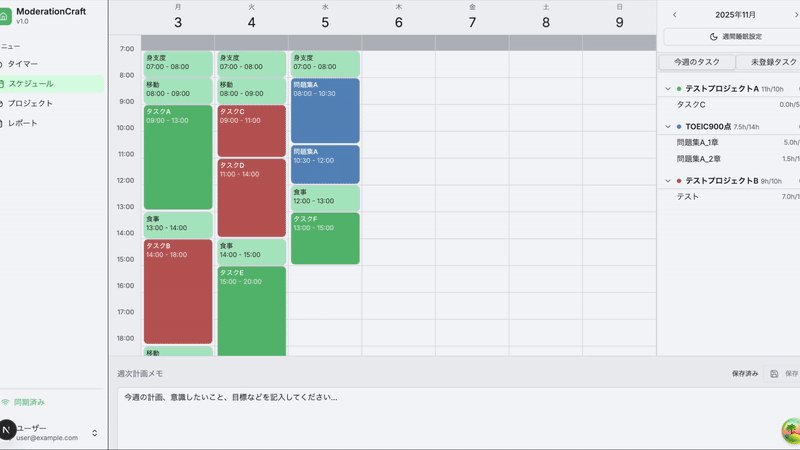
プロジェクトに紐づくタスクを予定にいれ、
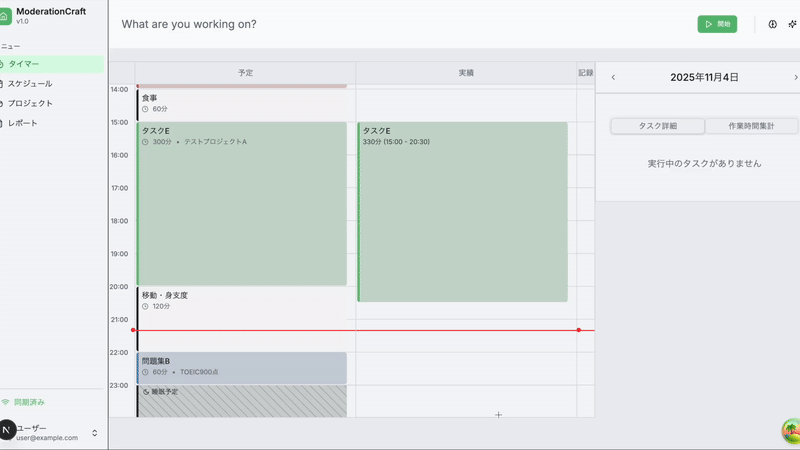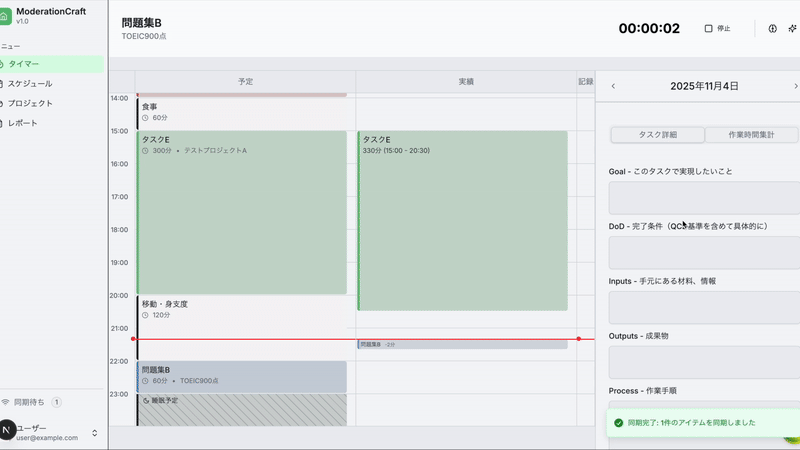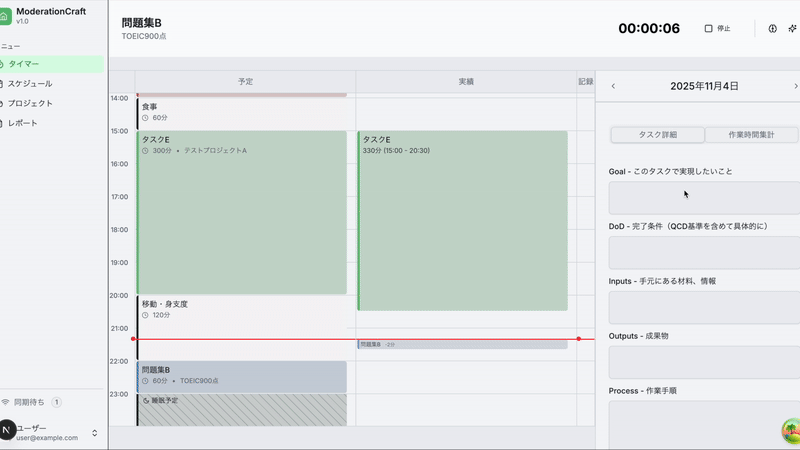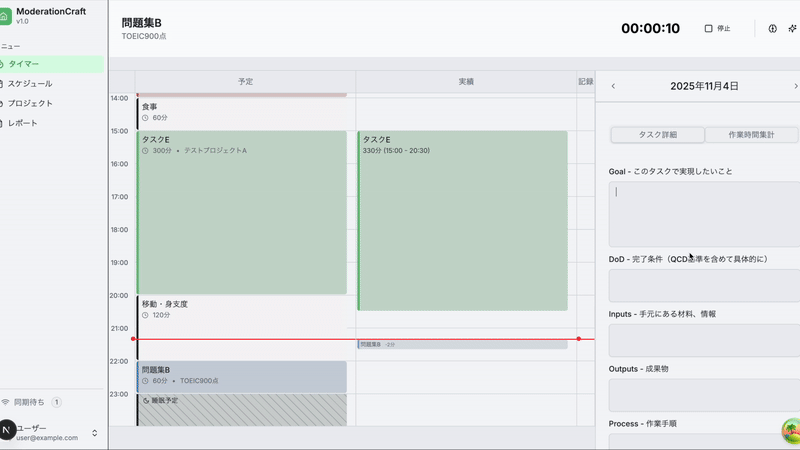
実際に記録
このアプリを作成したきっかけは三宅孝之さんの2時間かけてスケジュールを立てれば、勉強も仕事もうまくいくという記事でした。
簡単に説明すると、、
1. 毎週日曜日に2時間かけて1週間の超細かいスケジュールを立てる
2. 立てたスケジュールを絶対守る
ことで時間を制御しよう!という考え方です。
こちらに影響を受け、手帳に1週間のスケジュールを書いているのですが、せっかくならデータで保存したいと思い、専用アプリを作成しました。
データを分析できる形に整える
上記のアプリで活動記録を取得できるようになったので、BIツールで可視化・分析をしてみます。
また、Fitbitから取得した「睡眠」や「運動量」のデータも組み合わせて、
どんなコンディションのときに作業が捗るのかを分析します。
使用ツールとデータの流れは以下の通りです。
- DynamoDB:アプリのメインデータ保存先
- S3:DynamoDBのデータをエクスポートして一時保管
- DuckDB + dbt:S3上のデータを変換・集計(分析用データモデル化)
- Streamlit:分析結果をダッシュボードとして可視化

本記事では、アプリで生成されたデータをdbtを使って分析しやすいモデルに変換します。
その際に参考にしたのが、分析データ設計の方法論 「ディメンショナルモデリング」 です。
ディメンショナルモデリングとは
前提|OLTPとOLAP ~2つの情報システム~
情報システムは大きく2種類に分けられます。
「業務システム(OLTP:Online Transaction Processing)」 と
「分析システム(OLAP:Online Analytical Processing)」 です。
業務システムとはビジネスの"実行"を支援するシステムです。
営業支援のSalesforce(SFA/CRM)、調達管理支援のSAP(ERP)、会計・経費精算支援のfreeeなどがあたります。
これらでは、データの追加、更新、削除が頻繁に起こります。
データの更新時に整合性を保つために、業務システムではデータベースの正規化(複数のテーブルに分けて重複をなくすこと)をします。
一方、分析システムはビジネスの”評価”を支援するシステムです。
分析システムを構成する代表的なツールには、TableauなどのBIツールやそれらの基盤となるBig Query、Snowflakeなどのデータウェアハウスがあります。
分析システムは業務システムと異なり、データベースの更新はほとんどなく、基本的に読み取られるのみです。
ディメンショナルモデリングとは分析システム(OLAP)のための方法
ディメンショナルモデリングとは、分析システムのためのデータ設計手法です。
内容の説明に入る前に、まずテーブル構造を見てみましょう。
以下は、自動車販売データをディメンショナルモデリングで設計した例です。

ディメンショナルモデリングは、「ファクトテーブル」 と 「ディメンションテーブル」 から構成されます。
また、上図のように、1つのファクトテーブルを中心に複数のディメンションテーブルが放射状に接続された構造を、 スタースキーマ(Star Schema)と呼びます。
ファクトとは、集計対象となる数値データのことです。たとえば「成約数」や「成約金額」などが該当します。
対して、ディメンションは 集計の切り口(分析軸) を表します。「顧客の年代」「購入車種」「販売店」などがこれにあたります。
つまり、集計対象であるファクトをどの軸で分類・分析するかを定義するのがディメンションです。
ディメンションは 5W1H(When・Who・What・Where・How) の観点で整理されます。
ディメンショナルモデリングを採用する2つの理由
ディメンショナルモデリングの利点は2つあります。
「必要なデータだけをスキャンするため、集計が速い(コンピュータにやさしい)」
「分析の切り口(ディメンション)が整理されているため、クエリを直感的に書ける(人間にやさしい)」 の2つです。
集計が速い(コンピュータにやさしい)
集計が速くなるのは、正規化されたデータモデルよりもテーブルの結合(JOIN)の回数を減らせるため、読み取りデータ量が抑えられるからです。
先ほどのスタースキーマを正規化した場合、以下のようになります。

たとえば、この状態で「千葉県 船橋市のSUVの売上」を確認しようとすると、以下のように複数のテーブルを結合する必要があります。

地域は「注文テーブル → 販売店テーブル → 地域テーブル」、
ボディタイプは「注文テーブル → 車種テーブル → ボディタイプテーブル」と不必要に中間テーブルを辿る必要があります。
つまり、 分析に直接は不要でも、属性に到達するための“中継テーブル” を複数回JOINします。
一方、ディメンショナルモデリングでは、分析でよく使う属性をディメンション1枚に寄せるため、ファクトから1回のJOINで到達できます。
これにより、不要な中間結果の生成を避け、読み取りデータ量を最小化できるのです。

クエリが書きやすい(人間にやさしい)
業務におけるデータ分析の目的をシンプルに言えば、
「目標に対して不足している原因を見つけること」 です。
たとえば営業成績が未達だった場合、
「訪問数」が足りなかったのか?「成約率」が下がったのか?
さらに、「成約率」が下がった理由は「営業担当者(=教育・フォロー体制)」なのか、
それとも「商品力」そのものが下がっているのか。
このように要素を分解していくことで、改善の糸口を探ることができます。
このとき役立つのが ディメンショナルモデリング です。
ファクト(例:売上金額)を中心に、商品・担当者・顧客など複数のディメンションを組み合わせて分析することで、「どの切り口で成果が変わっているのか」を明確に把握できます。
さらに、ディメンショナルモデリングでは、ビジネスの文脈に沿ってディメンションが整理されているため、分析が直感的で分かりやすく、あとから新しい軸(ディメンション)を追加することも容易です。
データモデル全体像
ここまでで、分析に適したデータ構造(ディメンショナルモデリング)の考え方を整理しました。
ここからは、実際に個人開発アプリのデータを使ってどのようにモデリングを行ったかを紹介します。

S3からインポートしたデータをdbtで加工します
今回は、取得したデータを次の3層に分けて変換していきます。
- staging:ソースデータをクレンジングして、分析可能な形式に整える
- intermediate:複数ソースを結合し、ビジネスロジックを反映させる
- marts:分析・可視化に最適化された最終データを作成する
(参考:dbtのベストプラクティス)
3つ目の mart層 の中では、さらに以下の3種類のモデルを作成しています。
- ファクトテーブル(Fact):数値を集計する中心テーブル
- ディメンションテーブル(Dimension):分析の切り口となる軸
- BI用集計テーブル(BI):FactとDimensionを結合した最終的な可視化用データ
実際のディレクトリ構成は以下のようになりました。
dbt/models/
├── staging/ # ステージング層(生データのクレンジング)
├── intermediate/ # 中間層(ビジネスロジック適用)
└── marts/ # マート層(分析用最終テーブル)
├── _marts.yml
├── dim/ # ディメンション(分析軸)
├── fct/ # ファクト(事実データ)
└── bi/ # BIレポート用集計テーブル
実際にモデルを作ってみる
ディレクトリ構成が整ったところで、いよいよディメンショナルモデリングの実装に移ります。
Step1.マトリクス作成
目的: 分析の切り口(ディメンション)と事実(ファクト)を整理し、全体の構造を可視化する。
dbtでSQLを書く前に、まずはファクトテーブルとディメンションテーブルを整理します。
マトリクス形式でビジネスイベントを洗い出し、どのデータをどの粒度で扱うかを定義します。
以下は、例として営業組織の「引合・受注・納品」までの流れをファクトとディメンションに整理したものです。

ディメンション(分析軸)は5W1Hで分けていくとわかりやすいです。
同様に、今回のアプリで作成したマトリクスがこちらです。
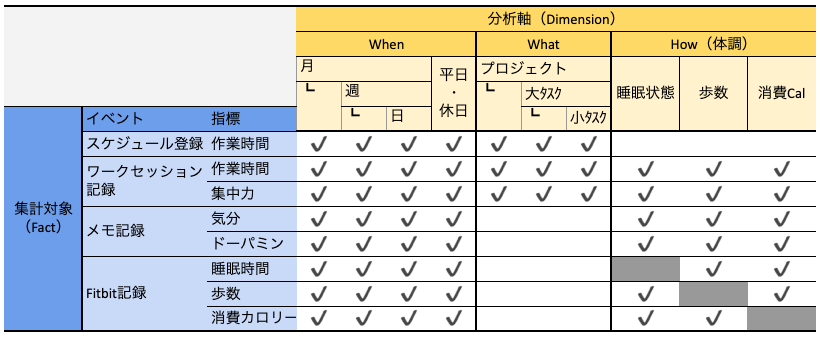
期間やプロジェクトは入れ子になっているため、階層的に表現します。
Step2.ファクトテーブル・ディメンションテーブル作成
目的: マトリクスで整理した構造をdbtモデルとしてコード化する。
マトリクスを書いたことで、集計するデータが一目で把握できるようになりました。
実際に、dbtでモデルを作成していきます。
(実際にはstaging層とintermediate層での前処理が必要ですが、本記事では省略します)
mart配下のdim(ディメンション)とfct(ファクト)にマトリクスに沿って以下のようなモデルを作成します。
dbt/models/
├── staging/ # ステージング層(生データのクレンジング)
├── intermediate/ # 中間層(ビジネスロジック適用)
└── marts/ # マート層(分析用最終テーブル)
├── _marts.yml
├── dim/ # ディメンション(分析軸)
│ ├── dim_date.sql # When(月/週/日・平日/休日)
│ ├── dim_project.sql # What(プロジェクト)
│ ├── dim_big_task.sql # What(大タスク)
│ └── dim_health_category.sql # How(体調)
├── fct/ # ファクト(事実データ)
│ ├── fact_small_tasks.sql # スケジュール登録
│ ├── fact_work_sessions.sql # ワークセッション記録
│ └── fact_daily_health.sql # Fitbit記録
└── bi/ # BIレポート用集計テーブル
Step3.ダッシュボード用モデル作成
ファクトテーブルとディメンションテーブルが整備されたことで、レポートの作成がやりやすくなりました。
「前日の睡眠時間が帰宅後の勉強時間にどう影響するか?」 を可視化してみます。
ここで必要なファクトとディメンションは以下になります。
-
ファクト(集計対象)
- 作業時間:fact_work_sessions.sql
-
ディメンション(分析軸)
- 平日/休日:dim_date.sql (仕事のある平日だけ絞る)
- プロジェクト:dim_project.sql (対象のプロジェクトだけ絞る)
- 体調:dim_health_category.sql (睡眠時間で比較する)
これらを用いてmart_sleep_work_correlation.sqlというモデルを作成。Streamlitで可視化させたのがこちらです。
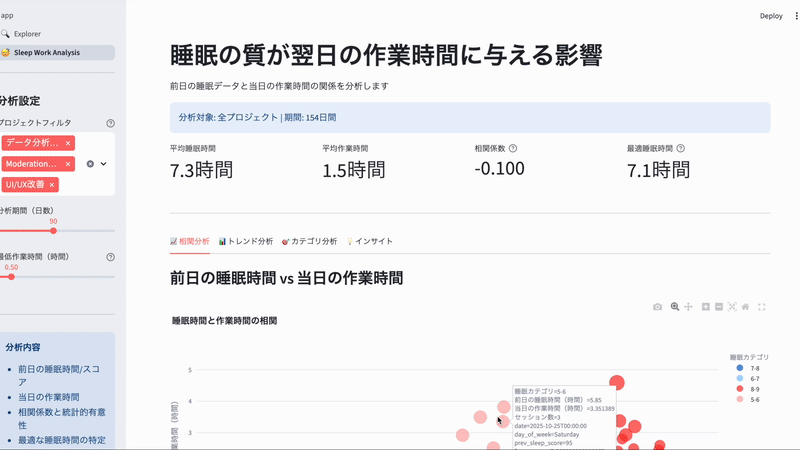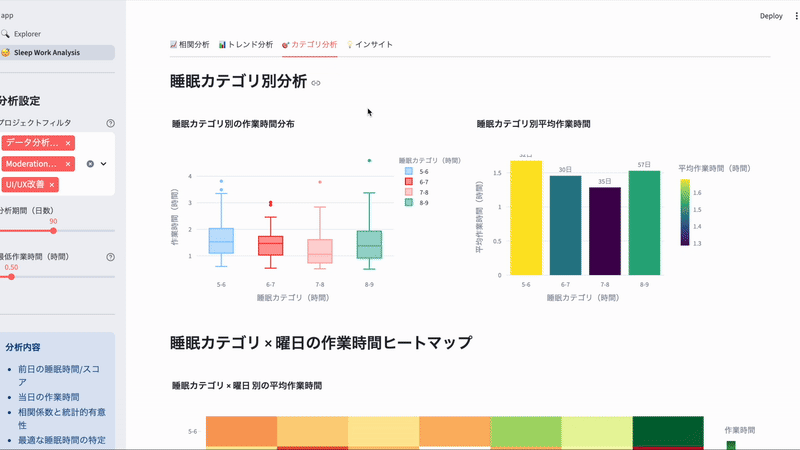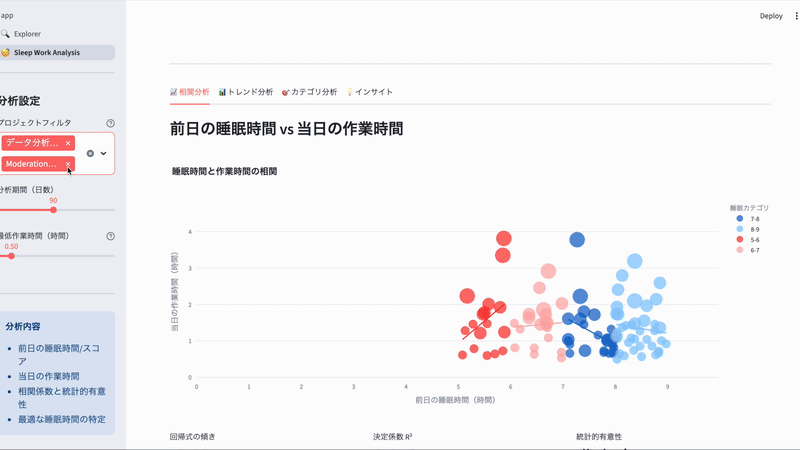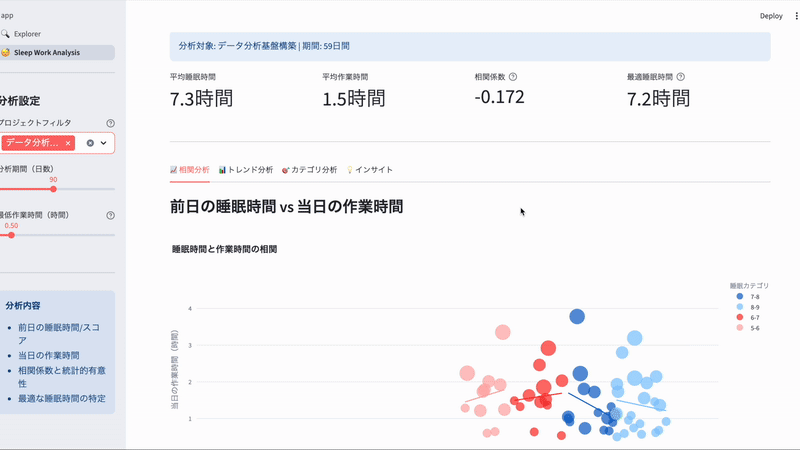
一旦モックデータを入れています
Claude Codeにざっくり作ってもらったのでチューニング必要ですが、いい感じに作ってくれました。(AIへの指示にも役に立ちそうでよかった!)
今後はこのモデルをベースに、睡眠や運動量と生産性の関係をさらに分析していく予定です。
参考にさせていただいた記事・スライド・書籍
Discussion