カウンターワークスで主にDevOpsなところでお手伝いしている@tchikubaです。ベンチャー企業のTech支援やアジャイルコーチ、エンジニア向け研修など複数社に関わっています。
✍️ はじめに
Cloudflare Workers を本番環境で運用していると、避けて通れないのが「ログ基盤」の問題です。
カウンターワークスの環境では、Workers は単なるフロントの CDN としてだけではなく、
-
リバースプロキシとしての役割を持ち
-
パスルールに応じて
- Vercel(Next.js)
- Rails API(ECS/Fargate)
- Go API(ECS/Fargate)
- メディア(WordPress or Cloudflare Workers)
へリクエストを正しく振り分ける
という、複数バックエンドの“ゲートウェイ”として機能しています。

カウンターワークスのシステム構成
この構成では、Workers が 外部アクセスのすべての入口になるため、
- どの URL がどれだけ呼ばれているか
- どの経路(Vercel / API / メディア)に流れているか
- ステータスコード/遅延はどうか
- 障害時にどの段階で詰まっているのか
といったログが、プロダクトの安定運用に不可欠な情報になります。
しかし、Cloudflare Workers には標準で「自由に外部へログ転送する」機能がありません。
Cloudflare には Logpush というログ転送サービスが存在しますが、現状利用できるのは Enterprise プランのみ[1]で、Pro/Business では利用できません。
「Enterprise プランに依存せずに、Workers のログを安価かつ確実に BigQuery に転送したい」
という課題を解決するために、Cloudflare Queue / R2 と、既存で利用していた digdag / embulk / BigQuery を組み合わせて、サーバーレスに近い形の ETL パイプラインを構築しました。
結果として$400/month程度で、
- Workers のログをロスなく収集
- 柔軟な JSON フォーマットで自由に拡張
- 日次/時間単位の集約
- BigQuery で全量を高速クエリ
が実現できています。
本記事では、この 「Workers → Queue → R2 → digdag → embulk → BigQuery」 というログ転送パイプラインについて、実際のコードと運用方法を含めて詳しく解説します。
特に、R2 や Queue の実践例はまだ少ない中で、組み合わせ次第で十分に実用的なログ基盤が作れることをお伝えしたいと思います。
🏛️ ログETLの全体アーキテクチャ
本記事の中心となるログ ETL パイプラインは、次の 5 つのコンポーネントで構成しています。
-
Cloudflare Workers
リクエスト単位でログを JSON として生成し、Cloudflare Queue に積む。 -
Cloudflare Queue
Workers から送られたログをバッファリングし、一定件数ごとに Queue Consumer(Worker)へ渡す。 -
Cloudflare Queue Consumer(Workers)
Queue から受け取ったログをバッチ単位でまとめ、R2 にファイルとして書き込む。 -
Cloudflare R2
時分・バッチ単位のログファイルをオブジェクトストレージとして保存する。 -
digdag + embulk(GCP)
1時間ごとのバッチ処理(Cloud run jobs)で R2 内のログを取得し、Embulk で JSON → BigQuery へロードする。 -
BigQuery
保存先のデータウェアハウス。日次パーティションを切ってクエリしやすい構造にしている。
R2 を中心とした ETL パイプラインは、ほぼサーバレス構成でありながら、ログをほぼロスなく・安価に・柔軟に蓄積できるのが特徴です。
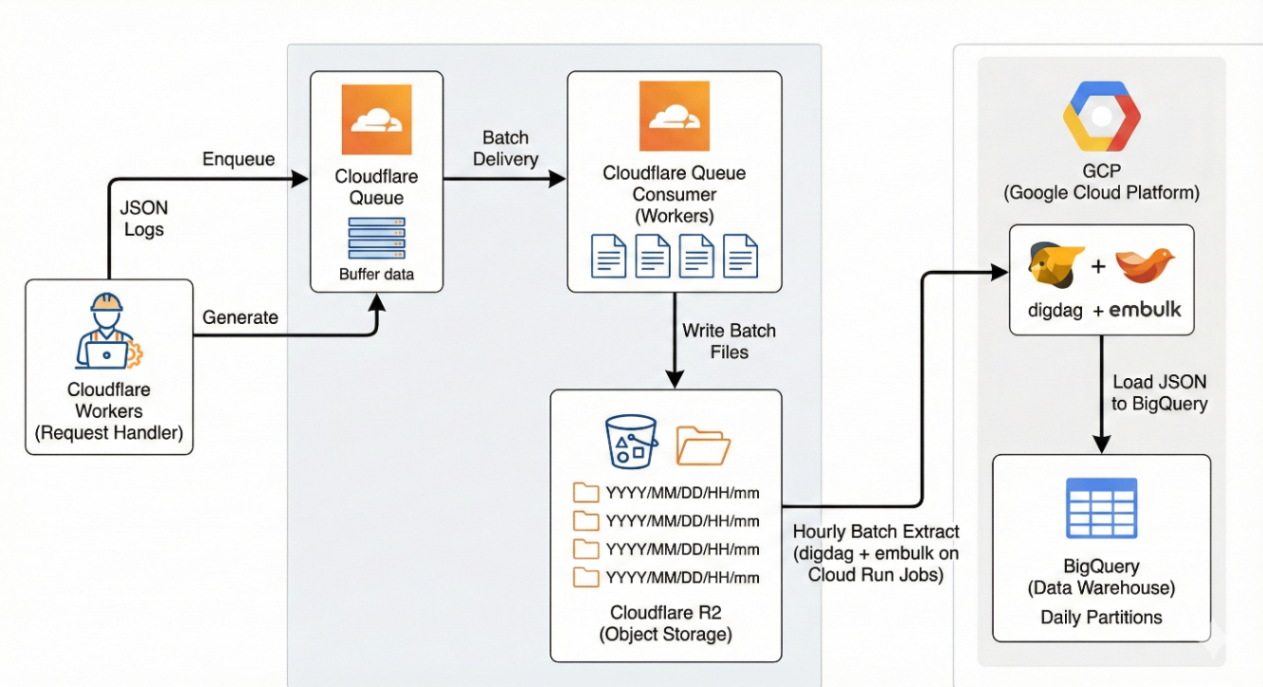
ログETLの全体アーキテクチャ
フローの全体像
- Cloudflare Workers がリバースプロキシとして動作し、各リクエストを処理する際に JSON 形式のログを生成する。
- 生成したログは Cloudflare Queue に非同期で enqueue されるため、元のリクエスト処理に遅延を与えない。
- Queue に溜まったログは Queue Consumer Worker によりバッチ単位で取り出され、まとまった JSON 配列として Cloudflare R2 にファイル書き込みされる。
- 日次の digdag ジョブが R2 の prefix を走査し、その日のログをすべてローカルに取得する。
- embulk が R2 から取得した JSON ファイルを BigQuery にロードする。
- BigQuery で可視化・分析・監視クエリを実行できる。
この構成により、Logpush を使わずとも、Enterprise プラン相当のログ基盤が自前で実現できます。
Queue と R2 が扱いやすいので、Worker 側の実装もシンプルで、バックエンドを持たない完全サーバレス ETL に近い体験が得られます。
⚒️ Workers / Queue / R2の実装
次に、Cloudflare Workers で生成したログを Queue に送り、Queue Consumer がそれを Cloudflare R2 に保存するまでの処理を、実際のコードとともに説明します。
カウンターワークス環境ではログの R2 オブジェクトキーを以下のような階層構造にしています:
workers-logs/{YYYY}/{MM}/{DD}/{HH}/{mm}/{ss.sss}-{uuid}.json
例:
workers-logs/2025/11/28/00/14/28.751-ad94a3d6-0e95-4ff7-b2c1-b292cebce0d4.json
これは R2 の directory listing 最適化・日付別の高速集計・秒単位の粒度管理・衝突回避の UUID という設計です。詳細については後述します。
Workers:リバースプロキシ内でログを生成 → Queueに送信
Workers は Vercel・Rails(ECS)・Go(ECS) へのゲートウェイになっており、その処理中に 1 リクエスト 1 JSON のログデータを生成します。
ログは非同期で Queue に送られ、リクエスト処理には影響しません。
✔ 実装例:Workers → Queue
たったこれだけのコードでWorkerログをQueueに積むことができます。
[[queues.producers]]
queue = "logs-queue"
binding = "WORKERS_LOGS_QUEUE"
const handle = async (request: Request, env: Env, ctx: ExecutionContext): Promise<Response> => {
let response = route(request, env);
return response.then(async (resolvedResponse) => {
const log = buildWorkersLog(request, resolvedResponse);
ctx.waitUntil(
(async () => {
try {
if (env.WORKERS_LOGS_QUEUE) {
await env.WORKERS_LOGS_QUEUE.send(log);
}
} catch (error) {
// queueに積んで例外発生しても本処理に影響させない
console.error('Failed to send log to queue:', error);
}
})(),
);
return resolvedResponse;
});
};
Queue Consumer:バッチログをR2に保存
Queue には 1 リクエストごとにログが積まれますが、Queue Consumer Worker ではbatch.messages を活用して一定件数(最大 100 件: tomlのmax_batch_sizeで指定)処理し、1 ファイルにまとめて R2 に保存しています。
✔ オブジェクトキー生成とQueue → R2
こちらも非常にシンプルな実装でQueueからR2への転送を実現できます。
[[queues.consumers]]
queue = "logs-queue"
max_batch_size = 100 # default: 10
max_batch_timeout = 5 # default: 5 seconds
[[r2_buckets]]
bucket_name = "logs-bucket"
binding = "WORKERS_LOGS_BUCKET"
export interface WorkerLogsEnv {
WORKERS_LOGS_BUCKET: R2Bucket;
}
export async function handleWorkerLogsQueue(
batch: unknown,
env: WorkerLogsEnv
): Promise<void> {
const messages = JSON.stringify(batch.messages);
const now = new Date();
const jst = new Date(now.getTime() + 9 * 60 * 60 * 1000); // JST
const year = jst.getFullYear();
const month = String(jst.getMonth() + 1).padStart(2, '0');
const day = String(jst.getDate()).padStart(2, '0');
const hour = String(jst.getHours()).padStart(2, '0');
const minute = String(jst.getMinutes()).padStart(2, '0');
const second = String(jst.getSeconds()).padStart(2, '0');
const millis = String(jst.getMilliseconds()).padStart(3, '0');
const uuid = crypto.randomUUID();
const logPrefix = 'workers-logs';
const filename = `${logPrefix}/${year}/${month}/${day}/${hour}/${minute}/${second}.${millis}-${uuid}.json`;
try {
await env.WORKERS_LOGS_BUCKET.put(filename, messages, {
httpMetadata: {
contentType: 'application/json',
},
});
console.log(`Saved ${messages.length} messages to R2: ${filename}`);
} catch (error) {
console.error('Failed to save messages to R2:', error);
}
}
R2オブジェクトキー形式の理由
キー形式のメリットは以下の通りです。
-
秒以下レベルでのログファイル分散
R2 の listing が重くなることを避けられ、特に digdag バッチの処理速度が安定しやすくなります。 -
年月日・時・分単位でクエリできる
分析では時間軸での集計がほぼ必須となるため、BigQuery のパーティション化と相性が良くなります。 -
名前衝突ゼロ(UUID)
Queue の batch 処理が複数並列に走っても、UUID により衝突が発生しません。 -
ローテーションが容易
古い prefix を削除しやすく、ライフサイクル管理も適用しやすくなります。 -
下位階層が固定長で listing が高速
ディレクトリ構造が規則的なため、digdag の S3 sync が安定して実行できます。
R2バケット内の実際の構造
workers-logs/
└── 2025/
└── 11/
└── 28/
├── 00/
│ ├── 14/
│ │ ├── 28.751-ad94a3d6-0e95-4ff7-b2c1-b292cebce0d4.json
│ │ ├── 28.910-bf4e4aaa-19f1-4b17-8f35-cf6bfb7870e2.json
│ │ └── ...
│ └── 15/
│ └── ...
└── 01/
└── ...
digdag が workers-logs/2025/11/28/** を拾うだけで、その日のログがすべて取得できます。
ここまでで完成するもの
- Workers → Queue → R2 のログ基盤(Cloudflare 側)
- 完全サーバーレスでログ転送
- cloudflareコストは$100/monthレベル
- 誰でも再現できるシンプルで壊れにくい構成
📦️ Cloudflare R2に蓄積したログをdigdag + embulkでBigQueryに転送
Cloudflare Workers → Queue → R2 の段階で、ログは時刻・UUID ベースの階層構造の JSON ファイルとして R2 に蓄積されます。
本章では、これらのログを digdag + embulk を用いて BigQuery に毎時(hourly)でロードする処理について紹介します。
Google Cloud側のETL
ログ転送パイプラインの後半は、以下の流れで構成しています。
- Cloudflare R2 上の対象ログファイルを embulk で直接読み込む
- JSON 配列として保存されたログを、embulk のフィルタで 1 レコードずつ展開
- Cloudflare Workers / cf.* 系のネストした JSON をフラットなテーブル構造へ変換
- BigQuery に append し、
timestampカラムで日次パーティション分割
毎時(hourly)実行とすることで、集計遅延を抑えつつコストと運用負荷のバランスを取っています。
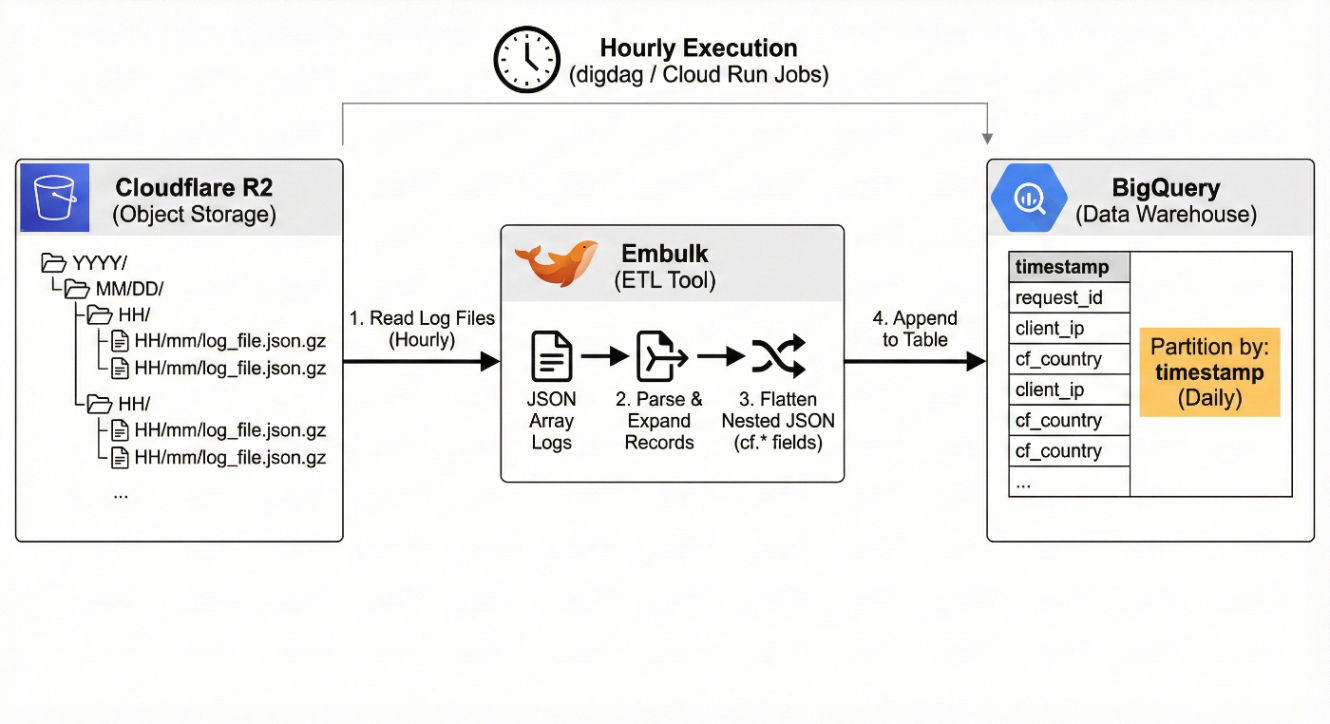
Google Cloud側ETLの概念図
R2の読み込み
R2 からの取得には、embulk の org.embulk:s3 input プラグインを利用します。
R2 は S3 API 互換のため、そのまま endpoint を差し替えるだけで読み込み可能です。
in:
type:
source: maven
group: org.embulk
name: s3
version: 0.6.0
endpoint: "https://{{env.CLOUDFLARE_ACCOUNT_ID}}.r2.cloudflarestorage.com"
bucket: "{{env.R2_BUCKET}}"
path_prefix: "workers-logs/"
path_match_pattern: "^workers-logs/{{env.CLOUDFLARE_R2_TARGET_REGEX}}/.*\\.json$"
access_key_id: "{{env.CLOUDFLARE_R2_ACCESS_KEY_ID}}"
secret_access_key: "{{env.CLOUDFLARE_R2_SECRET_ACCESS_KEY}}"
incremental: true
last_path: "{{env.CLOUDFLARE_R2_LAST_PATH}}"
parser:
type: none
column_name: records
ログは R2 側で「1 ファイル = JSON 配列」の形式で保存しているため、ここでは parser: none とし、いったんファイル全体を 1 カラムとして扱います。
JSON配列を1レコードずつ展開
R2 に保存されているログは以下のように JSON 配列になっています。
[
{ "id": "...", "timestamp": "...", ... },
{ "id": "...", "timestamp": "...", ... },
...
]
JSON配列はembulk 標準の jsonl パーサーは利用できないため、expand_json_array → expand_json の 2 段構成で配列をフラット化します。
filters:
- type: expand_json_array
json_column_name: records
root: "$."
expanded_column_name: body
- type: column
columns:
- { name: body, type: json }
- type: expand_json
json_column_name: body
root: "$."
expanded_columns:
- {name: id, type: string}
- {name: timestamp, type: timestamp, format: "%Y-%m-%dT%H:%M:%S.%LZ"}
- {name: attempts, type: long}
- {name: body.eventTimestamp, type: long}
- {name: body.event.request.url, type: string}
- {name: body.event.request.method, type: string}
# 以下省略(Cloudflare cf.* 系の大量の項目を展開)
Cloudflare Workers のログはネストが深く、特に event.request.headers.* やevent.request.cf.* など多層構造が続くため、expanded_columns で必要なフィールドを明示的に指定しています。
BigQueryが扱えるカラム名に正規化
expand_json の出力は body.event.request.url のように「ドット付きのカラム名」になります。
BigQuery のカラム名としてドットを含む文字列は利用できないため、rename フィルタで lowerCamelCase にマッピングしています。
- type: rename
columns:
body.event.request.url: eventRequestUrl
body.event.request.method: eventRequestMethod
body.event.request.headers.accept: eventRequestHeadersAccept
# ... 以下多数をマッピング
ネスト構造を名称から読み取れるようにしつつ、BigQuery でも扱いやすい命名規則に整えています。
空文字の混入に対処するための型変換
Cloudflare の cf.* 系フィールドには、本来 long 型の値に対して「空文字」が入るケースがあります。
そのまま long 型で受けると embulk が例外を投げるため、一度 string として受け、ruby_proc で安全に変換します。
- type: ruby_proc
columns:
- name: eventRequestCfClientTcpRtt
proc: |
->(value) { value == '' ? nil : value.to_i }
type: long
- name: eventRequestCfAsn
proc: |
->(value) { value == '' ? nil : value.to_i }
type: long
- name: eventResponseStatus
proc: |
->(value) { value == '' ? nil : value.to_i }
type: long
Cloudflare のログの仕様上避けられない問題ですが、この方式で安定して取り込めるようになります。
BigQueryへの転送設定
出力先は BigQuery なのでembulk-output-bigqueryプラグインを使います。
Cloud Run Jobs での実行を前提に application_default 認証を利用し、ログの timestamp をパーティションキーとする日次パーティションテーブルに append します。
out:
type: bigquery
mode: append
auth_method: application_default
location: asia-northeast1
project: "{{env.BQ_PROJECT}}"
dataset: "{{env.BQ_DATASET}}"
table: "{{env.BQ_TABLE}}"
auto_create_dataset: true
auto_create_table: true
default_timezone: "Asia/Tokyo"
time_partitioning:
type: DAY
field: timestamp
exec:
max_threads: 4
⏰️ Cloud Run Jobsによる毎時ETL実行
Cloudflare R2 に蓄積されたログの BigQuery へのロード処理は、
digdag serverではなく Cloud Run Jobs のスケジュール実行で自動化しています。
Cloud Run Jobs は以下の理由から、今回の ETL には非常に相性が良いサービスです。
- 実行タイミングを Cloud Scheduler と組み合わせて柔軟に設定できる
- 実行ごとのコンテナが 完全に分離され、ステートレスで安全
- 認証は Workload Identity Federation + application_default で統一可能
- embulk のような重めの JVM プロセスも安定して動作する
- ランタイム課金のため、頻繁なスケジュールでもコストを最小化できる
Cloud Run Jobsを「毎時」で実行する理由
ETL の実行頻度は1 時間ごとにログを取り込むようにしています。
- 書き換え頻度の高い Workers ログを、分析側(BigQuery)でなるべく早く検索したい
- 完全リアルタイムのストリーミング構成を組むほどではない
- hourly であれば R2 → BQ のレイテンシは実質 1 時間程度
- 1 回あたりの処理量が小さくなり、embulk の安定性が上がる
- Cloud Run Jobs は短時間ジョブのスケジューリングに最適
ログ件数が多いプロジェクトでも hourly ETL は現実的で、「シンプル・低コスト・十分な鮮度」 の三拍子が揃います。
Cloud Run Jobsのジョブ実行イメージ
Cloud Run Jobs の定義では、digdag経由でembulk を実行するためのコンテナをGihHub Actionsでデプロイし、Cloud Schedulerで以下のように毎時実行をトリガーします。
- name: Deploy to Cloud Run Job
run: |
JOB_NAME="${IMAGE_NAME}-${COMPANY_PREFIX}-${{ matrix.subsystem }}"
gcloud run jobs deploy $JOB_NAME \
--region=$REGION \
--image=$REGION-docker.pkg.dev/$PROJECT_ID/$REPOSITORY/$IMAGE_NAME:latest \
--command "./bin/entrypoint.sh" \
--args="company_prefix=${COMPANY_PREFIX},subsystem=${{ matrix.subsystem }}" \
--cpu=4 \
--memory=10Gi \
--add-volume=name=ramdisk,type=in-memory,size-limit=2Gi \
--add-volume-mount=volume=ramdisk,mount-path=/mnt/ramdisk \
--task-timeout=12h \
--max-retries=0 \
--set-env-vars=CLOUDFLARE_ACCOUNT_ID=${{ secrets.CLOUDFLARE_ACCOUNT_ID }},CLOUDFLARE_R2_ACCESS_KEY_ID=${{ secrets.CLOUDFLARE_R2_ACCESS_KEY_ID }},CLOUDFLARE_R2_SECRET_ACCESS_KEY=${{ secrets.CLOUDFLARE_R2_SECRET_ACCESS_KEY }} \
--service-account=r2-to-bq@$PROJECT_ID.iam.gserviceaccount.com
- name: Update Cloud Scheduler Job
run: |
JOB_NAME="${IMAGE_NAME}-${COMPANY_PREFIX}-${{ matrix.subsystem }}"
# 既存のスケジューラージョブを削除(存在しない場合はスキップ)
gcloud scheduler jobs delete $JOB_NAME \
--location=$REGION \
--quiet || echo "Scheduler job $JOB_NAME does not exist, skipping delete"
# 新しいスケジューラージョブを作成
gcloud scheduler jobs create http $JOB_NAME \
--location=$REGION \
--schedule="$CRON_SCHEDULE" \
--time-zone="Asia/Tokyo" \
--uri="https://run.googleapis.com/v2/projects/$PROJECT_ID/locations/$REGION/jobs/$JOB_NAME:run" \
--http-method POST \
--headers="Content-Type=application/json" \
--oauth-service-account-email r2-to-bq@$PROJECT_ID.iam.gserviceaccount.com
なお、ジョブコンテナのエントリーポイント(bin/entrypoint.sh)では、
- 対象日付(または「前回実行時以降」)を環境変数で組み立て
- 実行環境を環境変数から特定
-
java -jar /usr/local/bin/digdag run r2_to_bq.dig --rerunを実行 - digdag実行時に
-pオプションで環境変数をembulkに渡す
という構成にしています。
Cloud Run Jobs は実行ごとにクリーンな環境が立ち上がるため、embulk のような JVM ベースのツールでも環境汚染が起きず、再現性の高いバッチが組めます。
「incremental + last_path」設計との相性
embulk の s3 input プラグインでは、
incremental: true
last_path: "{{env.CLOUDFLARE_R2_LAST_PATH}}"
という設定で、前回読み込んだ最後のオブジェクトパスから再開することができます。
Cloud Run Jobs はステートレスなので、この last_path は Cloud Storageに保存し、ジョブ実行時に環境変数として注入しています。
こうすることで:
- 毎時実行でも 二重取り込みを防止
- R2 の listing 負荷を最小化
- embulk の実行時間が安定する(毎回「増分だけ」処理)
というメリットがあります。
処理フローまとめ
- Cloud Scheduler が Cloud Run Jobs を毎時キックする
- ジョブコンテナが起動し、環境変数から
CLOUDFLARE_R2_TARGET_REGEX/last_pathを組み立て - embulk が R2 から該当範囲の JSON ファイルを読み込む
- JSON 配列 → JSON → カラム展開 → rename → ruby_proc → BigQuery append
- 処理済みの
last_pathをCloud Storageに保存 - ジョブ終了 → 完全にクリーンな環境へ
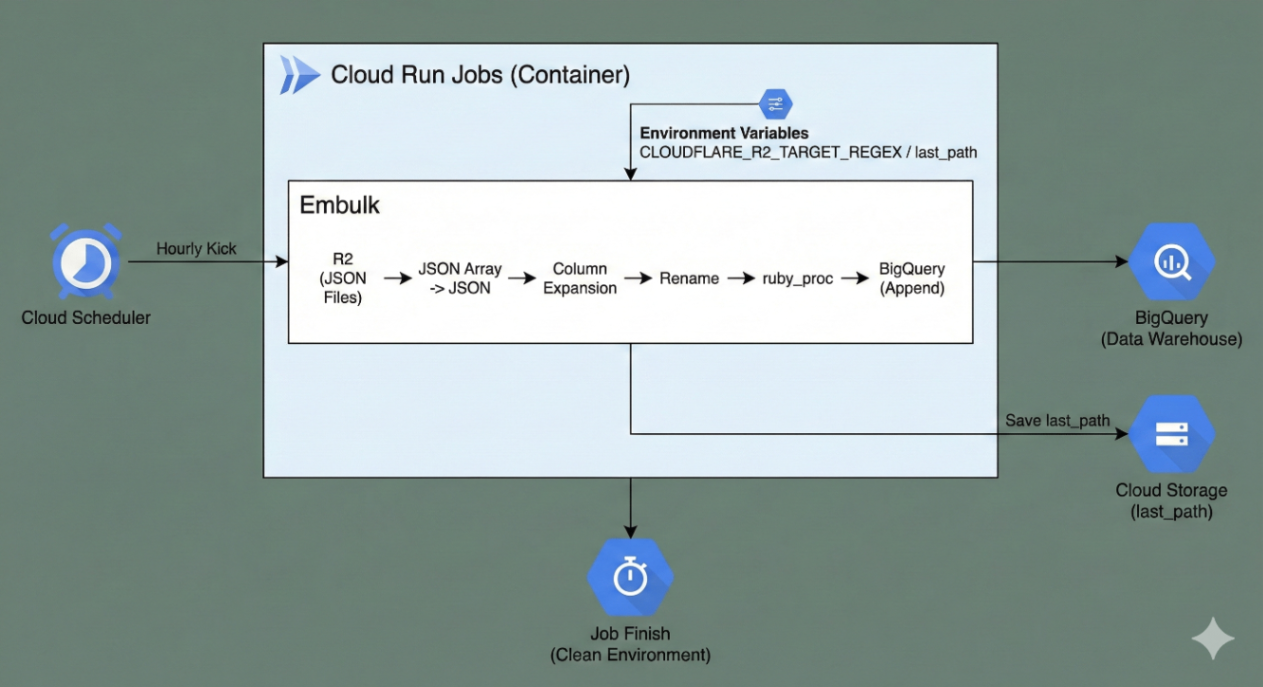
Cloud Run Jobs処理フロー
ETL の信頼性は Cloud Run Jobs によって大幅に向上し、コンテナベースであるため embulk のバージョン固定や依存関係管理も容易です。
Cloud Run JobsによるETLの利点
- 毎時 ETL をノンストップで安定実行できる
- digdag serverのように常時プロセスを維持する必要がない
- スケジューラとジョブ環境を完全に分離できる
- embulk をコンテナ化することで、CI/CD に統合しやすい
- コールドスタートでも実行時間は2〜3分程度で許容範囲
- ステートレスなので「毎回クリーンな ETL」が保証される
- Cloudflare Logs → R2 → BQ のパイプラインが完全にサーバレス化する
💡 運用 Tips:実際に運用してみてわかったこと
Cloudflare Workers のログを Queue → R2 → Cloud Run Jobs → BigQuery という構成で運用していると、実際の挙動や運用コストの見え方、想定外の動きなど、構築段階では気付きにくいポイントがいくつかありました。
ここでは、約半年ほど運用して得られた知見を紹介します。
1ヶ月で蓄積されるR2ログ量の実測値
Cloudflare R2 に保存されるログ量は、1 時間ごとのバッチ処理という構成の割に、比較的多くなりがちです。
実際の直近過去 1 ヶ月運用では、以下のような量になりました。
- R2 Storage Class A Operations:月間 約 430 万回
- R2 Data Storage:月間 約 824 GB
これは、Workers のトラフィック量や JSON 配列形式での保存方式にも影響を受けます。
R2 の階層構造(workers-logs/yyyy/mm/dd/hh/mm/ss-uuid.json)により listing が効率化されている一方、小さな JSON ファイルが大量に作成されるため、Class A Operations が多くなります。
料金自体は次章で触れますが、運用の観点では「R2 のオブジェクト量は想定以上に増えがち」という点だけ覚えておくと良さそうです。
Cloudflare公式サンプル実装の問題点
Workers → Queue の部分は、公式ドキュメントに掲載されている「基本的な enqueue/consume サンプル」から始めました。しかし、運用開始してしばらくしてから Queue が詰まって処理が遅延する現象が断続的に発生しました。
公式では:
await env.<MY_QUEUE>.send(log);
というサンプルコードが記述されています[2]が、この実装だと問題が発生しました。
最終的には「Queue の enqueue を必ず非同期(ctx.waitUntil)」で処理することでこの問題が解消しました。
ctx.waitUntil(
(async () => {
try {
await env.WORKERS_LOGS_QUEUE.send(log);
} catch (error) {
console.error('Failed to send log to queue:', error);
}
})(),
);
Cloudflare Queue は強力な仕組みですが、公式サンプルのままでは実トラフィックに耐えないケースがあるので、注意が必要です。
Cloud Run Jobsエラーと自動リカバリ
Cloud Run Jobs で毎時 ETL を実行していると、まれにジョブがエラー終了することがあります。
- 原因はログ上は JVM の exit / ネットワーク一時的不調 / embulk プラグイン起因など、特定しきれない
- ただし、次の 1 時間後のジョブが正常に動作し、増分 ingest により自動復旧している
- ステートレスな Cloud Run Jobs ×
incremental: trueの組み合わせにより、運用トラブルが結果的に吸収されている
データ処理基盤としては理想的で、単発のジョブ失敗が全体に重大な影響を与えない構成になっています。
とはいえ、定期的に Cloud Run Jobs のエラーログ(Cloud Logging)をモニタリングする運用は欠かせません。
エラーが発生した場合はGoogle Cloud Monitoringを使ってslackチャンネルに通知が行くようにしています。
ログ欠損の可能性
Queue → R2 → Cloud Run Jobs → BigQuery という流れは、全体として堅牢に見えますが、実際に運用してみると、わずかながら ログ欠損の可能性を完全に排除することは難しい と感じています。
理由としては:
- Queue バックプレッシャー時にメッセージの欠落が理論上起こり得る
- R2 書き込み時のネットワークエラーが発生すると、再試行の隙間で抜ける可能性がある
- Cloud Run Jobs の落ち方によっては、極めて短時間帯のログが飛ぶ可能性がある
- Cloudflare Workers のエラー時に Queue に送信されないケースがあり得る
実際のところ、現時点では 「明確な欠損を確認していないが、ゼロとは断言できない」 というのが正直な実感です。
ベストエフォートではなく欠損が許されないケースだとEnterpriseプラン契約してLogpushを使う方が良さそうです。
この構成における運用のポイントまとめ
最後に運用時の注意点を整理すると、以下のようになります。
- R2 のオブジェクト量は増えやすいため、prefix 設計とライフサイクル管理が重要
- Cloudflare Queue は 非同期 enqueue(ctx.waitUntil)必須
- Queue Consumer の負荷が高い場合は、R2 書き込み処理の軽量化が有効
- Cloud Run Jobs の単発エラーは incremental ingest と相性が良く自動回復する
- 完全ロスレスではない可能性はゼロではないため、可観測性の仕組みを併用すると安心
- トラフィック増加時には Queue → R2 → BQ 全体の throughput を再調整する余地がある
💰️ コスト:Enterpriseプラン導入より(恐らく)安価
前述の通り、Cloudflare Workers のログを安全に外部へ転送するには、本来 Logpush(Enterprise プラン限定) を利用する必要があります。
Enterpriseプランの月額コストは公開されていませんが、恐らく最低でも 数千ドル/月のコストがかかるのではないかと推測しています。
今回紹介している「Workers → Queue → R2 → Cloud Run Jobs → BigQuery」の構成では、Enterprise プランへのアップグレードを必要とせず、Pro / Business プランのままログ基盤を構築できます。
実際の直近1 ヶ月(2025/10/17〜2025/11/16)のコストは次の通りです。
Cloudflare Queue
- Queue Operations:153,517,477 ops
- 料金:約 $61.60
Queue はメッセージ単価が非常に安く、Workers のトラフィック量が多くてもコスト増がゆるやかです。
Cloudflare R2
- Class A Operations:4,327,806 ops
- Data Storage:約 824 GB
総量は大きいものの、R2 はストレージ単価が極めて安く、月間の合計も $40–50 程度に収まります。
(Class A + ストレージ合計で 約 $35 〜 $40)
BigQuery / Cloud Run Jobs
- BigQuery の日次(正確には hourly)append は非常に軽量
- Cloud Run Jobs の実行も毎時 1 回の短時間ジョブのみ
これで合計$300/month程度のコストです。
全体のコスト概算
これらコストを合計すると以下の通りです。
| Cloudflare | Google Cloud | 合計 |
|---|---|---|
| $100/month | $300/month | $400/month |
今回の構成でのログ転送基盤のコストはおおよそ:
約 $400 / month 程度
つまり、Enterprise プラン が 数千ドル/月と仮定すると、約 1/4〜1/5 以下のコストで、実質同等のログ取り込みが可能になります。
なお、BQに転送したい場合、Google CloudのコストはEnterpriseプランでもかかるので、除外すると1/10〜1/20以下のコストになります。
Cloudflare Workers を多用している環境でも、大規模な固定費を発生させずにログ基盤を構築できる点が、本構成の最大のメリットです。
📈 まとめと今後の展望
Cloudflare Workers を本番のゲートウェイとして使う以上、「ログをどう外に出すか」は避けて通れません。
- Enterprise 専用の Logpush には手が届かない
- でも、パフォーマンス可視化や障害対応のためにログはちゃんと取りたい
- ついでに、コストもそれなりに抑えたい
という状況に対して、
Workers → Queue → R2 → Cloud Run Jobs(digdag + embulk)→ BigQuery
というパイプラインで「そこそこガチなログ基盤」を、自前で $400/month 前後で構築した、というのが今回の内容でした。
この構成で得られたもの
この構成によって、少なくとも以下は実現できています。
- Enterprise プラン不要で、Workers の全リクエストログを外部に集約できる
- R2 を中心に、ほぼサーバレスなログ ETL が組める
- JSON 配列 + embulk フィルタで、Cloudflare 特有のネスト構造にも対応できる
- Cloud Run Jobs +
incrementalで、毎時バッチでも運用が安定する - Queue / R2 / BQ / Cloud Run Jobs を全部合わせても、コストは約 $400/月 程度
「Workers を本格的に使っているけれど、Enterprise まではまだちょっと…」というチームにとっては、十分実用的な選択肢になると思います。
割り切っているところ
一方で、割り切っているポイントもいくつかあります。
- Queue / R2 / Cloud Run Jobs どこかでの一時的な障害により、
ごく一部のログが欠損する可能性を完全には否定できない - Cloudflare のログ形式(特に cf.* 系)の癖に合わせるために、
embulk の設定(expand / rename / ruby_proc)がそれなりに複雑になっている - 1 時間単位のバッチ処理なので、「秒単位のリアルタイム分析」が必要なユースケースには向かない
「1 行も失いたくない・SLA レベルで保証したい」という要件であれば、やはり素直に Enterprise 契約して Logpush を選ぶ方が健全だと思います。
フィットするチーム
個人的には、次のようなチームにはオススメできる構成だと感じています。
- Cloudflare Workers を CDN + リバースプロキシ として本番運用している
- Pro / Business プランのまま、ログを BigQuery に集約したい
- GCP(Cloud Run / BigQuery)や embulk にある程度慣れている
- 「多少のベストエフォートは許容しつつ、現実的なコスト/運用でやりたい」
逆に、
- ガチガチな監査ログが必要
- 金額よりも「フルマネージド & 責任分界」が最優先
という場合は、Cloudflare Enterprise + Logpush 一択かなと思います😅
今後やると面白そうなこと
このログ基盤の上には、まだいろいろ遊べる余地があります。
- BigQuery のビューを使った API / パス単位のパフォーマンスダッシュボード
- 異常検知クエリ + Cloud Monitoring / Slack 通知での 簡易な SLO/SLA モニタリング
- Looker Studio などを使った 事業側へのレポーティング
- Workers ログとアプリ側のアプリケーションログを組み合わせた トレースっぽい分析
あたりは、今後活用を検討していきたいところです。
もし同じような構成を試してみた方や、「ここ、こうするともっと楽になるよ」というアイデアがあれば、ぜひ Twitter(@tchikuba)などで教えてもらえると嬉しいです。

ポップアップストアや催事イベント向けの商業スペースを簡単に予約できる「SHOPCOUNTER」と商業施設向けリーシングDXシステム「SHOPCOUNTER Enterprise」を運営しています。エンジニア採用強化中ですので、興味ある方はお気軽にご連絡ください! counterworks.co.jp/
Discussion
めちゃ分かりづらいのですが、Workers LogのLogpushはEnterpriseではなくとも実は使えます…!(全体のLogpushとWorkers Logpushはわりと違う製品扱いっぽい感じみたいです)