はじめに
はじめまして、4月からatama plusにデータエンジニアとしてジョインしたTackungです。
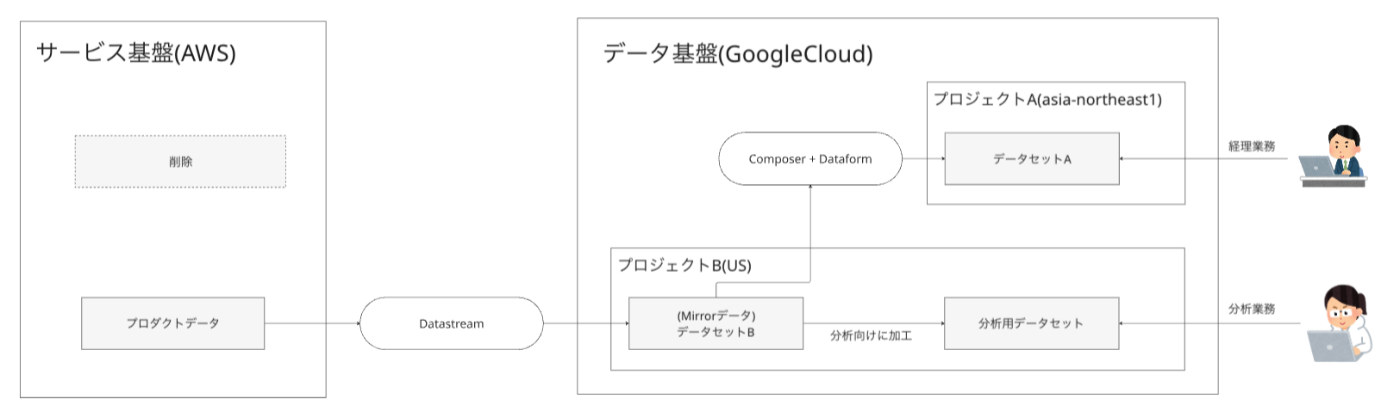
弊社ではデータ基盤にBigQueryを採用しており、プロダクト側で日々発生するデータをTROCCOやGoogle Cloud Dataform、Composerを使った日次転送でデータを蓄積しています。
今回、コスト削減を目的として一部のデータの転送方式をTROCCOからGoogle Cloud Dataform+Composerを使った方式に移行するプロジェクトに取り組みました。この移行によって、不要インスタンスの削除によるコスト削減ができました。
この取り組みの中で、BigQueryのデータセットのリージョンが異なることが原因で予想外の苦労をすることになりました。本記事では、その時ぶつかった壁と我々が取ったアプローチについてご紹介します。
あまり遭遇することのない状況かもしれませんが、同じ壁にぶつかった方への参考となれば幸いです。
今回のまなびの要約
- BigQueryではリージョンが異なるデータセット間のクエリの実行はできない
- これに対して取れる対応:
- (条件あり)当該データセットのレプリカを作成し、プライマリ側を転送用、セカンダリを参照用に使う
- BigQuery Data Transfer Serviceを使って一時的なデータセットにコピー→このデータセットをレプリカ設定しておいてレプリカ側から当該データセットに転送クエリ実行
- Cloud Composer(PythonOperator)を使って一時的なデータセットにコピー→このデータセットをレプリカ設定しておいてレプリカ側から当該データセットに転送クエリ実行
今回の移行の概要
今回の取り組みにて下記のような構成移行を実施しました。
移行前の構成
AWS上にあるADS AuroraインスタンスからTroccoでGoogle Cloud BigQueryのデータセットA(asia-northeast1)に日次転送
- データセットA
- 経理業務で利用しているデータ
- 外部サービス連携での制約があり、USではなくasia-northeast1リージョンにおく必要がある
- 分析業務とは利用目的が異なるため、プロジェクトを分けて作成している
- データセットB
- プロダクトのmirrorデータ
- Datastreamを用いてニアリアルタイムなデータ転送が行われている
- このデータを元に加工を施し分析用のデータセットを作成している

移行後の構成
プロダクトのmirrorデータが入っているデータセットB(US)からComposer+Dataform経由でデータセットAに日次転送
- 目的:データパイプラインのアーキテクチャをシンプルにして運用コストを下げること
- 副次的効果:TROCCOではテーブル転送コードのバージョン管理が困難なため、DataformのGitHub連携を活用したバージョン管理を実現
ぶつかった問題と制約
GoogleCloudのサービス仕様と実際の業務運用の2つの方向からの制約がありました。
ぶつかった問題
転送方式の移行を進める中で、データセット間のリージョンが異なるためDataform上でCOPYクエリが実行できないという壁にぶつかりました。
- 実際に発生したエラーメッセージ:
Not found: Dataset [データセット名] was not found in location asia-northeast1
転送元データセットのリージョンがUSだったため、直接asia-northeast1にあるデータセットAに対してクエリを実行できないことが原因 [1] でした。これを解決するためには参照するデータセットリソースのリージョンを一致させる必要がありました。
スケジューリングクエリも同様の制約を受けます。
なお、旧方式では転送元のDBがGoogle CloudではなくAWS上にあり、BigQuery内でのリージョン差分は関係なかったため、この問題は発生していませんでした。
業務上の制約条件
BigQueryの仕様制約に加えて上述の構成図にも記載している通り、データセットAは経理業務で利用されており以下のような業務上の制約がありました。
- すでに経理業務でデータセットAのテーブル群を利用したスケジューリングクエリおよびGASが稼働しており、この業務への影響を最小限に抑える必要がある
- データセットAは外部システム連携による制約によりリージョン(asia-northeast1)は変更できない
検討したアプローチ
この問題に対応するために大きく2つのアプローチを比較しました。
① 一時的なデータセットにコピーを作成し、レプリカを参照して最終的なデータセットへ転送する方式
Cloud ComposerにおけるDAGワークフローの中で、一時的なデータセット(US)へコピーした上で、このデータセットのレプリカ(asia-northeast1)を使ってasia-northeast1にあるデータセットAに転送するアプローチです。

このアプローチは、柔軟な実装が可能であるというメリットがある一方で、実装がやや複雑となり運用負荷が上がる点、転送が2段階になるためコストが増加する点といったデメリットが挙げられます。
フロー概要:
- step1. US側で転送を実行 (データセットB → 一時データセット)
- Composer上でのDataform実行によって、データセットBから一時的なデータセットへ転送(US側)
- step2. asia-northeast1側で転送を実行 (一時データセット → データセットA)
- データセットB(US側)から転送対象テーブル一覧を取得
- 一時的なデータセットのセカンダリレプリカ(asia-northeast1)からデータセットAにデータを転送
DAGの実装例
以下はこのアプローチでのstep2部分のPythonOperatorを用いたDAG実装例(関連部分のみ抜粋)です。
クエリ実行時のlocationを client.query(query, location="US")のように参照するデータセットと合わせることがポイントです。
PROJECT_ID = "gcp-project-name"
SOURCE_DATASET = "dataset_b" # USリージョン
TARGET_DATASET = "dataset_a" # 東京リージョン
def get_tables_to_transfer(**context):
"""転送対象テーブル一覧を取得するタスク"""
client = bigquery.Client(project=PROJECT_ID)
query = f"""
SELECT table_name, table_type
FROM `{PROJECT_ID}.{SOURCE_DATASET}.INFORMATION_SCHEMA.TABLES`
WHERE table_type = 'BASE TABLE'
ORDER BY table_name
"""
job = client.query(query, location="US") # SOURCE_DATASETと同じリージョンで実行
tables = []
for row in job.result():
table_info = {
'table_name': row.table_name,
'table_type': row.table_type,
}
tables.append(table_info)
print(f"Found table: {row.table_name})")
print(f"Total tables to transfer: {len(tables)}")
# XComにテーブル一覧を保存
context['task_instance'].xcom_push(key='tables_to_transfer', value=tables)
return tables
def transfer_cross_region_tables(**context):
"""USリージョンから東京リージョンへテーブル転送タスク"""
client = bigquery.Client(project=PROJECT_ID)
# 転送対象テーブル一覧を取得
tables = context['task_instance'].xcom_pull(
task_ids='get_tables_to_transfer',
key='tables_to_transfer'
)
successful_transfers = []
failed_transfers = []
for table_info in tables:
table_name = table_info['table_name']
try:
print(f"Transferring table: {table_name}")
# 東京リージョンにテーブル作成
transfer_query = f"""
CREATE OR REPLACE TABLE `{PROJECT_ID}.{TARGET_DATASET}.{table_name}`
AS SELECT * FROM `{PROJECT_ID}.{SOURCE_DATASET}.{table_name}`
"""
job_config = bigquery.QueryJobConfig(
use_legacy_sql=False,
destination=f"{PROJECT_ID}.{TARGET_DATASET}.{table_name}"
)
job = client.query(
transfer_query,
location="asia-northeast1", # TARGET_DATASETと同じリージョンで実行
job_config=job_config
)
job.result() # 完了まで待機
print(f"✓ Successfully transferred: {table_name}")
successful_transfers.append(table_name)
except Exception as e:
print(f"✗ Failed to transfer {table_name}: {e}")
failed_transfers.append({
'table_name': table_name,
'error': str(e)
})
# エラーハンドリング
if failed_transfers:
raise Exception(f"Failed to transfer {len(failed_transfers)} tables")
# 結果をXComに保存(後続タスクで利用)
context['task_instance'].xcom_push(key='transfer_summary', value={
'successful_transfers': successful_transfers,
'failed_transfers': failed_transfers,
'total_count': len(tables)
})
return f"Successfully transferred {len(successful_transfers)} tables"
# DAG定義
...
# task定義
get_tables_to_transfer = PythonOperator(
task_id="get_tables_to_transfer",
python_callable=get_tables_to_transfer,
)
transfer_cross_region_tables = PythonOperator(
task_id="transfer_cross_region_tables",
python_callable=transfer_cross_region_tables,
execution_timeout=timedelta(seconds=3600),
)
# ワークフロー定義
... # Dataformによる一時的なデータセットへの転送のコンパイル&実行など
>> get_tables_to_transfer
>> transfer_cross_region_tables
... # 後続task
PythonOperatorの代わりに、BigQueryCreateDataTransferOperatorを使用して同様のフローを実装することも可能です(検証時に試してみましたが、上記とあまり実装量は変わらなかったため採用に至りませんでした)。
参考:BigQueryCreateDataTransferOperatorについて
② 対象データセット自体のレプリカを使った方式
①の方式のような一時的なデータセットを挟まず、データセットA自体にレプリカ設定を行うアプローチです。

フロー概要
- (初回のみ) レプリケーションの設定
- レプリカの作成:asia-northeast1のデータセットAにUSリージョンのレプリカを作成
- プライマリ/セカンダリの切り替え:
- 変更前:プライマリ(asia-northeast1)、セカンダリ(なし)
- 変更後:プライマリ(US)、セカンダリ(asia-northeast1)
- 日次バッチ処理
- Dataformでプライマリ(US)にデータを転送
- asia-northeast1側へのレプリケーションは自動的に実行
このアプローチは、シンプルで理解しやすく、二重の転送コストが発生しないというメリットがあります。一方で、対象データセットを使った関連業務等で書き込みクエリが存在している場合は、それらが実行できなくなってしまう影響があるというデメリットがありました。
当初は①のような一時データセット経由の方式を検討していましたが、影響調査を進めたところ対象データセットは全て参照用途のクエリで利用されており書き込みが発生することはないことを確認できたため、②の方式で進める判断をしました。
レプリカ設定手順例
下記はデータセットのレプリカ設定手順の一例です。
- レプリカの作成
- BigQuery Studio上でデータセットAを選択
- 「レプリカの作成」をクリック
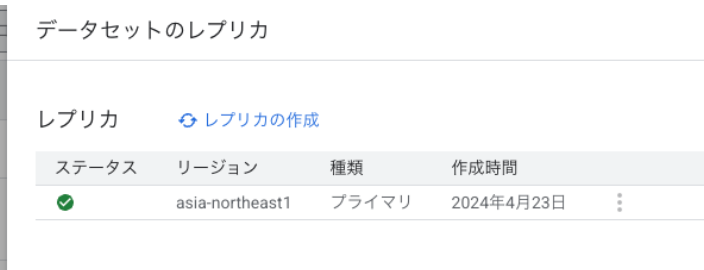
- リージョンを選択して作成

- 自分たちの環境の場合、約1分でレプリカ作成完了しました
- プライマリ/セカンダリの切り替え
- BigQuery Studio上でデータセットAを選択
- 「プライマリにプロモート」からリージョンを選択
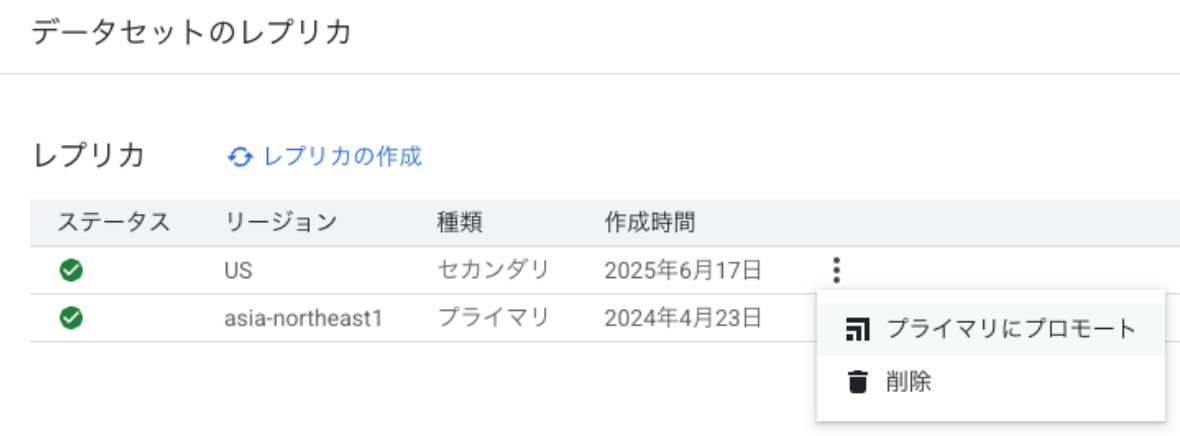
- USをプライマリに、asia-northeast1をセカンダリに変更
- こちらは約3分ほどで切り替え完了しました
まなび
BigQueryのリージョン制約
今回の移行作業を通じて、BigQueryにおけるリージョン制約の重要性を改めて認識できました。
Dataformとスケジューリングクエリの制約
- Dataform:デプロイされたリージョンと異なるリージョンのデータセットに対してクエリを実行できない
- スケジューリングクエリ:Dataformと同様にクエリ実行リージョンと参照データセットのリージョンが一致している必要がある
- これらの制約により、単純なCOPYクエリであってもリージョンをまたいだ処理は直接実行できない
事前調査の重要性
移行計画の初期段階でデータセットのリージョン配置を確認することの重要性を学びました。今回はプロジェクトが進んでから制約に気づいたため、設計の見直しが必要となりました。データ基盤の設計時には、将来の拡張性も考慮してリージョン配置を決定することが重要であることが再認識できました。
対応方法の比較
今回検討した2つの方式それぞれにメリット・デメリットがありました。
① 一時データセット経由方式のメリット・デメリット
メリット
- 既存データセットへの影響が最小限
- 柔軟な実装が可能で、複雑な変換処理にも対応しやすい
- 既存の業務フローに影響を与えない
デメリット
- 実装が複雑になり、運用負荷が増加
- 2段階の転送によりデータ転送コストが増加
- 一時データセットの管理も必要となる
② レプリカ方式のメリット・デメリット
メリット
- シンプルで理解しやすい構成
- BigQueryネイティブの機能を活用するため、運用負荷が低い
- 二重の転送コストが発生しない
- レプリケーションは自動実行される
デメリット
- セカンダリ側では書き込みクエリが実行できない
- 書き込み処理を伴う利用がある場合は影響調査と対応が必要
選択の判断基準
今回は影響調査の結果、幸いにも対象データセットが全て参照用途のみで利用されていることが確認できたため、②のレプリカ方式を採用できました。この判断により、シンプルで運用しやすい構成を実現できました。
書き込みクエリが存在する環境では①のような一時データセット経由方式の検討が必要になります。
おわりに
今回、ご紹介したようなマルチリージョンでの制約に苦しみましたが、BigQueryのレプリカ機能を活用することで既存システムへの影響0で移行を完了できました!この移行によって不要なDBインスタンス撤廃によるコスト削減が実現できました。
さらに、TROCCOからDataformへの移行により、GitHubと連携したコードのバージョン管理も実現でき、開発効率の向上も期待できます。
BigQueryを使ったデータ基盤構築では、データセットのリージョン配置が後々大きな制約となる可能性があります。同じような課題に直面している方の参考になれば幸いです。
-
BigQueryの公式ドキュメントではドキュメント内にはクエリでデータセットのロケーションを指定することで解消するとの記載がありましたが、Dataformからの実行の場合はそれでは解消せず、データセットとクエリ実行リクエストのロケーションを揃える必要がありました。 ↩︎

Discussion