Airflowさわってみた



概要
仕事でAirflowを触る機会があったので、そこで調べたことなどをまとめてみたいと思います。
Airflowとは
Airflowは、処理(タスク)を順に実行したり、監視やスケジューリングができるフレームワークとなっています。
例えば、ETL処理(データの抽出、変換、ロード)を行うことに適しています。

Airflowの用語
Dag
Airflowは一連のジョブ(処理のかたまり)をDagで定義します。
Dagとは、有向非巡回グラフ(Directed Acyclic Graph)のことで、1方向で処理を順に実行していくものになります。ETLでは、ロードは抽出、変換を先に実行しなくてはならないため、抽出→変換→ロードの順で処理を組み、Dagを作成することになります。
Operator
処理(タスク)を定義するテンプレートのようなもの。
様々なOperatorが用意されていて、Bashで処理を実装したい場合はBashOperator、Python処理をしたい場合は、PythonOperatorを使用します。
その他にも、gcsを操作するもの、mysqlを操作するもの、s3を操作するものなど、様々なOperatorが用意されています。
Sensor
Operatorの1種で、特定の事象が発生するまで実行し続けます。例えば、ファイルが配置されたら、処理をするというような時に使用します。
Sensorもgcs,s3など様々なものが用意されています。
Airflowのインストール
Airflowを簡単に動かす場合は、dockerを使用するのがおすすめです。
基本的に、以下のQuickStartに従い実行することで、インストールできます。
簡単にまとめると
- dockerファイル取得
curl -LfO 'https://airflow.apache.org/docs/apache-airflow/2.2.3/docker-compose.yaml'
- Airflowユーザーの設定/ディレクトリ作成
mkdir -p ./dags ./logs ./plugins
echo -e "AIRFLOW_UID=$(id -u)\nAIRFLOW_GID=0" > .env
- データベースの初期化
docker-compose up airflow-init
デフォルトで作成されるアカウントとパスワードは以下。
アカウント:airflow
パスワード:airflow
- 起動
docker-compose up -d
以下にアクセスし、ログイン画面が表示されればインストール完了です。
http://localhost:8080
- ログイン画面
Airflowの操作
Dagの作成
以下のようなDagファイルを作成し、インストール時に作成したdagsフォルダ配下に配置すると、web画面のDAGs画面に表示されます。
from datetime import datetime, timedelta
from airflow import DAG
from airflow.utils.dates import days_ago
from airflow.operators.bash import BashOperator
default_args = {
'owner': 'airflow',
'depends_on_past': False,
'start_date': days_ago(0),
}
with DAG(
'test_dag',
default_args=default_args,
description='Test DAG',
schedule_interval=None,
catchup=False,
) as dag:
t1 = BashOperator(
task_id='print_date',
bash_command='date',
)
t2 = BashOperator(
task_id='sleep',
depends_on_past=False,
bash_command='sleep 5',
retries=3,
)
t1 >> t2
-
default_args
- owner : 実行ユーザ名。
- depends_on_past :
trueは、前のDag実行が失敗した場合、以降のDagは実行されなくなります - start_date : Dagの開始日です。日付指定や何日前といった記載が可能です。
- 他にもパラメータがあるので以下を参考にしてください。
https://airflow.apache.org/docs/apache-airflow/stable/tutorial.html
-
with DAG
- test_dag : Dag名。他のDagと被らない名称を指定。
- schedule_interval : 実行間隔を指定。
timedelta(days=1)のような書き方や、cron形式でも指定可能です。 - catchup :
start_dateから現在までの過去分のDagを実行するかを指定。Falseは実行しないが、過去1回分は必ず実行されてしまいます。
-
t1 , t2 : 各処理(タスク)を実装。この例では、
BashOperatorを使用しBashコマンドを実行しています。t1 >> t2と記載することで、t1、t2順に実行します。
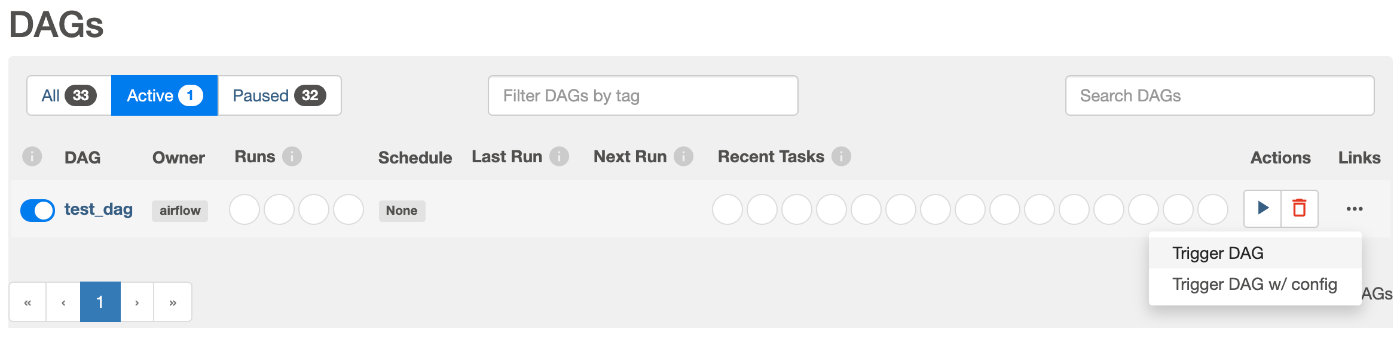
Dagの実行
Dagの実行は、DAGs画面のActionsの▶️を押下します。パラメータを指定する場合は、Trigger DAG w/config、そのまま実行する場合は、Trigger DAGを実行します。
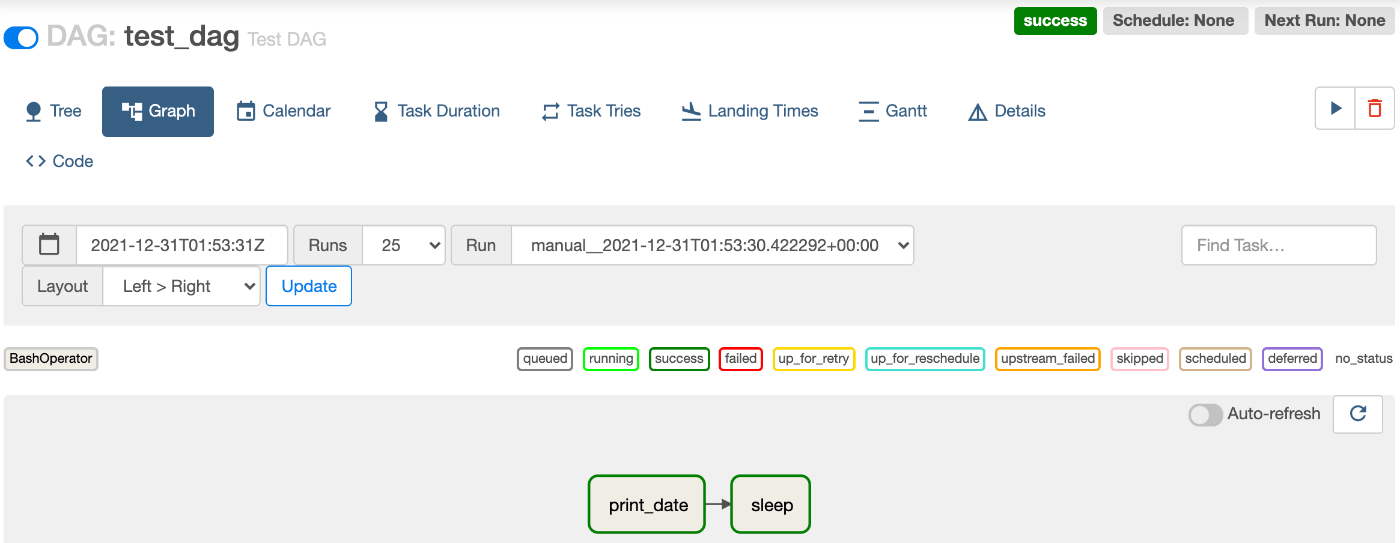
実行すると、処理(タスク)が順に実行されいるのがわかります。
- Tree形式表示

- Graph形式表示
ETL処理で必要そうなもの
ここまでで、簡単なDagの実装方法までまとめてみました。
ここからは、ETL処理で必要となりそうな機能を記載していきます。
Sensor
データの抽出、特にファイル連携をする場合に、ファイルの格納を検知するためにSensorを使用します。
Sensorも接続先毎に様々なものが用意されています。今回は、GCSを例にすると以下のGCSObjectExistenceSensorを使用します。
GCSの指定バケットに指定のファイルが格納されているかチェックします。
gcs_sensor = GCSObjectExistenceSensor(
task_id= 'gcs__sensor',
google_cloud_conn_id = 'gcp_connection',
bucket = 'gcs_bucket',
timeout = 100,
object = 'source.csv',
dag=dag,
)
Connections
GCSに接続するために、Connectionsの設定をします。
AirflowのConnections設定画面で、GCPの接続情報を登録します。
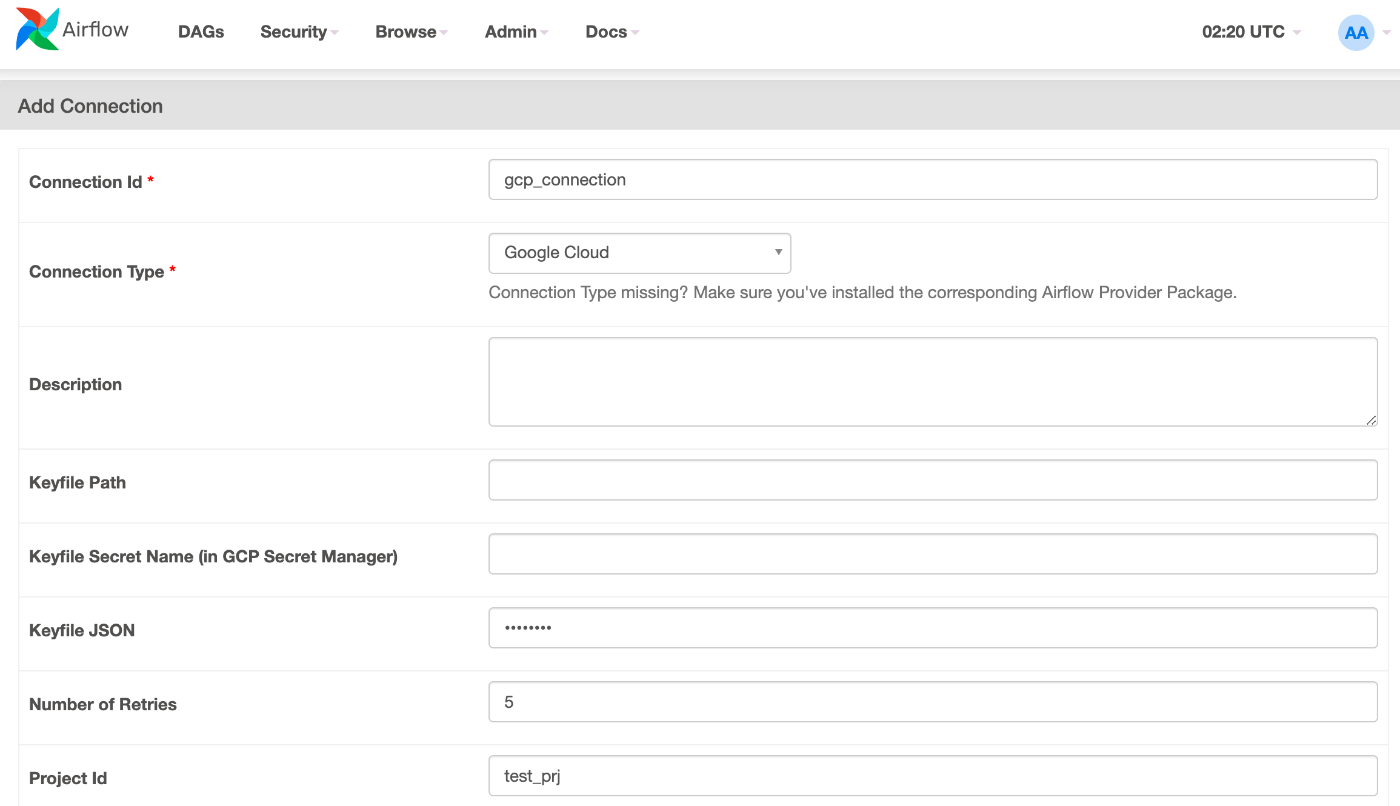
- Connection Id : 接続名を指定します。上記の例では
google_cloud_conn_idで指定しています。 - Connection Type : 接続種別を指定します。GCSの場合は、
Google Cloudを指定します。aws、azureなども用意されています。 - Keyfile JSON : サービスアカウントの認証情報を指定します。
Keyfile PathやKeyfile Secret Name (in GCP Secret Manager)でも可能です。 - Project Id : GCPのプロジェクトIDを指定します。
Transform
ファイルの変換をするためのOperatorも用意されています。
GCSFileTransformOperatorは、GCS上のファイルを読み込み、スクリプトで変換し、GCSにファイル出力してくれます。データ変換のスクリプトだけ実装すればよいです。
CUR_DIR = os.path.abspath(os.path.dirname(__file__))
gcs_transform = GCSFileTransformOperator(
task_id = 'gcs_transform',
gcp_conn_id = 'gcs_connection',
source_bucket = 'gcs_source_bucket',
source_object = 'source.csv',
transform_script=["python", f"{CUR_DIR}/script/transfer.py"],
destination_bucket = 'gcs_dest_bucket',
destination_object= 'dest.csv',
dag=dag,
)
import sys
import pandas as pd
inputfile=sys.argv[1]
outputfile=sys.argv[2]
df = pd.read_csv(inputfile, header=None)
##
## データ変換をごにょごにょ
##
output = df.drop(labels=0, axis=1)
output.to_csv(outputfile,index=False)
引数指定での実行
毎日実行するDagの場合、過去日を指定して実行したいときがあります。その場合は、confパラメータで日付を渡してDagを実行することができます。パラメータは、JSON形式で指定します。

- テンプレートで受け取る場合
各Operatorの引数で、Jinja templateが使用できるところでは{{ dag_run.conf['key'] }}で、confパラメータを受け取ることができます。
BashOperator(
bash_command="echo {{ dag_run.conf['date'] }}",
)
Jinja templateが使用できない引数にconfパラメータを渡したい場合は、カスタムオペレータを作成してtemplate_fieldsにconfパラメータを使用したい変数を設定します。
class CustomGCSFileTransformOperator(GCSFileTransformOperator):
template_fields = ["source_object","destination_object"]
def __init__(self, *args, **kwargs):
super().__init__(
*args,
**kwargs
)
def execute(self, context):
super().execute(context)
- contextで受け取る場合
Operatorの処理内で受け取る場合は、contextから取得することができます。
def get_data(**context):
date=context['dag_run'].conf['date']
PythonOperator(
python_callable=get_data,
)
おわりに
今回は、一旦ここまでとします。
Airflowは、GCPならCloud Composer、AWSならAmazon Managed Workflow for Apache Airflow(MWAA)というマネージドサービスが提供されているため、簡単に利用することができます。
Airflow自体も様々なOperatorが提供されているため、用途に合ったOperatorを組み合わせ簡単にワークフローを実装することができます。
Discussion