



はじめに
Pythonは世界的にも人気のあるプログラミング言語ですが、実行速度については課題があります。Pythonの実行速度を高速化したい、という要求は根強く、これまでにも様々なツールや処理系が開発されています。
この記事ではMITの研究者らが開発したPythonを高速化するツール「Codon」について紹介します。
この記事を3行でまとめると:
- 高性能で簡単に扱えるPythonコンパイラ「Codon」
- Pythonとの互換性がありながら、CやC++に匹敵する高速化を実現
- 実際にPythonコードが100倍速くなることを検証
Codonとは
Codonは高性能なPythonコンパイラです。実行時のオーバーヘッドなしにPythonコードをネイティブなマシンコードにコンパイルし、シングルスレッドで10-100倍以上の高速化が実現できます。Codonの開発はGithub上で行われており、2021年頃から現在まで様々な機能追加が行われています。
基本的な使い方
例えば次のようなPythonコードfib.pyがあるとします。
def fib(n):
# n未満のフィボナッチ数列を全てprintします
a, b = 0, 1
while a < n:
print(a, end=' ')
a, b = b, a+b
print()
fib(1000)
これをcodonコマンドでコンパイル → 実行します。
codon run fib.py
# 0 1 1 2 3 5 8 13 21 34 55 89 144 233 377 610 987
-releaseオプションをつけることで最適化してコンパイルすることができます。このオプションを付けない場合はdebug用にコンパイルされます。
codon run -release fib.py
# 0 1 1 2 3 5 8 13 21 34 55 89 144 233 377 610 987
-exeで実行ファイルを出力することもできます。この場合はfib というファイルが生成されます。
codon run -release -exe fib.py
./fib
# 0 1 1 2 3 5 8 13 21 34 55 89 144 233 377 610 987
このように、基本的にはPythonコードに変更を加えることなくコンパイルして高速化することが可能です。
Codonと他のツールとの比較
Pythonの実行速度を高速化する処理系やライブラリとして、代表的なものを紹介します。
- PyPy は高速化を求めるPythonユーザーから最も人気がある処理系の実装で、CPythonと互換性が高く、トレーシングJIT(Just-in-Time) コンパイルにより高速化を実現しています。高速化の要求が高い競技プログラミングの分野でも人気があるようです。
- Cython は、Pythonのスーパーセットとしての言語仕様で、C言語へトランスコンパイルすることにより高速化を実現します。
- Numba は、JITコンパイルを使用して最適化されたマシンコードを作成する、もう一つの人気のPythonアクセラレーションツールです。LLVMインフラを使用して、実行時にPython関数を最適化されたマシンコードに自動的に変換することで高速化を実現しています。
- CPython (Pythonの最も一般的な処理系) も 3.11で25%程度高速化されており、今後5年で4倍の高速化を目指すCPython高速化計画が開始されています
その他にも多くの高速化の試みがありますが、一般的に実行速度と煩雑さはトレードオフになる傾向があります。例えば実行速度では Cython > Numba > PyPy > CPython となることが普通ですが、(素のPythonから比べると)コード変更における煩雑さは逆の順番になります。
CodonはPythonの記法をできるだけ損なわず、かつネイティブコードと同等の速度を出すことが可能という特徴があります。
環境構築
下記コマンド一発でインストールすることが可能です。
Linux (x86_64) と MacOS (x86_64, arm64) でバイナリが配布されています。
/bin/bash -c "$(curl -fsSL https://exaloop.io/install.sh)"
pyenv + poetry + Codon (Ubuntu20.04) の場合
Pythonの共有ライブラリを使用するケースも多いため、仮想環境で環境をUbuntuで構築する例も紹介します。ここではpyenv + poetry で環境を整える例です。
# pyenvのインストール
git clone git://github.com/yyuu/pyenv.git ~/.pyenv
echo 'export PYENV_ROOT="$HOME/.pyenv"' >> ~/.bashrc
echo 'export PATH="$PYENV_ROOT/bin:$PATH"' >> ~/.bashrc
echo 'eval "$(pyenv init -)"' >> ~/.bashrc
source ~/.bashrc
# Python環境のインストール. 共有ライブラリもインストールします
CONFIGURE_OPTS=--enable-shared pyenv install 3.10.10
# poetryのインストール
curl -sSL https://install.python-poetry.org | python3 -
echo 'export PATH="$HOME/.poetry/bin:$PATH"' >> ~/.bashrc
source ~/.bashrc
# プロジェクト内での設定
cd <your/project/path>
pyenv local 3.10.10
poetry config --local virtualenvs.in-project true
poetry init
# Codonのインストール
/bin/bash -c "$(curl -fsSL https://exaloop.io/install.sh)"
echo 'export PATH="$HOME/.codon/bin:$PATH"' >> ~/.bashrc
# 共有ライブラリを環境変数に設定します
echo 'export CODON_PYTHON=$PYENV_ROOT/versions/3.10.10/lib/libpython3.10.so' >> ~/.bashrc
source ~/.bashrc
Codonの文法
基本的にはPythonと99%同じです。ここではPythonと異なる部分について、代表的な部分を紹介していきます。詳細はCodon公式の言語仕様を参照してください。
データ型
- 整数: Pythonのintは可変長整数ですが、Codonの intは64bit符号付き整数です
- 一方、
UInt[128](99)のように書くことで任意幅の整数を指定することができます。
- 一方、
- 辞書: Pythonの辞書型は3.6以降は順序が保持されますが、Codonでは保持されません
型チェック
Codonは強い型付け言語として振る舞うため、オブジェクトに異なる型の値を代入することができません。例えば、次のコードはPythonでは動作しますが、Codonではコンパイルエラーになります。
a = 123
a = "string" # Compile Error!
l = [1, "string"] # Compile Error! 異なる型をリストで混在させることはできません
t = (1, "string") # タプルはOK
lt = list(t) # Compile Error! リストへの変換はできません
d = {1: "one"}
d[2] = 2 # Compile Error!
lp = [1, 2.1, 3] # Compile Error! floatは自動的にintにキャストされません
逆にこの性質を利用して、Pythonコードを静的型付き言語として取り扱うことが可能になります。
制御構文
Pythonでは3.10以降でmatchが導入されていますが、拡張されてRust風のmatchステートメントがサポートされており、より簡潔に記述できるようです。
match a + some_heavy_expr():
case 1:
print('hi')
case 2 ... 10: # 2, 3, 4, 5, 6, 7, 8, 9, 10 に一致するか
print('wow!')
case _:
print('meh...')
関数
Pythonでは型アノテーションという仕組みがありますが、実際には宣言と異なる型を代入しても問題なく実行できてしまいます。一方、Codonは静的型付け言語として振る舞うので、型アノテーションで定義した関数の引数や戻り値を厳密に制限することができます。
def fn(a: int, b: float) -> float:
return a + b # int型には__add__(float)が実装されているのでこれはOK
fn(1, 2.2) # 3.2
fn(1.1, 2) # Compile Error!
クラス
CodonはPythonと同様のクラスをサポートしていますが、各クラスの先頭にクラスメンバーとその型を宣言する必要があります。(これはPythonのdataclassと似ています)
class Foo:
x: int
y: int
def __init__(self, x: int, y: int):
self.x, self.y = x, y
def method(self):
print(self.x, self.y)
f = Foo(1, 2)
f.method() # (1, 2)
C、Pythonとの統合
CodonはCや(Codonでコンパイルされていない)他のPythonモジュールから関数をシームレスに呼び出すことができます。
from C import pow(float, float) -> float
pow(2.0, 2.0) # 4.0
C extensionで実装されたPythonライブラリをimportすることで呼び出すことが可能です。これはCODON_PYTHONの環境変数をPython共有ライブラリ(.so)に設定することで動作します。
from python import numpy as np
a = np.array([1, 2, 3]) # numpyを含む部分はCodonによるコンパイルはされず、Pythonの共有ライブラリから動的に呼び出されます
print(a) # [1 2 3]
また、デコレータ@python を指定することで、明示的にPythonで実行させることができます。この場合もPythonの共有ライブラリが必要になります。逆に、既存のPythonコードにCodonを外部ライブラリとしてインポートし、 部分的に@codon.jitでJITコンパイルをさせることも可能です。
@python
def arange_list(n: int) -> list[int]:
# この関数はコンパイルされず、Pythonで実行されます
from numpy import arange
return list(arange(n))
print(arange_list(3)) # [0, 1, 2]
Codonの開発者たちは現在numpyのCodon実装に取り組んでおり、将来的にnumpyを含むコードもコンパイル可能になる見込みとのことです。
並列処理・GPUプログラミング
CodonはOpenMPによる並列処理とマルチスレッドをサポートしています。また、CodonはGILによる制限を受けません。
@par
for i in range(10):
import threading as thr
print('hello from thread', thr.get_ident())
# hello from thread 5
# hello from thread 1
# ...
@parは、以下のようないくつかのOpenMPパラメータをサポートしています。
-
num_threads(int): ループ実行時に使用するスレッド数. -
schedule(str):静的、動的、ガイド付き、自動、ランタイムのいずれか -
chunk_size(int): ループの反復を分割する際のチャンクサイズ。 -
ordered(bool): ループの反復を同じ順序で実行するかどうか。 -
collapse(int): 1つの反復空間に畳み込むループネストの数
Codonは、NvidiaのネイティブGPUバックエンドによるGPUプログラミングをサポートしています。@gpu.kernelによりGPUを直接呼び出すことが可能です。
import gpu
@gpu.kernel
def hello(a, b, c):
i = gpu.thread.x
c[i] = a[i] + b[i]
a = [i for i in range(16)]
b = [2*i for i in range(16)]
c = [0 for _ in range(16)]
hello(a, b, c, grid=1, block=16)
print(c)
# [0, 3, 6, 9, 12, 15, 18, 21, 24, 27, 30, 33, 36, 39, 42, 45]
Codonの速度検証
では実際にCodonがどのくらい高速化されるかを見ていきたいと思います。
ここでは簡単な例としてアッカーマン関数を計算させてみます。
アッカーマン関数
アッカーマン関数は急増加関数の一種で、計算量解析などの分野で用いられます。例えばUnion Findのならし計算量は、アッカーマン関数の逆関数になることが知られています。
def ackermann(m: int, n: int) -> int:
if m == 0:
return n + 1
elif n == 0:
return ackermann(m - 1, 1)
else:
return ackermann(m - 1, ackermann(m, n - 1))
シンプルな実装ですが、再帰的に計算されることにより爆発的に増大する特徴があります。
m=3のとき、2^(n+3) - 3、m=4のとき、2↑↑(n+3) - 3となることが知られています。(2↑↑kはクヌースの矢印表記で、2^(2^(2^…2)とべき乗がk回繰り返されることを意味します)
実際に計算させると、例えばackermann(3, 11) = 16381になりますが、その過程では7x10^8回以上もの再帰呼び出しが発生します。これは高速なプログラミング言語でも数百ミリ秒かかる計算量です。
Pythonによる実装
アッカーマン関数を (m=3, n=11)で計算させ、その時間を計測します。
処理系にもよりますが、Pythonはデフォルトでは再帰呼び出しの上限回数が1000回となっているので、 sys.setrecursionlimit()で解放しておきます。なお、PyPyでの実装もほぼ同様になります。
import sys
import time
# 再帰回数の上限を開放しておきます.
sys.setrecursionlimit(200000000)
def ackermann(m: int, n: int) -> int:
if m == 0:
return n + 1
elif n == 0:
return ackermann(m - 1, 1)
else:
return ackermann(m - 1, ackermann(m, n - 1))
m = 3
n = 11
t0 = time.time()
result = ackermann(m, n)
t1 = time.time()
print(f"ackermann({m}, {n}) = {result}")
print(f"elapsed time: {int((t1 - t0) * 1000)} [ms]")
Numba による実装
Numbaはimportして@jitデコレータをつけるだけなのでかなり簡単に導入することができます。
import time
from numba import jit
@jit
def ackermann(m: int, n: int) -> int:
if m == 0:
return n + 1
elif n == 0:
return ackermann(m - 1, 1)
else:
return ackermann(m - 1, ackermann(m, n - 1))
m = 3
n = 11
t0 = time.time()
result = ackermann(m, n)
t1 = time.time()
print(f"ackermann({m}, {n}) = {result}")
print(f"elapsed time: {int((t1 - t0) * 1000)} [ms]")
Codon による実装
Python実装と同じですが、再帰回数を気にする必要がない分むしろシンプルになっています。
import time
def ackermann(m: int, n: int) -> int:
if m == 0:
return n + 1
elif n == 0:
return ackermann(m - 1, 1)
else:
return ackermann(m - 1, ackermann(m, n - 1))
m = 3
n = 11
t0 = time.time()
result = ackermann(m, n)
t1 = time.time()
print(f"ackermann({m}, {n}) = {result}")
print(f"elapsed time: {int((t1 - t0) * 1000)} [ms]")
C++ による実装
最後にC++でも比較します。-O2 最適化オプションを付けてコンパイルします。
#include <stdio.h>
#include <chrono>
int ackermann(int m, int n) {
if (m == 0) {
return n + 1;
} else if (n == 0) {
return ackermann(m - 1, 1);
} else {
return ackermann(m - 1, ackermann(m, n - 1));
}
}
int main() {
int m = 3;
int n = 11;
auto t0 = std::chrono::high_resolution_clock::now();
int result = ackermann(m, n);
auto t1 = std::chrono::high_resolution_clock::now();
auto duration = std::chrono::duration_cast<std::chrono::milliseconds>(t1 - t0);
printf("ackermann(%d, %d) = %d\n", m, n, result);
printf("elapsed time: %d [ms]\n", int(duration.count()));
return 0;
}
g++ -O2 ackermann.cpp -o ackermann
実行結果
実行時間は次の通りになりました。
| 処理系 | 実行時間 [ms] |
|---|---|
| CPython | 25290 |
| PyPy | 7308 |
| Numba | 1988 |
| Codon | 266 |
| C++ | 255 |
通常のPythonでは25秒かかったのに対し、PyPyでは7.3秒となりました。Numbaでは2秒と10倍以上の高速化です。一方、Codonはさらに速く、266ミリ秒と元のPythonより100倍程度高速化されており、C++の-O2最適化と同等の速度が出ていることがわかります。
なぜCodonはこれほど高速なのか
基本的には、CodonがPythonコードをうまく事前コンパイルできていることによります。予めLLVMを用いて静的型付き言語としてコンパイルされるため、CやC++と同様のネイティブコードによるパフォーマンスが期待されます。
より詳細にはCodonの論文を参照してください。

また、この記事で紹介した以外の事例でも各種ベンチマークが公開されています。多くの環境、タスクでPythonより数十倍~100倍程度の高速化がなされています。
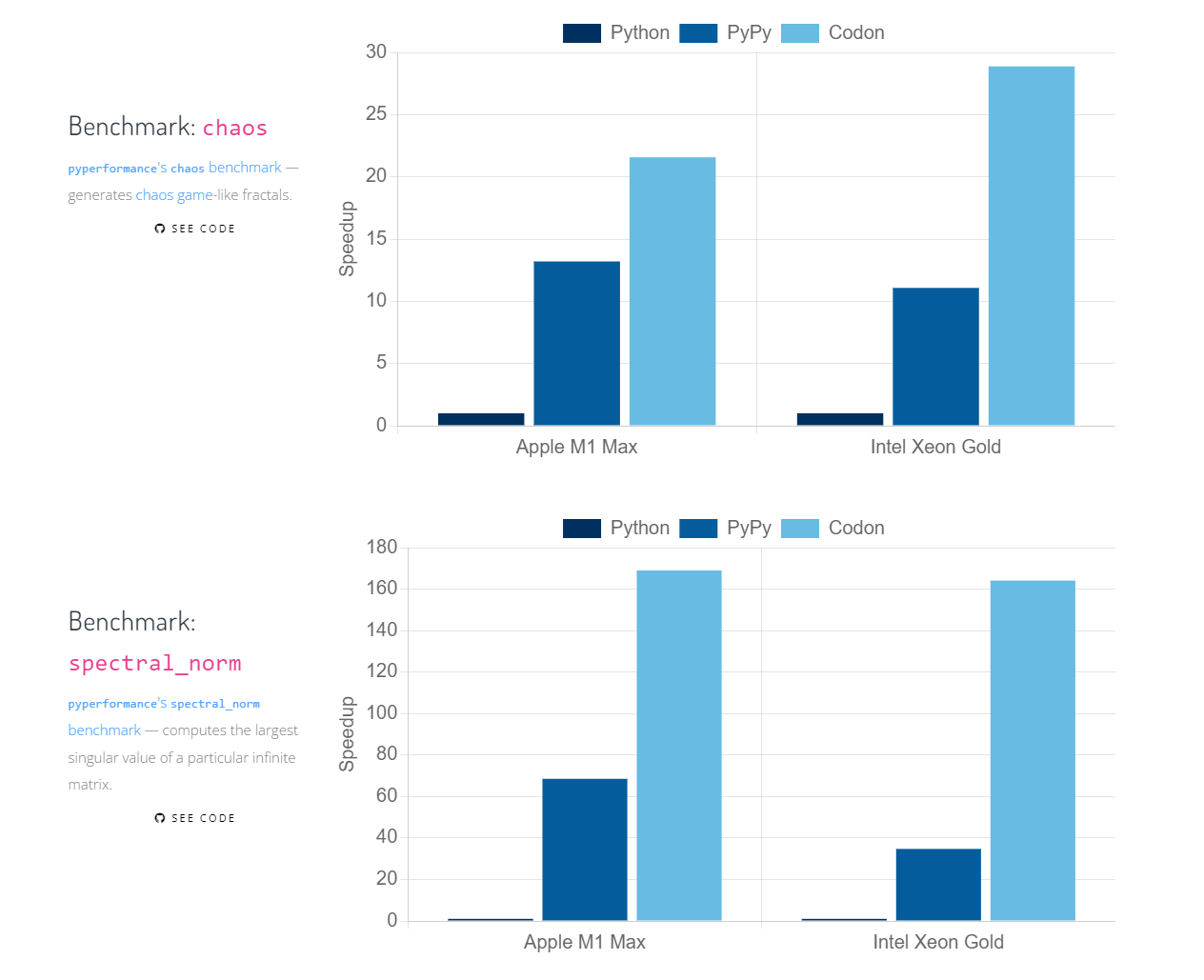
Codonの将来性
試してみて感じたのは、Pythonとの互換性が保たれているにも関わらず、CやC++と同等の高速化ができており、しかも利便性が高いことです。
また、副作用としてPythonとは異なり、静的型付き言語としての挙動を持っています。そのため、うまく使えば(Typescriptのように)Python的な記法でありながら型安全なコードを実装することが可能になるかもしれません。
一方、外部ライブラリ(例えばnumpyやpandasなど)を利用する場合は型の関係上、Codonでは外部ライブラリを含めたままコンパイルすることができません。Pythonコードとして明示的に分離する必要があり、その点はさらに簡単になるとよいなと感じました。このあたりは今も開発が進められているようです。
注意点として、CodonのライセンスはBusiness Source Licenseであり、非商用であれば自由に使用することが可能です。また、2025年11月以降であればApache License 2.0に移行するため、企業での利用シーンも増えていくかもしれません。
まとめ
この記事では、Pythonの高速化ツールであるCodonについて紹介しました。Codonは静的型付け言語として事前コンパイルされるため、Pythonとの互換性がありながら、C++に匹敵する高速化を実現しています。また、並列処理やGPUプログラミングもサポートしており、今後が非常に楽しみなツールです。
最後に、筆者の所属するTuring株式会社では、自動運転を実現するための技術開発を行っており、このような高速で安全なシステムを実装する技術についても着目しています。Turingは完全自動運転EVの開発を目指すスタートアップで、機械学習から3Dアプリケーション、車体の制作に至るまで、ソフトウェア・ハードウェアを横断的なエンジニアリングに取り組んでいます。
もし興味のある方は私のTwitterのDMにてご連絡いただくか、採用ページで「スカウトを待つ」にぜひ登録をお願いします。

Discussion