Webブラウザのレンダリングの仕組みを理解する





どうもフロントエンドエンジニアのoreoです。
今回はWebブラウザのレンダリングの仕組みについてまとめたいと思います。あまり意識していなくても開発はできますが、知っていればパフォーマンスの改善やAccessibilityの向上に役立ちそうですね。
1 レンダリングとは?
普段私たちは、WebブラウザにURLを指定することで、そのリソースをブラウザ画面に表示できます。この時の 「指定したリソースをブラウザ画面に表示すること」を「レンダリング」と言います。
Webブラウザは、下記のように多くの機能を搭載していますが、この中でRendering engineが、レンダリングを実行します。
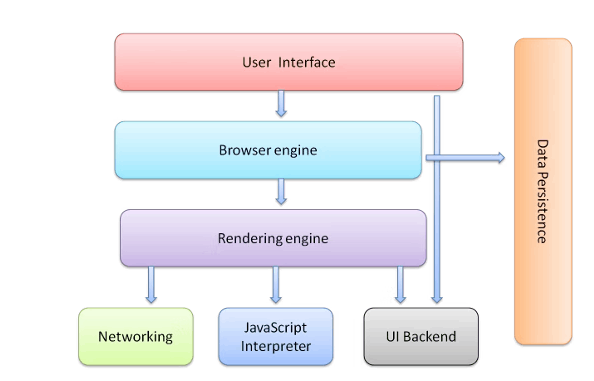
参考:https://web.dev/howbrowserswork/
ちなみに、ブラウザごとのRendering engineは下記になります。
| Rendering engine | Browser |
|---|---|
| Webkit | Safariなど |
| Blink | Google Chrome、Microsoft Edge、Operaなど |
| Gecko | Firefoxなど |
参考:https://ja.wikipedia.org/wiki/HTMLレンダリングエンジン
2 レンダリングの仕組み
レンダリングの大きな流れは下記のようになります。Webブラウザは、サーバーなどからHTML等のリソースを受け取り①〜⑥の処理を経て、レンダリングを実行します。それでは各処理の概要を見ていきます。
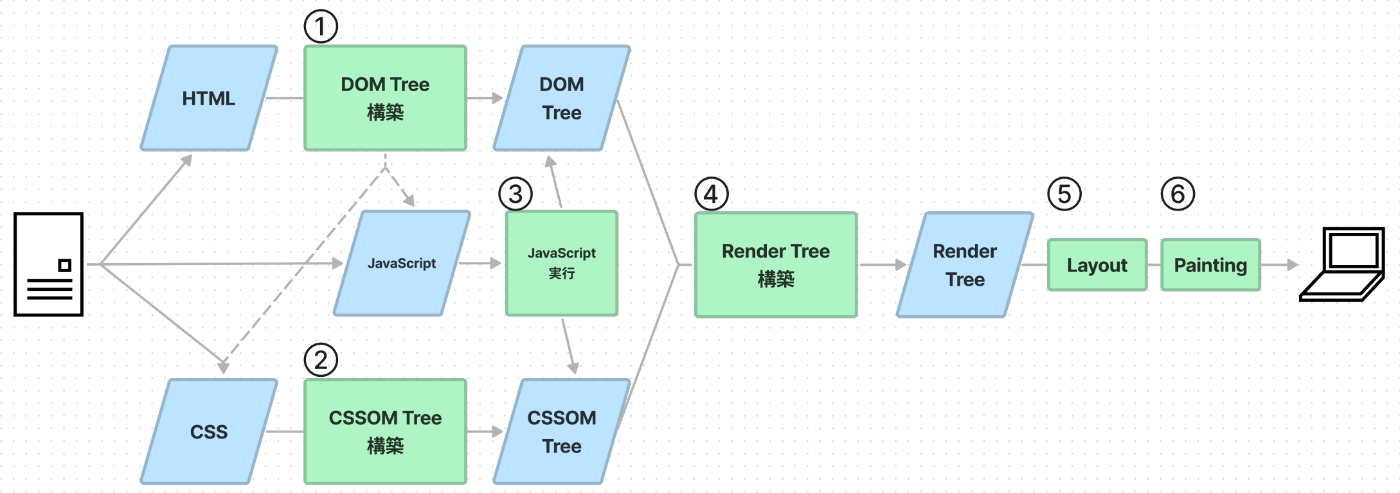
※点線は、HTML内にCSSやJavaScriptの記載があった場合に、HTML内からリソースを取得する流れです。
2-1 ①DOM Tree構築
DOMとは、Document Object Modelの略で、 HTML(またXML)をツリー状のデータ構造として、JavaScriptなど外部プログラムから操作する方法を定義したインターフェイス(API) になります。
DOMはツリー状のデータ構造をしているため、DOM Treeとも呼ばれます。DOM Tree構築までの全体像は下記のようになります。
Rendering engineは、HTMLのバイトデータを受け取り、加工をくり返してDOMを作成します。このDOMへの変換作業のことをParse(解析)と言います。
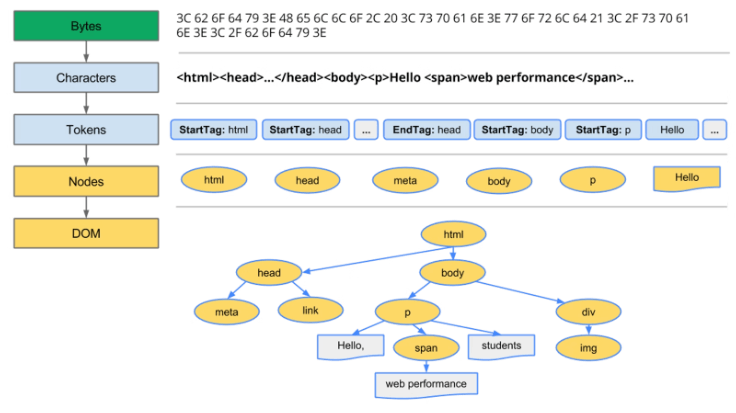
参考:https://web.dev/critical-rendering-path-constructing-the-object-model/
このParseについて、それぞれの過程を順番に見ていきたいと思います。
Conversion(Bytes→Charactersに変換)

ここでは、取得したバイトデータをResponse HeadersのContent-Typeに指定されている文字コード(UTF-8など)に基づいて、文字列に変換します。
Content-Typeに、文字コードが指定されていない場合は、HTMLのmetaタグのcharset属性に指定されている文字コードが適用されます。Content-Typeとmetaタグの両方に文字コードが指定されている場合は、Content-Typeが優先され、両方で指定されていない場合は、バイトデータから推測して文字コードが自動判定されます。
Tokenizing(Characters→Tokensに変換)

ここでは、文字列を一文字ずつ読み込み、<と>で囲まれているものはStartTag(開始タグ)、</と>で囲まれているものはEndTag(終了タグ)、<!--と-->で囲まれているものはComment(コメント)などと言ったようにの W3C HTML5 standardで規定されている規則に基づいて、文字列をトークンと呼ばれる塊に分けて意味を与えます。
Lexing(Tokens→Nodes)

ここで、各トークンはNodeと呼ばれるオブジェクトに変換されます。Nodeは、Document、Elementなど大きく12種類存在し、Nodeインターフェイス(機能の設計図)に基づいたプロパティやメソッドを持ちます。
参考:Nodeについて
参考:Nodeの種類
DOM construction(Nodes→DOM)
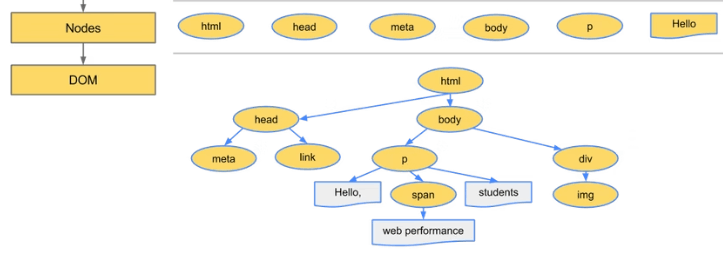
HTMLデータに基づいて作成された各Nodeは、親子関係を持っているので、それらを元にツリー状のデータであるDOM (DOM Tree)を構築します。
上記例ではbodyオブジェクトは、htmlオブジェクトの子で、pオブジェクトの親と言ったような関係を持っています。
2-2 ②CSSOM Tree構築
CSSOM construction
Webブラウザが、DOM Treeを構築しているときに、CSSファイルへの参照(またCSSの記述)があると、CSSデータをCSSOMに変換します。CSSOMは、CSS Object Modelの略で、DOM Treeと同じようにツリー状のデータ構造を取ります。その為、CSSOM Treeとも呼ばれます。
CSSデータからCSSOM Treeへの変換は、下記のような流れで処理され、DOM Treeの際に説明したものとほぼ同じ流れとなっています。

また、CSSOMは下記のようにツリー状のデータ構造を取ります。
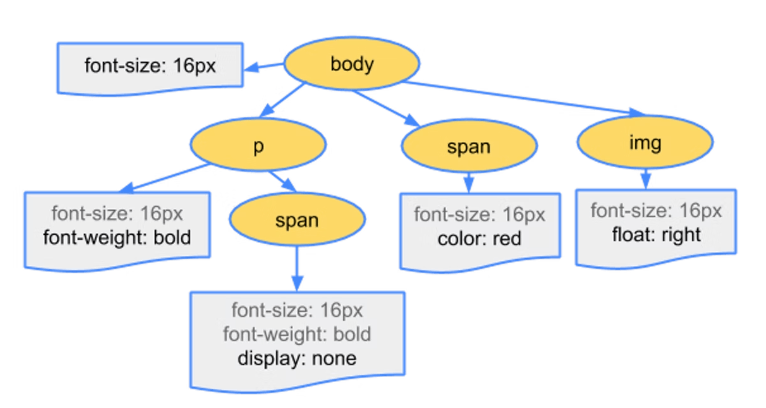
参考:https://web.dev/critical-rendering-path-constructing-the-object-model/
CSSOM Treeでは、cascade down(カスケードダウン)と呼ばれるルールが適用されます。cascade downでは、親ノードの設定を子ノードが継承し、子ノードで親ノードと同じ設定があると上書きされます。例えば、上記のCSSOM Treeでは、bodyオブジェクトは、font-size: 16pxという設定を持ち、その子であるpオブジェクトはfont-size: 16pxを継承します。
user agent stylesheet
各Webブラウザでは、user agent stylesheetと呼ばれるデフォルトのスタイルを提供しています。作成したCSSは、このuser agent stylesheetを継承する形になります。
2-3 ③JavaScriptの実行
JavaScript Execution
Webブラウザが、DOM Treeを構築しているときに、JavaScriptの参照(またJavaScriptの記述)があると、DOM Tree構築が中断され、JavaScriptコードに則って、DOMやCSSOMに変更処理が加えられます。変更処理が終了すると、DOM Tree構築が再開されます。
Parser blocking
このようにDOM Tree構築を中断させる処理のことをParser blockingと呼びます。
2-4 ④Render Tree構築
Render Tree construction
DOM TreeとCSSOM Treeが作成された後に、それらを結合してRender Treeが作成されます。Render Treeは、ブラウザ画面に表示されるNodeだけで構築されます。
例えば、下記例では、CSSOMでdisplay: noneが設定されているspanオブジェクトや、ブラウザ画面に表示されないheadオブジェクトなどは、Render Treeから除外されます。

参考:https://web.dev/critical-rendering-path-render-tree-construction/
Render blocking
DOM Treeの構築とCSSOM Treeの構築は並行して行われますが、Render Treeはそれら二つの構築が終わった後に開始されます。その為、CSSファイルが大きくCSSOM Treeの構築に時間がかかる場合は、Render Treeの構築に時間がかかります。このようにレンダリングが遅れることをRender blockingと呼びます。
参考:Render blocking
2-5 ⑤Layout
Render Treeの構築後に、各Nodeのviewport上でのサイズと位置を算出します。
例えば、下記では、bodyタグ配下のdivタグでは、表示サイズをviewportの50%とし、さらにその配下のdivタグでは、表示サイズをviewportの25%(=0.5 × 0.5 × 100)とします。
<!DOCTYPE html>
<html>
<head>
<meta name="viewport" content="width=device-width,initial-scale=1" />
<title>Critial Path: Hello world!</title>
</head>
<body>
<div style="width: 50%">
<div style="width: 50%">Hello world!</div>
</div>
</body>
</html>
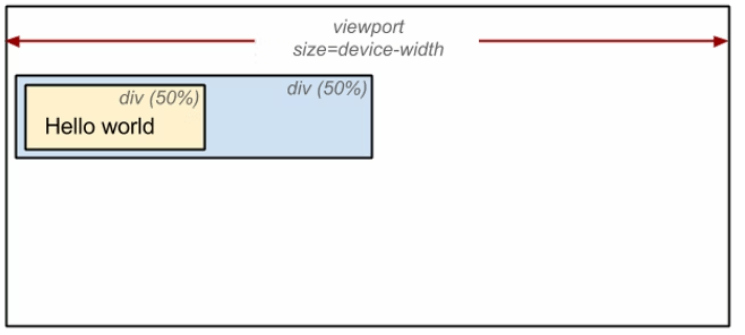
参考:https://web.dev/critical-rendering-path-render-tree-construction/
viewportに関しては、下記Qiitaにまとまっていました。
2-6 ⑥painting(rasterizing)
Layout後に、Render Treeを画面上のピクセルに変換しブラウザ画面に結果が描画されレンダリンが終了します。HTMLが大きい場合やCSSが複雑になるとこの変換には時間がかかります。
2-7 おまけ Accessibility Tree
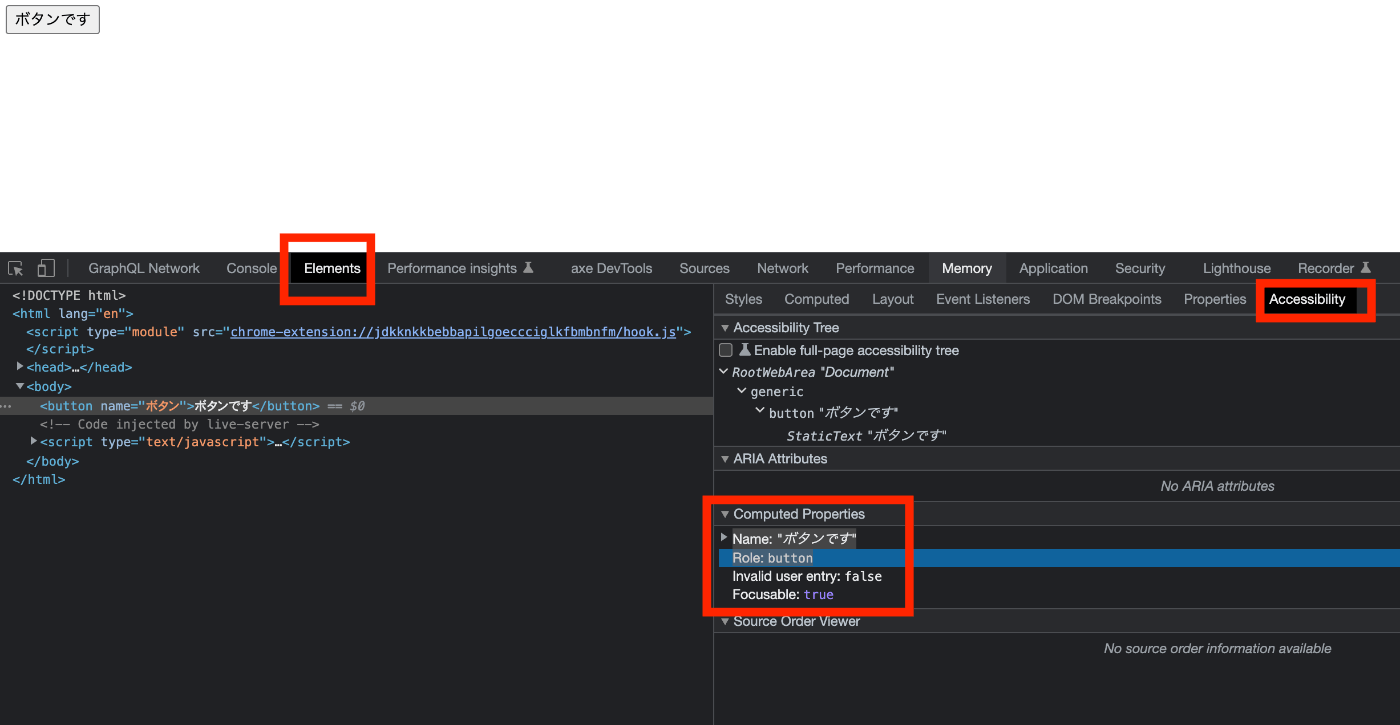
Webブラウザでは、レンダリングの際に、DOM Treeに基づいてAccessibility Treeが生成されます。スクリーンリーダーなどの支援技術は、このAccessibility Treeを介して情報を取得することができます。Accessibility Treeオブジェクトには、role(リンク、ボタンなどの要素の役割)、name(要素の名前)といったプロパティを持ちます。
chromeのDevToolsでは、Elements > Accessibility > Computed Propertiesで、各要素のAccessibility Treeオブジェクトのプロパティを確認出来ます。下記例では、roleプロパティがbutton、nameプロパティがボタンですという値を持っています。
3 最後に
Rendering engineの処理について、それぞれ単語は聞いたことはありましたが、頭の中で体系的に整理することができました。Parser blockingやRender blockingを意識することで、パフォーマンスの改善が出来そうですね。また、Accessibilityの観点では、Accessibility Treeを意識した開発をしたいと思います。JavaScript engineなど、さらに深掘りしたいtopicがたくさんありました。また、DOMなどのtopicに派生して、仮想DOMについても整理していきたいと思います。
4 参考
Discussion
理解しやすい解説ありがとうございます!!
ありがとうございます!そう言っていただけると嬉しいです!!
知りたかったことがとても分かりやすくまとまっていて、とても助かりました!
素晴らしい記事ありがとうございます!
ありがとうございます!