Next'24の帰りのフライトに乗り遅れた時間でGKEのコンテナネイティブのロードバランシングを理解する



はじめに
こんにちは。クラウドエースの間瀬です。
先日、ラスベガスで開催された Google Cloud Next'24 に参加したあと、帰りのフライトに乗り遅れてしまいその空き時間で検証した内容について記事に残します。
みなさん、飛行機に乗る際には早めに搭乗口に向かうようにしましょう。そして、怪しいと思ったら必ず受付の人なりに聞いて搭乗案内中じゃないか確認しましょう。
私は出発前に搭乗口に着いたのですが、搭乗案内中にも関わらず案内が遅れているのかと勘違いしてしまったことによって乗り遅れました。
今回は Google Kubernetes Engine(以下、GKE) において、クラスタ外に Pod を公開する際に利用することが推奨されている「コンテナネイティブなロードバランシング」の仕組みについて理解していきたいと思います。
また、本機能において特に分かりづらい Pod の状態管理の仕組みにフォーカスを当てて解説したいと思います。
クラスタ外からのアクセスにおいて、ロードバランサから直接 Pod へルーティングすることができる機能
これは公式docにも書かれていますが、ロードバランサから Pod へのルーティングを効率的に行うことができる機能です。
本機能の提供前は GKE のロードバランシングでは、ロードバランサ → GCEインスタンス → Pod と 2 回ロードバランシングをする必要があり、ホップ数が多くなることから非効率でした。
(やや記憶が怪しいですが、Pod を NodePort で公開して、ロードバランサから GCE のインスタンスグループをバックエンドとする必要があったはず。)
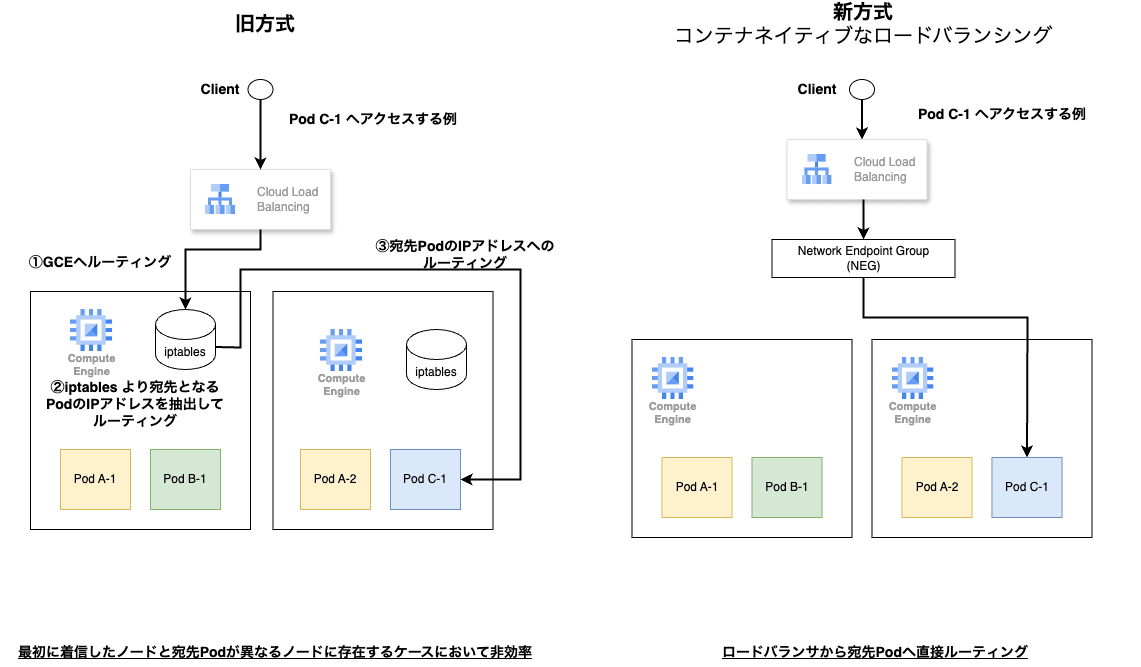
上図の通り、コンテナネイティブのロードバランシングでは、ロードバランサの宛先となるリソース「Network Endpoint Group(以下、NEG) 」に Pod の IP アドレスを紐づけて管理することで直接的なルーティングを実現しています。
NEG はロードバランサの宛先とすることができるエンドポイントのグループ
NEG は Google Cloud 独自のものなので分かりづらいのですが、見出しの通りロードバランサからルーティングする際の宛先のグループと理解しましょう。
実際には、バックエンドサービスというさらに別のグループに複数の NEG を紐づけることができ、ロードバランサからはバックエンドサービスを宛先として指定することでルーティングが行われます。

GKEの場合、リージョン内のゾーン毎に NEG が作られます。これらのリソースは基本的には個別に作成する必要はなく、Service や Ingress, Gateway API といったリソースを使って Pod をクラスタ外に公開することで自動的に作成されます。
細かいですが、スタンドアロンゾーンNEG によって Pod を公開する際にはロードバランサ、バックエンドサービスを個別に構築する必要があるので注意してください。
Kubernetes における Pod の状態管理方法
一般的な Pod の状態管理は Kubernetes(以下、k8s) が提供する Readiness Probe や Liveness Probe によって行います。これらはいわゆる Pod 内のコンテナのヘルスチェックの方法を定義するものです。
また、Readiness Gates という Readiness Probe による Pod の状態管理を拡張する機能も用意されています。
- Liveness Probe: Pod 内のコンテナが生きているか管理する。ここで定義する条件を満たさない場合、Pod が再起動される。
- Readiness Probe: Pod 内のコンテナがリクエストを受け付けられる状態か管理する。ここで定義する条件を満たさない場合、該当 Pod へリクエストは中継されない。
- Readiness Gates: Readiness Probe に加え、他の条件も含めてコンテナがリクエストを受け付けられる状態なのか制御できる機能です。
Nginx の Pod を例にそれぞれの機能の使い方を見ていきましょう。
apiVersion: v1
kind: Pod
metadata:
labels:
run: nginx
name: nginx
spec:
readinessGates: # Readiness Gates を定義 conditionType を複数定義することも可能。
- conditionType: "feature-ready"
containers:
- image: nginx:alpine
name: nginx
readinessProbe: # Readiness Probe の条件:コンテナの 80 ポートに対し、GET リクエストが行えること
httpGet:
port: 80
livenessProbe: # Liveness Probe の条件:コンテナの 80 ポートに対し、GET リクエストが行えること
httpGet:
port: 80
Readiness Gates の使い方については少し分かりづらいかもしれませんが、一つまたは複数の conditionType を定義して、定義された全ての conditionType が True となることで Pod の準備が完了したとみなされます。
上記 Pod の起動直後の状態を見ていきましょう。
$ kubectl describe pod nginx
(一部省略)
Readiness Gates:
Type Status
feature-ready <none> # 起動時には Status が none に。正常な状態とするにはこれを True にする必要がある。
Conditions:
Type Status
Initialized True
Ready False # Ready が False なので Pod にはリクエストが中継されない
ContainersReady True
PodScheduled True
kubectl get コマンドでも Readiness Gates の状態を確認することが可能です。(一番右列)
$ k get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx 1/1 Running 0 9m55s 10.18.129.2 gk3-autopilot-cluster-11-pool-2-6bf8ed9a-hm6p <none> 0/1
定義された conditionType を True にするには自身で用意するアプリケーションからライブラリ等を利用したり、直接 API をコールする必要があります。
現状、patch コマンドは対応していないとのことです。curl での更新例は以下の通りです。
※ kubectl proxy を別プロンプトで実行してください。
curl http://localhost:8001/api/v1/namespaces/default/pods/nginx/status -X PATCH -H "Content-Type: application/json-patch+json" -d '[{"op": "add", "path": "/status/conditions/-", "value": {"type": "feature-ready", "status": "True"}}]'
ここまでで、Readiness Probe や Readiness Gates の基本的な動作、使い方について解説しました。
以降ではコンテナネイティブなロードバランシングでこれらがどのように利用されているか見ていきましょう。
コンテナネイティブなロードバランシングにおける Pod の状態管理方法
コンテナネイティブなロードバランシングでは、前述した Readiness Gates を利用しています。
Readiness Gates を使う理由としては、Pod をクラスタ外に公開することによって、ロードバランサから Pod に対してヘルスチェックが行われます。このヘルスチェック結果も考慮した上で Pod へリクエストをルーティングできるか判断する必要があるためです。
本機能では、cloud.google.com/load-balancer-neg-ready という conditionType を利用しますが、ヘルスチェックが正常に行われたり、逆にヘルスチェックが正常に行われずにタイムアウトしてしまった際に True へ更新されます。 詳しくは公式docを参照してください。
後者については、Pod の起動が完了しないことによって、Pod のデプロイにおけるロールアウト(古い Pod を削除して新しい Pod を追加)が正常に行われなくなるため、いずれは True にする必要があるからだと思われます。
上記状態になるとヘルスチェックが正常に行われていない Pod に対して、ロードバランサからリクエストがルーティングされてしまうのでは?と思うのですが、ロードバランサのヘルスチェックが正常に行われていない限り、ロードバランサ自体が当該 Pod へリクエストをルーティングすることはありません。
参考までに、それぞれの状態別の Pod への接続可否については以下の通りとなります。
| LB のヘルスチェック | Pod の Readiness Gates | Pod の Readiness Probe | Pod への接続可否 |
|---|---|---|---|
| ✅ | ✅(※1) | ✅ | LB、クラスタ内から通信可 |
| ⛔ | ✅ | ✅ | LBから通信不可、クラスタ内から通信可 |
| ⛔ | ⛔ | ✅ | LB、クラスタ内から通信不可(※2) |
| ✅ | ✅ | ⛔(※3) | LBから通信可、クラスタ内から通信不可 |
✅:OK
⛔:NG
※1 Pod の Readiness Gates の ✅ は conditionType cloud.google.com/load-balancer-neg-ready が True となっている状態を指します。
※2 クラスタ内から通信不可のケースは他の Pod から Service 名によるアクセスを前提としています。
※3 コンテナの起動に関係ないコマンドを Readiness Probe として定義して、あえて ⛔ となるような状況を作っています。
まとめ
今回はコンテナネイティブなロードバランシングの機能について紹介しつつ、本機能において分かりづらい Pod の状態管理の部分について解説させていただきました。
基本的に GKE において Pod を外部公開する際には本機能の利用が推奨されていますが、自分自身 Readiness Gates 辺りの理解が曖昧だったので、空き時間ができた機会に調査してみました。
繰り返しにはなりますが、みなさん、飛行機に乗る際には早めに搭乗口に向かうようにしましょう。そして、怪しいと思ったら必ず受付の人なりに聞いて搭乗案内中じゃないか確認しましょう。
記事を閲覧いただきありがとうございました。
Discussion